Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Datenpipelines liegen vielen Datenanalyselösungen zugrunde. Wie der Name vermuten lässt, werden in einer Datenpipeline Rohdaten aufgenommen und dort bereinigt und nach Bedarf angepasst. Dann werden normalerweise Berechnungen oder Aggregationen ausgeführt, bevor die verarbeiteten Daten gespeichert werden. Die verarbeiteten Daten werden von Clients, Berichten oder APIs verwendet. Eine Datenpipeline muss wiederholbare Ergebnisse bereitstellen, entweder nach einem Zeitplan oder beim Auslösen durch neue Daten.
In diesem Artikel wird beschrieben, wie Sie Datenpipelines unter Verwendung von Oozie auf HDInsight Hadoop-Clustern zum Zweck der Wiederholbarkeit operationalisieren. Im Beispielszenario wird Schritt für Schritt eine Datenpipeline erläutert, mit der Flugzeitreihendaten von Fluggesellschaften vorbereitet und verarbeitet werden.
Im folgenden Szenario handelt es sich bei den Eingabedaten um ein Flatfile mit einem Batch von Flugdaten für einen Monat. Diese Flugdaten umfassen Informationen wie z.B. den Start- und Zielflughafen, die Flugkilometer, die Abflugs- und Ankunftszeiten usw. Zweck dieser Pipeline ist es, die tägliche Leistung der Fluggesellschaften zusammenzufassen, wobei in jeweils einer Zeile für jede Fluggesellschaft pro Tag die durchschnittlichen Verspätungen der Abflüge und Ankünfte in Minuten und die Gesamtflugkilometer des jeweiligen Tages aufgeführt sind.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10,142229 | 7,862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9,435449 | 5,482143 | 572289 |
| 2017 | 1 | 3 | DL | 6,935409 | –2,1893024 | 1909696 |
In der Beispielpipeline wird gewartet, bis Flugdaten für einen neuen Zeitraum eingehen. Diese detaillierten Fluginformationen werden dann für langfristige Analysen im Apache Hive-Data Warehouse gespeichert. In der Pipeline wird zudem ein wesentlich kleineres Dataset erstellt, das lediglich die täglichen Flugdaten zusammenfasst. Diese tägliche Zusammenfassung von Flugdaten wird zur Bereitstellung von Berichten (z. B. für eine Website) an eine SQL-Datenbank gesendet.
Die Beispielpipeline ist in der folgenden Abbildung dargestellt.
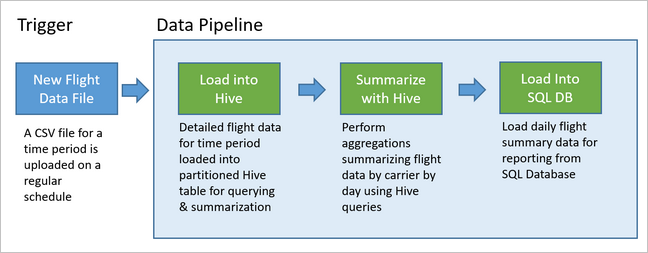
Übersicht über die Apache Oozie-Lösung
Bei dieser Pipeline wird Apache Oozie verwendet, das auf einem HDInsight Hadoop-Cluster ausgeführt wird.
In Oozie werden Pipelines in Form von Aktionen, Workflows und Koordinatoren beschrieben. Aktionen definieren die durchzuführenden Aufgaben, z.B. das Ausführen einer Hive-Abfrage. Workflows definieren die Abfolge von Aktionen. Koordinatoren definieren den Zeitplan für die Ausführung des Workflows. Koordinatoren können zudem auf die Verfügbarkeit neuer Daten warten, bevor eine Instanz des Workflows gestartet wird.
In der folgenden Abbildung ist der allgemeine Entwurf der Oozie-Beispielpipeline dargestellt.
