Azure HDInsight Accelerated Writes für Apache HBase
Dieser Artikel bietet Hintergrundinformationen zum Accelerated Writes-Feature für Apache HBase in Azure HDInsight und zu dessen effektiver Verwendung zur Verbesserung der Schreibleistung. Accelerated Writes verwendet verwaltete Azure-Premium-SSD-Datenträger zur Verbesserung der Leistung des Apache HBase-Write-Ahead-Protokolls (Write Ahead Log, WAL). Weitere Informationen zu Apache HBase finden Sie unter Überblick über Apache HBase in HDInsight: Eine NoSQL-Datenbank, die BigTable-ähnliche Funktionen für Apache Hadoop bereitstellt.
Übersicht über die HBase-Architektur
In HBase besteht eine Zeile aus einer oder mehreren Spalten und wird durch einen Zeilenschlüssel identifiziert. Mehrere Zeilen bilden eine Tabelle. Spalten enthalten Zellen, welche mit einem Zeitstempel versehene Versionen des Werts in dieser Spalte sind. Spalten werden in Spaltenfamilien gruppiert, und alle Spalten in einer Spaltenfamilie werden gemeinsam in Speicherdateien gespeichert, die als HFiles bezeichnet werden.
Regionen werden in HBase verwendet, um die Datenverarbeitungslast auszugleichen. HBase speichert zunächst die Zeilen einer Tabelle in einer einzelnen Region. Die Zeilen werden über mehrere Regionen verteilt, wenn die Menge der Daten in der Tabelle steigt. Regionsserver können Anforderungen für mehrere Regionen verarbeiten.
Write-Ahead-Protokoll für Apache Hbase
HBase schreibt Datenaktualisierungen zuerst in einen Commitprotokolltyp, der als Write-Ahead-Protokoll (WAL) bezeichnet wird. Sobald das Update im WAL gespeichert ist, wird es in den In-Memory-MemStore geschrieben. Wenn die maximale Datenkapazität im Arbeitsspeicher erreicht ist, werden die Daten als HFile auf den Datenträger geschrieben.
Wenn ein RegionServer abstürzt oder nicht mehr verfügbar ist, bevor der MemStore geleert wird, kann das Write-Ahead-Protokoll verwendet werden, um Updates zu wiederholen. Wenn ein RegionServer ohne WAL abstürzt, bevor Updates in einen HFile geleert wurden, gehen alle diese Updates verloren.
Das Accelerated Writes-Feature in HDInsight für Apache HBase
Das Accelerated Writes-Feature löst das Problem der höheren Schreiblatenzen, das durch Verwendung von Write-Ahead-Protokollen verursacht wird, die sich im Cloudspeicher befinden. Das Accelerated Writes-Feature für HDInsight Apache HBase-Cluster fügt verwaltete SSD-Premium-Datenträger jedem RegionServer (Workerknoten) hinzu. Write-Ahead-Protokolle werden dann auf das in diese verwalteten Premium-Datenträger eingebundene Hadoop Distributed File System (HDFS) statt in den Cloudspeicher geschrieben. Verwaltete Premium-Datenträger verwenden Solid State-Laufwerke (SSDs) und bieten eine ausgezeichnete E/A-Leistung mit Fehlertoleranz. Wenn eine Speichereinheit ausfällt, wirkt sich das im Gegensatz zu nicht verwalteten Datenträgern nicht auf andere Speichereinheiten in derselben Verfügbarkeitsgruppe aus. Daher bieten verwaltete Datenträger geringe Schreiblatenz und eine höhere Flexibilität für Ihre Anwendungen. Weitere Informationen zu verwalteten Azure-Datenträgern finden Sie unter Einführung in verwaltete Azure-Datenträger.
Gewusst wie: Aktivieren von Accelerated Writes für HBase in HDInsight
Um einen neuen HBase-Cluster mit dem Accelerated Writes-Feature zu erstellen, führen Sie die Schritte in Einrichten von Clustern in HDInsight mit Apache Hadoop, Apache Spark, Apache Kafka usw. aus. Wählen Sie auf der Registerkarte Grundlagen als Clustertyp „HBase“ aus, geben Sie eine Komponentenversion an, und klicken Sie dann auf das Kontrollkästchen neben Beschleunigte HBase-Schreibvorgänge aktivieren. Fahren Sie dann mit den verbleibenden Schritten zur Erstellung des Clusters fort.
