Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Weitere Informationen zum Verschieben von Machine-Learning-Projekten von ML Studio (klassisch) zu Azure Machine Learning finden Sie unter Migration zu Azure Machine Learning.
- Weitere Informationen zu Azure Machine Learning
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Python ist ein wertvolles Tool im Werkzeugkasten vieler Datenanalysten. Es wird in jeder Phase typischer Workflows beim maschinellen Lernen verwendet, einschließlich des Durchsuchens von Daten, der Featureextraktion, des Modelltrainings und der Modellvalidierung sowie der Bereitstellung.
In diesem Artikel erfahren Sie, wie Sie das Modul „Execute Python Script“ (Python-Skript ausführen) nutzen können, um Python-Code in Ihren Experimenten und Webdiensten mit Machine Learning Studio (Classic) zu verwenden.
Verwenden des Execute Python Script-Moduls
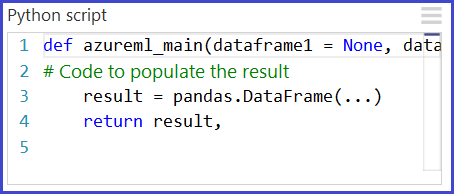
Die primäre Schnittstelle zu Python in Studio (klassisch) stellt das Modul Execute Python Script dar. Es nimmt bis zu drei Eingaben entgegen und erzeugt bis zu zwei Ausgaben, ähnlich dem Modul Execute R Script. Python-Code wird in das Parameterfeld durch eine besonders benannte Einstiegspunktfunktion mit dem Namen azureml_main eingegeben.
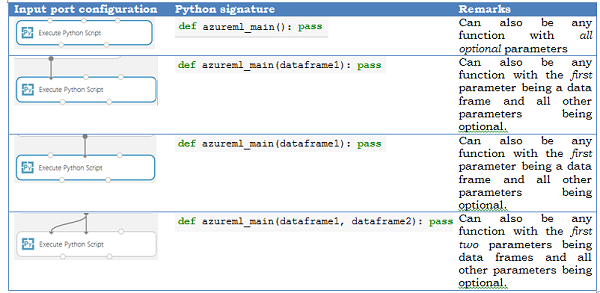
Eingabeparameter
Eingaben in das Python-Modul werden als Pandas-Datenrahmen verfügbar gemacht. Die azureml_main-Funktion akzeptiert bis zu zwei optionale Pandas-Datenrahmen als Parameter.
Die Zuordnung zwischen Eingangsports und Funktionsparametern erfolgt nach Position:
- Der erste verbundene Eingangsport wird dem ersten Parameter der Funktion zugeordnet.
- Der zweite Eingangsport (sofern verbunden) wird dem zweiten Parameter der Funktion zugeordnet.
- Die dritte Eingabe wird zum Importieren zusätzlicher Python-Module verwendet.
Eine ausführlichere Semantik zur Zuordnung der Eingangsports zu Parametern der azureml_main-Funktion wird unten dargestellt.
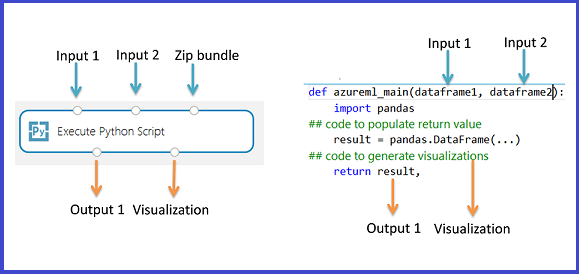
Ausgaberückgabewerte
Die azureml_main-Funktion muss einen einzelnen Pandas-Datenrahmen, verpackt in einer Python-Sequenz zurückgeben, beispielsweise in einem Tupel, einer Liste oder einem NumPy-Array. Das erste Element dieser Sequenz wird an den ersten Ausgabeport des Moduls zurückgegeben. Der zweite Ausgabeport des Moduls wird für Visualisierungen verwendet und erfordert keinen Rückgabewert. Dieses Schema ist unten dargestellt.
