Ausführen von Batchendpunkten über Azure Data Factory
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Für Big Data ist ein Dienst zur Orchestrierung und Operationalisierung von Prozessen erforderlich, mit dem diese enormen Rohdatenmengen in verwertbare geschäftliche Erkenntnisse verwandelt werden. Azure Data Factory ist ein spezieller verwalteter Clouddienst für diese komplexen Hybridprojekte mit ETL (Extrahieren, Transformieren und Laden), ELT (Extrahieren, Laden und Transformieren) und Datenintegration.
Azure Data Factory ermöglicht die Erstellung von Pipelines, die mehrere Datentransformationen orchestrieren und als einzelne Einheit verwalten können. Batchendpunkte eignen sich hervorragend als Schritt in diesem Verarbeitungsworkflow. In diesem Beispiel erfahren Sie, wie Sie Batchendpunkte in Azure Data Factory-Aktivitäten verwenden, indem Sie die Web-Aufrufaktivität und die REST-API nutzen.
Voraussetzungen
In diesem Beispiel wird davon ausgegangen, dass ein Modell ordnungsgemäß als Batchendpunkt bereitgestellt wurde. Insbesondere verwenden Sie den Klassifizierer „heart condition“ (Herzleiden), der im Lernprogramm Verwenden von MLflow-Modellen in Batchbereitstellungen erstellt wurde.
Eine erstellte und konfigurierte Azure Data Factory-Ressource. Wenn Sie Ihre Data Factory noch nicht erstellt haben, befolgen Sie die Schritte im Schnellstart: Erstellen einer Data Factory mithilfe des Azure-Portals und Azure Data Factory Studio, um eine zu erstellen.
Navigieren Sie nach dem Erstellen zur Data Factory im Azure-Portal:

Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Datenintegrationsanwendung in einer separaten Registerkarte zu starten.
Authentifizieren bei Batchendpunkten
Azure Data Factory kann die REST-APIs von Batchendpunkten mit der Aktivität Web-Aufruf aufrufen. Batch-Endpunkte unterstützen Microsoft Entra ID für die Autorisierung, so dass die an die APIs gerichteten Anforderungen eine angemessene Authentifizierungsverarbeitung erfordern.
Sie können einen Dienstprinzipal oder eine verwaltete Identität verwenden, um sich bei Batchendpunkten zu authentifizieren. Es wird empfohlen, eine verwaltete Identität zu verwenden, da sie die Verwendung von Geheimnissen vereinfacht.
Sie können eine verwaltete Azure Data Factory-Identität verwenden, um mit Batchendpunkten zu kommunizieren. In diesem Fall müssen Sie nur sicherstellen, dass Ihre Azure Data Factory-Ressource mit einer verwalteten Identität bereitgestellt wurde.
Wenn Sie über keine Azure Data Factory-Ressource verfügen oder sie bereits ohne verwaltete Identität bereitgestellt wurde, führen Sie die folgenden Schritte aus, um sie zu erstellen: Verwaltete Identität für Azure Data Factory.
Warnung
Beachten Sie, dass das Ändern der Ressourcenidentität nach der Bereitstellung in Azure Data Factory nicht möglich ist. Nachdem die Ressource erstellt wurde, müssen Sie sie neu erstellen, wenn Sie ihre Identität ändern müssen.
Gewähren Sie nach der Bereitstellung Zugriff für die verwaltete Identität der Ressource, die Sie für Ihren Azure Machine Learning-Arbeitsbereich erstellt haben, wie unter Gewähren von Zugriff erläutert. In diesem Beispiel ist für den Dienstprinzipal Folgendes erforderlich:
- Die Berechtigung im Arbeitsbereich, Batchbereitstellungen zu lesen und Aktionen dafür auszuführen.
- Berechtigungen, in Datenspeichern zu lesen/schreiben.
- Berechtigungen zum Lesen an jedem Cloudspeicherort (in jedem Speicherkonto), der bzw. das als Dateneingabe angegeben wird.
Informationen zur Pipeline
Wir erstellen in Azure Data Factory eine Pipeline, die einen bestimmten Batchendpunkt für einige Daten aufrufen kann. Die Pipeline kommuniziert mit Azure Machine Learning-Batchendpunkten mithilfe von REST. Weitere Informationen zur Verwendung der REST-API von Batchendpunkten finden Sie unter Erstellen von Aufträgen und Eingabedaten für Batchendpunkte.
