Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
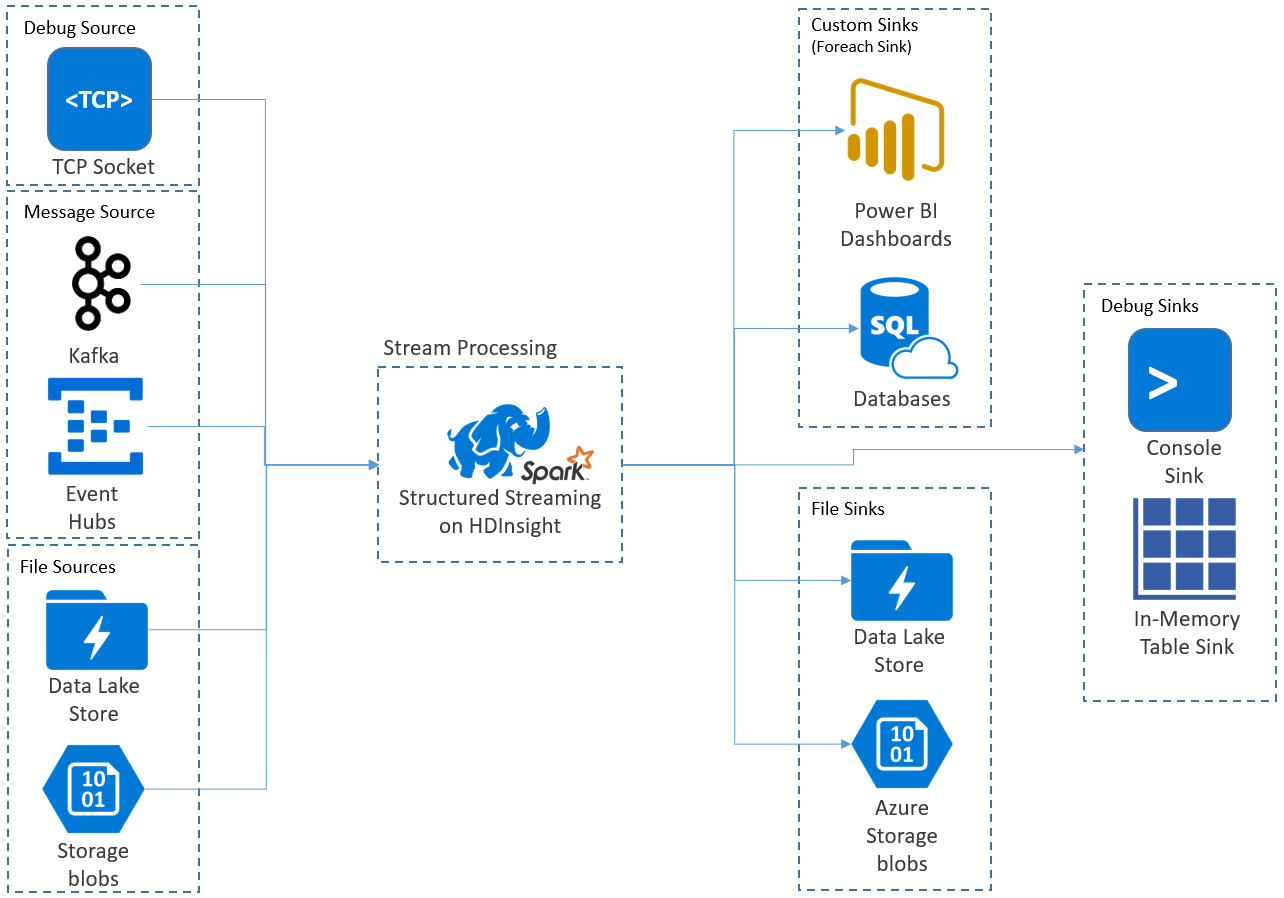
Mit dem strukturierten Apache Spark-Streaming können Sie skalierbare und fehlertolerante Anwendungen mit hohem Durchsatz zur Verarbeitung von Datenströmen implementieren. Strukturiertes Streaming basiert auf dem Spark SQL-Modul und verbessert die Konstrukte aus Spark SQL-Datenrahmen und -Datasets, damit Sie Streamingabfragen genauso schreiben können wie Batchabfragen.
