Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Der HDInsight-Cluster erzeugt verschiedene Protokolldateien. Beispielsweise erzeugen Apache Hadoop und die dazugehörigen Dienste, z.B. Apache Spark, ausführliche Protokolle zur Auftragsausführung. Die Verwaltung von Protokolldateien ist Teil des Betriebs eines fehlerfreien HDInsight-Clusters. Es kann auch sein, dass gesetzliche Anforderungen zur Archivierung von Protokollen erfüllt werden müssen. Aufgrund der Anzahl und Größe von Protokolldateien ist eine Optimierung der Protokollspeicherung und -archivierung für die Verwaltung der Dienstkosten hilfreich.
Die Verwaltung von HDInsight-Clusterprotokollen umfasst auch das Vorhalten von Informationen zu allen Aspekten der Clusterumgebung. Zu diesen Informationen gehören alle zugeordneten Azure Service-Protokolle, die Clusterkonfiguration, Informationen zur Auftragsausführung, alle Fehlerstatus sowie andere Daten je nach Bedarf.
Typische Schritte der HDInsight-Protokollverwaltung sind:
- Schritt 1: Ermitteln der Richtlinien für die Protokollaufbewahrung
- Schritt 2: Verwalten von Konfigurationsprotokollen für Clusterdienstversionen
- Schritt 3: Verwalten von Protokolldateien zur Ausführung von Clusteraufträgen
- Schritt 4: Prognostizieren von Speichergrößen und Kosten für das Protokollvolumen
- Schritt 5: Ermitteln der Richtlinien und Prozesse für die Protokollarchivierung
Schritt 1: Ermitteln der Richtlinien für die Protokollaufbewahrung
Der erste Schritt beim Erstellen einer Strategie für die Protokollverwaltung eines HDInsight-Clusters ist das Sammeln von Informationen zu Geschäftsszenarien und zu den Speicheranforderungen des Auftragsausführungsverlaufs.
Clusterdetails
Die folgenden Clusterdetails sind hilfreich beim Sammeln von Informationen für Ihre Strategie zur Protokollverwaltung. Sammeln Sie diese Informationen von allen HDInsight-Clustern, die Sie in einem bestimmten Azure-Konto erstellt haben.
- Clustername
- Clusterregion und Azure-Verfügbarkeitszone
- Clusterstatus, einschließlich Details zur letzten Statusänderung
- Art und Anzahl von HDInsight-Instanzen, die für die Master-, Core- und Aufgabenknoten angegeben werden
Sie können die meisten dieser Informationen der obersten Ebene über das Azure-Portal abrufen. Alternativ dazu können Sie die Azure CLI verwenden, um Informationen zu Ihren HDInsight-Clustern abzurufen:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Sie können zum Anzeigen dieser Informationen auch PowerShell nutzen. Weitere Informationen finden Sie unter Verwalten von Apache Hadoop-Clustern in HDInsight mit Azure PowerShell.
Grundlegendes zu Workloads, die in Ihren Clustern ausgeführt werden
Es ist wichtig, dass Sie die in Ihren HDInsight-Clustern ausgeführten Workloadtypen verstehen, damit Sie für jeden Typ die passende Protokollierungsstrategie entwerfen können.
- Sind die Workloads experimenteller Art (z.B. im Entwicklungs- oder Testbereich), oder geht es um Produktionsqualität?
- Wie häufig werden Workloads mit Produktionsqualität normalerweise ausgeführt?
- Sind Workloads mit hoher Ressourcenintensität oder langer Ausführungsdauer dabei?
- Wird für Workloads ein komplexer Satz von Hadoop-Diensten verwendet, für die mehrere Arten von Protokollen erzeugt werden?
- Bestehen für Workloads gesetzliche Anforderungen in Bezug auf die Ausführungsherkunft?
Beispiel für Protokollaufbewahrung – Muster und Vorgehensweisen
Erwägen Sie, die Datenherkunft nachzuverfolgen, indem Sie jedem Protokolleintrag einen Bezeichner hinzufügen oder andere Verfahren nutzen. So können Sie die ursprüngliche Quelle der Daten und den Vorgang zurückverfolgen und die Daten für jede Stufe anzeigen, um Informationen zur Konsistenz und Gültigkeit zu erhalten.
