Integrieren von Apache Spark und Apache Hive unter Azure HDInsight per Hive Warehouse Connector
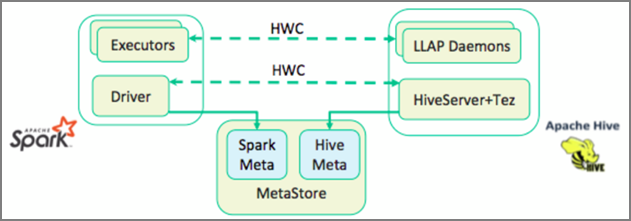
Der Apache Hive Warehouse Connector (HWC) ist eine Bibliothek, die Ihnen ein einfacheres Arbeiten mit Apache Spark und Apache Hive ermöglicht. Er unterstützt Aufgaben wie das Verschieben von Daten zwischen Spark-Datenrahmen und Hive-Tabellen. Darüber hinaus wird das Weiterleiten von Spark-Streamingdaten an Hive-Tabellen unterstützt. Hive Warehouse Connector fungiert quasi als Brücke zwischen Spark und Hive. Außerdem werden Scala, Java und Python als Programmiersprachen für die Entwicklung unterstützt.
Mit Hive Warehouse Connector können Sie die einzigartigen Features von Hive und Spark nutzen, um leistungsfähige Big Data-Anwendungen zu entwickeln.
Apache Hive verfügt über Unterstützung für Datenbanktransaktionen, die atomisch, konsistent, isoliert und dauerhaft sind (Atomic, Consistent, Isolated and Durable, ACID). Weitere Informationen zu ACID und Transaktionen in Hive finden Sie im Artikel zu Hive-Transaktionen. Darüber hinaus verfügt Hive über detaillierte Sicherheitssteuerelemente über Apache Ranger und die analytische Verarbeitung mit geringer Latenz (Low Latency Analytical Processing, LLAP), die in Apache Spark nicht verfügbar sind.
Apache Spark enthält eine API für strukturierte Streams, mit der Streamingfunktionen ermöglicht werden, die in Apache Hive nicht verfügbar sind. Ab HDInsight 4.0 weisen Apache Spark 2.3.1 und höher sowie Apache Hive 3.1.0 separate Metastorekataloge auf, sodass die Interoperabilität erschwert werden kann.
Der Hive Warehouse Connector (HWC) vereinfacht die gemeinsame Nutzung von Spark und Hive. Die HWC-Bibliothek lädt Daten parallel aus LLAP-Daemons in Spark-Executors. Dieser Prozess führt zu besserer Effizienz und Anpassbarkeit als bei einer standardmäßigen JDBC-Verbindung von Spark zu Hive. Dadurch sind zwei verschiedene Ausführungsmodi für HWC verfügbar:
- Hive-JDBC-Modus über HiveServer2
- Hive-LLAP-Modus mit LLAP-Daemons [empfohlen]
HWC ist standardmäßig für die Verwendung von Hive-LLAP-Daemons konfiguriert. Informationen zum Ausführen von Hive-Abfragen (lesen und schreiben) mit den oben genannten Modi mit ihren jeweiligen APIs finden Sie unter HWC-APIs.
Einige Vorgänge, die von Hive Warehouse Connector unterstützt werden, sind:
- Beschreiben einer Tabelle
- Erstellen einer Tabelle für Daten im ORC-Format
- Auswählen von Hive-Daten und Abrufen eines Datenrahmens
- Schreiben eines Datenrahmens in Hive als Batchvorgang
- Ausführen einer Hive-Aktualisierungsanweisung
- Lesen von Tabellendaten aus Hive, Durchführen der Transformation für Spark und Schreiben der Daten in eine neue Hive-Tabelle
- Schreiben eines Datenrahmens oder Spark-Streams in Hive per HiveStreaming
Hive Warehouse Connector-Setup
Wichtig
- Die Verwendung der auf den Enterprise-Sicherheitspaket-Clustern von Spark 2.4 installierten HiveServer2 Interactive-Instanz mit dem Hive Warehouse Connector wird nicht unterstützt. Stattdessen müssen Sie einen eigenständigen HiveServer2 Interactive-Cluster konfigurieren, um Ihre HiveServer2 Interactive-Workloads zu hosten. Eine Hive Warehouse Connector-Konfiguration, die einen einzelnen Spark 2.4-Cluster verwendet, wird nicht unterstützt.