Anwendungen für strukturiertes Streaming werden auf HDInsight Spark-Clustern ausgeführt und stellen mit Streamingdaten von Apache Kafka, einem TCP-Socket (für Debugzwecke), Azure Storage oder Azure Data Lake Storage Verbindungen her. Die letzten beiden Optionen, die auf externen Speicherdiensten basieren, ermöglichen Ihnen, nach neu im Speicher hinzugefügten Dateien zu suchen und ihre Inhalte so zu verarbeiten, als ob sie per Stream übertragen würden.
In Structured Streaming wird eine Abfrage mit langer Ausführungszeit erstellt, während der Vorgänge wie die Auswahl, die Projektion, die Aggregation, das Windowing und die Verknüpfung des streamenden mit dem referenzierten DataFrame auf die Eingabedaten angewendet werden. Als Nächstes geben Sie die Ergebnisse mithilfe von benutzerdefiniertem Code an den Dateispeicher (Azure Storage Blob-Instanzen oder Data Lake Storage) oder einen beliebigen Datenspeicher (z.B. SQL-Datenbank oder Power BI) aus. Structured Streaming stellt auch die Ausgabe an die Konsole für lokales Debuggen und ebenso für eine In-Memory-Tabelle bereit, damit Sie die für das Debuggen generierten Daten in HDInsight sehen können.
Hinweis
Spark Structured Streaming löst Spark Streaming (DStreams) ab. In Zukunft werden für Structured Streaming Verbesserungen und Wartung geboten, während DStreams nur im Wartungsmodus bleibt. Da Structured Streaming derzeit nicht so vollständig ist wie DStreams, was die einsatzbereiten Features für Quellen und Senken betrifft, bewerten Sie Ihre Anforderungen, um die geeignete Spark-Streamverarbeitungsoption auszuwählen.
Streams als Tabellen
Strukturiertes Spark-Streaming stellt einen Datenstrom als Tabelle mit unbegrenztem Umfang dar, d. h., die Tabelle wächst mit neu eintreffenden Daten. Diese Eingabetabelle wird durch eine Abfrage mit langer Ausführungszeit kontinuierlich verarbeitet, und die Ergebnisse werden an eine Ausgabetabelle gesendet:

In Structured Streaming werden die im System eingehenden Daten sofort in einer Eingabetabelle erfasst. Sie schreiben Abfragen (mit Datenrahmen- und Dataset-API), mit denen Vorgänge für diese Eingabetabelle ausgeführt werden. Die Abfrageausgabe erfolgt in einer anderen Tabelle, der Ergebnistabelle. Die Ergebnistabelle enthält die Ergebnisse Ihrer Abfrage, aus denen Sie Daten für einen externen Datenspeicher, z.B. eine relationale Datenbank, beziehen. Wann Daten aus der Eingabetabelle verarbeitet werden, wird mit dem Triggerintervall festgelegt. Standardmäßig ist das Triggerintervall null (0), also versucht Structured Streaming, die Daten sofort bei Eintreffen zu verarbeiten. In der Praxis bedeutet dies, dass Structured Streaming sofort nach Verarbeitung einer Abfrage mit einer weiteren Verarbeitung neu empfangener Daten beginnt. Sie können den Trigger zur Ausführung in einem Intervall konfigurieren, sodass die Streamingdaten in zeitbasierten Batches verarbeitet werden.
In den Ergebnistabellen können nur die Daten enthalten sein, die seit der letzten Verarbeitung der Abfrage neu hinzugekommen sind (Anfügemodus), oder die Tabelle kann bei jedem Eingang neuer Daten aktualisiert werden, sodass die Ergebnistabelle alle Ausgabedaten seit dem Start der Streamingabfrage enthält (vollständiger Modus).
Anfügemodus
Im Anfügemodus sind nur die Zeilen, die seit der letzten Abfrageausführung der Ergebnistabelle hinzugefügt wurden, in der Ergebnistabelle vorhanden, und nur sie werden in den externen Speicher geschrieben. Die einfachste Abfrage kopiert beispielsweise alle Daten unverändert aus der Eingabe- in die Ergebnistabelle. Jedes Mal, wenn ein Triggerintervall abläuft, werden die neuen Daten verarbeitet, und die Zeilen, die diese neuen Daten darstellen, werden in der Ergebnistabelle angezeigt.