Übersetzung von Eingabe- und Ausgabedatentypen
Studio-Datasets sind nicht das gleiche wie Panda-Datenrahmen. Das hat zur Folge, dass Eingabe-Datensätze in Studio (klassisch) in Pandas-Datenrahmen konvertiert werden und Ausgabe-Datenrahmen in Studio (klassisch) Datensätze zurückkonvertiert werden. Während dieses Konvertierungsvorgangs werden außerdem die folgenden Übersetzungen ausgeführt:
| Python-Datentyp | Studio-Übersetzungsvorgang |
|---|---|
| Zeichenfolgen und numerische Werte | Wörtlich übersetzt |
| Pandas 'NA' | Als ‚Fehlender Wert‘ übersetzt |
| Indexvektoren | Nicht unterstützt* |
| Nicht-String-Spaltennamen |
str für Spaltennamen aufrufen |
| Doppelte Spaltennamen | Fügen Sie numerisches Suffix hinzu: (1), (2), (3) usw. |
* Alle Eingabedatenrahmen in der Python-Funktion haben stets einen numerischen 64-Bit-Index von 0 bis zur Anzahl der Zeilen minus 1
Importieren vorhandener Python-Skriptmodule
Das zum Ausführen von Python-Code verwendete Back-End basiert auf Anaconda, einer weitverbreiteten wissenschaftlichen Python-Distribution. Sie wird mit knapp 200 der gängigsten Python-Pakete geliefert, die für datenorientierte Workloads verwendet werden. Studio (klassisch) bietet aktuell keine Unterstützung für Paketverwaltungssystem wie Pip oder Conda zum Installieren und Verwalten externer Bibliotheken. Wenn die Notwendigkeit besteht, zusätzliche Bibliotheken einzubinden, verwenden Sie das folgende Szenario als Richtschnur.
Ein häufiger Anwendungsfall besteht in der Einbeziehung vorhandener Python-Skripts in Studio-Experimenten (klassisch). Das Modul Execute Python Script nimmt eine ZIP-Datei mit Python-Modulen am dritten Eingabeport entgegen. Die Datei wird zur Laufzeit vom Ausführungs-Framework entpackt, und die Inhalte werden dem Bibliothekspfad des Python-Interpreters hinzugefügt. Die azureml_main -Einstiegspunktfunktion kann diese Module anschließend direkt importieren.
Ein Beispiel wäre etwa die Datei „Hello.py“ mit einer einfachen Funktion vom Typ „Hello, World“.
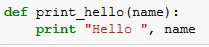
Als Nächstes erstellen wir die Datei „Hello.zip“, die „Hello.py“ enthält:

Laden Sie ZIP-Datei als Dataset in Studio (klassisch) hoch. Erstellen und führen Sie anschließend ein Experiment aus, das den Python-Code in der Datei „Hello.zip“ verwendet, indem Sie ihn mit dem dritten Eingabeport des Execute Python Script-Moduls verbinden, wie in der folgenden Abbildung dargestellt.
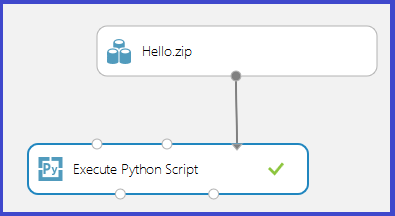
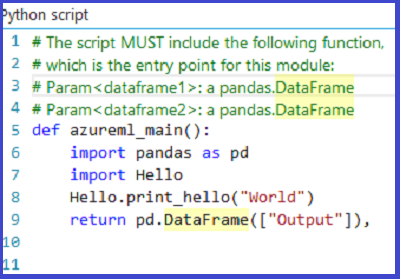
Die Modulausgabe zeigt, dass die ZIP-Datei entpackt und die Funktion print_hello ausgeführt wurde.

Zugreifen auf Azure Storage Blobs
Auf Daten, die in einem Azure Blob Storage-Konto gespeichert sind, können Sie mit diesen Schritten zugreifen:
- Laden Sie das Azure Blob Storage-Paket für Python lokal herunter.
- Laden Sie die ZIP-Datei als Dataset in Ihren (klassischen) Studio-Arbeitsbereich hoch.
