Manuelles Skalieren von Azure HDInsight-Clustern
Mit der Option, die Anzahl der Workerknoten in Ihren Clustern zentral hoch- und herunterskalieren zu können, ermöglicht Ihnen HDInsight ein hohes Maß an Flexibilität. Dadurch können Sie etwa einen Cluster nach den Geschäftszeiten oder am Wochenende verkleinern. In Zeiten von Spitzenbelastungen können Sie ihn hingegen erweitern.
Skalieren Sie den Cluster vor einer regelmäßigen Batchverarbeitung zentral hoch, damit ausreichend Ressourcen zur Verfügung stehen. Bei sinkender Nutzung nach Abschluss der Verarbeitung können Sie den HDInsight-Cluster auf eine kleinere Anzahl von Workerknoten zentral herunterskalieren.
Sie können einen Cluster manuell mithilfe einer der folgenden Methoden skalieren. Oder Sie verwenden die Optionen zur Autoskalierung, um anhand bestimmter Metriken eine automatische vertikale Skalierung durchzuführen.
Hinweis
Es werden nur Cluster mit HDInsight-Versionen ab 3.1.3 unterstützt. Überprüfen Sie ggf. auf der Seite „Eigenschaften“ die Version Ihres Clusters.
Hilfsprogramme zum Skalieren von Clustern
Microsoft bietet die folgenden Hilfsprogramme für das Skalieren von Clustern:
| Hilfsprogramm | BESCHREIBUNG |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Klassische Azure-Befehlszeilenschnittstelle | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure portal | Öffnen Sie Ihren HDInsight-Clusterbereich, wählen Sie im linken Menü Clustergröße aus, geben Sie dann im Bereich „Clustergröße“ die Anzahl der Workerknoten ein, und wählen Sie „Speichern“ aus. |
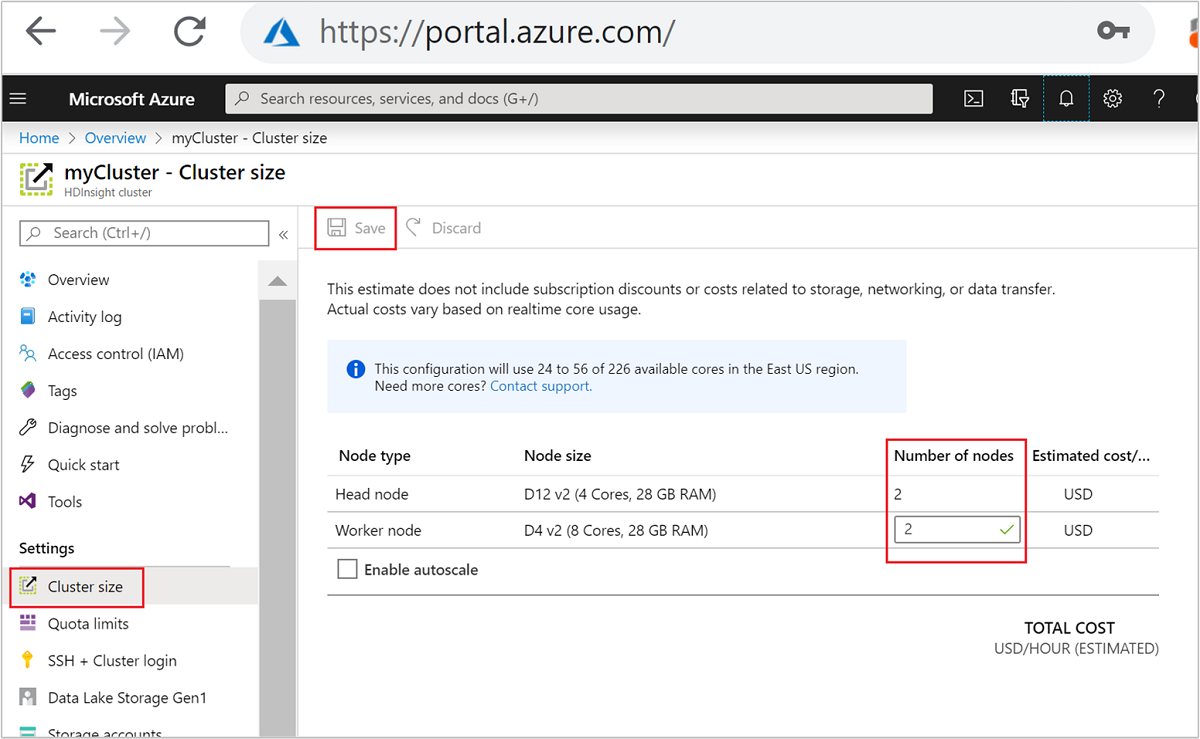
Mit jeder dieser Methoden können Sie Ihren HDInsight-Cluster innerhalb von Minuten zentral hoch- oder herunterskalieren.