Stellen Sie sich ein Szenario vor, in dem Sie Telemetriedaten aus Temperatursensoren verarbeiten, z. B. von einem Thermostat. Nehmen Sie an, dass der erste Trigger zum Zeitpunkt 00:01 ein Ereignis für Gerät 1 mit einem Temperaturmesswert von 95 Grad verarbeitet hat. Im ersten Abfragetrigger wird nur die Zeile mit dem Zeitpunkt 00:01 in der Ergebnistabelle angezeigt. Für den Zeitpunkt 00:02, als ein weiteres Ereignis eingeht, ist die einzige neue Zeile die Zeile mit dem Zeitpunkt 00:02, sodass die Ergebnistabelle nur diese eine Zeile enthält.
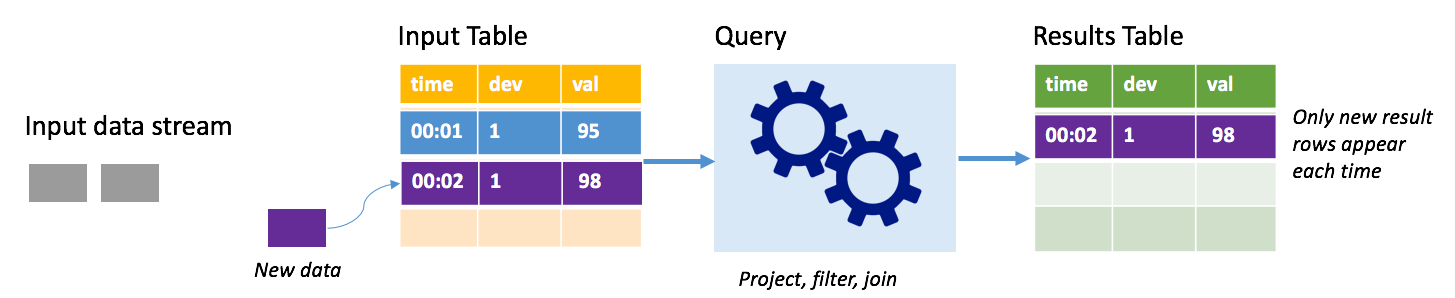
Bei Verwendung des Anfügemodus würde die Abfrage Projektionen anwenden (Auswählen der Spalten von Interesse), filtern (nur Auswählen der Zeilen, die bestimmten Bedingungen entsprechen) oder verknüpfen (die Daten mit Daten aus einer statischen Nachschlagetabelle erweitern). Im Anfügemodus können ganz unkompliziert nur die relevanten neuen Datenpunkte in den externen Speicher gepusht werden.
Vollständiger Modus
Stellen Sie sich das gleiche Szenario vor, dieses Mal jedoch im vollständigen Modus. Im vollständigen Modus wird die gesamte Ausgabetabelle bei jedem Trigger aktualisiert, sodass die Tabelle nicht nur Daten aus dem letzten Trigger enthält, sondern aus allen Ausführungen. Mit dem vollständigen Modus können Sie die Daten unverändert aus der Eingabe- in die Ergebnistabelle kopieren. Bei jeder ausgelösten Ausführung werden die neuen Ergebniszeilen zusammen mit allen vorherigen Zeilen angezeigt. In der Ausgabeergebnistabelle werden alle Daten gespeichert, die seit Beginn der Abfrage gesammelt wurden, und irgendwann würde Ihnen der Arbeitsspeicher ausgehen. Der vollständige Modus dient zur Verwendung mit Aggregatabfragen, die die eingehenden Daten in irgendeiner Weise zusammenfassen, sodass bei jedem Trigger die Ergebnistabelle mit einer neuen Zusammenfassung aktualisiert wird.
Angenommen, dass die Daten der ersten fünf Sekunden bereits verarbeitet wurden und dass es an der Zeit ist, die Daten der sechsten Sekunde zu verarbeiten. Die Eingabetabelle enthält Ereignisse für die Zeitpunkte 00:01 und 00:03. Das Ziel dieser Beispielabfrage besteht darin, alle fünf Sekunden die Durchschnittstemperatur des Geräts zu ermitteln. Bei der Implementierung dieser Abfrage wird ein Aggregat angewandt, das alle Werte entgegennimmt, die innerhalb des jeweiligen 5-Sekunden-Intervalls liegen. Dann ermittelt es die Durchschnittstemperatur und erzeugt eine Zeile für die Durchschnittstemperatur dieses Zeitintervalls. Am Ende des ersten 5-Sekunden-Fensters gibt es zwei Tupel: (00:01, 1, 95) und (00:03, 1, 98). Für das Fenster 00:00-00:05 erstellt die Aggregation ein Tupel mit der Durchschnittstemperatur 96,5 Grad. Im nächsten 5-Sekunden-Intervall gibt es nur einen Datenpunkt beim Zeitpunkt 00:06, sodass die resultierende Durchschnittstemperatur 98 Grad beträgt. Zum Zeitpunkt 00:10 enthält die Ergebnistabelle im vollständigen Modus die Zeilen für beide Intervalle (00:00-00:05 und 00:05 00:10), da die Abfrage alle aggregierten Zeilen ausgibt, nicht nur die neuen. Aus diesem Grund wächst die Ergebnistabelle weiter an, indem neue Fenster hinzugefügt werden.
