Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Replikationsmechanismen von Azure HDInsight können in eine hoch verfügbare Lösungsarchitektur integriert werden. In diesem Artikel wird eine fiktive Fallstudie für Contoso Retail verwendet, um mögliche Ansätze zur Notfallwiederherstellung mit hoher Verfügbarkeit, Kostenaspekte und deren entsprechende Designs zu erläutern.
Empfehlungen für die Notfallwiederherstellung mit hoher Verfügbarkeit können viele Permutationen und Kombinationen aufweisen. Diese Lösungen sind nach der Beratung der Vor- und Nachteile jeder Option zu finden. In diesem Artikel wird nur eine mögliche Lösung erläutert.
Kundenarchitektur
Die folgende Abbildung zeigt die primäre Architektur von Contoso Retail. Die Architektur besteht aus einer Streaming-Workload, Batchworkload, Bereitstellungsebene, Verbrauchsschicht, Speicherebene und Versionssteuerung.
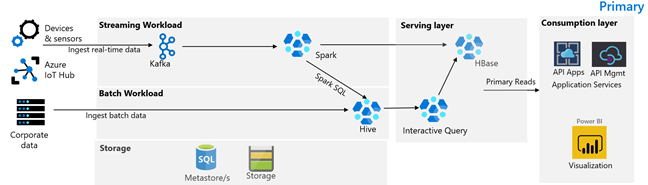
Streamingworkload
Geräte und Sensoren erzeugen Daten zu HDInsight Kafka, das das Messaging-Framework darstellt. Ein HDInsight Spark-Verbraucher liest aus den Kafka Topics. Spark transformiert die eingehenden Nachrichten und schreibt sie in einen HDInsight HBase-Cluster auf der Bereitstellungsebene.
Batchworkload
Ein HDInsight Hadoop-Cluster mit Hive und MapReduce erfasst Daten aus lokalen Transaktionssystemen. Rohdaten, die von Hive und MapReduce transformiert werden, werden in Hive-Tabellen auf einer logischen Partition des von Azure Data Lake Storage Gen2 gesicherten Datensees gespeichert. Daten, die in Hive-Tabellen gespeichert sind, werden auch Spark SQL bereitgestellt, das Batch-Transformationen durchführt, bevor die kuratierten Daten in HBase zur Bereitstellung gespeichert werden.
Bereitstellungsebene
Ein HDInsight HBase-Cluster mit Apache Phoenix wird verwendet, um Daten für Webanwendungen und Visualisierungsdashboards bereitzustellen. Ein HDInsight LLAP-Cluster wird verwendet, um interne Berichtsanforderungen zu erfüllen.
Verbrauchsschicht
Eine Azure API Apps und API Management-Schicht unterstützt eine öffentlich zugängliche Webseite. Interne Berichterstellungsanforderungen werden von Power BI erfüllt.
Speicherebene
Logisch partitionierte Azure Data Lake Storage Gen2 wird als Unternehmensdatensee verwendet. Die HDInsight-Metastores werden von Azure SQL DB unterstützt.
Versionskontrollsystem
Ein Versionssteuerungssystem, das in eine Azure-Pipeline integriert und außerhalb von Azure gehostet wird.
Geschäftskontinuitätsanforderungen für Kunden
Es ist wichtig, die minimalen Geschäftsfunktionen zu ermitteln, die Sie benötigen, wenn ein Notfall vorhanden ist.
Anforderungen an die Geschäftskontinuität von Contoso Retail
- Wir müssen vor einem regionalen Ausfall oder einem regionalen Dienstgesundheitsproblem geschützt sein.
- Meine Kunden dürfen niemals einen 404-Fehler sehen. Öffentliche Inhalte müssen immer bereitgestellt werden. (RTO = 0)
- Für den größten Teil des Jahres können wir öffentliche Inhalte anzeigen, die um 5 Stunden veraltet sind. (RPO = 5 Stunden)
- Während der Ferienzeit müssen unsere öffentlich zugänglichen Inhalte immer auf dem neuesten Stand sein. (RPO = 0)
- Meine internen Berichterstellungsanforderungen werden nicht als kritisch für die Geschäftskontinuität betrachtet.
- Optimieren Sie die Kosten für die Geschäftskontinuität.
Vorgeschlagene Lösung
Die folgende Abbildung zeigt die Hochverfügbarkeitsarchitektur der Notfallwiederherstellung von Contoso Retail.