Überlegen Sie, wie Sie Protokolle für den Cluster oder mehr als einen Cluster sammeln und für Zwecke wie Auditing, Überwachung, Planung und Warnung zusammenstellen können. Sie können ggf. eine benutzerdefinierte Lösung nutzen, um regelmäßig auf die Protokolldateien zuzugreifen und diese herunterzuladen und dann zu kombinieren und zu analysieren, um eine entsprechende Dashboardanzeige bereitzustellen. Außerdem können Sie weitere Funktionen für Sicherheitswarnungen oder die Fehlererkennung hinzufügen. Sie können diese Hilfsprogramme mit PowerShell, den HDInsight SDKs oder Code erstellen, mit dem auf das klassische Azure-Bereitstellungsmodell zugegriffen wird.
Überlegen Sie, ob eine Überwachungslösung oder ein entsprechender Dienst nützlich wäre. In Microsoft System Center ist ein HDInsight Management Pack verfügbar. Sie können auch Drittanbietertools verwenden, z. B. Apache Chukwa und Ganglia, um Protokolle zu sammeln und zu zentralisieren. Viele Unternehmen bieten Dienste zum Überwachen von Hadoop-basierten Big Data-Lösungen an, z. B.
Centerity, Compuware APM, Sematext SPM und Zettaset Orchestrator.
Schritt 2: Verwalten von Clusterdienstversionen und Anzeigen von Protokollen
Für einen typischen HDInsight-Cluster werden mehrere Dienste und Open-Source-Softwarepakete verwendet (z.B. Apache HBase, Apache Spark usw.). Bei einigen Workloads, z. B. der Bioinformatik, kann es ggf. erforderlich sein, zusätzlich zu den Protokollen zur Auftragsausführung den Protokollierungsverlauf der Dienstkonfiguration aufzubewahren.
Anzeigen von Einstellungen zur Clusterkonfiguration mit der Ambari-Benutzeroberfläche
Mit Apache Ambari wird die Verwaltung, Konfiguration und Überwachung eines HDInsight-Clusters vereinfacht, indem eine Webbenutzeroberfläche und eine REST-API bereitgestellt werden. Ambari ist in Linux-basierten HDInsight-Clustern enthalten. Wählen Sie im Azure-Portal auf der Seite „HDInsight“ den Bereich Clusterdashboard, um die Linkseite Clusterdashboards zu öffnen. Wählen Sie als Nächstes den Bereich HDInsight-Cluster-Dashboard, um die Ambari-Benutzeroberfläche zu öffnen. Sie werden aufgefordert, Ihre Anmeldeinformationen für den Cluster einzugeben.
Wählen Sie zum Öffnen einer Liste mit den Dienstansichten im Azure-Portal auf der Seite „HDInsight“ den Bereich Ambari Views. Der Inhalt der Liste variiert in Abhängigkeit davon, welche Bibliotheken Sie installiert haben. Beispielsweise werden ggf. YARN Queue Manager, Hive View und Tez View angezeigt. Wählen Sie einen beliebigen Dienstlink aus, um die Konfigurations- und Dienstinformationen anzuzeigen. Die Seite Stack and Versions (Stapel und Versionen) der Ambari-Benutzeroberfläche enthält Informationen zur Konfiguration und zum Dienstversionsverlauf der Clusterdienste. Wählen Sie zum Navigieren dieses Abschnitts der Ambari-Benutzeroberfläche das Menü Admin und dann die Option Stack and Versions (Stapel und Versionen). Wählen Sie die Registerkarte Versions (Versionen), um Informationen zur Dienstversion anzuzeigen.