Die Pipeline sieht wie folgt aus:
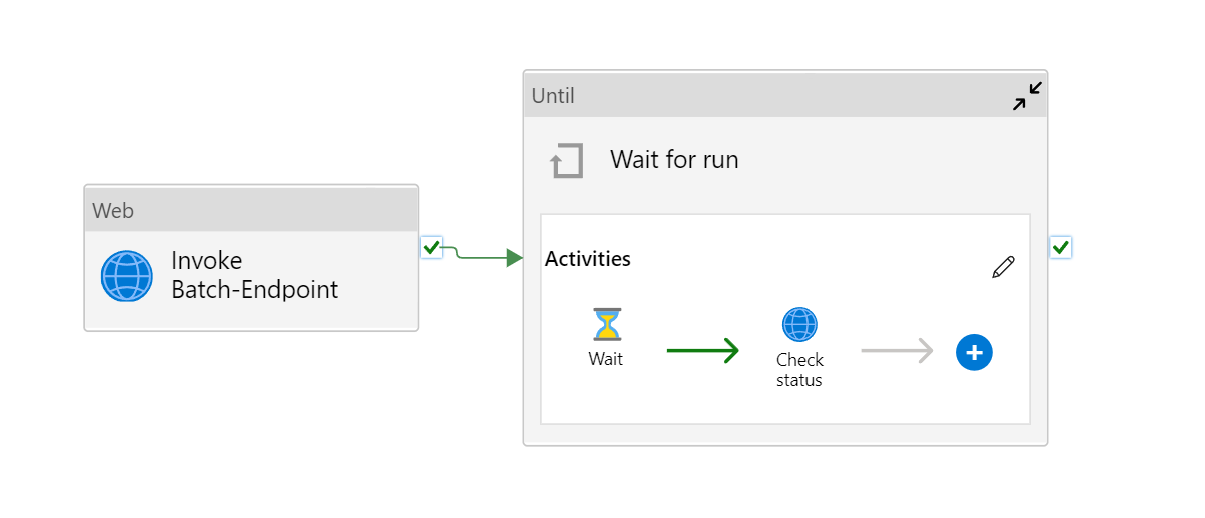
Sie besteht aus den folgenden Aktivitäten:
- Run Batch-Endpoint (Batchendpunkt ausführen): Dies ist eine Webaktivität, die den Batchendpunkt-URI für den Aufruf verwendet. Sie übergibt den Eingabedaten-URI, unter dem sich die Daten befinden, und die erwartete Ausgabedatei.
- Wait for job (Auf Auftrag warten): Dies ist eine Schleifenaktivität, die den Status des erstellten Auftrags überprüft und auf dessen Abschluss als entweder Completed (Abgeschlossen) oder Failed (Fehlgeschlagen) wartet. Diese Aktivität verwendet wiederum die folgenden Aktivitäten:
- Check status (Status überprüfen): Dies ist eine Webaktivität, die den Status der Auftragsressource abfragt, die als Antwort auf die Aktivität Run Batch-Endpoint (Batchendpunkt ausführen) zurückgegeben wurde.
- Wait (Warten): Dies ist eine Warteaktivität, die die Abrufhäufigkeit für den Auftragsstatus steuert. Wir legen einen Standardwert von 120 (2 Minuten) fest.