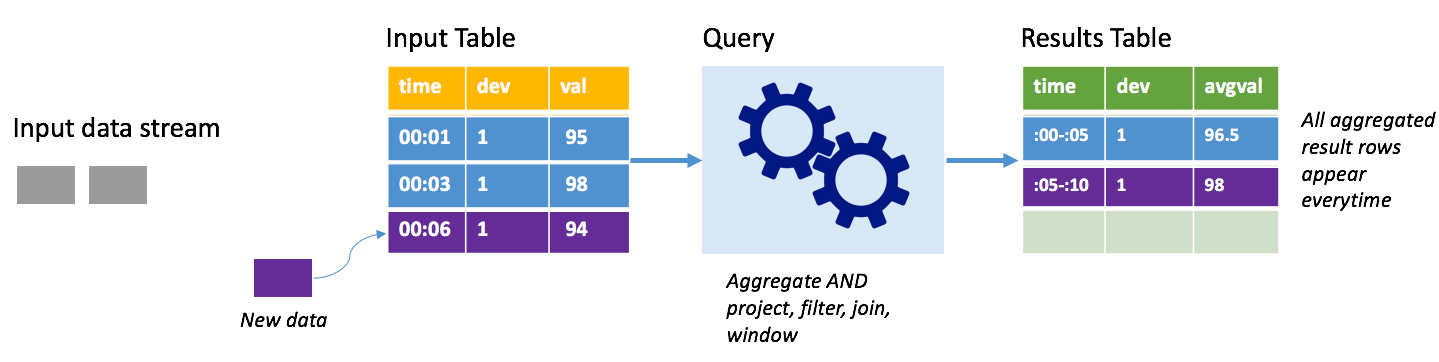
Nicht alle Abfragen im vollständigen Modus führen dazu, dass die Tabelle unbegrenzt wächst. Stellen Sie sich vor, im vorherigen Beispiel sei die Durchschnittstemperatur nicht nach dem Zeitfenster, sondern der Geräte-ID berechnet worden. Die Ergebnistabelle enthält eine feste Anzahl von Zeilen (eine pro Gerät) mit der Durchschnittstemperatur für das Gerät von allen Datenpunkten, die von diesem Gerät empfangen wurden. Wenn neue Temperaturen empfangen werden, wird die Ergebnistabelle aktualisiert, damit die Durchschnittswerte in der Tabelle immer aktuell sind.
Komponenten einer Spark Structured Streaming-Anwendung
Eine einfache Beispielabfrage kann die Temperaturmesswerte von einstündigen Fenstern zusammenfassen. In diesem Fall werden die Daten in Azure Storage (als Standardspeicher für das HDInsight-Cluster angefügt) in JSON-Dateien gespeichert:
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Diese JSON-Dateien werden im Unterordner temps unter dem Container des HDInsight-Clusters gespeichert.
Definieren der Eingabequelle
Zunächst konfigurieren Sie einen Datenrahmen, der die Quelle der Daten und alle Einstellungen beschreibt, die diese Quelle erfordert. In diesem Beispiel dienen die JSON-Dateien in Azure Storage als Datenquelle und es wird zur Lesezeit ein Schema auf sie angewendet.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Anwenden der Abfrage
Führen Sie als Nächstes eine Abfrage des Streamingdatenrahmens aus, die die gewünschten Vorgänge enthält. In diesem Fall gruppiert eine Aggregation alle Zeilen in 1-Stunden-Fenstern und berechnet dann die minimale, durchschnittliche und maximale Temperatur in diesem 1-Stunden-Fenster.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definieren der Ausgabesenke
Definieren Sie als Nächstes das Ziel für die Zeilen, die der Ergebnistabelle in jedem Triggerintervall hinzugefügt werden. Dieses Beispiel gibt nur alle Zeilen in eine In-Memory-Tabelle temps aus, die Sie später mit Spark SQL abfragen können. Im vollständigen Ausgabemodus wird sichergestellt, dass immer alle Zeilen für alle Fenster ausgegeben werden.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Starten der Abfrage
Starten Sie die Streamingabfrage, und führen Sie sie aus, bis ein Beendigungssignal empfangen wird.
