Daten in Bins gruppieren Komponente
Dieser Artikel beschreibt die Verwendung der Komponente Daten in Bins gruppieren im Azure Machine Learning Designer, um Zahlen zu gruppieren oder die Verteilung von kontinuierlichen Daten zu ändern.
Die Komponente Daten in Bins gruppieren unterstützt mehrere Optionen für das Binning von Daten. Sie können die Festlegung der Randwerte der Quantisierung und die Aufteilung der Werte auf die Container anpassen. Beispielsweise können Sie folgende Aktionen ausführen:
- Geben Sie manuell eine Reihe von Werten ein, die als Grenzen der Quantisierung dienen sollen.
- Weisen Sie den Containern Werte zu, indem Sie Quantilen oder Perzentilränge verwenden.
- Erzwingen Sie eine gleichmäßige Verteilung der Werte auf die Container.
Weitere Informationen zur Quantisierung und Gruppierung
Das Quantisieren oder Gruppieren von Daten ist ein wichtiges Tool für die Vorbereitung numerischer Daten für maschinelles Lernen. Es ist in Szenarien wie den folgenden nützlich:
Eine Spalte mit fortlaufenden Zahlen hat zu viele eindeutige Werte für die effektive Modellierung. Somit weisen Sie die Werte automatisch oder manuell Gruppen zu, um einen kleineren Satz von diskreten Bereichen zu erstellen.
Sie sollten eine Zahlenreihe durch kategorische Werte ersetzen, die bestimmte Bereiche repräsentieren.
Sie können z. B. Werte in der Spalte „Alter“ gruppieren, indem Sie benutzerdefinierte Bereiche für demografische Benutzerdaten angeben, z. B. 1-15, 16-22, 23-30 usw.
Ein Datenset hat einige wenige Extremwerte, die alle weit außerhalb des erwarteten Bereichs liegen, und diese Werte haben einen übergroßen Einfluss auf das trainierte Modell. Um die Verzerrung im Modell zu minimieren, können Sie die Daten mithilfe der Quantilmethode in eine gleichmäßige Verteilung transformieren.
Bei dieser Methode bestimmt die Komponente Daten in Bins gruppieren die idealen Bin-Positionen und Bin-Breiten, um sicherzustellen, dass ungefähr die gleiche Anzahl von Proben in jedes Bin fällt. Dann werden die Werte in den Containern abhängig von der gewählten Normalisierungsmethode in Perzentile transformiert oder einer Containernummer zugeordnet.
Beispiele für die Quantisierung
Das folgende Diagramm zeigt die Verteilung der numerischen Werte vor und nach der Quantisierung mit der Quantilmethode. Beachten Sie, dass im Vergleich zu den Rohdaten auf der linken Seite die Daten in Container aufgeteilt und in eine normale Größe transformiert wurden.
Da es so viele Möglichkeiten zur Gruppierung von Daten gibt, die alle anpassbar sind, empfehlen wir Ihnen, mit verschiedenen Methoden und Werten zu experimentieren.
Konfigurieren von „Gruppieren von Daten in Containern“
Fügen Sie die Komponente Group Data Into Bins zu Ihrer Pipeline im Designer hinzu. Sie finden diese Komponente in der Kategorie Datentransformation.
Verbinden Sie das Dataset, das die zu gruppierenden numerischen Daten enthält. Die Quantisierung kann nur auf Spalten angewendet werden, die numerische Daten enthalten.
Wenn der Datensatz nicht-numerische Spalten enthält, verwenden Sie die Komponente Spalten im Datensatz auswählen, um eine Untergruppe von Spalten auszuwählen, mit denen Sie arbeiten möchten.
Legen Sie den Quantisierungsmodus fest. Der Quantisierungsmodus bestimmt andere Parameter, daher wählen Sie unbedingt zuerst die Option für den Quantisierungsmodus. Die folgenden Typen werden für die Quantisierung unterstützt:
Quantiles (Quantilen): Die Quantilmethode teilt Werte basierend auf dem Perzentilrang in Klassen ein. Diese Methode wird auch als Quantisierung mit gleicher Höhe bezeichnet.