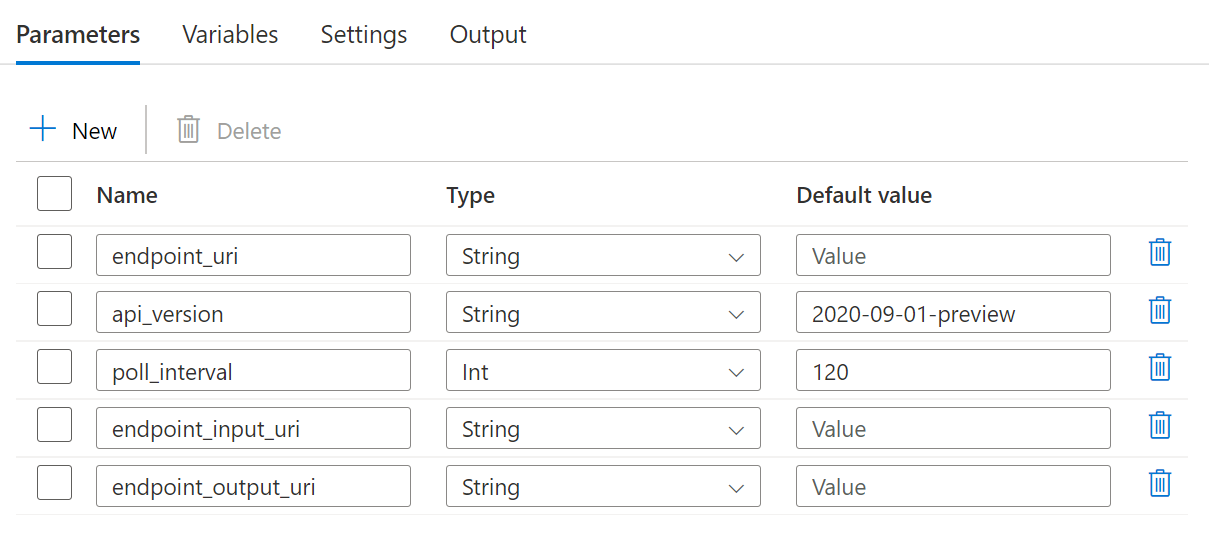
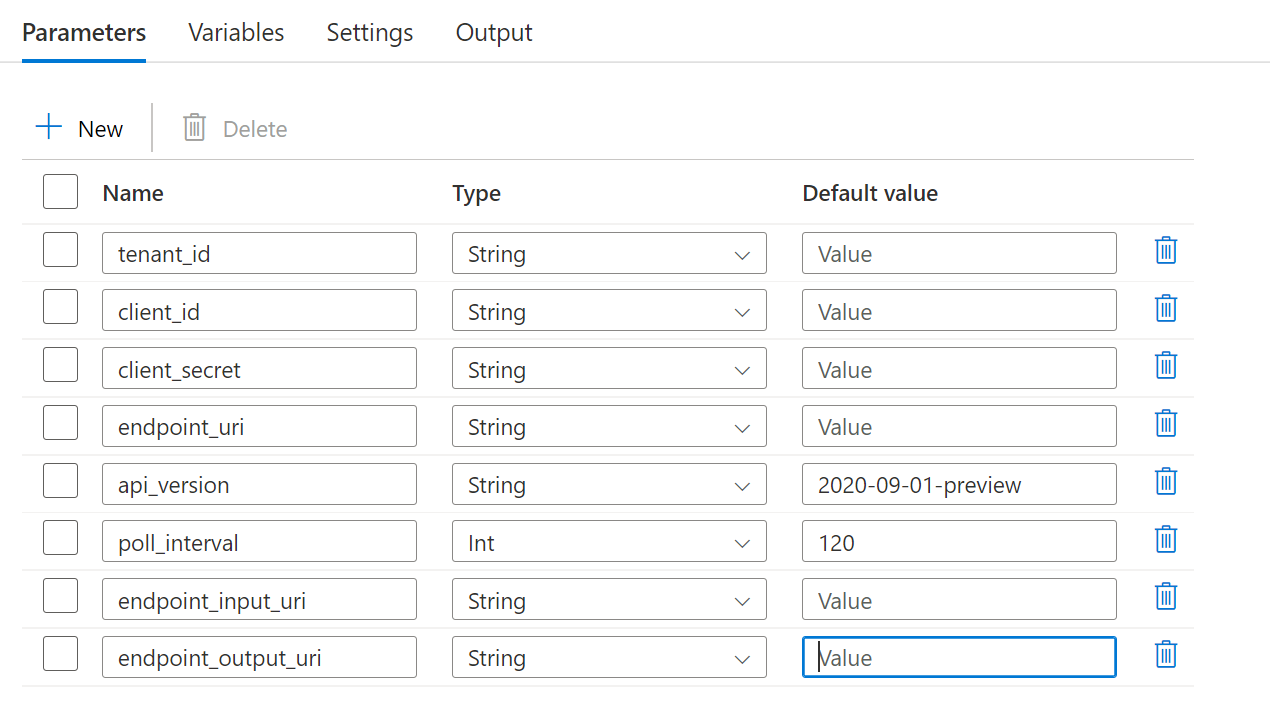
Für die Pipeline müssen die folgenden Parameter konfiguriert werden:
| Parameter | BESCHREIBUNG | Beispielwert |
|---|---|---|
endpoint_uri |
Der Endpunktbewertungs-URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Die Anzahl von Sekunden, die abgewartet werden soll, bevor der Status des Auftrags auf seinen Abschluss überprüft wird. Der Standardwert lautet 120. |
120 |
endpoint_input_uri |
Die Eingabedaten des Endpunkts. Es werden mehrere Dateneingabetypen unterstützt. Stellen Sie sicher, dass die verwaltete Identität, die Sie zum Ausführen des Auftrags verwenden, Zugriff auf den zugrunde liegenden Speicherort hat. Wenn Sie Datenspeicher verwenden, stellen Sie alternativ sicher, dass die Anmeldeinformationen dort angegeben sind. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Der Typ der Eingabedaten, die Sie bereitstellen. Derzeit unterstützen Batchendpunkte Ordner (UriFolder) und Dateien (UriFile). Wird standardmäßig auf UriFolder festgelegt. |
UriFolder |
endpoint_output_uri |
Die Ausgabedatendatei des Endpunkts. Dabei muss es sich um einen Pfad zu einer Ausgabedatei in einem Datenspeicher handeln, der an den Machine Learning-Arbeitsbereich angefügt ist. Es werden keine anderen URI-Typen unterstützt. Sie können den Azure Machine Learning-Standarddatenspeicher mit dem Namen workspaceblobstore verwenden. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |
Warnung
Denken Sie daran, dass endpoint_output_uri der Pfad zu einer Datei sein sollte, der noch nicht vorhanden ist. Andernfalls schlägt der Auftrag mit dem Fehler the path already exists (der Pfad ist bereits vorhanden) fehl.