val query = streamingOutDF.start()
Anzeigen der Ergebnisse
Während die Abfrage ausgeführt wird, könnenSie in derselben SparkSession eine SparkSQL-Abfrage der -Tabelle ausführen, in der die Ergebnisse der Abfrage gespeichert werden.
select * from temps
Die Ergebnisse dieser Abfrage sehen in etwa wie folgt aus:
| Fenster | min(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Weitere Informationen zur API für strukturierte Spark-Streams finden Sie zusammen mit den unterstützten Eingabedatenquellen, Vorgängen und Ausgabesenken im Programmierhandbuch für strukturiertes Apache Spark-Streaming (in englischer Sprache).
Prüfpunkte und Write-Ahead-Protokolle
Um Resilienz und Fehlertoleranz zu gewährleisten, stellt das Structured Streaming mithilfe von Prüfpunkten sicher, dass die Datenstromverarbeitung auch bei Knotenfehlern kontinuierlich durchgeführt werden kann. In HDInsight erstellt Spark Prüfpunkte in permanentem Speicher, entweder Azure Storage oder Data Lake Storage. Diese Prüfpunkte speichern die Statusinformationen über die Streamingabfrage. Darüber hinaus verwendet Structured Streaming ein Write-Ahead-Protokoll (Write-Ahead Log, WAL). Das WAL erfasst Daten, die empfangen, jedoch noch nicht von einer Abfrage verarbeitet wurden. Wenn ein Fehler auftritt und die Verarbeitung vom WAL neu gestartet wird, gehen keine aus der Quelle empfangenen Ereignisse verloren.
Bereitstellen von Spark-Streaminganwendungen
Sie erstellen eine Spark-Streaming-Anwendung in der Regel lokal in einer JAR-Datei und stellen sie dann in HDInsight für Spark bereit, indem Sie die JAR-Datei in den Standardspeicher kopieren, der an Ihren HDInsight-Cluster angefügt ist. Sie können Ihre Anwendung mit den Apache LIVY-REST-APIs, die in Ihrem Cluster verfügbar sind, mit einem POST-Vorgang starten. Der POST-Textkörper enthält ein JSON-Dokument, das Folgendes angibt: den Pfad zu Ihrer JAR-Datei, den Namen der Klasse, deren Hauptmethode die Streaming-Anwendung definiert und ausführt, und optional die Ressourcenanforderungen des Auftrags (z.B. die Anzahl der Executors, Speicher und Kerne) sowie alle Konfigurationseinstellungen, die Ihr Anwendungscode erfordert.
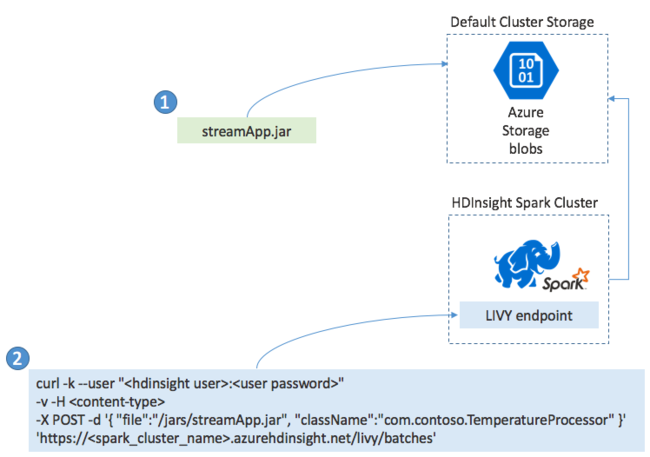
Der Status aller Anwendungen kann auch mit einer GET-Anforderung an einem LIVY-Endpunkt überprüft werden. Außerdem können Sie eine ausgeführte Anwendung durch das Senden einer DELETE-Anforderung an den LIVY-Endpunkt beenden. Weitere Informationen zur LIVY-API finden Sie unter Übermitteln von Remoteaufträgen mit Apache LIVY