Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie C# verwenden, um eine MapReduce-Lösung in HDInsight zu erstellen.
Mit Apache Hadoop-Streaming können Sie MapReduce-Aufträge mithilfe eines Skripts oder einer ausführbaren Datei ausführen. Hier wird .NET verwendet, um die Mapper- und Reducer-Prozesse für eine Lösung zum Zählen von Wörtern zu implementieren.
.NET in HDInsight
HDInsight-Cluster nutzen Mono (https://mono-project.com) für die Ausführung von .NET-Anwendungen. Mono-Version 4.2.1 ist in HDInsight Version 3.6 enthalten. Weitere Informationen über die in HDInsight enthaltene Version von Mono finden Sie unter Apache Hadoop-Komponenten und -Versionen – Azure HDInsight.
Weitere Informationen zur Kompatibilität von Mono mit .NET Framework-Versionen finden Sie unter Mono compatibility (Kompatibilität von Mono).
Funktionsweise von Hadoop-Datenströmen
Der in diesem Artikel verwendete grundlegende Prozess für das Streaming sieht wie folgt aus:
- Hadoop übergibt Daten an den Mapper-Prozess (in diesem Beispiel mapper.exe) auf STDIN.
- Der Mapper verarbeitet die Daten und gibt durch Tabstoppzeichen getrennte Schlüssel/Wert-Paare an STDOUT aus.
- Die Ausgabe wird von Hadoop gelesen und dann an den Reducer-Prozess (in diesem Beispiel reducer.exe) auf STDIN übergeben.
- Der Reducer-Prozess liest die durch Tabstoppzeichen getrennten Schlüssel/Wert-Paare, verarbeitet die Daten und gibt dann das Ergebnis als durch Tabstoppzeichen getrennte Schlüssel/Wert-Paare auf STDOUT aus.
- Die Ausgabe wird von Hadoop gelesen und in das Ausgabeverzeichnis geschrieben.
Weitere Informationen zum Streaming finden Sie unter Hadoop-Streaming.
Voraussetzungen
Visual Studio.
Gute Kenntnisse im Schreiben und Erstellen von C#-Code für .NET Framework 4.5.
Eine Möglichkeit zum Hochladen von EXE-Dateien in den Cluster. In den Schritten in diesem Artikel werden die Data Lake-Tools für Visual Studio zum Hochladen der Dateien in primären Speicher für den Cluster verwendet.
Bei Verwendung von PowerShell benötigen Sie das Az-Modul.
Ein Apache Hadoop-Cluster in HDInsight. Weitere Informationen finden Sie unter Erste Schritte mit HDInsight unter Linux.
Das URI-Schema für Ihren primären Clusterspeicher. Dieses Schema ist für Azure Storage
wasb://, für Azure Data Lake Storage Gen2abfs://und für Azure Data Lake Storage Gen1adl://. Wenn die sichere Übertragung für Azure Storage oder Data Lake Storage Gen2 aktiviert ist, lautet der URIwasbs://bzw.abfss://.
Erstellen des Mappers
Erstellen Sie in Visual Studio eine neue .NET Framework-Konsolenanwendung mit dem Namen mapper. Verwenden Sie für die Anwendung den folgenden Code:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Nachdem Sie die Anwendung erstellen, erzeugen Sie mit ihrer Hilfe die Datei /bin/Debug/mapper.exe im Projektverzeichnis.
Erstellen des Reducers
Erstellen Sie in Visual Studio eine neue .NET Framework-Konsolenanwendung mit dem Namen reducer. Verwenden Sie für die Anwendung den folgenden Code:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Nachdem Sie die Anwendung erstellen, erzeugen Sie mit ihrer Hilfe die Datei /bin/Debug/reducer.exe im Projektverzeichnis.
Hochladen in den Speicher
Als nächstes müssen Sie die Anwendungen mapper und reducer in den HDInsight-Speicher hochladen.
Wählen Sie in Visual Studio Ansicht>Server-Explorer aus.
Klicken Sie mit der rechten Maustaste auf den Knoten Azure, wählen Sie Verbindung mit Microsoft Azure-Abonnement herstellen... aus, und schließen Sie den Anmeldevorgang ab.
Erweitern Sie den HDInsight-Cluster, in dem Sie diese Anwendung bereitstellen möchten. Ein Eintrag mit dem Text (Standardspeicherkonto) ist aufgeführt.
