Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird die Komponente „Execute Python Script“ in Azure Machine Learning Designer beschrieben.
Verwenden Sie diese Komponente, um Python-Code auszuführen. Weitere Informationen zur Architektur und zu den Entwurfsprinzipien von Python finden Sie im Artikel zum Ausführen von Python-Code in Azure Machine Learning-Designer.
Mit Python können Sie Aufgaben ausführen, die vorhandene Komponenten nicht unterstützen, z. B.:
- Visualisieren von Daten mit
matplotlib - Verwenden von Python-Bibliotheken zum Auflisten von Datasets und Modellen in Ihrem Arbeitsbereich
- Lesen, Laden und Bearbeiten von Daten aus Quellen, die von der Komponente Import Data nicht unterstützt werden.
- Ausführen von eigenem Deep Learning-Code
Unterstützte Python-Pakete
Azure Machine Learning verwendet die Anaconda-Distribution von Python, die viele gängige Hilfsprogramme für die Datenverarbeitung enthält. Wir nutzen hier die Funktion für die automatische Aktualisierung der Anaconda-Version. Die aktuelle Version lautet:
- Anaconda-Verteilung für Python 3.10
Eine vollständige Liste finden Sie im Abschnitt Vorinstallierte Python-Pakete.
Um Pakete zu installieren, die nicht in der Liste mit den vorinstallierten Paketen enthalten sind (z. B. scikit-misc), fügen Sie Ihrem Skript den folgenden Code hinzu:
import os
os.system(f"pip install scikit-misc")
Verwenden Sie den folgenden Code zum Installieren von Paketen, um die Leistung zu verbessern, insbesondere in Bezug auf Rückschlüsse:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Hinweis
Wenn Ihre Pipeline mehrere Komponenten „Execute Python Script“ enthält, die Pakete benötigen, welche nicht in der Liste vorinstalliert sind, installieren Sie die Pakete in jeder Komponente.
Warnung
Die Komponente „Execute Python Script“ unterstützt nicht die Installation von Paketen, die von zusätzlichen nativen Bibliotheken mit Befehlen wie „apt-get“ abhängen, z. B. Java, PyODBC usw. Dies liegt daran, dass diese Komponente in einer einfachen Umgebung ausgeführt wird, in der Python nur vorinstalliert und nicht über Administratorberechtigungen verfügt.
Zugreifen auf den aktuellen Arbeitsbereich und registrierte Datasets
Verwenden Sie den folgenden Beispielcode, um auf die in Ihrem Arbeitsbereich registrierten Datasets zuzugreifen:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Hochladen von Dateien
Die Komponente „Execute Python Script“ unterstützt das Hochladen von Dateien mithilfe des Azure Machine Learning Python SDK.