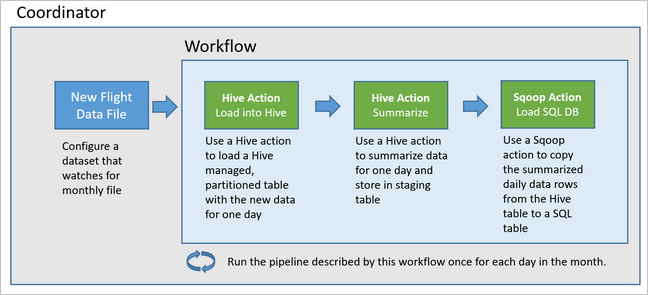
Bereitstellen von Azure-Ressourcen
Für diese Pipeline müssen eine Azure SQL-Datenbank und ein HDInsight Hadoop-Cluster am selben Speicherort vorhanden sein. In der Azure SQL-Datenbank werden die von der Pipeline generierten Zusammenfassungsdaten sowie der Oozie-Metadatenspeicher gespeichert.
Bereitstellen einer Azure SQL-Datenbank
Erstellen Sie eine Azure SQL-Datenbank-Instanz. Weitere Informationen finden Sie unter Erstellen einer Azure SQL-Datenbank im Azure-Portal.
Um sicherzustellen, dass Ihr HDInsight-Cluster auf die verbundene Azure SQL-Datenbank zugreifen kann, konfigurieren Sie Firewallregeln für die Azure SQL-Datenbank, sodass Azure-Dienste und -Ressourcen auf den Server zugreifen können. Sie können diese Option im Azure-Portal aktivieren. Wählen Sie hierzu Serverfirewall festlegen und anschließend unter Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten für die Azure SQL-Datenbank die Option EIN aus. Weitere Informationen finden Sie unter IP-Firewallregeln für Azure SQL-Datenbank und Azure SQL Data Warehouse.
Führen Sie mit dem Abfrage-Editor die folgenden SQL-Anweisungen aus, um die Tabelle
dailyflightszu erstellen, in der die zusammengefassten Daten aus jeder Ausführung der Pipeline gespeichert werden.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Die Azure SQL-Datenbank ist damit eingerichtet.
Bereitstellen eines Apache Hadoop-Clusters
Erstellen Sie einen Apache Hadoop-Cluster mit einem benutzerdefinierten Metastore. Vergewissern Sie sich während der Clustererstellung über das Portal, dass Sie auf der Registerkarte Storage unter Metastore-Einstellungen Ihre SQL-Datenbank auswählen. Weitere Informationen zum Auswählen eines Metastore finden Sie unter Auswählen eines benutzerdefinierten Metastore während der Clustererstellung. Weitere Informationen zur Clustererstellung finden Sie unter Erste Schritte mit HDInsight unter Linux.
Überprüfen des Setups des SSH-Tunnels
Richten Sie einen SSH-Tunnel zu dem HDInsight-Cluster ein, um über die Oozie-Webkonsole den Status der Koordinator- und Workflow-Instanzen anzuzeigen. Weitere Informationen finden Sie unter SSH-Tunnel.
Hinweis
Sie können auch Chrome mit der Erweiterung FoxyProxy verwenden, um die Webressourcen Ihres Clusters im SSH-Tunnel zu durchsuchen. Konfigurieren Sie sie so, dass alle Anforderungen über den Host localhost am Port 9876 des Tunnels über einen Proxy gesendet werden. Dieser Ansatz ist kompatibel mit dem Windows-Subsystem für Linux, das unter Windows 10 auch als Bash bezeichnet wird.
Führen Sie den folgenden Befehl aus, um einen SSH-Tunnel zu Ihrem Cluster zu öffnen, wobei
CLUSTERNAMEder Name Ihres Clusters ist:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netVergewissern Sie sich, dass der Tunnel betriebsbereit ist, indem Sie auf dem Hauptknoten unter folgender URL zu Ambari navigieren:
http://headnodehost:8080Für den Zugriff auf die Oozie-Webkonsole in Ambari navigieren Sie zu Oozie>Quick Links> [Aktiver Server] >Oozie Web UI (Oozie-Webbenutzeroberfläche).
Konfigurieren von Hive
Hochladen von Daten
Laden Sie eine CSV-Beispieldatei herunter, die Flugdaten für einen Monat enthält. Laden Sie die zugehörige ZIP-Datei
2017-01-FlightData.zipaus dem HDInsight-GitHub-Repository herunter, und entpacken Sie die entsprechende CSV-Datei2017-01-FlightData.csv.Kopieren Sie diese CSV-Datei in dem an den HDInsight-Cluster angefügten Azure Storage-Konto in den Ordner
/example/data/flights.Verwenden Sie SCP, um die Datei vom lokalen Computer in den lokalen Speicher des Hauptknotens Ihres HDInsight-Clusters zu kopieren.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvVerwenden Sie einen ssh-Befehl zum Herstellen der Verbindung mit dem Cluster. Bearbeiten Sie den unten angegebenen Befehl, indem Sie
CLUSTERNAMEdurch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netVerwenden Sie in Ihrer SSH-Sitzung den HDFS-Befehl, um die Datei vom lokalen Speicher des Hauptknotens in Azure Storage zu kopieren.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Erstellen von Tabellen
Die Beispieldaten sind nun verfügbar. Die Pipeline benötigt jedoch zwei Hive-Tabellen für die Verarbeitung, eine für die eingehenden Daten (rawFlights) und eine für die zusammengefassten Daten (flights). Erstellen Sie diese Tabellen wie folgt in Ambari.
Melden Sie sich bei Ambari an, indem Sie zu
http://headnodehost:8080navigieren.Wählen Sie Hive in der Liste der Dienste aus.
Wählen Sie neben Hive View 2.0 den Link Go To View (Gehe zu Ansicht) aus.
Fügen Sie im Textbereich der Abfrage die folgenden Anweisungen ein, um die Tabelle
rawFlightszu erstellen. Die TabellerawFlightsenthält ein Schema zum Lesen für die CSV-Dateien im Ordner/example/data/flightsin Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Wählen Sie Execute (Ausführen) aus, um die Tabelle zu erstellen.
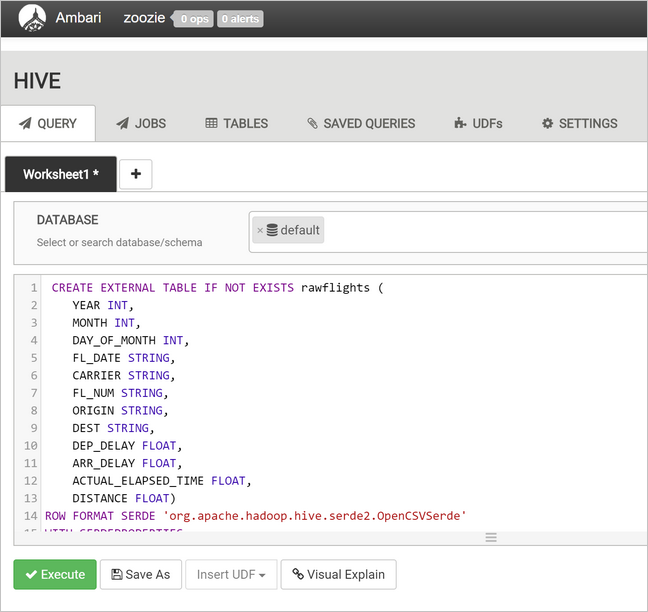
Ersetzen Sie den Text im Textbereich der Abfrage durch die folgenden Anweisungen, um die Tabelle
flightszu erstellen. Die Tabelleflightsist eine über Hive verwaltete Tabelle, in der geladene Daten nach Jahr, Monat und Tag des Monats untergliedert werden. Diese Tabelle enthält alle Verlaufsflugdaten mit einer Zeile pro Flug als kleinste in den Quelldaten vorhandene Granularitätseinheit.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Wählen Sie Execute (Ausführen) aus, um die Tabelle zu erstellen.