- Die HWC-Bibliothek (Hive Warehouse Connector) wird nicht für die Verwendung mit Interactive Query-Clustern unterstützt, in denen die Funktion zur Workloadverwaltung (Workload Management, WLM) aktiviert ist.
In einem Szenario, in dem Sie nur über Spark-Workloads verfügen und die HWC-Bibliothek verwenden möchten, müssen Sie sicherstellen, dass für den Interactive Query-Cluster nicht das Feature zur Workloadverwaltung aktiviert ist (die Konfigurationhive.server2.tez.interactive.queueist in den Hive-Konfigurationen nicht festgelegt).
In einem Szenario, das sowohl Spark-Workloads (HWC) als auch native LLAP-Workloads umfasst, müssen Sie zwei separate Interactive Query-Cluster mit einer freigegebenen Metastore-Datenbank erstellen: einen Cluster für native LLAP-Workloads, bei denen die Funktion zur Workloadverwaltung bedarfsabhängig aktiviert werden kann, und einen weiteren Cluster für HWC-Workloads, bei denen die Funktion zur Workloadverwaltung nicht konfiguriert wird. Beachten Sie, dass Sie die Ressourcenpläne für die Workloadverwaltung aus beiden Clustern anzeigen können, auch wenn die Funktion nur in einem Cluster aktiviert ist. Nehmen Sie keine Änderungen an den Ressourcenplänen in dem Cluster vor, in dem die Funktion zur Workloadverwaltung deaktiviert ist, da sich dies auf die Funktionalität der Workloadverwaltung im anderen Clustern auswirken kann. - Obwohl Spark die R-Computingsprache unterstützt, um die Datenanalyse zu vereinfachen, wird die Hive Warehouse Connector-Bibliothek (HWC) nicht für die Verwendung mit R unterstützt. Zum Ausführen von HWC-Workloads können Sie Abfragen von Spark an Hive mithilfe der HiveWarehouseSession-API im JDBC-Stil ausführen, die nur Scala, Java und Python unterstützt.
- Das Ausführen von Abfragen (lesen und schreiben) über HiveServer2 über den JDBC-Modus wird für komplexe Datentypen wie Arrays/Strukturen/Zuordnungstypen nicht unterstützt.
- HWC unterstützt das Schreiben nur in ORC-Dateiformaten. Nicht-ORC-Schreibvorgänge (z. B. Parquet- und Textdateiformate) werden über HWC nicht unterstützt.
Für Hive Warehouse Connector werden separate Cluster für Spark- und Interactive Query-Workloads benötigt. Führen Sie diese Schritte aus, um diese Cluster in Azure HDInsight einzurichten.
Unterstützte Clustertypen und Versionen
| HWC-Version | Spark-Version | InteractiveQuery-Version |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| V2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Erstellen von Clustern
Erstellen Sie einen HDInsight Spark 4.0-Cluster mit einem Speicherkonto und einem benutzerdefinierten virtuellen Azure-Netzwerk. Informationen zur Erstellung eines Clusters in einem virtuellen Azure-Netzwerk finden Sie unter Hinzufügen von HDInsight zu einem vorhandenen virtuellen Netzwerk.
Erstellen Sie einen Cluster des Typs „HDInsight Interactive Query (LLAP) 4.0“, indem Sie dasselbe Speicherkonto und virtuelle Azure-Netzwerk wie für den Spark-Cluster verwenden.
Konfigurieren von HWC-Einstellungen
Sammeln vorläufiger Informationen
Navigieren Sie in einem Webbrowser zu
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE. Hierbei ist „LLAPCLUSTERNAME“ der Name Ihres Interactive Query-Clusters.Navigieren Sie zu Summary>HiveServer2 Interactive JDBC URL, und notieren Sie sich den Wert. Der Wert kann wie folgt lauten:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Navigieren Sie zu Configs>Advanced>Advanced hive-site>hive.zookeeper.quorum, und notieren Sie sich den Wert. Der Wert kann wie folgt lauten:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Navigieren Sie zu Configs>Advanced>General>hive.metastore.uris, und notieren Sie sich den Wert. Der Wert kann wie folgt lauten:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Navigieren Sie zu Configs>Advanced>Advanced hive-interactive-site>hive.llap.daemon.service.hosts, und notieren Sie sich den Wert. Der Wert kann wie folgt lauten:
@llap0.