- Erstellen Sie mit
protocol='http'Ihr BlobService-Objekt.
from azure.storage.blob import BlockBlobService
# Create the BlockBlockService that is used to call the Blob service for the storage account
block_blob_service = BlockBlobService(account_name='account_name', account_key='account_key', protocol='http')
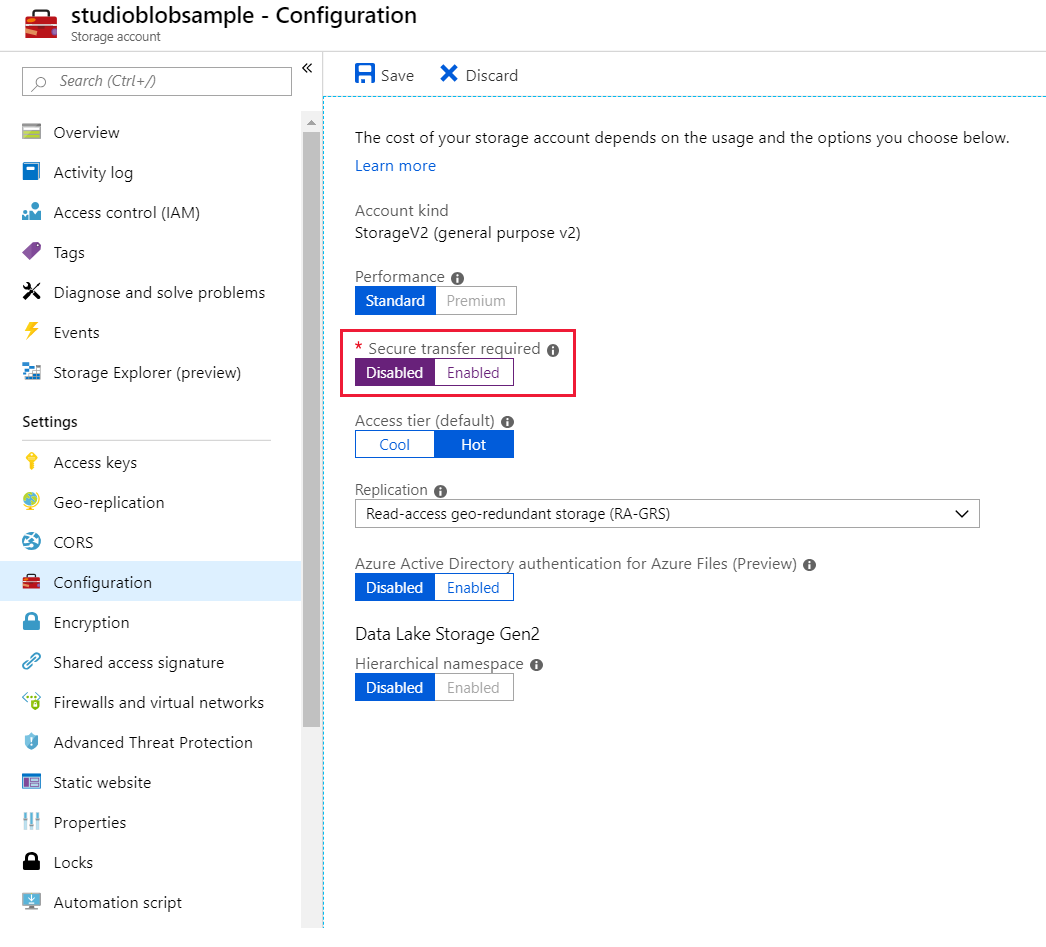
- Deaktivieren Sie auf der Einstellungsregisterkarte Konfiguration die Option Sichere Übertragung erforderlich
Operationalisieren von Python-Skripts
Alle Execute Python Script-Module in einem Bewertungsexperiment werden bei der Veröffentlichung als Webdienst aufgerufen. Die Abbildung unten zeigt beispielsweise ein Bewertungsexperiment, das den Code zum Auswerten eines einzelnen Python-Ausdrucks enthält.
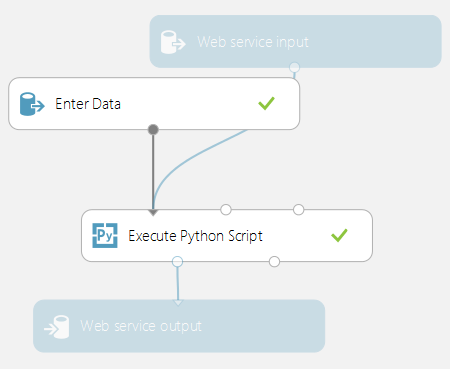
Ein aus diesem Experiment erstellter Webdienst würde die folgenden Aktionen ausführen:
- Annehmen eines Python-Ausdrucks als Eingabe (in Form einer Zeichenfolge)
- Senden des Python-Ausdrucks an den Python-Interpreter
- Rückgabe einer Tabelle, die sowohl den Ausdruck als auch das bewertete Ergebnis enthält.
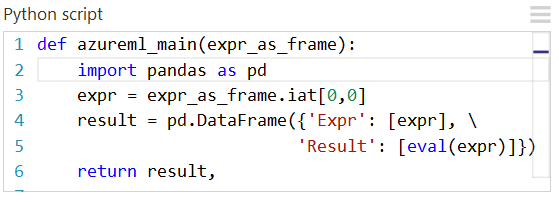
Arbeiten mit Visualisierungen
Mit MatplotLib erstellte Plots können vom Modul Execute Python Script zurückgegeben werden. Allerdings werden Plots nicht, wie bei R, automatisch in Bilder umgeleitet. Daher muss der Benutzer Plots explizit als PNG-Dateien speichern.
Um Bilder aus MatplotLib zu generieren, müssen Sie die folgenden Schritte ausführen:
- Stellen Sie das Back-End vom Qt-basierten Standardrenderer auf „AGG“ um.
- Erstellen Sie ein neues Abbildungsobjekt.
- Rufen Sie die Achse ab, und generieren Sie alle zugehörigen Plots.
- Speichern Sie die Abbildung als PNG-Datei.
Dieser Prozess wird in den folgenden Abbildungen dargestellt, in denen mithilfe der „scatter_matrix“-Funktion in Pandas eine Punktdiagramm-Matrix erstellt wird.
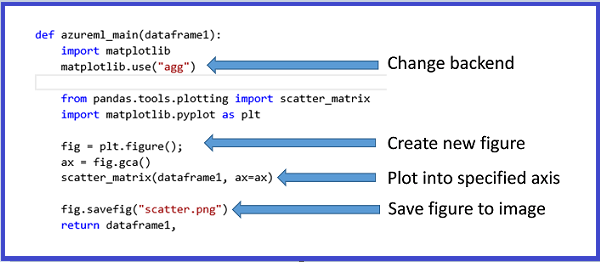
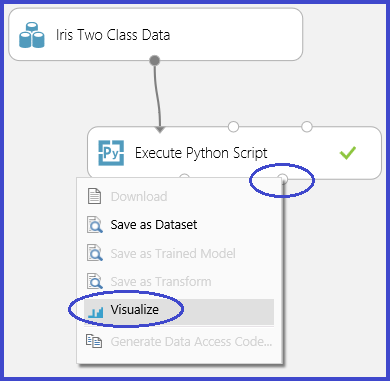
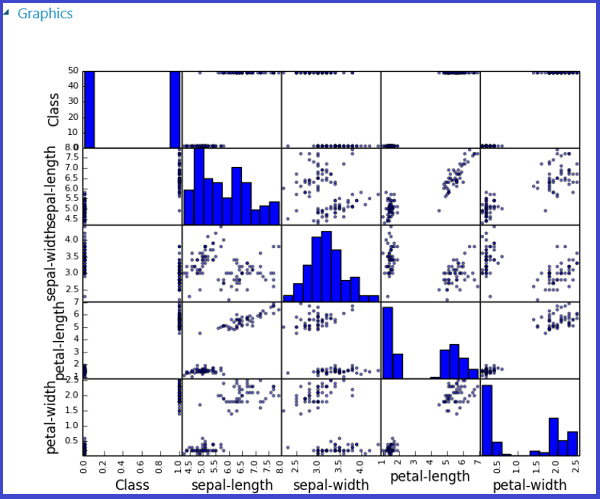
Es ist möglich, mehrere Abbildungen zurückzugeben, indem man sie als verschiedene Bilddateien speichert. Die Studio-Runtime (klassisch) nimmt alle Images auf und verkettet sie zum Zweck der Visualisierung.
Erweiterte Beispiele
Die in Studio (klassisch) installierte Anaconda-Umgebung enthält gängige Pakete wie NumPy, SciPy und Scikits-Learn. Diese Pakete können effektiv für die Datenverarbeitung in einer Machine Learning-Pipeline verwendet werden.
