Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie die Speicherverwaltung Ihres Apache Spark-Clusters für eine optimale Leistung in Azure HDInsight optimieren.
Überblick
Spark wird durch Platzieren von Daten im Arbeitsspeicher betrieben. Das Verwalten von Speicherressourcen ist daher ein wichtiger Aspekt der Optimierung der Ausführung von Spark-Aufträgen. Es gibt mehrere Techniken, die Sie anwenden können, um den Speicher Ihres Clusters effizient zu verwenden.
- Bevorzugen Sie kleinere Datenpartitionen und berücksichtigen Sie datengröße, Typen und Verteilung in Ihrer Partitionierungsstrategie.
- Berücksichtigen Sie die neuere, effizientere
Kryo data serializationund nicht die standardmäßige Java-Serialisierung. - Bevorzugen Sie die Verwendung von YARN, da es
spark-submitnach Batch trennt. - Überwachen und Optimieren von Spark-Konfigurationseinstellungen
Für Ihre Referenz werden die Spark-Speicherstruktur und einige Schlüsselausführerspeicherparameter in der nächsten Abbildung angezeigt.
Überlegungen zum Spark Memory
Wenn Sie Apache Hadoop YARN verwenden, steuert YARN den Von allen Containern auf jedem Spark-Knoten verwendeten Speicher. Das folgende Diagramm zeigt die wichtigsten Objekte und deren Beziehungen.
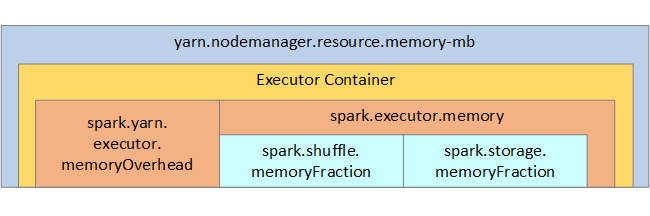
Um nachrichten außerhalb des Arbeitsspeichers zu adressieren, versuchen Sie Folgendes:
- Überprüfung von DAG-Management-Shuffles. Verringern Sie die Datenmenge durch zuordnungsseitige Reduktion, partitionieren Sie Quelldaten vorab (oder legen Sie sie in Buckets ab), maximieren Sie einzelne Shufflevorgänge, und verringern Sie die Menge an gesendeten Daten.
- Bevorzugen Sie
ReduceByKeymit seinem festen Speicherlimit stattGroupByKey, das Aggregationen, Fensterfunktionen und andere Funktionen bereitstellt, aber ein ungebundenes Speicherlimit hat. - Bevorzugen Sie
TreeReduce, das mehr Arbeit auf den Executoren oder Partitionen verrichtet, gegenüberReduce, der alle Arbeiten auf dem Treiber durchführt. - Verwenden Sie DataFrames anstelle der RDD-Objekte auf niedrigerer Ebene.
- Erstellen Sie ComplexTypes, die Aktionen kapseln, z. B. "Top N", verschiedene Aggregationen oder Fenstervorgänge.
Weitere Schritte zur Problembehandlung finden Sie unter OutOfMemoryError-Ausnahmen für Apache Spark in Azure HDInsight.