Equal Width (Gleiche Breite): Bei dieser Option müssen Sie die Gesamtanzahl der Container angeben. Die Werte aus der Datenspalte werden in den Containern so platziert, dass jeder Container das gleiche Intervall zwischen Start- und Endwerten aufweist. Dies führt dazu, dass einige Container möglicherweise mehr Werte enthalten, wenn ein bestimmter Punkt von sehr vielen Daten umgeben ist.
Custom Edges (Benutzerdefinierte Grenzen): Sie können die Werte angeben, mit denen jeder Container beginnt. Der Grenzwert ist immer die untere Grenze des Containers.
Nehmen Sie z. B. an, Sie möchten Werte in zwei Container gruppieren. Einer wird Werte größer als 0 enthalten, und einer wird Werte kleiner oder gleich 0 aufweisen. In diesem Fall geben Sie für Diskretisierungsrandwerte 0 in Comma-separated list of bin edges (durch Komma getrennte Liste von Diskretisierungsrandwerten) ein. Die Ausgabe der Komponente ist 1 und 2, was den Bin-Index für jeden Zeilenwert angibt. Beachten Sie, dass die durch Komma getrennte Werteliste in aufsteigender Reihenfolge sein muss, z. B. 1, 3, 5, 7.
Hinweis
Der Modus Entropie MDL ist in Studio (Classic) definiert, und es gibt noch kein entsprechendes Open Source-Paket, das zur Unterstützung im Designer genutzt werden kann.
Wenn Sie die Quantisierungsmodi Quantiles und Equal Width verwenden, geben Sie mit der Option Number of bins (Anzahl der Container) an, wie viele Container oder Quantilen Sie erstellen möchten.
Verwenden Sie für Columns to bin (Zu gruppierende Spalten) die Spaltenauswahl, um die Spalten mit den Werten auszuwählen, die Sie in Containern gruppieren möchten. Spalten müssen einen numerischen Datentyp aufweisen.
Auf alle gewählten geeigneten Spalten wird die gleiche Quantisierungregel angewendet. Wenn Sie einige Spalten mit einer anderen Methode binden müssen, verwenden Sie eine separate Instanz der Komponente Daten in Bins gruppieren für jeden Satz von Spalten.
Warnung
Wenn Sie eine Spalte auswählen, die keinen zulässigen Typ aufweist, wird ein Laufzeitfehler generiert. Die Komponente gibt einen Fehler zurück, sobald sie eine Spalte eines unzulässigen Typs findet. Wenn Sie einen Fehler erhalten, überprüfen Sie alle ausgewählten Spalten. Der Fehler listet nicht alle ungültigen Spalten auf.
Geben Sie für den Ausgabemodus an, wie die quantifizierten Werte ausgegeben werden sollen:
Anfügen: Erstellt eine neue Spalte mit gruppierten Werten und fügt sie an die Eingabetabelle an.
Inplace (Direkt): Ersetzt die ursprünglichen Werte durch die neuen Werte im Dataset.
ResultOnly: Gibt nur die Ergebnisspalten zurück.
Wenn Sie den Quantisierungsmodus Quantiles (Quantilen) auswählen, verwenden Sie die Option Quantile normalization (Quantilnormalisierung), um zu bestimmen, wie Werte vor der Sortierung in Quantile normalisiert werden. Beachten Sie, dass die Normalisierung der Werte die Werte transformiert, aber nicht die endgültige Anzahl von Containern beeinflusst.
Die folgenden Normalisierungstypen werden unterstützt:
Percent (Prozent): Werte werden innerhalb des Bereichs [0,100] normalisiert.
PQuantile: Werte werden innerhalb des Bereichs [0,1] normalisiert.
QuantileIndex: Werte werden innerhalb des Bereichs [1,Containeranzahl] normalisiert.
Wenn Sie die Option Custom Edges (Benutzerdefinierte Grenzen) auswählen, geben Sie eine durch Kommas getrennte Liste von Zahlen ein, die als Diskretisierungsrandwert im Textfeld Comma-separated list of bin edges (durch Komma getrennte Liste von Diskretisierungsrandwerten) verwendet werden sollen.
Die Werte markieren den Punkt, der die Container trennt. Wenn Sie z. B. einen Diskretisierungsrandwert eingeben, werden zwei Container generiert. Wenn Sie zwei Diskretisierungsrandwerte eingeben, werden drei Container erstellt.
