Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
HDInsight Spark-Cluster bieten Kernels, die Sie mit dem Jupyter Notebook in Apache Spark zum Testen Ihrer Anwendungen verwenden können. Ein Kernel ist ein Programm, das ausgeführt wird und Ihren Code interpretiert. Folgende drei Kernel sind verfügbar:
- PySpark: für in Python 2 geschriebene Anwendungen. (Gilt nur für Cluster mit der Spark-Version 2.4)
- PySpark3: für in Python 3 geschriebene Anwendungen.
- Spark: für in Scala geschriebene Anwendungen.
In diesem Artikel erfahren Sie, wie Sie diese Kernels verwenden und welche Vorteile sie bieten.
Voraussetzungen
Einen Apache Spark-Cluster unter HDInsight Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Erstellen eines Jupyter Notebooks unter Spark HDInsight
Wählen Sie im Azure-Portal Ihren Spark-Cluster aus. Anweisungen dazu finden Sie unter Auflisten und Anzeigen von Clustern. Die Übersicht wird geöffnet.
Wählen Sie in der Übersicht im Feld Clusterdashboards die Option Jupyter Notebook aus. Geben Sie die Administratoranmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden.
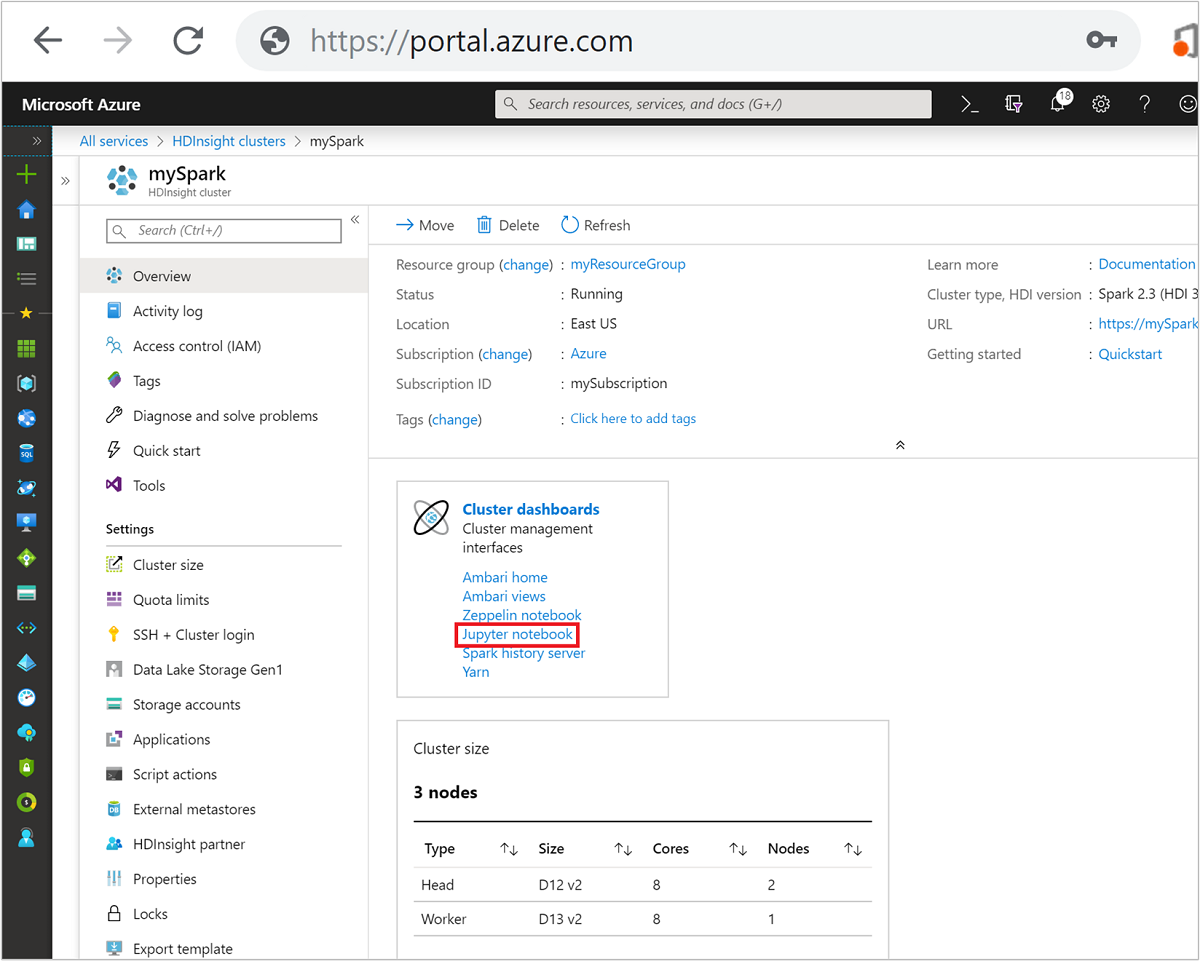
Hinweis
Sie können das Jupyter Notebook im Spark-Cluster auch aufrufen, indem Sie in Ihrem Browser die folgende URL öffnen. Ersetzen Sie CLUSTERNAME durch den Namen Ihres Clusters:
https://CLUSTERNAME.azurehdinsight.net/jupyterWählen Sie Neu und anschließend entweder Pyspark, PySpark3 oder Spark aus, um ein Notebook zu erstellen. Der Spark-Kernel ist für Scala-Anwendungen vorgesehen, der PySpark-Kernel für Python2-Anwendungen und der PySpark3-Kernel für Python3-Anwendungen.