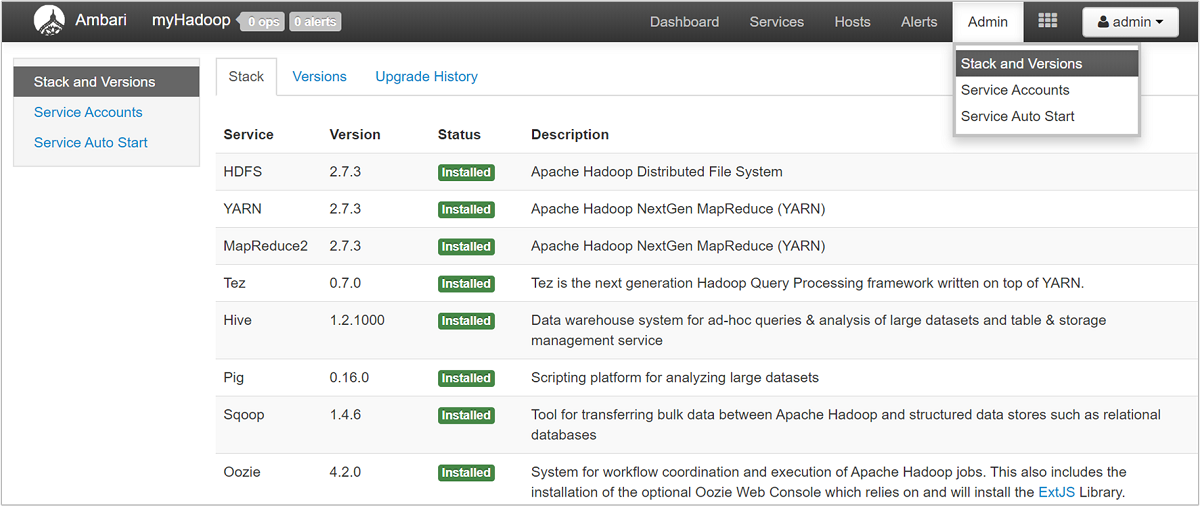
Mit der Ambari-Benutzeroberfläche können Sie die Konfiguration für beliebige (oder alle) Dienste herunterladen, die auf einem bestimmten Host (oder Knoten) im Cluster ausgeführt werden. Wählen Sie das Menü Hosts und anschließend den Link für den gewünschten Host. Wählen Sie auf der Seite des Hosts die Schaltfläche Host Actions (Hostaktionen) und dann Download Client Configs (Clientkonfigurationen herunterladen).
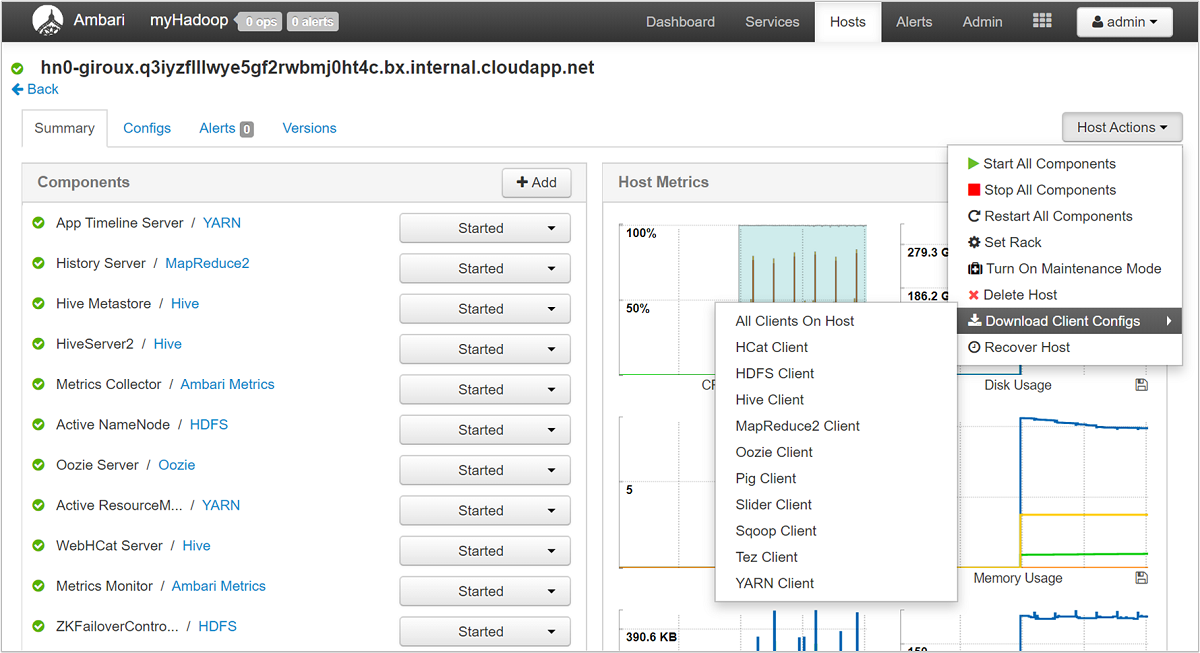
Anzeigen der Skriptaktionsprotokolle
Mit HDInsight-Skriptaktionen werden Skripts in einem Cluster manuell oder gemäß Festlegung ausgeführt. Skriptaktionen können beispielsweise verwendet werden, um zusätzliche Software im Cluster zu installieren oder für Konfigurationseinstellungen die Standardwerte zu ändern. Skriptaktionsprotokolle können Erkenntnisse zu Fehlern liefern, die während der Einrichtung des Clusters aufgetreten sind, sowie zu Änderungen von Konfigurationseinstellungen, die sich auf die Clusterleistung und -verfügbarkeit auswirken können. Wählen Sie zum Anzeigen des Status einer Skriptaktion in der Ambari-Benutzeroberfläche die Schaltfläche ops (Vorgänge), oder greifen Sie auf die Statusprotokolle im Standardspeicherkonto zu. Die Speicherprotokolle stehen unter /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE zur Verfügung.