Das folgende Beispiel zeigt, wie Sie eine Bilddatei in der Komponente „Execute Python Script“ hochladen:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Nachdem die Pipeline ausgeführt wurde, können Sie im rechten Bereich der Komponente eine Vorschau des Bildes anzeigen.
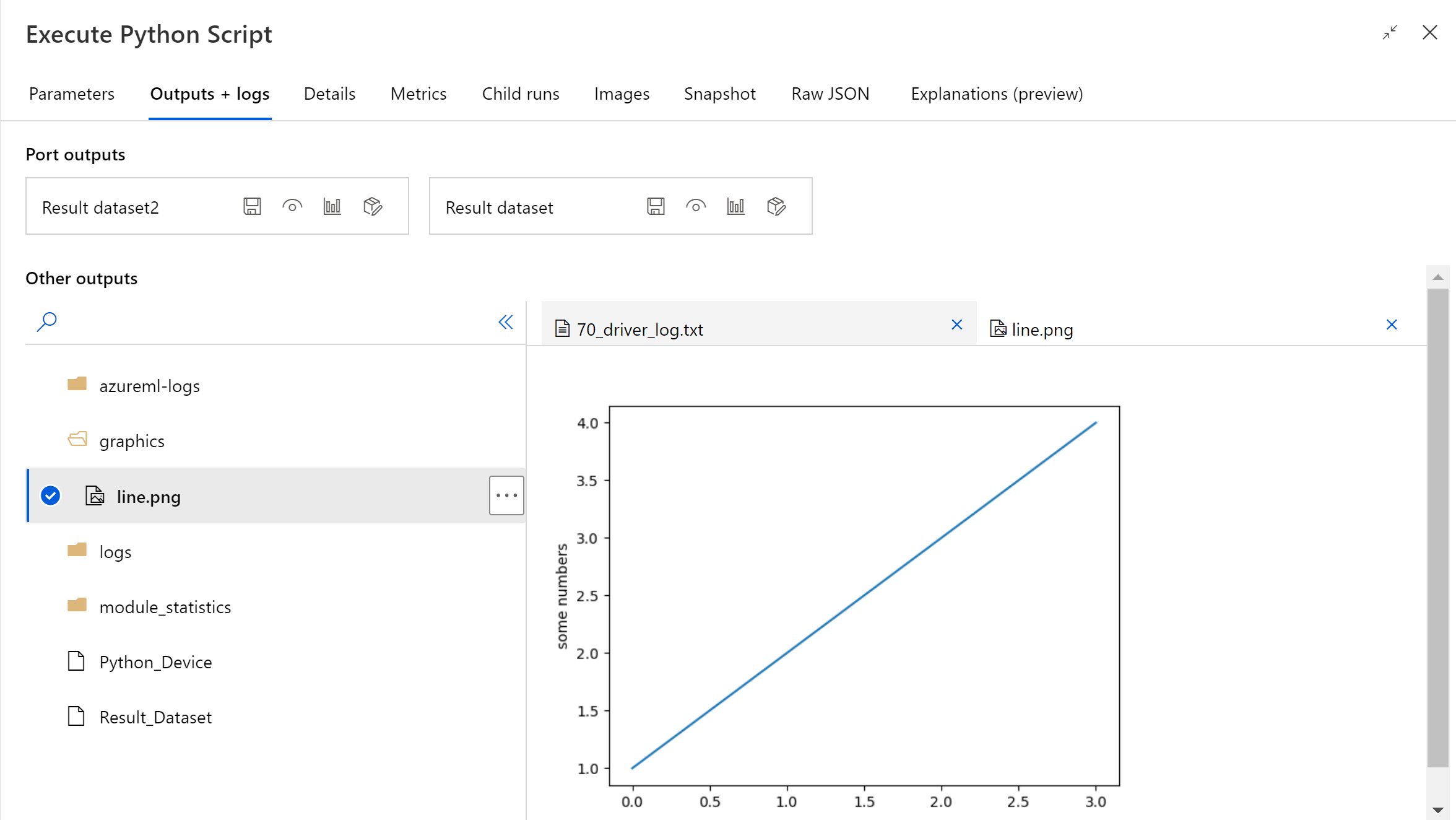
Sie können die Datei auch mit dem folgenden Code in einen beliebigen Datenspeicher hochladen. Sie können die Datei nur in Ihrem Speicherkonto in der Vorschau anzeigen.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Konfigurieren von „Execute Python Script“ (Python-Skript ausführen)
Die Komponente „Execute Python Script“ enthält Python-Beispielcode, den Sie als Ausgangspunkt verwenden können. Geben Sie zum Konfigurieren der Komponente „Execute Python Script“ eine Reihe von Eingaben und Python-Code an, die im Textfeld Python Script ausgeführt werden sollen.
Fügen Sie Ihrer Pipeline die Komponente Execute Python Script hinzu.
Fügen Sie in Dataset1 alle Datasets aus dem Designer hinzu, die Sie als Eingabe verwenden möchten. Verweisen Sie auf dieses Dataset in Ihrem Python-Skript als DataFrame1.
Die Verwendung eines Datasets ist optional. Verwenden Sie sie, wenn Sie Daten mithilfe von Python generieren möchten, oder verwenden Sie Python-Code, um die Daten direkt in die Komponente zu importieren.
Diese Komponente unterstützt das Hinzufügen eines zweiten Datasets in Dataset2. Verweisen Sie auf das zweite Dataset in Ihrem Python-Skript als DataFrame2.
In Azure Machine Learning gespeicherte Datasets werden automatisch in Pandas-Datenframes konvertiert, wenn sie mit dieser Komponente geladen werden.
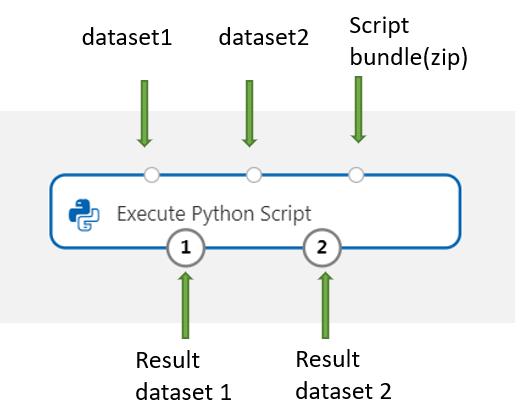
Verbinden Sie die ZIP-Datei, die diese benutzerdefinierten Ressourcen enthält, mit dem Port Script bundle (Skriptbundle), um neue Python-Pakete einzuschließen. Wenn Ihr Skript größer als 16 KB ist, verwenden Sie den Script Bundle-Port, um Fehler wie CommandLine überschreitet das Limit von 16.597 Zeichen zu vermeiden.
- Fassen Sie das Skript und andere benutzerdefinierte Ressourcen in einer ZIP-Datei zusammen.
- Laden Sie die ZIP-Datei als Dateidataset in Studio hoch.
- Ziehen Sie die Datasetkomponente aus der Liste Datasets im linken Komponentenbereich der Designer-Dokumenterstellungsseite.
- Verbinden Sie die Dataset-Komponente mit dem Port Script Bundle der Komponente Execute Python Script.
Während der Ausführung der Pipeline kann jede Datei verwendet werden, die im hochgeladenen ZIP-Archiv enthalten ist. Wenn das Archiv eine Verzeichnisstruktur enthält, bleibt die Struktur erhalten.