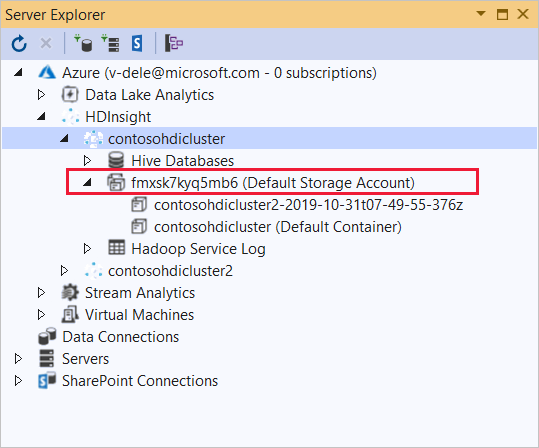
Wenn der Eintrag (Standardspeicherkonto) erweitert werden kann, verwenden Sie ein Azure Storage-Konto als Standardspeicher für den Cluster. Um die Dateien im Standardspeicher für den Cluster anzuzeigen, erweitern Sie den Eintrag, und doppelklicken Sie dann auf (Standardcontainer) .
Wenn der Eintrag (Standardspeicherkonto) nicht erweitert werden kann, verwenden Sie Azure Data Lake Storage als Standardspeicher für den Cluster. Um die Dateien im Standardspeicher für den Cluster anzuzeigen, doppelklicken Sie auf den Eintrag (Standardspeicherkonto) .
Laden Sie die EXE-Dateien mithilfe einer der folgenden Methoden hoch:
Wenn Sie ein Azure Storage-Konto verwenden, wählen Sie das Symbol Blob hochladen aus.

Wählen Sie im Dialogfeld Neue Datei hochladen unter Dateiname die Option Durchsuchen aus. Wechseln Sie im Dialogfeld Blob hochladen zum Ordner bin\debug dieses mapper-Projekts, und wählen Sie dann die Datei mapper.exe aus. Wählen Sie abschließend Öffnen und dann OK aus, um den Upload abzuschließen.
Wenn Sie Azure Data Lake Storage verwenden, klicken Sie mit der rechten Maustaste auf einen leeren Bereich in der Dateiliste, und wählen Sie dann Hochladen aus. Wählen Sie abschließend die Datei mapper.exe und dann Öffnen aus.
Sobald der Upload der Datei mapper.exe abgeschlossen ist, wiederholen Sie den Uploadvorgang für die Datei reducer.exe.
Ausführen eines Auftrags: Verwenden einer SSH-Sitzung
Im folgenden Verfahren wird beschrieben, wie Sie einen MapReduce-Auftrag über eine SSH-Sitzung ausführen:
Verwenden Sie einen ssh-Befehl zum Herstellen der Verbindung mit dem Cluster. Bearbeiten Sie den folgenden Befehl, indem Sie CLUSTERNAME durch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerwenden Sie zum Starten des MapReduce-Auftrags einen der folgenden Befehle:
Wenn der Standardspeicher Azure Storage ist:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutWenn der Standardspeicher Data Lake Storage Gen1: ist:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutWenn der Standardspeicher Data Lake Storage Gen2: ist:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
In der folgenden Liste wird beschrieben, was die einzelnen Parameter und Optionen darstellen:
Parameter BESCHREIBUNG hadoop-streaming.jar Gibt die JAR-Datei an, die die MapReduce-Streamingfunktionen enthält. -files Gibt die Dateien mapper.exe und reducer.exe für diesen Auftrag an. Die Protokolldeklaration wasbs:///,adl:///oderabfs:///vor jeder Datei ist der Pfad zum Stamm des Standardspeichers für den Cluster.-mapper Gibt die Datei an, die den Mapper implementiert. -reducer Gibt die Datei an, die den Reducer implementiert. -input Gibt die Eingabedaten an. -output Gibt das Ausgabeverzeichnis an. Wenn der MapReduce-Auftrag abgeschlossen ist, können Sie die Ergebnisse mit dem folgenden Befehl anzeigen:
hdfs dfs -text /example/wordcountout/part-00000Der folgende Text ist ein Beispiel der von diesem Befehl zurückgegebenen Daten:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Ausführen eines Auftrags: PowerShell
Verwenden Sie das folgende PowerShell-Skript zum Ausführen eines MapReduce-Auftrags und zum Herunterladen der Ergebnisse.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Dieses Skript fordert Sie auf den Kontonamen und das Kennwort für die Clusteranmeldung sowie den HDInsight-Clusternamen einzugeben. Wenn der Auftrag abgeschlossen wurde, wird die Ausgabe in die Datei output.txt heruntergeladen. Der folgende Text ist ein Beispiel für die Daten in der Datei output.txt:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17