Konfigurieren von Einstellungen des Spark-Clusters
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs. Hierbei ist „CLUSTERNAME“ der Name Ihres Apache Spark-Clusters.Erweitern Sie Custom spark2-defaults.
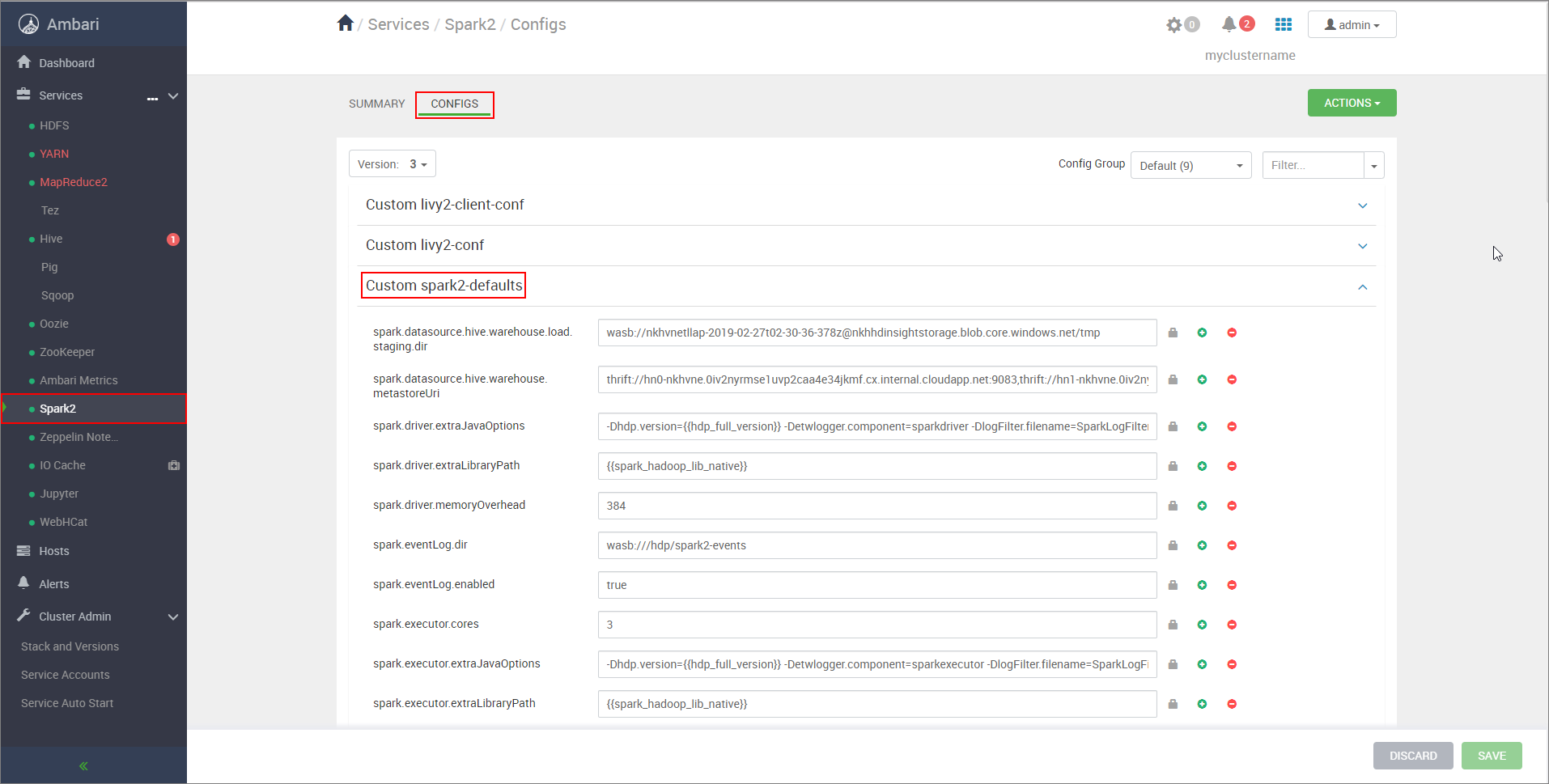
Wählen Sie Add Property... , um die folgenden Konfigurationen hinzuzufügen:
Konfiguration Wert spark.datasource.hive.warehouse.load.staging.dirVerwenden Sie bei Nutzung von ADLS Gen2-Speicherkonten abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp.