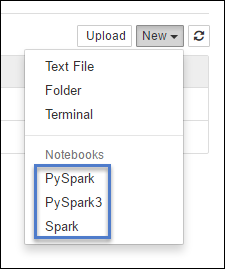
Hinweis
Für Spark 3.1 ist nur PySpark3 oder Spark verfügbar.
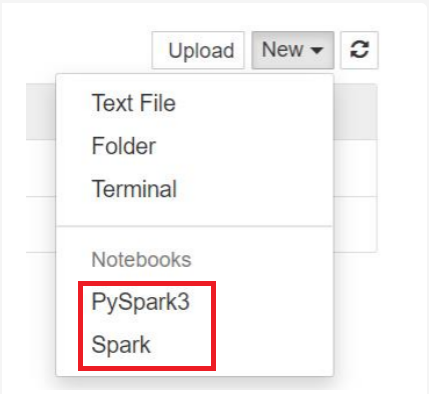
- Mit dem gewählten Kernel wird ein Notebook geöffnet.
Vorteile der Kernelverwendung
Hier sind einige Vorteile der Verwendung der neuen Kernel mit einem Jupyter Notebook in Spark HDInsight-Clustern.
Voreingestellte Kontexte Bei Verwendung der PySpark-, PySpark3- oder Spark-Kernel müssen Sie die Spark- oder Hive-Kontexte nicht mehr explizit festlegen, um mit Ihren Anwendungen arbeiten zu können. Diese Kontexte sind standardmäßig verfügbar. Diese Kontexte sind:
sc (Spark-Kontext)
sqlContext – für Hive-Kontext
Sie müssen also keine Anweisungen wie die folgenden ausführen, um die Kontexte festzulegen:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Stattdessen können Sie in Ihrer Anwendung direkt die vordefinierten Kontexte verwenden.
Zellen-Magics Der PySpark-Kernel bietet einige vordefinierte „Magics“, spezielle Befehle, die Sie mit
%%(z. B.%%MAGIC<args>) aufrufen können. Der Magic-Befehl muss das erste Wort in einer Codezelle sein und ermöglicht mehrere Inhaltszeilen. Das Magic-Wort sollte das erste Wort in der Zelle sein. Beliebige Hinzufügungen vor dem Magic, auch Kommentare, verursachen einen Fehler. Weitere Informationen zu Magics finden Sie hier.In der folgenden Tabelle sind die verschiedenen über den Kernel verfügbaren Magics aufgeführt.