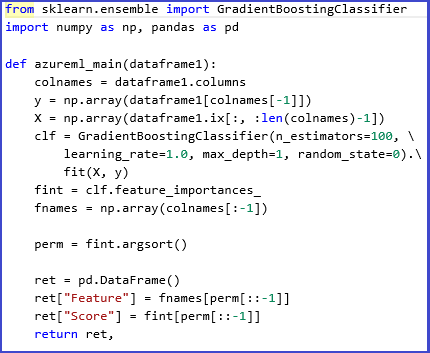
Als Beispiel veranschaulichen der folgende Versuch und das Skript die Verwendung von Ensemble-Learnern in Scikits-Learn, um Featurewichtigkeitsbewertungen für ein Dataset zu berechnen. Anhand der Punktzahlen kann dann eine überwachte Merkmalsauswahl durchgeführt werden, bevor diese in ein anderes Modell aufgenommen werden.
Dies ist die Python-Funktion zum Berechnen der Wichtigkeitsbewertungen und zum Sortieren der Features anhand der Ergebnisse:
Im folgenden Experiment werden dann die Wichtigkeitsbewertungen der Features berechnet und im Dataset „Pima Indian Diabetes“ in Machine Learning Studio (Classic) ausgegeben:
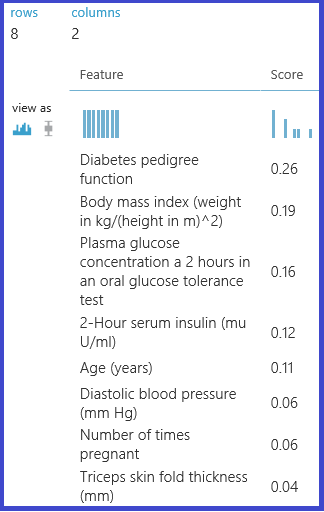
Begrenzungen
Für das Modul Execute Python Script gelten derzeit folgende Einschränkungen:
Ausführung in einer Sandbox-Umgebung
Die Python-Laufzeit befindet sich derzeit im Sandbox-Modus und ermöglicht keinen dauerhaften Zugriff auf das Netzwerk oder auf das lokale Dateisystem. Alle lokal gespeicherten Dateien sind isoliert und werden nach Abschluss des Moduls gelöscht. Auf dem Computer, auf dem er ausgeführt wird, kann der Python-Code nur auf das aktuelle Verzeichnis und die zugehörigen Unterverzeichnisse zugreifen.
Keine hoch entwickelte Unterstützung für Entwicklung und Debuggen
IDE-Features wie Intellisense und Debuggen werden vom Python-Modul derzeit nicht unterstützt. Sollte zur Laufzeit ein Fehler im Modul auftreten, steht der vollständige Python-Stack-Trace zur Verfügung. Diese muss jedoch im Ausgabeprotokoll für das Modul angezeigt werden. Derzeit wird empfohlen, dass Sie Python-Skripts in einer Umgebung wie IPython entwickeln und debuggen und den Code anschließend in das Modul importieren.
Ausgabe in einem einzelnen Datenrahmen
Der Python-Einstiegspunkt kann nur einen einzelnen Datenrahmen als Ausgabe zurückgeben. Derzeit ist es nicht möglich, beliebige Python-Objekte wie z. B. trainierte Modelle direkt an die (klassische) Studio-Runtime zurückzugeben. Wie beim Modul Execute R Script, das die gleiche Einschränkung aufweist, ist es in vielen Fällen möglich, Objekte in ein Bytearray einzubetten und dieses innerhalb eines Datenrahmens zurückzugeben.
Keine Möglichkeit zum Anpassen der Python-Installation
Derzeit besteht die einzige Möglichkeit zum Hinzufügen benutzerdefinierter Python-Module über den weiter oben beschriebenen ZIP-Dateimechanismus. Während dies bei kleinen Modulen machbar ist, ist dieser Ansatz für große Module (vor allem Module mit systemeigenen DLLs) oder eine große Anzahl von Modulen umständlich.
Nächste Schritte
Weitere Informationen finden Sie im Python Developer Center.