Wichtig
Verwenden Sie einen eindeutigen und aussagekräftigen Namen für Dateien im Skriptpaket, da einige gängige Wörter (z. B.
test,appusw.) für integrierte Dienste reserviert sind.Im Folgenden finden Sie ein Beispiel für ein Skriptbundle, das eine Python-Skriptdatei und eine TXT-Datei enthält:
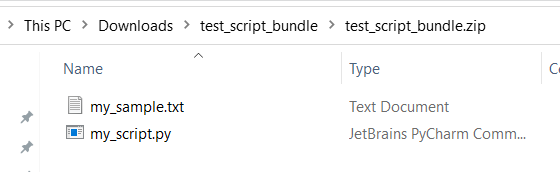
Dies ist der Inhalt von
my_script.py:def my_func(dataframe1): return dataframe1Der folgende Beispielcode zeigt, wie die Dateien im Skriptbundle verwendet werden:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])Geben oder fügen Sie in das Textfeld Python script (Python-Skript) ein gültiges Python-Skript ein.
Hinweis
Gehen Sie beim Schreiben Ihres Skripts mit Bedacht vor. Vergewissern Sie sich, dass keine Syntaxfehler vorliegen, wie z. B. die Verwendung nicht deklarierter Variablen oder nicht importierter Komponenten oder Funktionen. Schenken Sie der Liste mit den vorinstallierten Komponenten besondere Aufmerksamkeit. Um Komponenten zu importieren, die nicht aufgelistet sind, installieren Sie die entsprechenden Pakete in Ihrem Skript, z. B.:
import os os.system(f"pip install scikit-misc")Das Textfeld Python script (Python-Skript) enthält bereits einige Anweisungen in Kommentaren und Beispielcode für den Datenzugriff und die Datenausgabe. Sie müssen diesen Code bearbeiten oder ersetzen. Halten Sie sich an die Python-Konventionen, die in Bezug auf Einzüge und die Groß-/Kleinschreibung gelten:
- Das Skript muss eine Funktion mit dem Namen
azureml_mainals Einstiegspunkt für diese Komponente enthalten. - Die Einstiegspunktfunktion muss über die beiden Eingabeargumente
Param<dataframe1>undParam<dataframe2>verfügen. Dies gilt auch, wenn diese Argumente nicht in Ihrem Skript verwendet werden. - ZIP-Dateien, die mit dem dritten Eingabeport verbunden sind, werden entzippt und im Verzeichnis
.\Script Bundlegespeichert, das auch demsys.pathvon Python hinzugefügt wird.
Wenn Ihre ZIP-Datei die Datei
mymodule.pyenthält, müssen Sie sie mitimport mymoduleimportieren.Es können zwei Datasets den Designer zurückgegeben werden, bei denen es sich um eine Sequenz vom Typ
pandas.DataFramehandeln muss. Sie können weitere Ausgaben in Ihrem Python-Code erstellen und sie direkt in den Azure-Speicher schreiben.Warnung
Es wird nicht empfohlen, in der Komponente Execute Python Script eine Verbindung mit einer Datenbank oder anderen externen Speichern herzustellen. Sie können die Komponente Import Data und Export Data verwenden.
- Das Skript muss eine Funktion mit dem Namen
Übermitteln Sie die Pipeline.
Wenn die Komponente abgeschlossen wurde, überprüfen Sie, ob die Ausgabe den Erwartungen entspricht.
Wenn bei der Komponente ein Fehler aufgetreten ist, müssen Sie eine Problembehandlung durchführen. Wählen Sie die Komponente aus, und öffnen Sie im rechten Bereich Ausgaben und Protokolle. Öffnen Sie 70_driver_log.txt, und suchen Sie nach in azureml_main, um die Zeile zu ermitteln, die den Fehler verursacht hat. Beispielsweise gibt „File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main“ an, dass der Fehler in Zeile 17 Ihres Python-Skripts aufgetreten ist.
Ergebnisse
Die Ergebnisse der Berechnungen des eingebetteten Python-Codes müssen als pandas.DataFrame bereitgestellt werden, der dann automatisch in das Azure Machine Learning-Datasetformat konvertiert wird. Anschließend können Sie die Ergebnisse mit anderen Komponenten in der Pipeline nutzen.
Die Komponente gibt zwei Datasets zurück:
Results Dataset 1 (Ergebnisdataset 1), das durch den ersten zurückgegebenen Pandas-Datenrahmen im Python-Skript definiert wird
Results Dataset 2 (Ergebnisdataset 2), das durch den zweiten zurückgegebenen Pandas-Datenrahmen im Python-Skript definiert wird
Vorinstallierte Python-Pakete
Dies sind die vorinstallierten Pakete:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- Azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- Botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- Cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- Kryptografie==2.8
- cycler==0.10.0
- dill==0.3.1.1
- Distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- Kolben==1.0.3
- Fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- Ungleichgewichte==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- Jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- Pandas==0.25.3
- pfadpec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- Pyarrow==0.16.0
- Pyasn1-Module==0.2.8
- Pyasn1==0.4.8
- Pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- Pyopensl==19.1.0
- Pyparsing==2.4.6
- Pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- Anfragen==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- sechs==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- Rad==0.34.2
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.