Die Werte müssen in der Reihenfolge der Container sortiert werden, vom niedrigsten zum höchsten.
Wählen Sie die Option Tag columns as categorical (Spalten als kategorisch markieren) aus, um anzugeben, dass die quantisierten Spalten als kategorische Variablen behandelt werden sollen.
Übermitteln Sie die Pipeline.
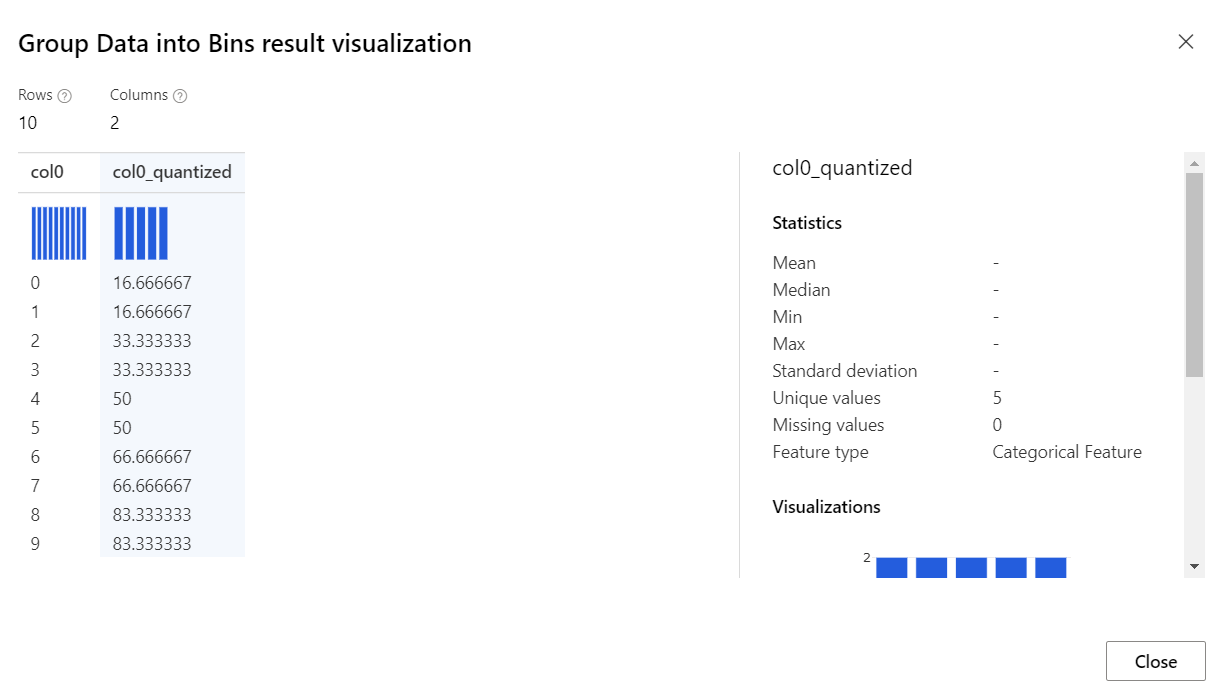
Ergebnisse
Die Komponente Group Data into Bins (Daten in Bins gruppieren) gibt einen Datensatz zurück, in dem jedes Element entsprechend dem angegebenen Modus eingeteilt wurde.
Sie gibt auch eine Quantisierungstransformation zurück. Diese Funktion kann an die Komponente Transformation anwenden weitergegeben werden, um neue Datenproben zu binden, indem der gleiche Binning-Modus und die gleichen Parameter verwendet werden.
Tipp
Wenn Sie die Quantisierung für Ihre Trainingsdaten verwenden, müssen Sie dieselbe Quantisierungsmethode für Daten verwenden, die Sie für Tests und Vorhersagen verwenden. Außerdem müssen Sie dieselben Containerspeicherorte und Containerbreiten verwenden.
Um sicherzustellen, dass Daten immer mit derselben Quantisierungsmethode transformiert werden, empfehlen wir Ihnen, sinnvolle Datentransformationen zu speichern. Wenden Sie sie dann auf andere Datensätze an, indem Sie die Komponente Transformation anwenden verwenden.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.