Erstellen des Oozie-Workflows
Pipelines verarbeiten Daten in Batches normalerweise in einem bestimmten Zeitintervall. In diesem Fall verarbeitet die Pipeline die Flugdaten täglich. Dieser Ansatz ermöglicht den täglichen, wöchentlichen, monatlichen oder jährlichen Eingang der CSV-Eingabedateien.
Der Beispielworkflow verarbeitet die Flugdaten täglich in drei Hauptschritten:
- Ausführen einer Hive-Abfrage zum Extrahieren der Daten für den Zeitraum des jeweiligen Tages aus der CSV-Quelldatei, die durch die Tabelle
rawFlightsdargestellt wird, und Einfügen der Daten in die Tabelleflights. - Ausführen einer Hive-Abfrage zum dynamischen Erstellen einer Stagingtabelle in Hive für den Tag, die eine Kopie der Flugdaten zusammengefasst nach Tag und Fluggesellschaft enthält
- Verwenden von Apache Sqoop zum Kopieren aller Daten aus der täglichen Stagingtabelle in Hive in die Zieltabelle
dailyflightsin Azure SQL-Datenbank. Sqoop liest die Quellzeilen aus den Daten aus der Hive-Tabelle in Azure Storage und lädt sie über eine JDBC-Verbindung in SQL-Datenbank.
Diese drei Schritte werden von einem Oozie-Workflow koordiniert.
Erstellen Sie auf Ihrer lokalen Arbeitsstation eine Datei namens
job.properties. Verwenden Sie den folgenden Text als Anfangsinhalt für die Datei. Aktualisieren Sie dann die Werte entsprechend Ihrer jeweiligen Umgebung. In der Tabelle unterhalb des Texts sind die einzelnen Eigenschaften zusammengefasst. Außerdem ist angegeben, wo Sie die Werte für Ihre eigene Umgebung finden.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Eigenschaft Wertquelle nameNode Der vollständige Pfad zu dem Azure Storage-Container, der an den HDInsight-Cluster angefügt ist. jobTracker Der interne Hostname für den YARN-Hauptknoten des aktiven Clusters. Wählen Sie auf der Ambari-Startseite YARN in der Liste der Dienste und dann „Active Resource Manager“ (Aktiver Ressourcen-Manager) aus. Der URI des Hostnamens wird oben auf der Seite angezeigt. Fügen Sie den Port 8050 an. queueName Der Name der YARN-Warteschlange, die bei der Planung der Hive-Aktionen verwendet wird. Behalten Sie den Standard bei. oozie.use.system.libpath Behalten Sie „true“ bei. appBase Der Pfad zu dem Unterordner in Azure Storage, in dem Sie den Oozie-Workflow und die unterstützenden Dateien bereitstellen. oozie.wf.application.path Der Speicherort des auszuführenden Oozie-Workflows workflow.xml.hiveScriptLoadPartition Der Pfad in Azure Storage zu der Hive-Abfragedatei hive-load-flights-partition.hql.hiveScriptCreateDailyTable Der Pfad in Azure Storage zu der Hive-Abfragedatei hive-create-daily-summary-table.hql.hiveDailyTableName Der dynamisch generierte Name für die Stagingtabelle. hiveDataFolder Der Pfad in Azure Storage zu den in der Stagingtabelle enthaltenen Daten. sqlDatabaseConnectionString Die Verbindungszeichenfolge in JDBC-Syntax zu Ihrer Azure SQL-Datenbank. sqlDatabaseTableName Der Name der Tabelle in Azure SQL-Datenbank, in die Zusammenfassungszeilen eingefügt werden. Behalten Sie dailyflightsbei.year Die Jahreskomponente des Tages, für den Flugzusammenfassungen berechnet werden. Nehmen Sie keine Änderung vor. month Die Monatskomponente des Tages, für den Flugzusammenfassungen berechnet werden. Nehmen Sie keine Änderung vor. day Die Monatstagkomponente des Tages, für den Flugzusammenfassungen berechnet werden. Nehmen Sie keine Änderung vor. Erstellen Sie auf Ihrer lokalen Arbeitsstation eine Datei namens
hive-load-flights-partition.hql. Fügen Sie den folgenden Code als Inhalt der Datei ein.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie-Variablen verwenden die Syntax