Magic Beispiel BESCHREIBUNG help %%helpGeneriert eine Tabelle mit allen verfügbaren Magics mit Beispiel und Beschreibung. info %%infoGibt Sitzungsinformationen für den aktuellen Livy-Endpunkt heraus. KONFIGURIEREN %%configure -f{"executorMemory": "1000M","executorCores": 4}Konfiguriert die Parameter für das Erstellen einer neuen Sitzung. Das Erzwingungsflag ( -f) ist obligatorisch, wenn bereits eine Sitzung erstellt wurde, um sicherzustellen, dass die Sitzung gelöscht und neu erstellt wird. Unter „Request Body“ in „POST /sessions“ für Livy finden Sie eine Liste der gültigen Parameter. Parameter müssen als JSON-Zeichenfolge übergeben werden und in der nächsten Zeile nach dem Magic-Befehl stehen, wie in der Beispielspalte gezeigt.sql %%sql -o <variable name>
SHOW TABLESFührt eine Hive-Abfrage für sqlContext aus. Wenn der Parameter -oübergeben wird, wird das Ergebnis der Abfrage im %%local-Python-Kontext als Pandas -Dataframe beibehalten.local %%locala=1Der gesamte Code in späteren Zeilen wird lokal ausgeführt. Der Code muss gültiger Python 2-Code sein, unabhängig vom verwendeten Kernel. Sogar wenn Sie beim Erstellen des Notebooks PySpark3- oder Spark-Kernels gewählt haben und die %%local-Magic in einer Zelle verwenden, darf diese Zelle nur gültigen Python2-Code enthalten.logs %%logsGibt die Protokolle für die aktuelle Livy-Sitzung aus. delete %%delete -f -s <session number>Löscht eine bestimmte Sitzung des aktuellen Livy-Endpunkts. Die Sitzung, die für den Kernel selbst initiiert wird, können Sie nicht löschen. cleanup %%cleanup -fLöscht alle Sitzungen für den aktuellen Livy-Endpunkt, einschließlich dieser Notebook-Sitzung. Das Force-Flag „-f“ ist obligatorisch Hinweis
Zusätzlich zu den Magics, die durch den PySpark-Kernel hinzugefügt werden, können Sie auch die integrierten IPython-Magics verwenden, einschließlich
%%sh. Sie können das Magic%%shverwenden, um Skripts und Codeblöcke auf dem Clusterhauptknoten auszuführen.Automatische Visualisierung. Der Pyspark-Kernel visualisiert automatisch die Ausgabe von Hive- und SQL-Abfragen. Sie können zwischen verschiedenen Arten von Visualisierungen wählen, inklusive Tabelle, Kreis-, Linie-, Flächen- und Balkendiagramm.
Mit %%sql-Magic unterstützte Parameter
Die %%sql-Magic unterstützt verschiedene Parameter, mit denen Sie steuern können, welche Art der Ausgabe Sie erhalten, wenn Sie Abfragen ausführen. In der folgenden Tabelle werden die Ausgaben aufgeführt.
| Parameter | Beispiel | BESCHREIBUNG |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Verwenden Sie diesen Parameter, um das Ergebnis der Abfrage im %%local-Python-Kontext als Pandas -Dataframe beizubehalten. Der Name der Datenrahmenvariablen ist der Variablenname, den Sie angeben. |
| -q | -q |
Verwenden Sie diesen Parameter, um die Visualisierungen für die Zelle zu deaktivieren. Wenn Sie den Inhalt einer Zelle nicht automatisch visualisieren, sondern einfach als Dataframe erfassen möchten, verwenden Sie -q -o <VARIABLE>. Wenn Sie Visualisierungen deaktivieren möchten, ohne die Ergebnisse zu erfassen (z.B. zum Ausführen einer SQL-Abfrage wie etwa einer CREATE TABLE-Anweisung), verwenden Sie einfach -q ohne Angabe eines -o-Arguments. |
| -M | -m <METHOD> |
Dabei ist METHOD entweder take oder sample (der Standardwert ist take). Wenn die Methode take ist, wählt der Kernel Elemente von der obersten Position des Ergebnisdatasets gemäß MAXROWS (weiter unten in dieser Tabelle beschrieben) aus. Wenn die Methode sample ist, wählt der Kernel nach dem Zufallsprinzip Elemente des Datasets gemäß des -r-Parameters, der in dieser Tabelle beschrieben wird. |
| -r | -r <FRACTION> |
Hier ist FRACTION eine Gleitkommazahl zwischen 0,0 und 1,0. Wenn die Methode für die SQL-Abfrage sample ist, dann wählt der Kernel nach dem Zufallsprinzip den angegebenen Bruchteil der Elemente des Resultsets aus. Wenn Sie z.B. eine SQL-Abfrage mit den Argumenten -m sample -r 0.01 ausführen, wird 1% der Ergebniszeilen nach dem Zufallsprinzip entnommen. |
| -n | -n <MAXROWS> |
MAXROWS ist ein Ganzzahlwert. Der Kernel schränkt die Anzahl der Ausgabezeilen auf MAXROWS ein. Wenn MAXROWS eine negative Zahl ist, z.B. -1, dann ist die Anzahl der Zeilen im Resultset nicht begrenzt. |
Beispiel:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
Die obige Anweisung führt folgende Aktionen aus:
- Wählt alle Datensätze aus hivesampletableaus.