Schritte
Um diese Pipeline in Ihrer bestehenden Azure Data Factory zu erstellen und Batchendpunkte aufzurufen, folgen Sie diesen Schritten:
Stellen Sie sicher, dass die Compute-Instanz, auf der der Batchendpunkt ausgeführt wird, über Berechtigungen zum Einbinden der Daten verfügt, die von Azure Data Factory als Eingabe bereitgestellt werden. Beachten Sie, dass der Zugriff weiterhin von der Identität gewährt wird, die den Endpunkt aufruft (in diesem Fall Azure Data Factory). Die Compute-Instanz, auf der der Batchendpunkt ausgeführt wird, muss jedoch über die Berechtigung zum Einbinden des Speicherkontos verfügen, das von Ihrer Azure Data Factory-Instanz bereitgestellt wird. Weitere Informationen finden Sie unter Zugreifen auf Speicherdienste.
Öffnen Sie Azure Data Factory Studio, und klicken Sie unter Factoryressourcen auf das Pluszeichen.
Wählen Sie Pipeline>Aus Pipelinevorlage importieren aus.
Sie werden zur Auswahl einer
zip-Datei aufgefordert. Verwenden Sie die folgende Vorlage, wenn Sie verwaltete Identitäten verwenden oder die folgende Vorlage, wenn Sie einen Dienstprinzipal verwenden.Eine Vorschau der Pipeline wird im Portal angezeigt. Klicken Sie auf Diese Vorlage verwenden.
Die Pipeline wird für Sie mit dem Namen Run-BatchEndpoint erstellt.
Konfigurieren Sie die Parameter der von Ihnen verwendeten Batchbereitstellung:
Warnung
Stellen Sie sicher, dass für Ihren Batchendpunkt eine Standardbereitstellung konfiguriert wurde, bevor Sie einen Auftrag an ihn übermitteln. Die erstellte Pipeline ruft den Endpunkt auf, und daher muss eine Standardbereitstellung erstellt und konfiguriert werden.