${variableName}. Diese Variablen werden in der Dateijob.propertiesfestgelegt. Oozie ersetzt die tatsächlichen Werte zur Laufzeit.Erstellen Sie auf Ihrer lokalen Arbeitsstation eine Datei namens
hive-create-daily-summary-table.hql. Fügen Sie den folgenden Code als Inhalt der Datei ein.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Diese Abfrage erstellt eine Stagingtabelle, in der nur die zusammengefassten Daten für einen Tag gespeichert werden. Beachten Sie die SELECT-Anweisung, mit der die durchschnittlichen Verspätungen und die Gesamtflugkilometer pro Fluggesellschaft pro Tag berechnet werden. Die in diese Tabelle eingefügten Daten werden an einem bekannten Speicherort (dem Pfad, der durch die Variable „hiveDataFolder“ angegeben wird) gespeichert, sodass sie im nächsten Schritt als Quelle für Sqoop verwendet werden können.
Erstellen Sie auf Ihrer lokalen Arbeitsstation eine Datei namens
workflow.xml. Fügen Sie den folgenden Code als Inhalt der Datei ein. Diese obigen Schritte werden in der Oozie-Workflowdatei als separate Aktionen ausgedrückt.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Der Zugriff auf die zwei Hive-Abfragen erfolgt über ihren jeweiligen Pfad in Azure Storage. Die übrigen Variablenwerte sind in der Datei job.properties angegeben. Mit dieser Datei wird der Workflow so konfiguriert, dass er für den 3. Januar 2017 ausgeführt wird.
Bereitstellen und Ausführen des Oozie-Workflows
Verwenden Sie SCP aus der Bash-Sitzung, um Ihren Oozie-Workflow (workflow.xml), die Hive-Abfragen (hive-load-flights-partition.hql und hive-create-daily-summary-table.hql) und die Auftragskonfiguration (job.properties) bereitzustellen. In Oozie kann nur die Datei job.properties im lokalen Speicher des Hauptknotens vorhanden sein. Alle anderen Dateien müssen in HDFS gespeichert werden, in diesem Fall Azure Storage. Die im Workflow verwendete Sqoop-Aktion hängt von einem JDBC-Treiber für die Kommunikation mit der SQL-Datenbank ab, der vom Hauptknoten in HDFS kopiert werden muss.
Erstellen Sie den Unterordner
load_flights_by_dayunterhalb des Pfads des Benutzers im lokalen Speicher des Hauptknotens. Führen Sie aus Ihrer geöffneten SSH-Sitzung den folgenden Befehl aus:mkdir load_flights_by_dayKopieren Sie alle Dateien im aktuellen Verzeichnis (die Dateien
workflow.xmlundjob.properties) in den Unterordnerload_flights_by_day. Führen Sie auf Ihrer lokalen Arbeitsstation den folgenden Befehl aus:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayKopieren Sie Workflowdateien in HDFS. Führen Sie aus Ihrer geöffneten SSH-Sitzung die folgenden Befehle aus:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayKopieren Sie
mssql-jdbc-7.0.0.jre8.jarvom lokalen Hauptknoten in den Workflowordner in HDFS. Falls Ihr Cluster eine andere JAR-Datei enthält, überarbeiten Sie den Befehl entsprechend. Ändern Sieworkflow.xmlnach Bedarf, um eine andere JAR-Datei widerzuspiegeln. Führen Sie aus Ihrer geöffneten SSH-Sitzung den folgenden Befehl aus:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayFühren Sie den Workflow aus. Führen Sie aus Ihrer geöffneten SSH-Sitzung den folgenden Befehl aus:
oozie job -config job.properties -runÜberprüfen Sie den Status über die Oozie-Webkonsole. Wählen Sie in Ambari die Optionen Oozie, Quick Links und dann Oozie Web Console (Oozie-Webkonsole) aus. Wählen Sie auf der Registerkarte Workflow Jobs (Workflowaufträge) die Option All Jobs (Alle Aufträge) aus.