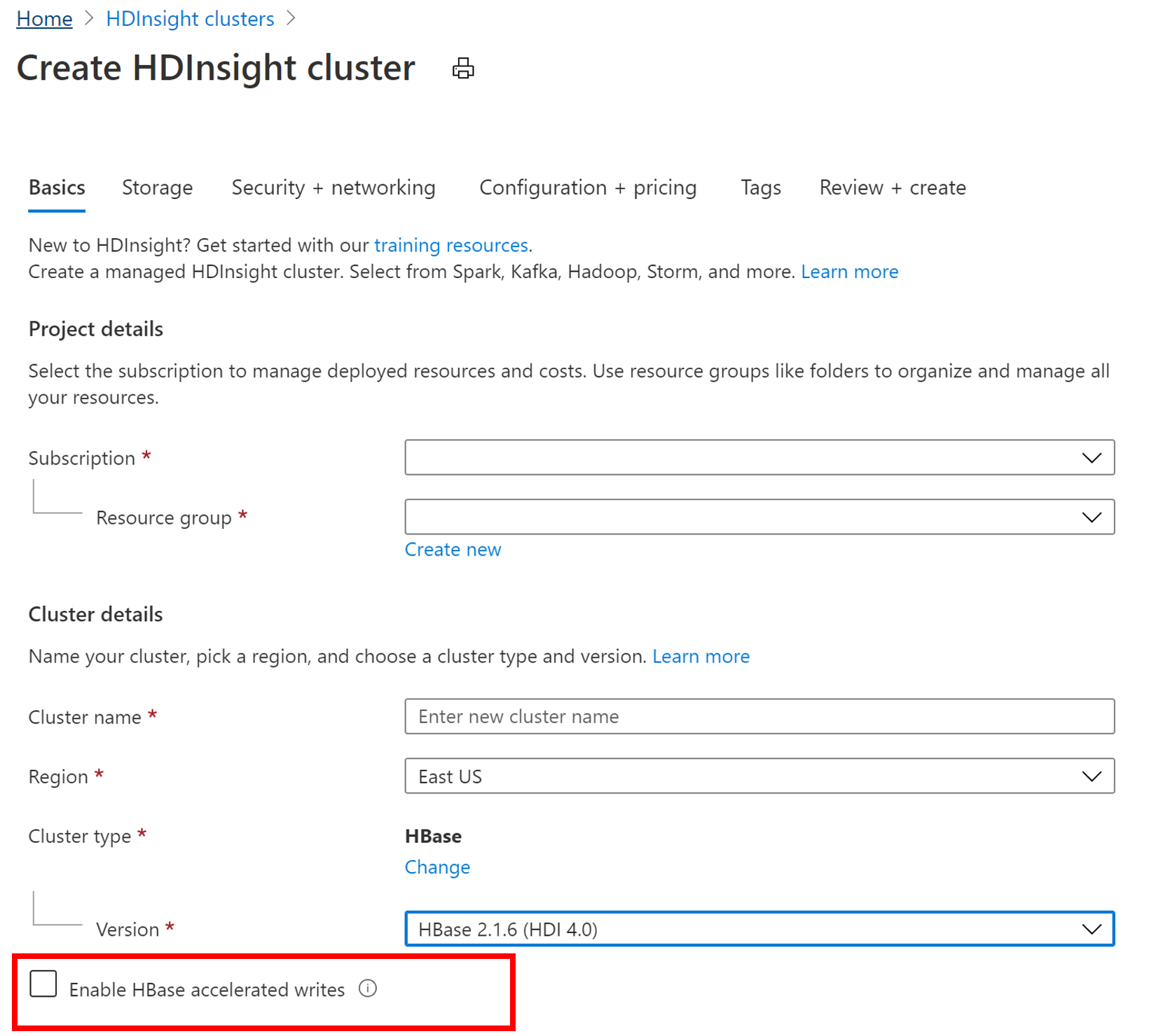
Überprüfen, ob die Funktion für beschleunigte Schreibvorgänge aktiviert wurde
Sie können das Azure-Portal verwenden, um zu überprüfen, ob das Feature für beschleunigte Schreibvorgänge in einem HBASE-Cluster aktiviert ist.
- Suchen Sie im Azure-Portal nach Ihrem HBASE-Cluster.
- Wählen Sie das Blatt Clustergröße aus.
- Premium-Datenträger pro Workerknoten werden angezeigt.
Skalieren von HBASE-Clustern
Damit die Dauerhaftigkeit der Daten erhalten bleibt, erstellen Sie einen Cluster mit mindestens drei Workerknoten. Nach der Erstellung können Sie den Cluster nicht auf weniger als drei Workerknoten zentral herunterskalieren.
Leeren oder deaktivieren Sie die HBase-Tabellen vor dem Löschen des Clusters, damit Sie keine Write-Ahead-Protokoll-Daten verlieren.
flush 'mytable'
disable 'mytable'
Führen Sie beim zentralen Herunterskalieren des Clusters ähnliche Schritte aus: Leeren Sie Ihre Tabellen, und deaktivieren Sie sie, um den Eingang von Daten zu beenden. Sie können Ihren Cluster nicht auf weniger als drei Knoten zentral herunterskalieren.
Wenn Sie diese Schritte ausführen, stellen Sie eine erfolgreiche zentrale Herunterskalierung sicher und vermeiden die Möglichkeit, dass ein Namensknoten aufgrund von unterreplizierten oder temporären Dateien in den abgesicherten Modus wechselt.
Wenn Ihr Namensknoten nach einer Herunterskalierung in den abgesicherten Modus wechselt, replizieren Sie mithilfe der HDFS-Befehle die unzureichend replizierten Blöcke erneut, und heben Sie den abgesicherten Modus für HDFS auf. Mit dieser erneuten Replikation können Sie HBase erfolgreich neu starten.
Nächste Schritte
- Offizielle Dokumentation zu Apache HBase im Write-Ahead-Protokoll-Feature
- Wie Sie Ihren HDInsight Apache HBase-Cluster für die Verwendung von Accelerated Writes aktualisieren, erfahren Sie unter Migrieren eines Apache HBase-Clusters zu einer neuen Version.