Apache Phoenix in Azure HDInsight
Apache Phoenix ist eine relationale Open-Source-Datenbankschicht mit hochgradig parallelisierter Verarbeitung, die auf Apache HBase basiert. Mit Phoenix können Sie SQL-ähnliche Abfragen per HBase verwenden. Phoenix nutzt im Hintergrund JDBC-Treiber, um Benutzern das Erstellen, Löschen und Ändern von SQL-Tabellen, -Indizes, -Sichten und -Sequenzen sowie das Durchführen des Upsert-Vorgangs für Zeilen einzeln oder als Massenvorgang zu ermöglichen. Für Phoenix wird anstelle von MapReduce die native NoSQL-Kompilierung verwendet, um Abfragen zu kompilieren und so basierend auf HBase die Erstellung von Anwendungen mit geringer Wartezeit zu ermöglichen. Phoenix fügt Coprozessoren hinzu, um das Ausführen von per Client bereitgestelltem Code im Adressraum des Servers zu unterstützen und den Code auszuführen, der den Daten beigefügt ist. Mit diesem Ansatz kann der Aufwand für die Datenübertragung zwischen Client und Server reduziert werden.
Apache Phoenix eröffnet auch anderen Personen als Entwicklern die Nutzung von Big Data-Abfragen, indem anstelle einer Programmierung eine SQL-ähnliche Syntax eingesetzt wird. Im Gegensatz zu anderen Tools wie Apache Hive und Apache Spark SQL ist Phoenix stark für HBase optimiert. Der Vorteil für Entwickler ist die Möglichkeit zum Schreiben von äußerst leistungsfähigen Abfragen mit deutlich weniger Code.
Wenn Sie eine SQL-Abfrage übermitteln, kompiliert Phoenix die Abfrage in native HBase-Aufrufe und führt den Scanvorgang (oder Plan) parallel aus, um eine Optimierung zu erzielen. Dank dieser Abstraktionsebene muss der Entwickler keine MapReduce-Aufträge schreiben und kann sich stattdessen auf die Geschäftslogik und den Workflow der Anwendung im Zusammenhang mit der Big Data-Speicherung für Phoenix konzentrieren.
Optimierung der Abfrageleistung und andere Features
Mit Apache Phoenix werden für HBase-Abfragen mehrere Leistungsverbesserungen und Features hinzugefügt.
Sekundäre Indizes
HBase verfügt über einen einzelnen Index, der lexikografisch nach dem primären Zeilenschlüssel sortiert ist. Auf diese Datensätze kann nur über den Zeilenschlüssel zugegriffen werden. Für den Zugriff auf Datensätze über eine andere Spalte als den Zeilenschlüssel ist das Scannen aller Daten erforderlich, während der benötigte Filter angewendet wird. In einem sekundären Index bilden die Spalten oder Ausdrücke, die indiziert werden, einen alternativen Zeilenschlüssel, sodass Suchen und Bereichsscans für diesen Index möglich sind.
Erstellen Sie mit dem Befehl CREATE INDEX einen sekundären Index:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Dieser Ansatz kann zu einer erheblichen Leistungssteigerung bei der Ausführung von Abfragen mit nur einem Index führen. Dieser sekundäre Index ist ein Index mit vollständiger Abdeckung und enthält alle Spalten, die Teil der Abfrage sind. Aus diesem Grund ist die Tabellensuche nicht erforderlich, und der Index deckt die gesamte Abfrage ab.
Ansichten
Phoenix-Ansichten können eine HBase-Einschränkung überwinden, bei der sich die Leistung zunehmend verschlechtert, wenn Sie mehr als ca. 100 physische Tabellen erstellen. Bei Phoenix-Ansichten können mehrere virtuelle Tabellen eine zugrunde liegende physische HBase-Tabelle gemeinsam nutzen.
Die Erstellung einer Phoenix-Ansicht ähnelt der Verwendung der Standardsyntax für SQL-Ansichten. Ein Unterschied besteht darin, dass Sie zusätzlich zu den Spalten, die von der dazugehörigen Basistabelle geerbt werden, weitere Spalten für Ihre Ansicht definieren können. Außerdem können Sie neue KeyValue-Spalten hinzufügen.
Hier ist beispielsweise eine physische Tabelle mit dem Namen product_metrics und der folgenden Definition angegeben:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Definieren Sie eine Ansicht für diese Tabelle mit zusätzlichen Spalten:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Verwenden Sie die ALTER VIEW-Anweisung, um später weitere Spalten hinzuzufügen.
Scan überspringen
Bei „Scan überspringen“ werden eine oder mehrere Spalten eines zusammengesetzten Index verwendet, um einzelne Werte zu finden. Im Gegensatz zu einem Bereichsscan wird bei „Scan überspringen“ das zeileninterne Scannen implementiert, um eine Leistungsverbesserung zu erzielen. Beim Scanvorgang wird der erste übereinstimmende Wert zusammen mit dem Index übersprungen, bis der nächste Wert gefunden wurde.
Für „Scan überspringen“ wird die Enumeration SEEK_NEXT_USING_HINT des HBase-Filters verwendet. Mithilfe von SEEK_NEXT_USING_HINT wird bei „Scan überspringen“ nachverfolgt, nach welchen Schlüsseln bzw. Schlüsselbereichen in den einzelnen Spalten gesucht wird. Für den Vorgang „Scan überspringen“ wird dann ein Schlüssel verwendet, der während der Filterauswertung übergeben wurde, und ermittelt, ob sich eine Übereinstimmung für eine der Kombinationen ergibt. Wenn nicht, wertet „Scan überspringen“ den nächsthöheren Schlüssel aus, zu dem gesprungen wird.
Transaktionen
Während für HBase Transaktionen auf Zeilenebene bereitgestellt werden, wird für Phoenix eine Integration in Tephra durchgeführt, um Unterstützung für zeilen- und tabellenübergreifende Transaktionen mit vollständiger ACID-Semantik hinzuzufügen.
Wie bei herkömmlichen SQL-Transaktionen auch, können Sie mit den per Phoenix-Transaktions-Manager bereitgestellten Transaktionen sicherstellen, dass für eine Atomeinheit der Daten ein erfolgreicher Upsert-Vorgang durchgeführt wird. Für die Transaktion erfolgt ein Rollback, falls der Upsert-Vorgang für eine transaktionsfähige Tabelle fehlschlägt.
Informationen zur Aktivierung von Phoenix-Transaktionen finden Sie in der Dokumentation zu Apache Phoenix-Transaktionen.
Legen Sie die TRANSACTIONAL-Eigenschaft in einer CREATE-Anweisung auf true fest, um eine neue Tabelle mit aktivierten Transaktionen zu erstellen:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Verwenden Sie die gleiche Eigenschaft in einer ALTER-Anweisung, um eine vorhandene Tabelle transaktionsfähig zu machen:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Hinweis
Es ist nicht möglich, eine transaktionsfähige Tabelle wieder in eine nicht transaktionsfähige Tabelle umzuwandeln.
Tabellen mit Salting
Regionsserver-Hotspotting kann beim Schreiben von Datensätzen mit sequenziellen Schlüsseln in HBase auftreten. Auch wenn in Ihrem Cluster ggf. mehrere Regionsserver vorhanden sind, werden Ihre Schreibvorgänge nur auf einem Server durchgeführt. Bei dieser Konzentration kommt es zum Hotspotting-Problem, da die Schreibworkload nicht auf alle verfügbaren Regionsserver verteilt wird, sondern nur von einem Server abgearbeitet wird. Da jede Region über eine vordefinierte maximale Größe verfügt, wird eine Region jeweils in zwei kleine Regionen geteilt, wenn sie diese Größenbegrenzung erreicht. In diesem Fall übernimmt eine der neuen Regionen alle neuen Datensätze und wird zum neuen Hotspot.
Sie können Tabellen vorab teilen, damit alle Regionsserver in gleichem Maße verwendet werden, um dieses Problem zu beheben und eine bessere Leistung zu erzielen. Unter Phoenix werden Tabellen mit Salting bereitgestellt, indem das Salting-Byte dem Zeilenschlüssel für eine bestimmte Tabelle hinzugefügt wird. Die Tabelle wird vorab gemäß den Salting-Byte-Grenzen geteilt, um während der ersten Phase der Tabelle eine gleichmäßige Ladeverteilung für die Regionsserver sicherzustellen. Bei diesem Ansatz wird die Schreibworkload auf alle verfügbaren Regionsserver verteilt, um die Schreib- und Leseleistung zu verbessern. Geben Sie die SALT_BUCKETS-Tabelleneigenschaft bei der Erstellung der Tabelle an, um für eine Tabelle das Salting festzulegen:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Aktivieren und Optimieren von Phoenix mit Apache Ambari
Ein HDInsight HBase-Cluster enthält die Ambari-Benutzeroberfläche zum Vornehmen von Konfigurationsänderungen.
Melden Sie sich an der Ambari-Webbenutzeroberfläche (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) mit Ihren Hadoop-Benutzeranmeldeinformationen an, um Phoenix zu aktivieren bzw. zu deaktivieren und die Abfragetimeouteinstellungen für Phoenix zu steuern.Wählen Sie im Menü auf der linken Seite in der Liste mit den Diensten den Eintrag HBase und dann die Registerkarte Configs (Konfigurationen).
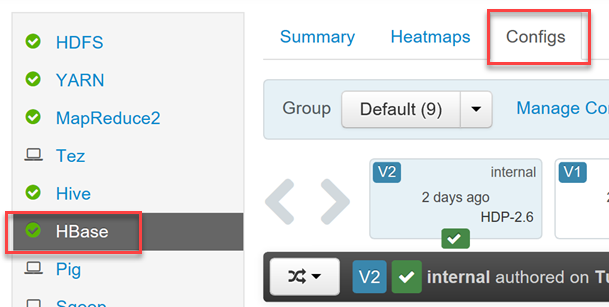
Suchen Sie nach dem Abschnitt für die Konfiguration von Phoenix SQL, um Phoenix zu aktivieren bzw. zu deaktivieren und das Abfragetimeout festzulegen.