Verwenden Sie bei Nutzung von Azure Blob Storage-Kontenwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Legen Sie diese Einstellung auf ein geeignetes mit HDFS kompatibles Stagingverzeichnis fest. Wenn Sie zwei unterschiedliche Cluster verwenden, sollte das Stagingverzeichnis ein Ordner im Stagingverzeichnis Ihres Speicherkontos im LLAP-Cluster sein, damit HiveServer2 Zugriff darauf hat. Ersetzen SieSTORAGE_ACCOUNT_NAMEdurch den Namen des vom Cluster verwendeten Speicherkontos undSTORAGE_CONTAINER_NAMEdurch den Namen des Speichercontainers.spark.sql.hive.hiveserver2.jdbc.urlDer Wert, den Sie zuvor unter HiveServer2 Interactive JDBC URL notiert haben. spark.datasource.hive.warehouse.metastoreUriDer Wert, den Sie zuvor aus hive.metastore.uris abgerufen haben. spark.security.credentials.hiveserver2.enabledtruefür YARN-Clustermodus undfalsefür YARN-Clientmodus.spark.hadoop.hive.zookeeper.quorumDer Wert, den Sie zuvor aus hive.zookeeper.quorum abgerufen haben. spark.hadoop.hive.llap.daemon.service.hostsDer Wert, den Sie zuvor aus hive.llap.daemon.service.hosts abgerufen haben. Speichern Sie die Änderungen, und starten Sie alle betroffenen Komponenten neu.
Konfigurieren von HWC für ESP-Cluster (Enterprise-Sicherheitspaket)
Das Enterprise-Sicherheitspaket (ESP) umfasst Unternehmensfunktionen wie Active Directory-basierte Authentifizierung, Mehrbenutzerunterstützung und rollenbasierte Zugriffssteuerung für Apache Hadoop-Cluster in Azure HDInsight. Weitere Informationen zu Enterprise-Sicherheitspaketen finden Sie unter Verwendung des Enterprise-Sicherheitspakets in HDInsight.
Fügen Sie zusätzlich zu den im vorherigen Abschnitt erwähnten Konfigurationen die folgende Konfiguration hinzu, um HWC in den ESP-Clustern zu verwenden.
Navigieren Sie auf der Ambari-Webbenutzeroberfläche des Spark-Clusters zu Spark2>CONFIGS>Custom spark2-defaults.
Aktualisieren Sie die folgende Eigenschaft.
Konfiguration Wert spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary. Hierbei ist „CLUSTERNAME“ der Name Ihres Interactive Query-Clusters. Klicken Sie auf HiveServer2 Interactive. Sie sehen den vollqualifizierten Domänennamen (FQDN) des Hauptknotens, auf dem LLAP ausgeführt wird, wie im Screenshot gezeigt. Ersetzen Sie<llap-headnode>durch diesen Wert.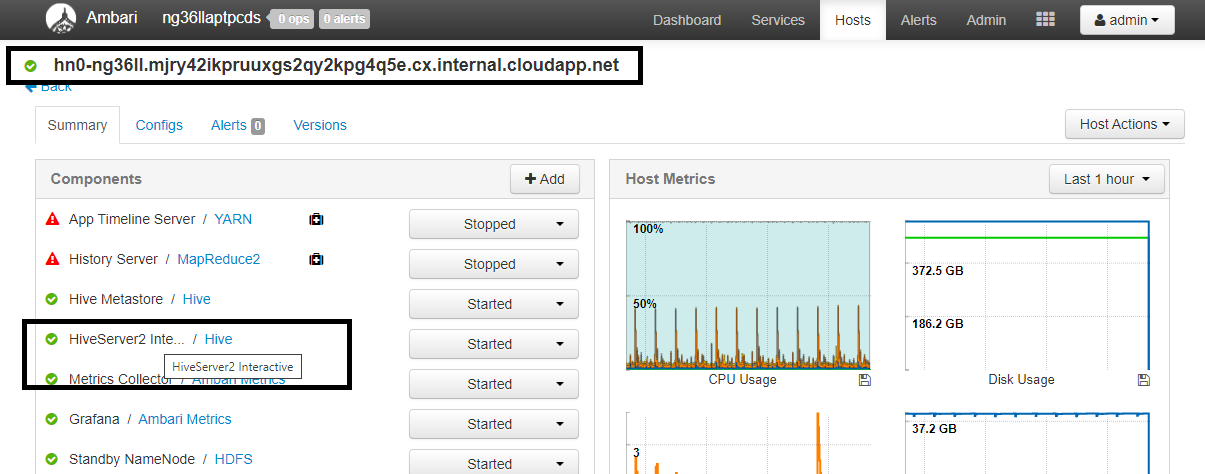
Verwenden Sie den Befehl „ssh“, um eine Verbindung mit Ihrem Interactive Query-Cluster herzustellen. Suchen Sie in der Datei
/etc/krb5.confnach dem Parameterdefault_realm. Ersetzen Sie<AAD-DOMAIN>durch diesen Wert als Zeichenfolge in Großbuchstaben, da die Anmeldeinformationen andernfalls nicht gefunden werden.