Anzeigen von Protokollen zum Ambari-Warnungsstatus
Apache Ambari schreibt Warnungsstatusänderungen in ambari-alerts.log. Der vollständige Pfad lautet /var/log/ambari-server/ambari-alerts.log. Um das Debuggen für das Protokoll zu aktivieren, ändern Sie eine Eigenschaft in /etc/ambari-server/conf/log4j.properties.. Ändern Sie dann den Eintrag unter # Log alert state changes von:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Schritt 3: Verwalten von Protokolldateien zur Ausführung von Clusteraufträgen
Im nächsten Schritt werden die Protokolldateien zur Auftragsausführung für die verschiedenen Dienste überprüft. Beispiele für diese Dienste sind Apache HBase, Apache Spark und viele weitere. Ein Hadoop-Cluster erzeugt eine große Zahl von ausführlichen Protokollen, sodass die Ermittlung, welche Protokolle nützlich sind (und welche nicht), ein zeitaufwändiger Vorgang sein kann. Es ist wichtig, das Protokollierungssystem zu verstehen, um eine zielgerichtete Verwaltung von Protokolldateien zu ermöglichen. Die folgende Abbildung zeigt ein Beispiel für eine Protokolldatei.
Zugreifen auf die Hadoop-Protokolldateien
HDInsight speichert die Protokolldateien sowohl im Clusterdateisystem als auch in Azure Storage. Sie können Protokolldateien im Cluster untersuchen, indem Sie eine SSH-Verbindung mit dem Cluster öffnen und das Dateisystem durchsuchen oder das Hadoop YARN-Statusportal auf dem Hauptknoten-Remoteserver verwenden. Sie können die Protokolldateien in Azure Storage mit allen Tools untersuchen, mit denen auf Daten in Azure Storage zugegriffen und diese heruntergeladen werden können. Beispiele hierfür sind AzCopy, CloudXplorer und der Server-Explorer von Visual Studio. Sie können auch PowerShell und die Azure Storage-Clientbibliotheken oder die Azure .NET SDKs verwenden, um auf Daten in Azure Blob Storage zuzugreifen.
Hadoop führt die Schritte der Aufträge als Taskversuche auf verschiedenen Knoten im Cluster aus. HDInsight kann spekulative Taskversuche initiieren und zuerst alle anderen Taskversuche beenden, die nicht erfolgreich abgeschlossen werden können. Hierbei wird eine erhebliche Zahl von Aktivitäten generiert, die nebenbei in den controller-, stderr- und syslog-Protokolldateien protokolliert werden. Außerdem werden gleichzeitig mehrere Taskversuche ausgeführt, aber eine Protokolldatei kann Ergebnisse nur linear anzeigen.
In Azure Blob Storage geschriebene HDInsight-Protokolle
HDInsight-Cluster werden so konfiguriert, dass Taskprotokolle für alle Aufträge, die über die Azure PowerShell-Cmdlets oder die .NET-APIs für die Auftragsübermittlung gesendet werden, in ein Azure Blob Storage-Konto geschrieben werden. Wenn Sie Aufträge per SSH an den Cluster senden, werden die Informationen zur Ausführungsprotokollierung in den Azure-Tabellen gespeichert, wie im vorherigen Abschnitt beschrieben.
Zusätzlich zu den von HDInsight generierten Kernprotokolldateien generieren auch installierte Dienste wie YARN Protokolldateien zur Auftragsausführung. Anzahl und Typ der Protokolldateien richten sich nach den installierten Diensten. Häufig genutzte Dienste sind Apache HBase, Apache Spark usw. Sehen Sie sich die Protokolldateien zur Auftragsausführung für jeden Dienst an, um zu verstehen, welche allgemeinen Protokollierungsdateien in Ihrem Cluster verfügbar sind. Jeder Dienst verfügt über eigene Methoden für die Protokollierung sowie über eigene Speicherorte für die Protokolldateien. Als Beispiel werden im folgenden Abschnitt Details zum Zugreifen auf die am häufigsten verwendeten Protokolldateien (aus YARN) beschrieben.