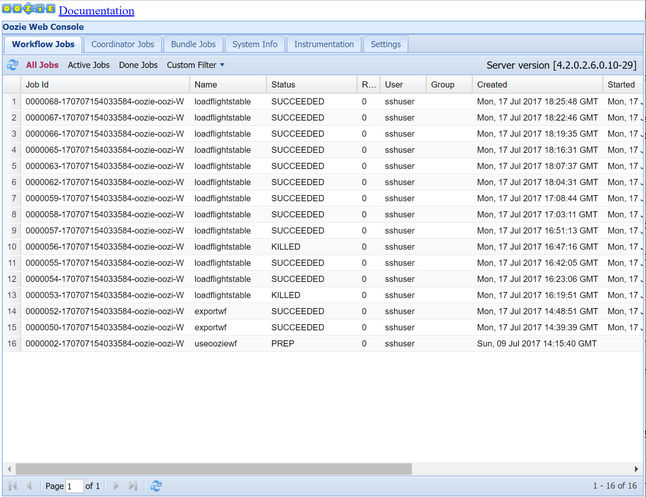
Wenn der Status SUCCEEDED (Erfolgreich) angegeben ist, fragen Sie die SQL-Datenbanktabelle ab, um die eingefügten Zeilen anzuzeigen. Navigieren Sie im Azure-Portal zum Bereich für die SQL-Datenbank, wählen Sie Tools aus, und öffnen Sie den Abfrage-Editor.
SELECT * FROM dailyflights
Der Workflow für den einzelnen Testtag wird damit ausgeführt. Sie können diesen Workflow nun mit einem Koordinator umschließen, der den Workflow so plant, dass er täglich ausgeführt wird.
Ausführen des Workflows mit einem Koordinator
Um den Workflow so zu planen, dass er täglich (oder an allen Tagen in einem bestimmten Zeitraum) ausgeführt wird, können Sie einen Koordinator verwenden. Ein Koordinator wird durch eine XML-Datei definiert, z.B. coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Wie Sie sehen können, übergibt der Koordinator mehrheitlich lediglich Konfigurationsinformationen an die Workflowinstanz. Es sind jedoch einige wichtige Punkte hervorzuheben.