Beispielsweise
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Speichern Sie Änderungen, und starten Sie Komponenten nach Bedarf neu.
Hive Warehouse Connector-Nutzung
Sie können zwischen einigen unterschiedlichen Methoden wählen, um eine Verbindung mit Ihrem Interactive Query-Cluster herzustellen und Abfragen auszuführen, indem Sie Hive Warehouse Connector verwenden. Beispielsweise werden die folgenden Tools unterstützt:
Hier sind einige Beispiele für die Verbindungsherstellung mit HWC aus Spark angegeben.
Spark-Shell
Dies ist eine Möglichkeit, Spark interaktiv über eine geänderte Version der Scala-Shell auszuführen.
Verwenden Sie den Befehl ssh, um eine Verbindung mit Ihrem Apache Spark-Cluster herzustellen. Bearbeiten Sie den folgenden Befehl, indem Sie CLUSTERNAME durch den Namen Ihres Clusters ersetzen, und geben Sie den Befehl dann ein:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netFühren Sie in Ihrer SSH-Sitzung den folgenden Befehl aus, und notieren Sie sich die Version von
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorBearbeiten Sie den unten angegebenen Code, indem Sie die oben ermittelte Version für
hive-warehouse-connector-assemblyverwenden. Führen Sie anschließend den Befehl aus, um die Spark-Shell zu starten:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseNachdem die Spark-Shell gestartet wurde, kann mit den folgenden Befehlen eine Hive Warehouse Connector-Instanz gestartet werden:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit ist ein Hilfsprogramm zum Übermitteln beliebiger Spark-Programme (oder -Aufträge) an Spark-Cluster.
Der Spark-submit-Auftrag richtet Spark und Hive Warehouse Connector entsprechend unseren Anweisungen ein und konfiguriert diese, führt das Programm aus, das wir an ihn übergeben haben, und gibt dann die verwendeten Ressourcen ordnungsgemäß frei.
Nachdem Sie den Scala/Java-Code zusammen mit den Abhängigkeiten als Assembly-JAR-Datei erstellt haben, können Sie den unten angegebenen Befehl verwenden, um eine Spark-Anwendung zu starten. Ersetzen Sie <VERSION> und <APP_JAR_PATH> durch die tatsächlichen Werte.
YARN-Clientmodus
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN-Clustermodus
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Dieses Hilfsprogramm wird auch verwendet, wenn die gesamte Anwendung in pySpark geschrieben und in .py-Dateien (Python) gepackt wurde, um den gesamten Code zur Ausführung an den Spark-Cluster zu übermitteln.
Übergeben Sie für Python-Anwendungen eine PY-Datei anstelle von /<APP_JAR_PATH>/myHwcAppProject.jar, und fügen Sie dem Suchpfad mit --py-files die folgende Konfigurationsdatei (Python.zip) hinzu.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Ausführen von Abfragen in ESP-Clustern (Enterprise-Sicherheitspaket)
Verwenden Sie kinit, bevor Sie „spark-shell“ oder „spark-submit“ starten. Ersetzen Sie „USERNAME“ durch den Namen eines Domänenkontos mit Berechtigungen zum Zugreifen auf den Cluster, und führen Sie anschließend den folgenden Befehl aus:
kinit USERNAME
Schützen von Daten in Spark-ESP-Clustern
Erstellen Sie die Tabelle
demomit einigen Beispieldaten, indem Sie die folgenden Befehle eingeben:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Zeigen Sie den Inhalt der Tabelle mit dem folgenden Befehl an. Vor dem Anwenden der Richtlinie wird in der Tabelle
demodie gesamte Spalte angezeigt.hive.executeQuery("SELECT * FROM demo").show()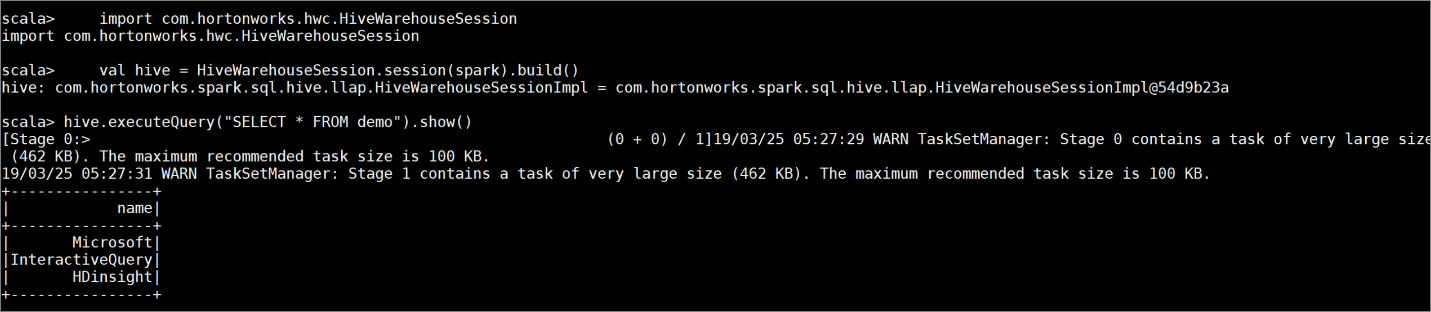
Wenden Sie eine Richtlinie für die Spaltenmaskierung an, bei der nur die letzten vier Zeichen der Spalte angezeigt werden.
Navigieren Sie zur Ranger-Administratoroberfläche unter
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Klicken Sie unter Hive auf den Hive-Dienst für Ihren Cluster.
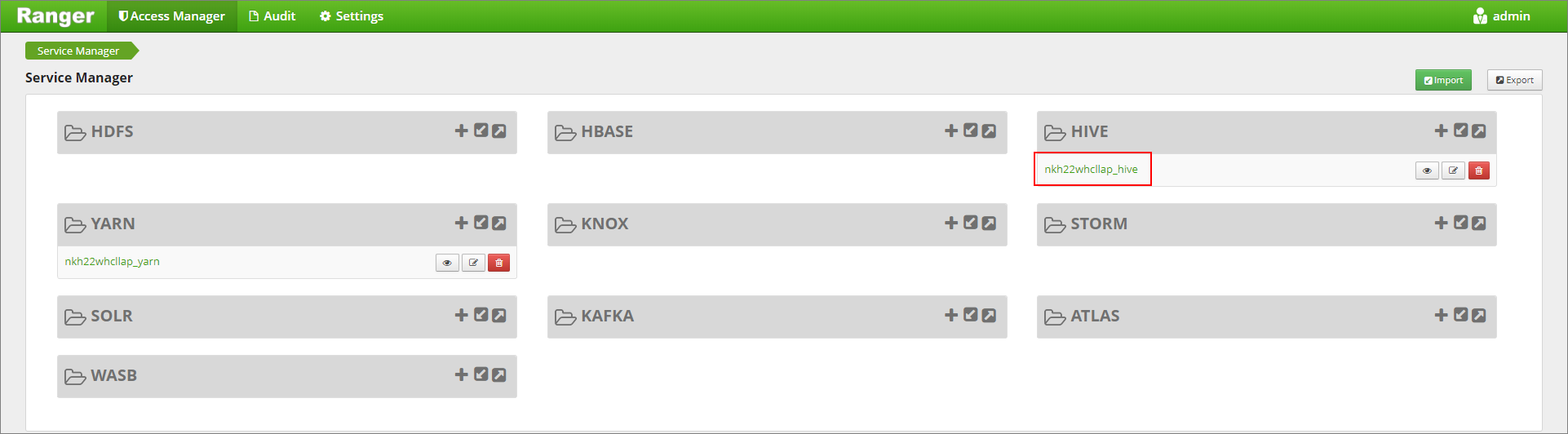
Klicken Sie auf die Registerkarte für die Maskierung und dann auf Neue Richtlinie hinzufügen.