Von YARN generierte HDInsight-Protokolle
YARN aggregiert Protokolle in allen Containern auf einem Workerknoten und speichert sie als eine aggregierte Protokolldatei pro Workerknoten. Dieses Protokoll wird, nachdem eine Anwendung beendet wurde, im Standarddateisystem gespeichert. Ihre Anwendung nutzt unter Umständen Hunderte oder Tausende von Containern, aber Protokolle für alle auf einem einzelnen Workerknoten vorhandenen Container werden immer zu einer zentralen Datei zusammengeführt. Es wird nur ein Protokoll pro Workerknoten von Ihrer Anwendung genutzt. Die Protokollaggregation ist für HDInsight-Cluster ab Version 3.0 standardmäßig aktiviert. Aggregierte Protokolle befinden sich im Standardspeicher für den Cluster.
/app-logs/<user>/logs/<applicationId>
Die zusammengeführten Protokolle sind nicht unmittelbar lesbar, da sie in einem TFile-Binärformat mit Indizierung nach Container geschrieben werden. Verwenden Sie die YARN-ResourceManager-Protokolle oder CLI-Tools, um diese Protokolle für relevante Anwendungen oder Container im Nur-Text-Format anzuzeigen.
YARN-CLI-Tools
Zur Verwendung der YARN CLI-Tools müssen Sie zuerst über SSH eine Verbindung mit dem HDInsight-Cluster herstellen. Geben Sie die Informationen zu <applicationId>, <user-who-started-the-application>, <containerId> und <worker-node-address> an, wenn Sie diese Befehle ausführen. Sie können die Protokolle mit einem der folgenden Befehle als Klartext anzeigen:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
YARN Resource Manager-Benutzeroberfläche
Die YARN-Resource Manager-Benutzeroberfläche wird auf dem Hauptknoten des Clusters ausgeführt, und der Zugriff erfolgt über die Ambari-Webbenutzeroberfläche. Führen Sie die folgenden Schritte aus, um die YARN-Protokolle anzeigen:
- Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net. Ersetzen Sie CLUSTERNAME durch den Namen Ihres HDInsight-Clusters. - Wählen Sie in der Liste mit den Diensten auf der linken Seite die Option „YARN“ aus.
- Wählen Sie in der Dropdownliste „Quicklinks“ einen der Clusterhauptknoten und dann Resource Manager-Protokolle aus. Eine Liste mit Links zu YARN-Protokollen wird angezeigt.
Schritt 4: Prognostizieren von Speichergrößen und Kosten für das Protokollvolumen
Nachdem Sie die obigen Schritte ausgeführt haben, sind Sie mit den Typen und Mengen von Protokolldateien vertraut, die von Ihren HDInsight-Clustern erzeugt werden.
Analysieren Sie als Nächstes für einen bestimmten Zeitraum die Menge der Protokolldaten an wichtigen Protokollspeicherorten. Sie können beispielsweise die Menge und die Zunahme für Zeiträume von 30, 60 oder 90 Tagen analysieren. Zeichnen Sie diese Informationen in einer Tabelle auf, oder verwenden Sie andere Tools, z.B. Visual Studio, Azure Storage-Explorer oder Power Query für Excel. ```
Sie verfügen jetzt über ausreichende Informationen zum Aufstellen einer Protokollverwaltungsstrategie für die Schlüsselprotokolle. Verwenden Sie Ihre Tabelle (bzw. das Tool Ihrer Wahl), um sowohl die Zunahme der Protokollgröße als auch die Kosten für Azure-Dienste zur Protokollspeicherung zu prognostizieren. Berücksichtigen Sie für die Gruppe der Protokolle, die Sie untersuchen, auch alle Anforderungen in Bezug auf die Protokollaufbewahrung. Sie können nun die zukünftigen Kosten für die Protokollspeicherung erneut prognostizieren, nachdem Sie ermittelt haben, welche Protokolldateien ggf. gelöscht und welche Protokolle aufbewahrt und in kostengünstigeren Azure Storage-Optionen archiviert werden können.