Wichtig
- Die klassische Azure-Befehlszeilenschnittstelle ist veraltet und sollte nur mit dem klassischen Bereitstellungsmodell verwendet werden. Verwenden Sie für alle anderen Bereitstellungen die Azure-Befehlszeilenschnittstelle.
- Das PowerShell-AzureRM-Modul ist veraltet. Verwenden Sie wenn möglich das Az-Modul.
Auswirkungen von Skalierungsvorgängen
Wenn Sie Ihrem ausgeführten HDInsight-Cluster Knoten hinzufügen (Hochskalieren), hat dies keine Auswirkungen auf Aufträge. Neue Aufträge können sicher übermittelt werden, während der Skalierungsprozess ausgeführt wird. Tritt bei der Skalierung ein Fehler auf, bleibt der Cluster weiterhin funktionsfähig.
Wenn Sie Knoten entfernen (Herunterskalieren), treten bei ausstehenden oder ausgeführten Aufträgen Fehler auf, wenn der Skalierungsvorgang abgeschlossen ist. Das liegt daran, dass einige Dienste während des Skalierungsvorgangs neu gestartet werden. Während eines manuellen Skalierungsvorgangs kann der Cluster im abgesicherten Modus hängen bleiben.
Auswirkungen der Änderung der Anzahl von Datenknoten variieren für die von HDInsight unterstützten Clustertypen:
Apache Hadoop
Sie können die Anzahl der Workerknoten in einem ausgeführten Hadoop-Cluster problemlos und ohne Auswirkungen auf die Aufträge erhöhen. Neue Aufträge können auch während des Vorgangs gesendet werden. Fehler, die während eines Skalierungsvorgangs auftreten, werden ordnungsgemäß behandelt. So bleibt der Cluster immer funktionsfähig.
Wird ein Hadoop-Cluster auf weniger Datenknoten zentral herunterskaliert, werden einige Dienste neu gestartet. Dieses Verhalten führt beim Abschluss des Skalierungsvorgangs bei allen aktiven und ausstehenden Aufträgen zu einem Fehler. Sie können die Aufträge jedoch nach Abschluss des Vorgangs erneut senden.
Apache HBase
Sie können Knoten problemlos Ihrem HBase-Cluster während der Ausführung hinzufügen oder aus diesem entfernen. Regionale Server werden innerhalb weniger Minuten nach Abschluss des Skalierungsvorgangs automatisch ausgeglichen. Sie können die regionalen Server jedoch auch manuell ausgleichen. Melden Sie sich beim Hauptknoten des Clusters an, und führen Sie die folgenden Befehle aus:
pushd %HBASE_HOME%\bin hbase shell balancerWeitere Informationen zur Verwendung von HBase-Shell finden Sie unter Erste Schritte mit einem Apache HBase-Beispiel in HDInsight.
Hinweis
Nicht anwendbar für Kafka-Cluster.
Apache Hive-LLAP
Nachdem die Skalierung auf
N-Workerknoten erfolgt ist, werden die folgenden Konfigurationen von HDInsight automatisch festgelegt und Hive neu gestartet.- Maximale Anzahl gleichzeitiger Abfragen:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Anzahl der von Hive LLAP verwendeten Knoten:
num_llap_nodes = N - Anzahl der Knoten für die Ausführung des Hive LLAP-Daemons:
num_llap_nodes_for_llap_daemons = N
- Maximale Anzahl gleichzeitiger Abfragen:
Sicheres zentrales Herunterskalieren eines Clusters
Zentrales Herunterskalieren eines Clusters mit ausgeführten Aufträgen
Um zu vermeiden, dass bei ausgeführten Aufträgen bei einem Vorgang zum zentralen Herunterskalieren Fehler auftreten, können Sie drei Möglichkeiten ausprobieren:
- Warten Sie, bis die Aufträge abgeschlossen sind, bevor Sie den Cluster zentral herunterskalieren.
- Beenden Sie die Aufträge manuell.
- Übermitteln Sie die Aufträge nach Abschluss des Skalierungsvorgangs erneut.
Um eine Liste der ausstehenden und ausgeführten Aufträge anzuzeigen, können Sie mit folgenden Schritten die YARN Resource Manager-Benutzeroberfläche verwenden:
Wählen Sie im Azure-Portal Ihren Cluster aus. Der Cluster wird auf einer neuen Portalseite geöffnet.