- Da wir „-q“ verwenden, wird die automatische Visualisierung deaktiviert.
- Da wir
-m sample -r 0.1 -n 500verwenden, werden nach dem Zufallsprinzip 10 % der Zeilen in „hivesampletable“ ausgewählt, und die Größe des Resultsets wird auf 500 Zeilen beschränkt. - Da wir
-o query2verwendet haben, wird schließlich auch die Ausgabe in einem Dataframe namens query2gespeichert.
Überlegungen bei der Verwendung der neuen Kernel
Unabhängig vom verwendeten Kernel werden von ausgeführten Notebooks immer Clusterressourcen beansprucht. Da die Kontexte für diese Kernels voreingestellt sind, wird der Kontext durch ein einfaches Beenden der Notebooks nicht ebenfalls beendet. Die Clusterressourcen werden somit weiterhin verwendet. Es wird empfohlen, nach der Verwendung des Notebooks die Option zum Schließen und Anhalten im Menü Datei zu verwenden. Durch das Schließen wird die Beendigung des Kontexts erzwungen und das Notebook beendet.
Wo werden die Notebooks gespeichert?
Wenn Ihr Cluster Azure Storage als Standardspeicherkonto verwendet, werden Jupyter Notebooks unter dem Ordner /HdiNotebooks im Speicherkonto gespeichert. Der Zugriff auf Notebooks, Textdateien und Ordner, die Sie in Jupyter erstellen, erfolgt über das Speicherkonto. Wenn Sie z. B. Jupyter verwenden, um den Ordner myfolder und das Notebook myfolder/mynotebook.ipynb zu erstellen, können Sie im Speicherkonto unter /HdiNotebooks/myfolder/mynotebook.ipynb auf dieses Notebook zugreifen. Das gilt auch umgekehrt, d.h. wenn Sie ein Notebook direkt in Ihr Speicherkonto unter /HdiNotebooks/mynotebook1.ipynb hochladen, ist das Notebook auch von Jupyter aus sichtbar. Die Notebooks verbleiben im Speicherkonto, auch nachdem der Cluster gelöscht wurde.
Hinweis
HDInsight-Cluster mit Azure Data Lake Storage als Standardspeicher speichern Notebooks nicht im zugehörigen Speicher.
Der Vorgang des Speicherns von Notebooks im Speicherkonto ist mit Apache Hadoop HDFS kompatibel. Wenn Sie eine SSH-Verbindung mit dem Cluster herstellen, können Sie die Dateiverwaltungsbefehle verwenden:
| Get-Help | BESCHREIBUNG |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Alle Elemente im Stammverzeichnis auflisten – alles in diesem Verzeichnis ist auf der Homepage für Jupyter sichtbar. |
hdfs dfs –copyToLocal /HdiNotebooks |
# Herunterladen des Inhalts des Ordners „HdiNotebooks“ |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Hochladen eines Notebooks „example.ipynb“ in den Stammordner, damit es aus Jupyter sichtbar ist. |
Unabhängig davon, ob der Cluster Azure Storage oder Azure Data Lake Storage als Standardspeicherkonto verwendet, werden die Notebooks auch auf dem Clusterhauptknoten unter /var/lib/jupyter gespeichert.
Unterstützte Browser
Jupyter Notebooks in Spark HDInsight-Clustern werden nur von Google Chrome unterstützt.
Vorschläge
Die neuen Kernels befinden sich in der Entwicklungsphase und werden mit der Zeit ausreifen. Im Lauf dieser Entwicklung werden unter Umständen auch die APIs geändert. Wir freuen uns über Ihr Feedback zur Verwendung der neuen Kernel. Das Feedback hilft uns bei der Gestaltung des endgültigen Kernelrelease. Kommentare/Feedback können Sie im Feedbackabschnitt am Ende dieses Artikels hinterlassen.
Nächste Schritte
- Übersicht: Apache Spark in Azure HDInsight
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)