Schritt 5: Ermitteln der Richtlinien und Prozesse für die Protokollarchivierung
Nachdem Sie festgelegt haben, welche Protokolle gelöscht werden können, können Sie die Protokollierungsparameter für viele Hadoop-Dienste anpassen, um Protokolldateien nach einem bestimmten Zeitraum automatisch zu löschen.
Für bestimmte Protokolldateien können Sie einen kostengünstigeren Ansatz zur Archivierung von Protokolldateien verwenden. Für Azure Resource Manager-Aktivitätsprotokolle können Sie diesen Ansatz über das Azure-Portal untersuchen. Richten Sie die Archivierung der Resource Manager-Protokolle ein, indem Sie im Azure-Portal für Ihre HDInsight-Instanz den Link Aktivitätsprotokoll wählen. Wählen Sie oben auf der Seite „Aktivitätsprotokoll“ das Menüelement Exportieren, um den Bereich Aktivitätsprotokoll exportieren zu öffnen. Geben Sie an, welches Abonnement und welche Region verwendet werden sollen, ob der Export in ein Speicherkonto durchgeführt werden soll und wie viele Tage die Protokolle aufbewahrt werden sollen. In diesem Bereich können Sie auch angeben, ob ein Event Hub exportiert werden soll.
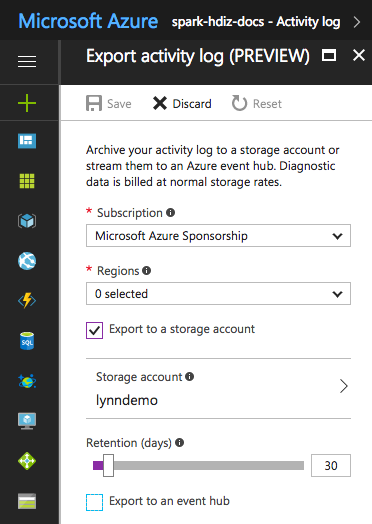
Alternativ hierzu können Sie auch mit PowerShell ein Skript für die Protokollarchivierung erstellen.
Zugreifen auf Azure Storage-Metriken
Azure Storage kann zum Protokollieren von Speichervorgängen und Zugriffen konfiguriert werden. Sie können diese ausführlichen Protokolle für die Kapazitätsüberwachung und -planung sowie für die Überwachung von Anforderungen für den Speicher verwenden. Die protokollierten Informationen enthalten auch Details zur Wartezeit, sodass Sie die Leistung Ihrer Lösungen überwachen und optimieren können. Sie können das .NET SDK für Hadoop verwenden, um die Protokolldateien zu untersuchen, die für das Azure Storage-Konto mit den Daten für einen HDInsight-Cluster generiert werden.
Steuern der Größe und Anzahl von Sicherungsindizes für alte Protokolldateien
Legen Sie die folgenden Eigenschaften des RollingFileAppender-Elements fest, um die Größe und Anzahl von aufbewahrten Protokolldateien zu steuern:
-
maxFileSizeist die kritische Größe der Datei, die nicht überschritten werden darf. Der Standardwert ist 10 MB. -
maxBackupIndexgibt die Anzahl von Sicherungsdateien an, die erstellt werden (Standardwert: 1).
Weitere Verfahren für die Protokollverwaltung
Sie können einige Betriebssystemtools, z. B. logrotate, zum Verwalten der Verarbeitung von Protokolldateien verwenden, um zu verhindern, dass nicht mehr genügend Festplattenspeicher vorhanden ist. Sie können für logrotate die tägliche Ausführung konfigurieren, um Protokolldateien zu komprimieren und alte Dateien zu entfernen. Ihre Vorgehensweise richtet sich nach Ihren Anforderungen, z.B. danach, wie lange die Protokolldateien auf lokalen Knoten aufbewahrt werden sollen.
Sie können auch überprüfen, ob die DEBUG-Protokollierung für einen oder mehrere Dienste aktiviert ist, wodurch sich die Größe der Ausgabeprotokolle stark erhöht.
Zum Sammeln der Protokolle von allen Knoten an einem zentralen Speicherort können Sie einen Datenfluss erstellen, z.B. die Erfassung aller Protokolleinträge in Solr.
Nächste Schritte
- Monitoring and Logging Practice for HDInsight (Vorgehensweise zur Überwachung und Protokollierung für HDInsight)
- Zugreifen auf Apache Hadoop YARN-Anwendungsprotokolle in Linux-basiertem HDInsight