Punkt 1: Die Attribute
startundendfür das Elementcoordinator-appsteuern das Zeitintervall, für das der Koordinator ausgeführt wird.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Ein Koordinator ist zuständig für die Planung von Aktionen innerhalb des Zeitraums von
startbisendentsprechend dem durch das Attributfrequencyangegebene Intervall. Jede geplante Aktion führt wiederum den Workflow wie konfiguriert aus. In der oben aufgeführten Koordinatordefinition ist der Koordinator für die Ausführung von Aktionen vom 1. Januar 2017 bis zum 5. Januar 2017 konfiguriert. Die Häufigkeit ist durch den Häufigkeitsausdruck${coord:days(1)}der Oozie-Ausdruckssprache auf einen Tag festgelegt. Dies führt dazu, dass der Koordinator eine Aktion (und somit den Workflow) einmal pro Tag plant. Bei Zeiträumen, die wie in diesem Beispiel in der Vergangenheit liegen, wird die Aktion so geplant, dass sie ohne Verzögerung ausgeführt wird. Der Beginn des Datums, ab dem eine Aktion zur Ausführung geplant ist, wird als nominelle Zeit bezeichnet. Zur Verarbeitung der Daten für den 1. Januar 2017 plant der Koordinator die Aktion beispielsweise mit der nominellen Zeit 2017-01-01T00:00:00 GMT.Punkt 2: Innerhalb des Zeitraums des Workflows gibt das Element
datasetan, wo in HDFS nach den Daten für einen bestimmten Datumsbereich gesucht wird, und konfiguriert, wie Oozie ermittelt, ob die Daten zur Verarbeitung verfügbar sind.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Der Pfad zu den Daten in HDFS wird entsprechend dem im Element
uri-templateangegebenen Ausdruck dynamisch erstellt. In diesem Koordinator wird die Häufigkeit von einem Tag auch für das Dataset verwendet. Während mit dem Start- und dem Enddatum für das Koordinatorelement gesteuert wird, zu welchem Zeitpunkt die Aktionen geplant werden (und die jeweils nominelle Zeit definiert wird), steuerninitial-instanceundfrequencyfür das Dataset die Berechnung des Datums, das beim Erstellen vonuri-templateverwendet wird. Legen Sie in diesem Fall die erste Instanz auf einen Tag vor dem Beginn des Koordinators fest, um sicherzustellen, dass dieser die Daten des ersten Tages (1. Januar 2017) abruft. Für die Berechnung der Daten des Datasets wird ab dem Wert voninitial-instance(31.12.2016) ein Rollforward in den Häufigkeitsschritten für das Dataset (ein Tag) ausgeführt, bis das letzte Datum gefunden wird, an dem die vom Koordinator festgelegte nominelle Zeit (2017-01-01T00:00:00 GMT für die erste Aktion) nicht übergeben wird.Das leere Element
done-flaggibt an, dass wenn Oozie das Vorhandensein von Eingabedaten zum festgesetzten Zeitpunkt prüft, verfügbare Daten anhand des Vorhandenseins eines Verzeichnisses oder einer Datei ermittelt werden. In diesem Fall ist es das Vorhandensein einer CSV-Datei. Wenn eine CSV-Datei vorhanden ist, wird in Oozie davon ausgegangen, dass die Daten bereit sind. Dann wird eine Workflowinstanz zum Verarbeiten der Datei gestartet. Wenn keine CSV-Datei vorhanden ist, wird in Oozie davon ausgegangen, dass die Datei noch nicht bereit ist, und der Workflow wechselt in einen Wartestatus.Punkt 3: Das Element
data-ingibt den spezifischen Zeitstempel an, der beim Ersetzen der Werte inuri-templatefür das verknüpfte Dataset als nominelle Zeit zu verwenden ist.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>Legen Sie in diesem Fall die Instanz auf den Ausdruck
${coord:current(0)}fest, sodass die nominelle Zeit der Aktion wie ursprünglich vom Koordinator geplant verwendet wird. Anders gesagt: Wenn der Koordinator die Aktion zur Ausführung mit der nominellen Zeit 01.01.2017 plant, dann wird 01.01.2017 zum Ersetzen der Variablen „YEAR“ (2017) und „MONTH“ (01) in der URI-Vorlage verwendet. Nachdem die URI-Vorlage für diese Instanz berechnet wurde, überprüft Oozie, ob das erwartete Verzeichnis oder die erwartete Datei verfügbar ist, und plant die nächste Ausführung des Workflows entsprechend.
Die Kombination dieser drei Punkte führt dazu, dass der Koordinator die tägliche Verarbeitung der Quelldaten plant.
Punkt 1: Der Koordinator beginnt mit dem nominellen Datum 01.01.2017.