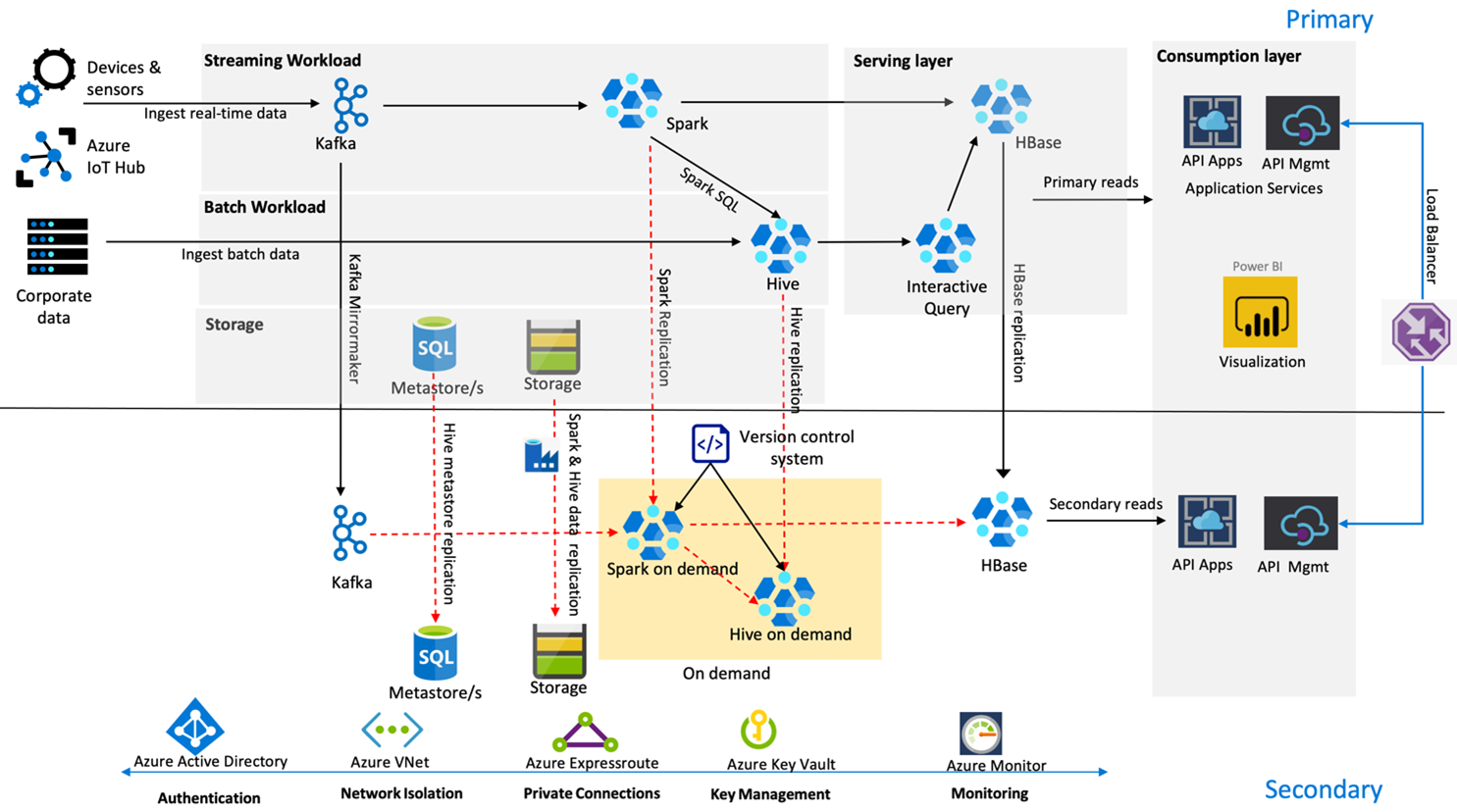
Kafka verwendet aktive – passive Replikation, um Kafka Topics aus der primären Region in die sekundäre Region zu spiegeln. Eine Alternative zur Kafka-Replikation könnte darin bestehen, in beiden Regionen Daten an Kafka zu senden.
Hive und Spark verwenden Aktives Primär – On-Demand Secondary Replikationsmodelle während normaler Zeiten. Der Hive-Replikationsprozess wird regelmäßig ausgeführt und umfasst die Replikation des Hive Azure SQL-Metastores sowie des Hive-Speicherkontos. Das Spark-Speicherkonto wird in regelmäßigen Abständen mithilfe von ADF DistCP repliziert. Die vorübergehende Natur dieser Cluster trägt zur Optimierung der Kosten bei. Replikationen sind für alle 4 Stunden geplant, um eine RPO zu gewährleisten, die die 5-Stunden-Anforderung problemlos erfüllt.
Die HBase-Replikation verwendet das Leader - Follower-Modell in normalen Zeiten, um sicherzustellen, dass Daten unabhängig von der Region immer bereitgestellt werden und das RPO sehr niedrig ist.
Wenn es einen regionalen Fehler in der primären Region gibt, werden die Webseiten- und Back-End-Inhalte 5 Stunden lang aus der sekundären Region mit einem gewissen Grad an Veraltetkeit bereitgestellt. Wenn das Azure-Dienststatusdashboard im fünfstündigen Fenster keine Wiederherstellungs-ETA anzeigt, erstellt Contoso Retail die Hive- und Spark-Transformationsebene in der sekundären Region und leitet dann alle Upstream-Datenquellen zur sekundären Region um. Würde die sekundäre Region beschreibbar gemacht, so würde dadurch ein Failbackprozess ausgelöst, der eine Replikation zurück in die primäre Region umfasst.
Während einer spitzen Einkaufssaison ist die gesamte Sekundärpipeline immer aktiv und läuft. Die Kafka-Producer senden Daten an beide Regionen, und die HBase-Replikation wird von Leader-Follower in Leader-Leader geändert, um sicherzustellen, dass die öffentlichen Inhalte immer auf dem neuesten Stand sind.
Es muss keine Failoverlösung für interne Berichte entwickelt werden, da es für die Geschäftskontinuität nicht wichtig ist.
Nächste Schritte
Weitere Informationen zu den in diesem Artikel erörterten Themen finden Sie unter: