Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Tutorial erfahren Sie, wie Sie eine in Scala geschriebene Apache Spark-Anwendung erstellen, die Apache Maven mit IntelliJ IDEA nutzt. In diesem Artikel wird Apache Maven als Buildsystem verwendet. Darüber hinaus wird ein von IntelliJ IDEA bereitgestellter vorhandener Maven-Archetyp für Scala genutzt. Das Erstellen einer Scala-Anwendung in IntelliJ IDEA umfasst die folgenden Schritte:
- Verwenden von Maven als Buildsystem
- Aktualisieren der Projektobjektmodell-Datei (POM-Datei) zum Auflösen von Spark-Modulabhängigkeiten
- Schreiben der Anwendung in Scala
- Generieren einer JAR-Datei, die an HDInsight Spark-Cluster übermittelt werden kann
- Ausführen der Anwendung in einem Spark-Cluster mithilfe von Livy
In diesem Tutorial lernen Sie Folgendes:
- Installieren des Scala-Plug-Ins für IntelliJ IDEA
- Verwenden von IntelliJ zum Entwickeln einer Scala Maven-Anwendung
- Erstellen eines eigenständigen Scala-Projekts
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Oracle Java Development Kit. In diesem Tutorial wird die Java-Version 8.0.202 verwendet.
Eine Java-IDE. In diesem Artikel wird IntelliJ IDEA Community 2018.3.4 verwendet.
Azure-Toolkit für IntelliJ. Weitere Informationen finden Sie unter Installieren des Azure-Toolkits für IntelliJ.
Installieren des Scala-Plug-Ins für IntelliJ IDEA
Führen Sie die folgenden Schritte aus, um das Scala-Plug-In zu installieren:
Öffnen Sie IntelliJ IDEA.
Navigieren Sie auf der Willkommensseite zu Konfigurieren>Plug-Ins, um das Fenster Plug-Ins zu öffnen.
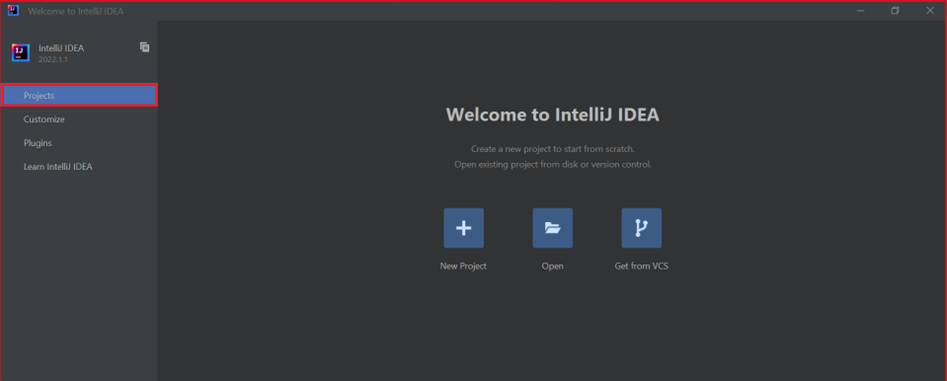
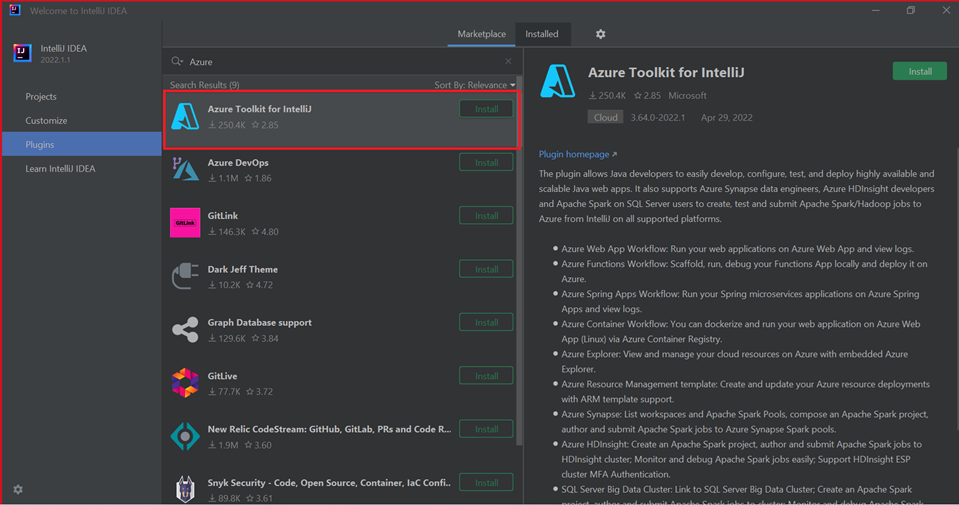
Wählen Sie Install (Installieren) für Azure-Toolkit für IntelliJ aus.
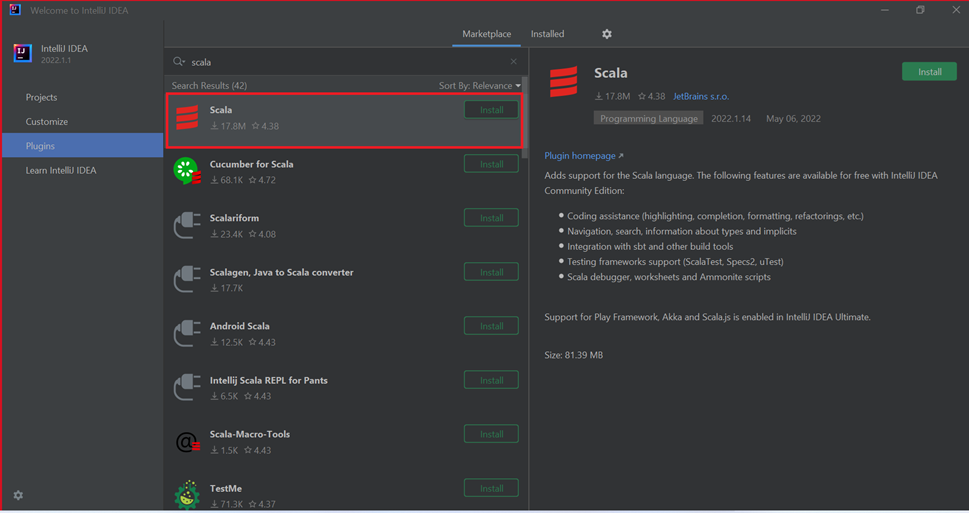
Wählen Sie für das in dem neuen Fenster empfohlene Scala-Plug-In die Option Installieren aus.
Nach erfolgreicher Plug-In-Installation müssen Sie die IDE neu starten.
Erstellen der Anwendung mit IntelliJ
Starten Sie IntelliJ IDEA, und wählen Sie Create New Project (Neues Projekt erstellen) aus, um das Fenster New Project (Neues Projekt) zu öffnen.
Wählen Sie im linken Bereich Apache Spark/HDInsight aus.
Wählen Sie im Hauptfenster Spark Project (Scala) (Spark-Projekt (Scala)) aus.
Wählen Sie in der Dropdownliste Build tool (Buildtool) einen der folgenden Werte aus:
- Maven für die Unterstützung des Scala-Projekterstellungs-Assistenten
- SBT zum Verwalten von Abhängigkeiten und Erstellen für das Scala-Projekt
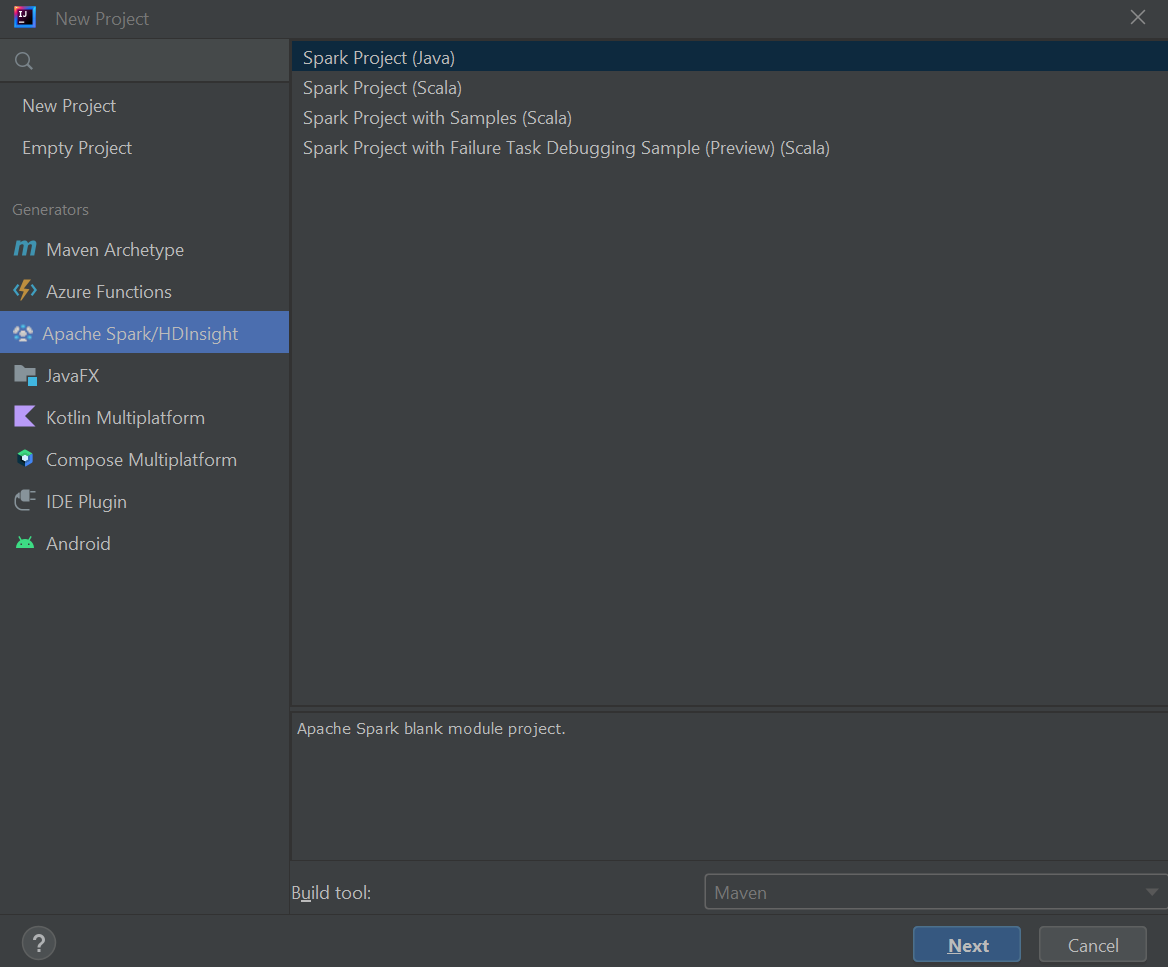
Wählen Sie Weiter aus.
Geben Sie im Fenster New Project (Neues Projekt) die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Projektname Geben Sie einen Namen ein. Projektspeicherort Geben Sie den Speicherort für Ihr Projekt ein. Project SDK (Projekt-SDK) Dieses Feld ist bei der erstmaligen Verwendung von IDEA leer. Wählen Sie New... (Neu...) aus, und navigieren Sie zu Ihrem JDK. Spark-Version Der Erstellungs-Assistent integriert die passende Version für das Spark-SDK und das Scala-SDK. Wenn Sie eine ältere Spark-Clusterversion als 2.0 verwenden, wählen Sie Spark 1.x aus. Wählen Sie andernfalls Spark 2.x aus. In diesem Beispiel wird Spark 2.3.0 (Scala 2.11.8) verwendet. 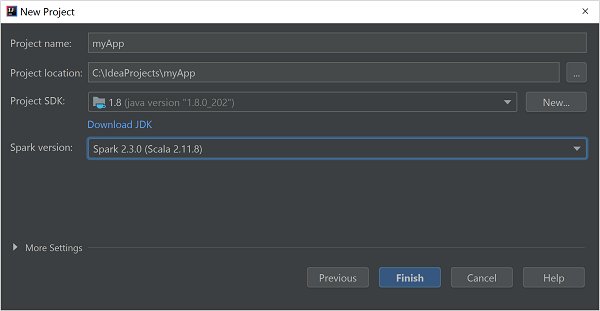
Wählen Sie Fertig stellenaus.
Erstellen eines eigenständigen Scala-Projekts
Starten Sie IntelliJ IDEA, und wählen Sie Create New Project (Neues Projekt erstellen) aus, um das Fenster New Project (Neues Projekt) zu öffnen.
Wählen Sie im linken Bereich die Option Maven aus.
Geben Sie ein Projekt-SDKan. Klicken Sie auf New... (Neu...), und navigieren Sie zum Installationsverzeichnis von Java.
Aktivieren Sie das Kontrollkästchen Create from archetype (Archetypbasierte Erstellung).
Wählen Sie in der Liste der Archetypen
org.scala-tools.archetypes:scala-archetype-simpleaus. Dieser Archetyp erstellt die passende Verzeichnisstruktur und lädt die erforderlichen Standardabhängigkeiten zum Schreiben des Scala-Programms herunter.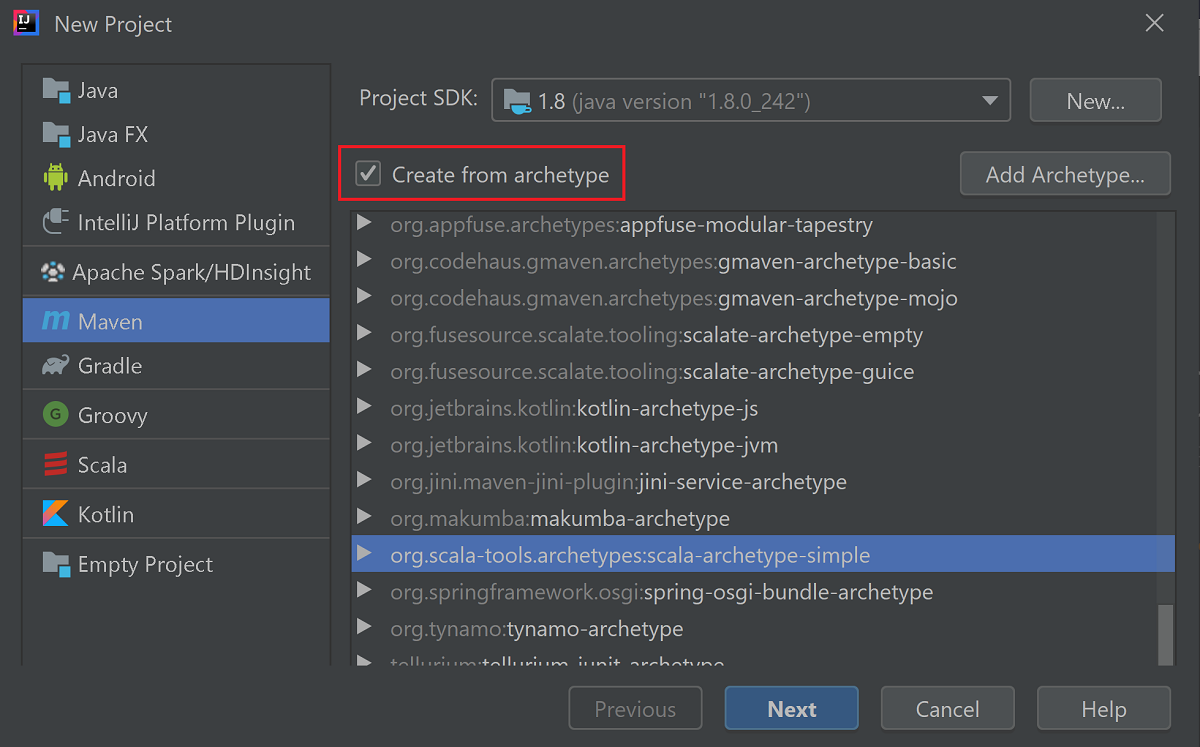
Wählen Sie Weiter aus.
Klappen Sie Artifact Coordinates (Artefaktkoordinaten) auf. Geben Sie passende Werte für GroupId und ArtifactId an. Name und Ort werden automatisch ausgefüllt. In diesem Tutorial werden die folgenden Werte verwendet:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
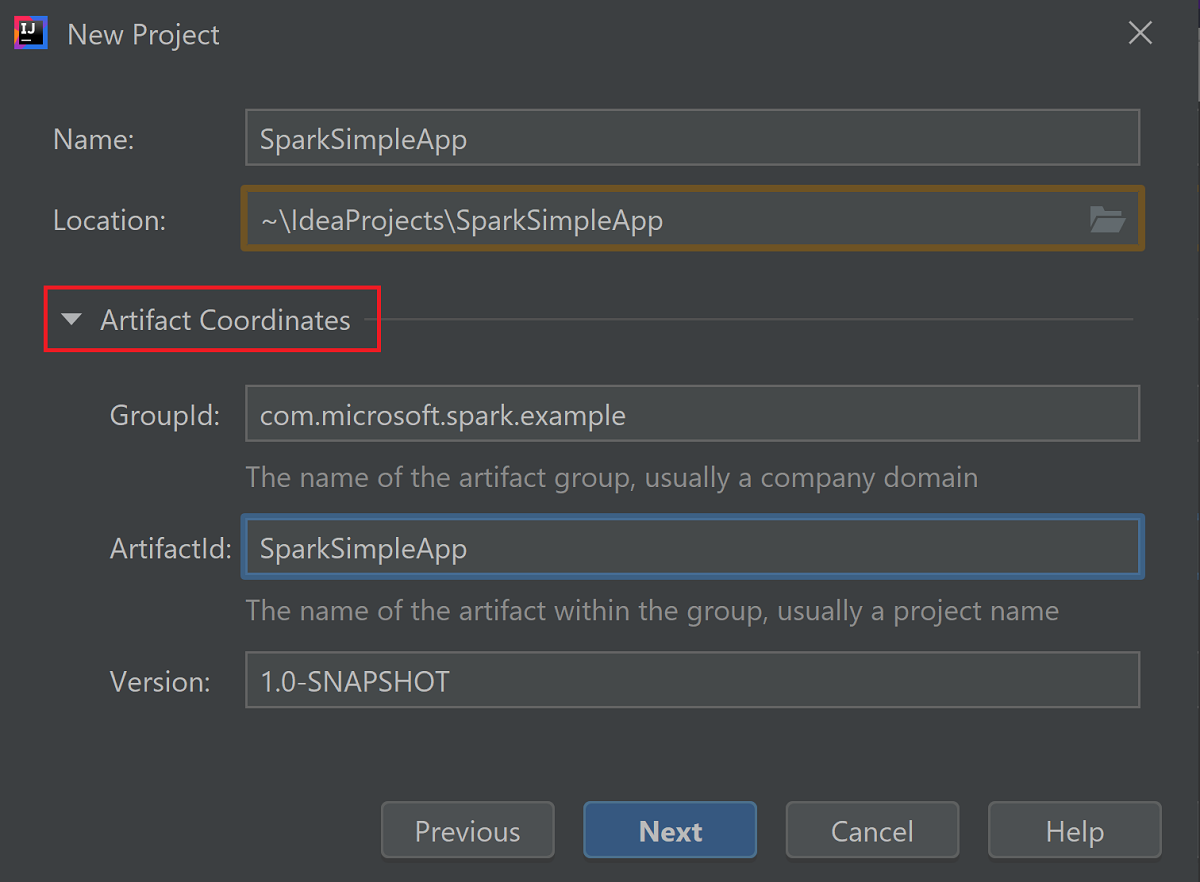
Wählen Sie Weiter aus.
Überprüfen Sie die Einstellungen, und wählen Sie Weiter aus.
Überprüfen Sie den Projektnamen und einen Speicherort, und wählen Sie anschließend Fertig stellen aus. Das Importieren des Projekts dauert ein paar Minuten.
Navigieren Sie nach Abschluss des Projektimports im linken Bereich zu SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Klicken Sie mit der rechten Maustaste auf MySpec, und wählen Sie Delete... (Löschen...) aus. Sie brauchen diese Datei für die Anwendung nicht. Wählen Sie im Dialogfeld OK aus.
In späteren Schritten wird die Datei pom.xml aktualisiert, um die Abhängigkeiten für die Spark Scala-Anwendung zu definieren. Damit diese Abhängigkeiten automatisch heruntergeladen und aufgelöst werden, muss Maven konfiguriert sein.
Wählen Sie im Menü File (Datei) die Option Settings (Einstellungen) aus, um das Fenster Settings (Einstellungen) zu öffnen.
Navigieren Sie im Fenster Settings (Einstellungen) zu Build, Execution, Deployment>Build Tools>Maven>Importing („Erstellung, Ausführung, Bereitstellung“ > „Buildtools“ > „Maven“ > „Importieren“).
Aktivieren Sie das Kontrollkästchen Import Maven projects automatically (Maven-Projekte automatisch importieren).
Klicken Sie auf Apply (Anwenden) und dann auf OK. Daraufhin wird wieder das Projektfenster angezeigt.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::Navigieren Sie im linken Bereich zu src>main>scala>com.microsoft.spark.example, und doppelklicken Sie dann auf App, um „App.scala“ zu öffnen.
Ersetzen Sie den vorhandenen Beispielcode durch den folgenden Code, und speichern Sie die Änderungen. Dieser Code liest die Daten aus der Datei „HVAC.csv“ (verfügbar in allen HDInsight Spark-Clustern), ruft die Zeilen ab, die nur eine Ziffer in der sechsten Spalte enthalten, und schreibt die Ausgabe in /HVACOut unter dem Standardspeichercontainer für den Cluster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }Doppelklicken Sie im linken Bereich auf pom.xml.
Fügen Sie in
<project>\<properties>folgende Segmente hinzu:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Fügen Sie in
<project>\<dependencies>folgende Segmente hinzu:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Erstellen Sie die JAR-Datei. IntelliJ IDEA ermöglicht die Erstellung von JAR als Projektartefakt. Führen Sie die folgenden Schritte aus:
Wählen Sie im Menü File (Datei) die Option Project Structure... (Projektstruktur...) aus.
Navigieren Sie im Fenster Project Structure (Projektstruktur) zu Artifacts>+>JAR>From modules with dependencies... („Artefakte“ > Plussymbol > „JAR“ > „Aus Modulen mit Abhängigkeiten...“).
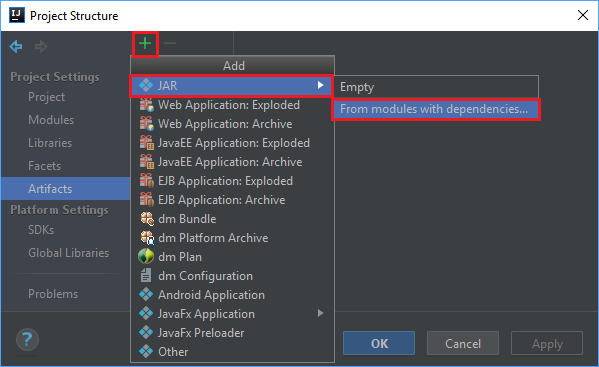
Wählen Sie im Fenster Create JAR from Modules (JAR aus Modulen erstellen) das Ordnersymbol im Textfeld Main Class (Hauptklasse) aus.
Wählen Sie im Fenster Select Main Class (Hauptklasse auswählen) die standardmäßig angezeigte Klasse und anschließend OK aus.
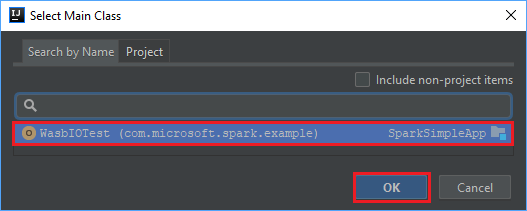
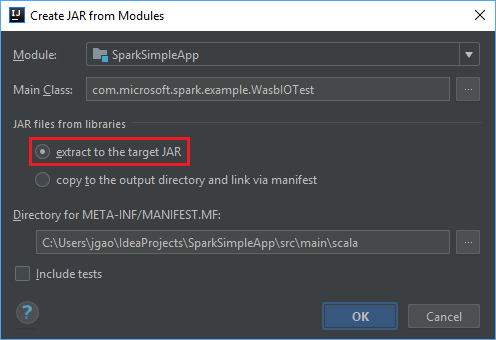
Vergewissern Sie sich im Fenster Create JAR from Modules (JAR aus Modulen erstellen), dass die Option extract to the target JAR (Extrahieren in die JAR-Zieldatei) aktiviert ist, und wählen Sie anschließend OK aus. Mit dieser Einstellung wird eine einzelne JAR-Datei mit allen Abhängigkeiten erstellt.
Die Registerkarte Output Layout führt alle JAR-Dateien des Maven-Projekts auf. Sie können die Dateien auswählen und löschen, zu denen die Scala-Anwendung keine direkte Abhängigkeit hat. Bei der hier erstellten Anwendung können Sie alle bis auf die letzte (SparkSimpleApp-Kompilierungsausgabe) entfernen. Wählen Sie die zu löschenden JAR-Dateien und anschließend das Minussymbol - aus.
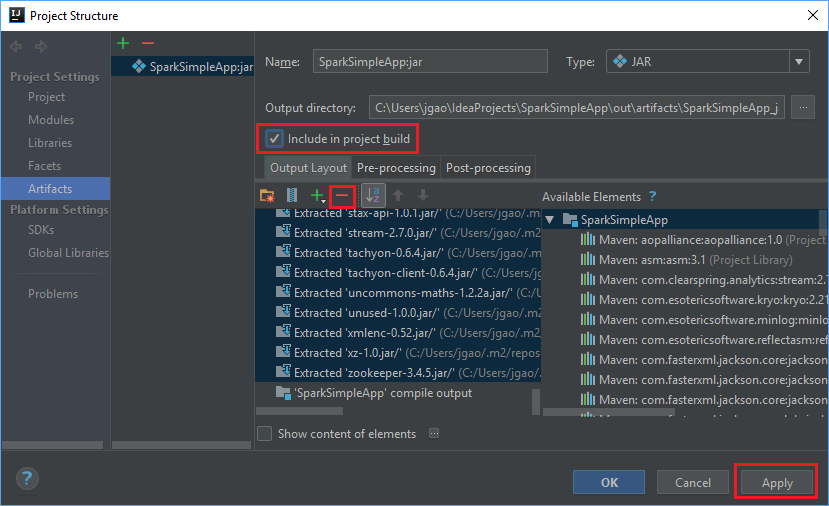
Vergewissern Sie sich, dass das Kontrollkästchen Include in project build (In Projektbuild einbeziehen) aktiviert ist. Mit dieser Option wird sichergestellt, dass die JAR-Datei bei jeder Projekterstellung oder -aktualisierung erstellt wird. Wählen Sie Apply (Übernehmen) und anschließend OK aus.
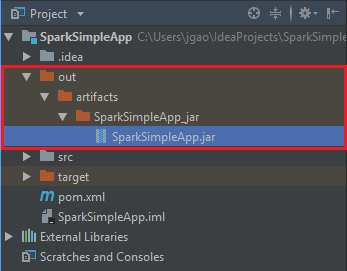
Navigieren Sie zum Erstellen der JAR-Datei zu Build>Build Artifacts>Build („Erstellen“ > „Artefakte erstellen“ > „Erstellen“). Das Projekt wird in ca. 30 Sekunden kompiliert. Die JAR-Ausgabe wird unter \out\artifacts erstellt.
Ausführen der Anwendung im Apache Spark-Cluster
Sie können die folgenden Ansätze nutzen, um die Anwendung im Cluster auszuführen:
Kopieren Sie die JAR-Anwendungsdatei in das dem Cluster zugeordnete Azure Storage-Blob. Hierzu können Sie das Befehlszeilenprogramm AzCopy verwenden. Daneben gibt es aber auch noch zahlreiche andere Clients, die Sie zum Hochladen von Daten verwenden können. Weitere Informationen finden Sie unter Hochladen von Daten für Hadoop-Aufträge in HDInsight.
Verwenden Sie Apache Livy, um einen Anwendungsauftrag remote an den Spark-Cluster zu übermitteln. Spark-Cluster in HDInsight enthalten Livy, um REST-Endpunkte für die Remoteübermittlung von Spark-Aufträgen verfügbar zu machen. Weitere Informationen finden Sie unter Übermitteln von Remoteaufträgen an einen HDInsight Spark-Cluster mithilfe der Apache Spark-REST-API.
Bereinigen von Ressourcen
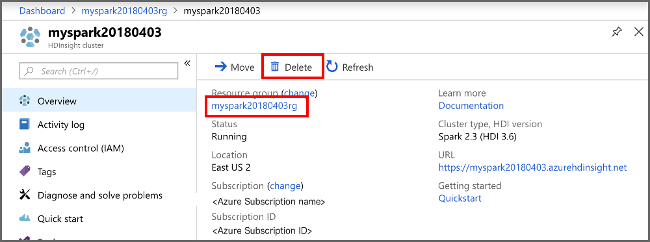
Wenn Sie diese Anwendung nicht mehr benötigen, gehen Sie wie folgt vor, um den erstellten Cluster zu löschen:
Melden Sie sich beim Azure-Portal an.
Geben Sie oben im Suchfeld den Suchbegriff HDInsight ein.
Wählen Sie unter Dienste die Option HDInsight-Cluster aus.
Klicken Sie in der daraufhin angezeigten Liste mit den HDInsight-Clustern neben dem Cluster, den Sie für dieses Tutorial erstellt haben, auf die Auslassungspunkte ( ... ).
Klicken Sie auf Löschen. Wählen Sie Ja aus.
Nächster Schritt
In diesem Artikel haben Sie gelernt, wie eine Apache Spark Scala-Anwendung erstellt wird. Im nächsten Artikel erfahren Sie, wie Sie diese Anwendung in einem HDInsight Spark-Cluster mit Livy ausführen.