Punkt 2: Oozie sucht nach verfügbaren Daten in der Datei
sourceDataFolder/2017-01-FlightData.csv.Punkt 3: Wenn Oozie diese Datei findet, wird eine Instanz des Workflows geplant, die die Daten für den 1. Januar 2017 verarbeitet. Anschließend setzt Oozie die Verarbeitung für 02.01.2017 fort. Diese Auswertung wird bis 05.01.2017 wiederholt, jedoch nicht einschließlich dieses Datums.
Wie bei Workflows wird die Konfiguration eines Koordinators in einer Datei des Typs job.properties definiert, die eine Obermenge der vom Workflow verwendeten Einstellungen enthält.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
In dieser Datei job.properties sind lediglich die folgenden neuen Eigenschaften enthalten:
| Eigenschaft | Wertquelle |
|---|---|
| oozie.coord.application.path | Gibt den Speicherort der Datei coordinator.xml an, die den auszuführenden Oozie-Koordinator enthält. |
| hiveDailyTableNamePrefix | Das beim dynamischen Erstellen des Tabellennamens der Stagingtabelle verwendete Präfix. |
| hiveDataFolderPrefix | Das Präfix des Pfads, in dem alle Stagingtabellen gespeichert werden. |
Bereitstellen und Ausführen des Oozie-Koordinators
Zum Ausführen der Pipeline mit einem Koordinator gehen Sie in ähnlicher Weise wie für den Workflow vor, mit der Ausnahme, dass Sie einen Ordner verwenden, der sich eine Ebene über dem Ordner mit dem Workflow befindet. Durch diese die Ordner betreffende Konvention sind die Koordinatoren auf dem Datenträger von den Workflows getrennt, sodass ein Koordinator mit unterschiedlichen untergeordneten Workflows verknüpft werden kann.
Verwenden Sie SCP auf dem lokalen Computer, um die Koordinatordateien in den lokalen Speicher des Hauptknotens Ihres Clusters zu kopieren.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Stellen Sie eine SSH-Verbindung mit dem Hauptknoten her.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netKopieren Sie die Koordinatordateien in HDFS.
hdfs dfs -put ./* /oozie/Führen Sie den Koordinator aus.
oozie job -config job.properties -runÜberprüfen Sie den Status über die Oozie-Webkonsole. Wählen Sie dieses Mal die Registerkarte Coordinator Jobs (Koordinatoraufträge) und dann All Jobs (Alle Aufträge) aus.
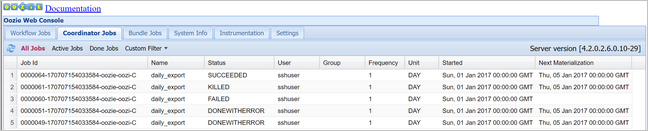
Wählen Sie eine Koordinatorinstanz aus, um die Liste der geplanten Aktionen anzuzeigen. In diesem Fall sollten vier Aktionen mit nominellen Zeiten im Zeitraum vom 1. Januar 2017 bis zum 4. Januar 2017 angezeigt werden.
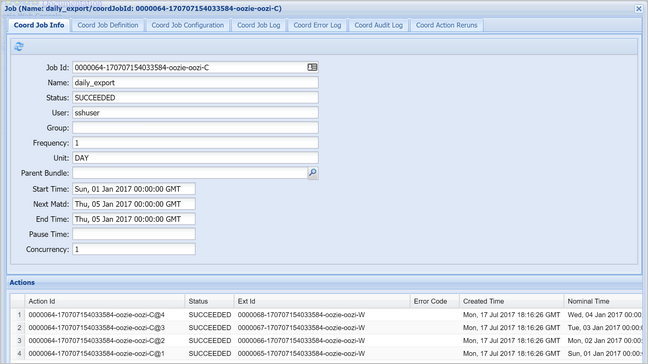
Jede Aktion in dieser Liste entspricht einer Instanz des Workflows, die die Daten eines Tages verarbeitet, wobei der Beginn des jeweiligen Tages durch die nominelle Zeit angegeben wird.