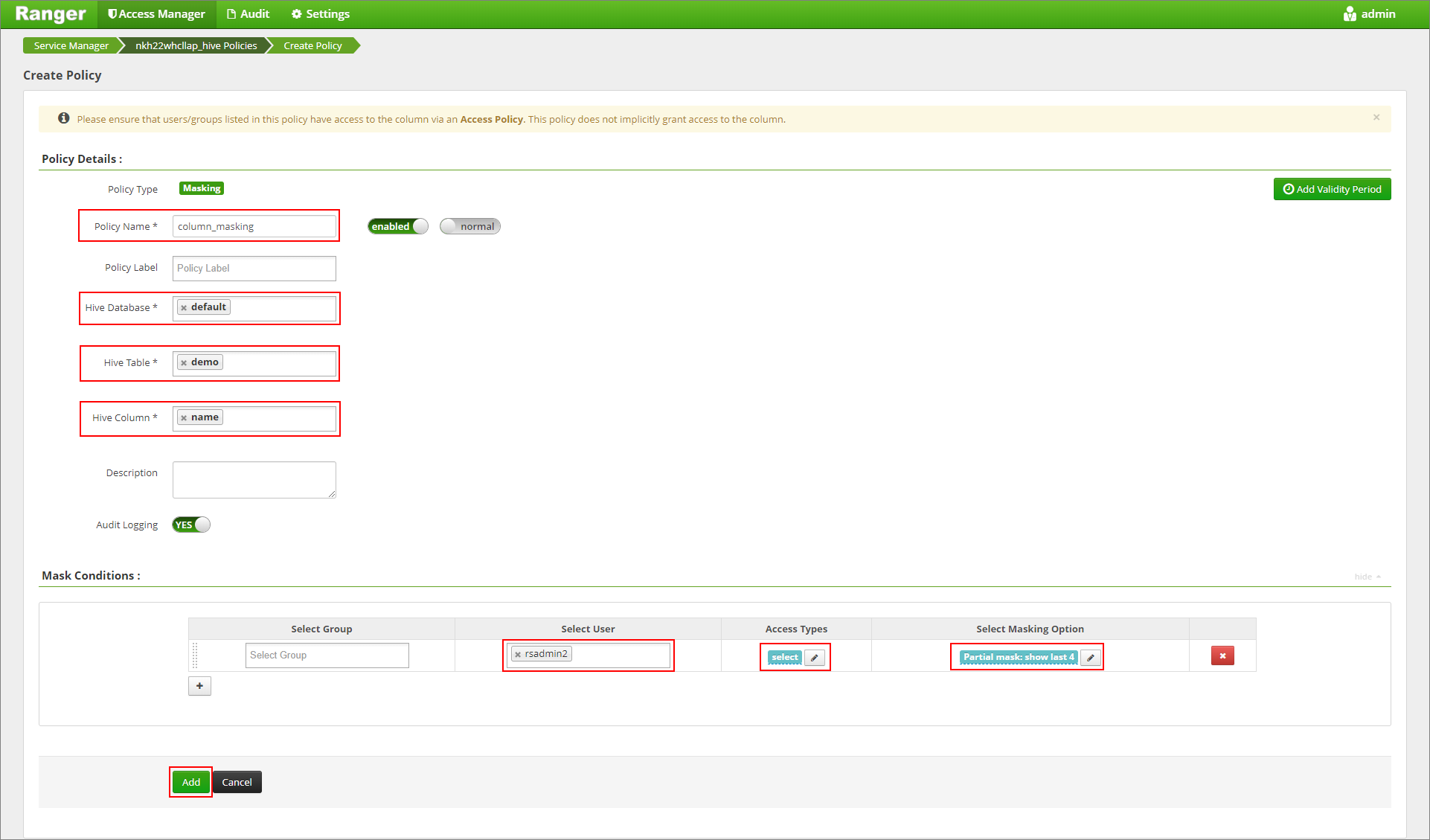
Geben Sie den gewünschten Namen für die Richtlinie ein. Wählen Sie Folgendes aus. Datenbank: Standard, Hive-Tabelle: demo, Hive-Spalte: name, Benutzer: rsadmin2, Zugriffstypen: Auswählen und Teilmaske: Letzte 4 anzeigen (Menü Maskierungsfunktion auswählen). Klicken Sie auf Hinzufügen.
Zeigen Sie den Inhalt der Tabelle erneut an. Nachdem die Ranger-Richtlinie angewendet wurde, werden nur die letzten vier Zeichen der Spalte angezeigt.