Tipp
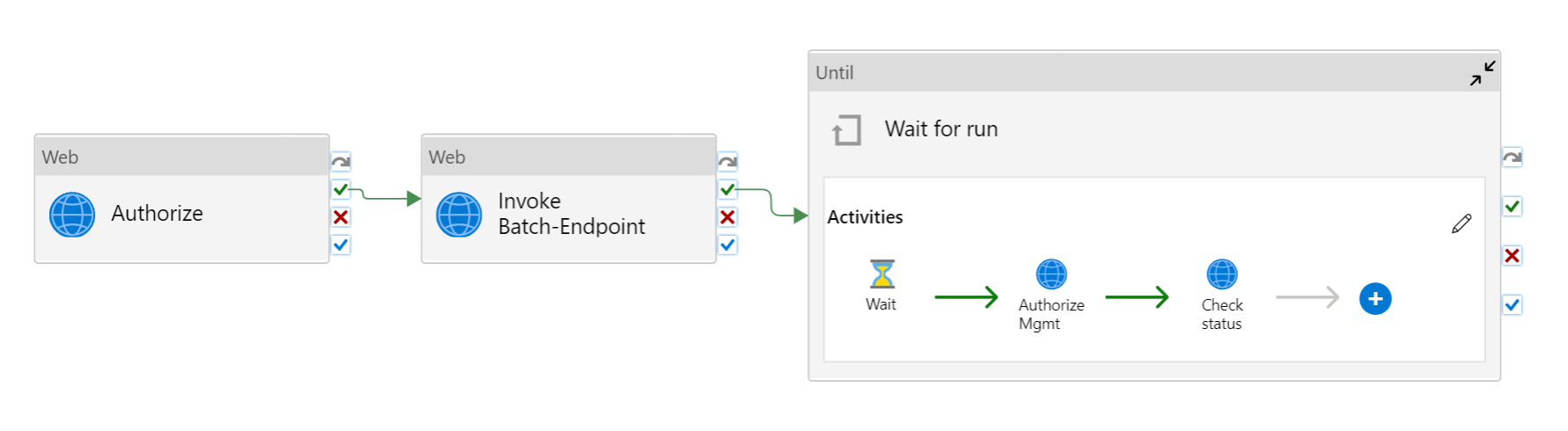
Für eine optimale Wiederverwendbarkeit verwenden Sie die erstellte Pipeline als Vorlage, und rufen Sie sie in anderen Azure Data Factory-Pipelines auf, indem Sie die Aktivität „Pipeline ausführen“ nutzen. In diesem Fall konfigurieren Sie die Parameter nicht in der inneren Pipeline, sondern übergeben sie als Parameter aus der äußeren Pipeline, wie in der folgenden Abbildung gezeigt:
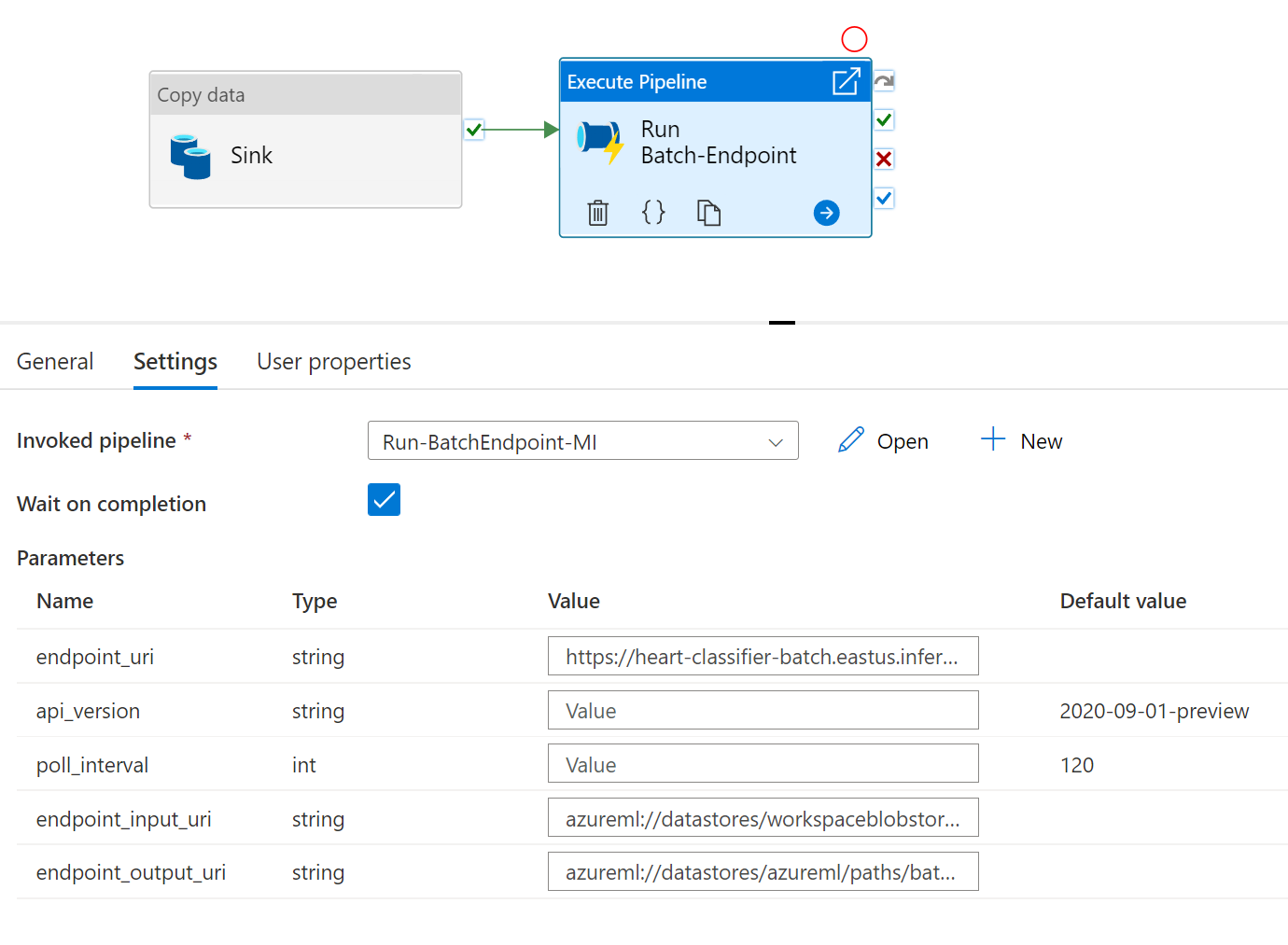
- Ihre Pipeline ist für die Verwendung bereit.
Einschränkungen
Wenn Sie Azure Machine Learning-Batchbereitstellungen aufrufen, sollten Sie die folgenden Einschränkungen berücksichtigen:
Dateneingaben
- Nur Azure Machine Learning-Datenspeicher oder Azure Storage-Konten (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) werden als Eingaben unterstützt. Wenn sich Ihre Eingabedaten in einer anderen Quelle befinden, verwenden Sie die Azure Data Factory-Kopieraktivität vor der Ausführung des Batchauftrags, um die Daten in einen kompatiblen Speicher zu senken.