Navigieren Sie in der Hauptansicht zu Clusterdashboards>Ambari-Startseite. Geben Sie Ihre Clusteranmeldeinformationen ein.
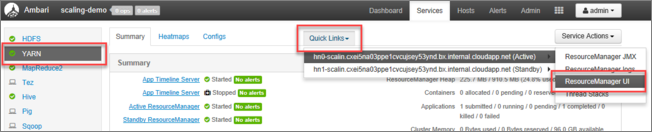
Wählen Sie auf der Benutzeroberfläche von Ambari in der Liste mit den Diensten im linken Menü YARN aus.
Wählen Sie auf der Seite „YARN“ die Option Quicklinks aus. Zeigen Sie auf den aktiven Hauptknoten, und klicken Sie auf Resource Manager-Benutzeroberfläche.
Über den folgenden Link können Sie direkt auf die Resource Manager-Benutzeroberfläche zugreifen: https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Eine Liste der Aufträge wird zusammen mit ihren aktuellen Status angezeigt. Im Screenshot wird derzeit ein Auftrag ausgeführt:
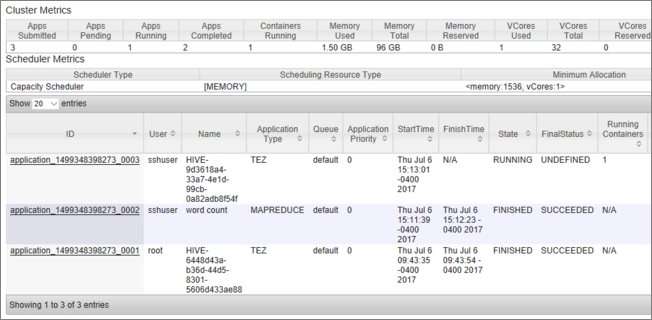
Um die ausgeführte Anwendung manuell zu beenden, führen Sie den folgenden Befehl der SSH-Shell aus:
yarn application -kill <application_id>
Beispiel:
yarn application -kill "application_1499348398273_0003"
Hängenbleiben im abgesicherten Modus
Wenn Sie einen Cluster zentral herunterskalieren, werden in HDInsight Apache Ambari-Verwaltungsoberflächen verwendet, um zunächst die zusätzlichen Workerknoten außer Betrieb zu setzen. Diese replizieren ihre HDFS-Blöcke auf andere Workerknoten, die online sind. Anschließend wird der Cluster in HDInsight sicher zentral herunterskaliert. HDFS wechselt während des Skalierungsvorgangs in den abgesicherten Modus. Nach Abschluss der Skalierung sollte HDFS den abgesicherten Modus wieder beenden. In einigen Fällen bleibt HDFS jedoch aufgrund der Unterreplikation des Dateiblocks während eines Skalierungsvorgangs im abgesicherten Modus hängen.
Standardmäßig ist HDFS mit der dfs.replication-Einstellung 1 konfiguriert, mit der gesteuert wird, wie viele Kopien jedes Dateiblocks verfügbar sind. Jede Kopie eines Dateiblocks wird auf einem unterschiedlichen Knoten des Clusters gespeichert.
Ist die erwartete Anzahl von kopierten Dateiblöcken nicht verfügbar, wechselt HDFS in den abgesicherten Modus, und in Ambari werden Warnungen generiert. Während eines Skalierungsvorgangs wechselt HDFS möglicherweise in den abgesicherten Modus. Wird die für die Replikation erforderliche Anzahl von Knoten nicht erkannt, kann der Cluster im abgesicherten Modus hängen bleiben.
Beispiel für Fehler bei aktiviertem abgesichertem Modus
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Sie können die Namensknotenprotokolle aus dem /var/log/hadoop/hdfs/-Ordner überprüfen, die nahe am Zeitpunkt der Clusterskalierung liegen, um festzustellen, wann der Wechsel in den abgesicherten Modus erfolgte. Die Protokolldateien werden mit Hadoop-hdfs-namenode-<active-headnode-name>.* benannt.
Dies liegt hauptsächlich daran, dass Hive während der Ausführung von Abfragen von temporären Dateien in HDFS abhängig ist. Wenn HDFS in den abgesicherten Modus wechselt, kann Hive keine Abfragen ausführen, da es nicht in HDFS schreiben kann. Die temporären Dateien in HDFS befinden sich auf dem lokalen Laufwerk, das in die einzelnen virtuellen Computer der Workerknoten eingebunden ist. Die Dateien werden mit mindestens drei Replikaten zwischen anderen Workerknoten repliziert.