- Batchendpunktaufträge untersuchen keine geschachtelten Ordner und können daher nicht mit geschachtelten Ordnerstrukturen arbeiten. Wenn Ihre Daten in mehreren Ordnern verteilt sind, müssen Sie die Struktur vereinfachen.
- Stellen Sie sicher, dass Ihr in der Bereitstellung bereitgestelltes Bewertungsskript die Daten wie erwartet verarbeiten kann, damit sie in den Auftrag aufgenommen werden. Wenn das Modell ein MLflow-Modell ist, lesen Sie die Einschränkung in Bezug auf den derzeit unterstützten Dateityp unter Verwenden von MLflow-Modellen in Batchbereitstellungen.
Datenausgaben
- Es werden derzeit nur registrierte Azure Machine Learning-Datenspeicher unterstützt. Es wird empfohlen, das Speicherkonto zu registrieren, das Ihre Azure Data Factory-Instanz als Datenspeicher in Azure Machine Learning verwendet. Auf diese Weise können Sie in dasselbe Speicherkonto zurückschreiben, aus dem Sie lesen.
- Es werden nur Azure Blob Storage-Konten für Ausgaben unterstützt. Beispielsweise wird Azure Data Lake Storage Gen2 nicht als Ausgabe in Batchbereitstellungsaufträgen unterstützt. Wenn Sie die Daten an einen anderen Speicherort/Senke ausgeben müssen, verwenden Sie die Azure Data Factory-Kopieraktivität nach der Ausführung des Batchauftrags.