Verhindern, dass HDInsight im abgesicherten Modus hängen bleibt
Es gibt mehrere Möglichkeiten, zu verhindern, dass HDInsight im abgesicherten Modus hängen bleibt:
- Beenden Sie alle Hive-Aufträge, bevor Sie HDInsight zentral herunterskalieren. Alternativ können Sie das zentrale Herunterskalieren planen, um Konflikte mit der Ausführung von Hive-Aufträgen zu verhindern.
- Bereinigen Sie vor dem zentralen Herunterskalieren manuell die
tmp-Scratchverzeichnisdateien von Hive in HDFS. - Skalieren Sie HDInsight nur auf minimal drei Workerknoten herunter. Vermeiden Sie es, auf nur einen Workerknoten herunter zu gehen.
- Führen Sie bei Bedarf den Befehl zum Verlassen des abgesicherten Modus aus.
In den folgenden Abschnitten werden diese Optionen beschrieben.
Beenden aller Hive-Aufträge
Beenden Sie alle Hive-Aufträge, bevor Sie einen Workerknoten zentral herunterskalieren. Wenn Ihre Workload geplant ist, führen Sie Ihre zentrale Herunterskalierung nach Abschluss der Hive-Arbeit durch.
Durch Beenden der Hive-Aufträge vor der Skalierung kann die Anzahl der Scratchdateien im Ordner „tmp“ gegebenenfalls minimiert werden.
Manuelles Bereinigen der Hive-Scratchdateien
Wenn Hive temporäre Dateien zurückgelassen hat, können Sie diese Dateien vor dem zentralen Herunterskalieren manuell bereinigen, um den abgesicherten Modus zu vermeiden.
Überprüfen Sie, welcher Speicherort für temporäre Hive-Dateien verwendet wird, indem Sie die Konfigurationseigenschaft
hive.exec.scratchdiranzeigen. Dieser Parameter wird in/etc/hive/conf/hive-site.xmlfestgelegt:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Beenden Sie die Hive-Dienste, und achten Sie darauf, dass alle Abfragen und Aufträge abgeschlossen sind.
Listen Sie den Inhalt des oben angegebenen Scratchverzeichnisses
hdfs://mycluster/tmp/hive/auf, um festzustellen, ob es Dateien enthält:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveDies ist eine Beispielausgabe für den Fall, dass Dateien vorhanden sind:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoWenn Sie wissen, dass Hive diese Dateien nicht mehr benötigt, können Sie sie entfernen. Wechseln Sie auf der Seite „YARN“ zur Resource Manager-Benutzeroberfläche, und vergewissern Sie sich, dass keine Hive-Abfragen ausgeführt werden.
Beispielbefehlszeile zum Entfernen von Dateien aus HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Skalieren von HDInsight auf drei oder mehr Workerknoten
Wenn Sie feststellen, dass Ihre Cluster häufig im abgesicherten Modus hängen bleiben, wenn Sie einen Skalierungsvorgang auf weniger als drei Workerknoten ausführen, behalten Sie mindestens drei Workerknoten bei.
Die Verwendung von drei Workerknoten ist zwar teurer als das horizontale Herunterskalieren auf einen einzelnen Workerknoten. Dadurch können Sie aber verhindern, dass Ihr Cluster im abgesicherten Modus hängen bleibt.
Herunterskalieren von HDInsight auf einen Workerknoten
Auch wenn Sie den Cluster auf einen Knoten herunterskalieren, bleibt der Workerknoten 0 weiterhin bestehen. Workerknoten 0 kann nie außer Betrieb gesetzt werden.
Ausführen des Befehls zum Verlassen des abgesicherten Modus
Die letzte Möglichkeit besteht darin, den Befehl zum Verlassen des abgesicherten Modus auszuführen. Ist der Wechsel von HDFS in den abgesicherten Modus auf die Unterreplikation der Hive-Datei zurückzuführen, führen Sie zum Verlassen des abgesicherten Modus den folgenden Befehl aus:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Zentrales Herunterskalieren eines Apache HBase-Clusters
Regionsserver werden innerhalb weniger Minuten nach Abschluss eines Skalierungsvorgangs automatisch ausgeglichen. Um Regionsserver manuell auszugleichen, führen Sie folgende Schritte aus:
Stellen Sie mithilfe von SSH eine Verbindung mit dem HDInsight-Cluster her. Weitere Informationen finden Sie unter Verwenden von SSH mit Linux-basiertem Hadoop in HDInsight unter Linux, Unix oder OS X.
Starten Sie die HBase-Shell:
hbase shellUm die Regionsserver manuell auszugleichen, führen Sie folgenden Befehl aus:
balancer
Nächste Schritte
Detaillierte Informationen zum Skalieren von HDInsight-Clustern finden Sie hier: