Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer.
Verwenden Sie diese Komponente zum Transformieren eines Datasets mittels Normalisierung.
Normalisierung ist eine Methode, die häufig im Rahmen der Datenaufbereitung für maschinelles Lernen eingesetzt wird. Ziel der Normalisierung ist es, die Werte numerischer Spalten im Dataset so zu ändern, dass sie eine gemeinsame Skala verwenden, ohne Unterschiede in den Wertebereichen zu verzerren oder Informationen zu verlieren. Eine Normalisierung ist auch für einige Algorithmen erforderlich, um die Daten ordnungsgemäß zu modellieren.
Angenommen, Ihr Eingabedataset enthält eine Spalte mit Werten von 0 bis 1 und eine weitere Spalte mit Werten von 10.000 bis 100.000. Der große Unterschied in der Skala der Werte kann zu Problemen führen, wenn Sie versuchen, die Werte während der Modellierung als Features zu kombinieren.
Dank Normalisierung werden diese Probleme vermieden, indem neue Werte erstellt werden, die die allgemeine Verteilung und Verhältnisse in den Quelldaten beibehalten, während die Werte innerhalb einer Skala verbleiben, die für alle im Modell verwendeten numerischen Spalten gilt.
Diese Komponente bietet mehrere Optionen zum Transformieren numerischer Daten:
- Sie können alle Werte auf einer Skala von 0-1 ändern oder die Werte transformieren, indem Sie sie als Perzentilränge statt als absolute Werte darstellen.
- Sie können die Normalisierung auf eine einzelne Spalte oder mehrere Spalten in einem Dataset anwenden.
- Wenn Sie die Pipeline wiederholen oder die gleichen Normalisierungsschritte auf andere Daten anwenden müssen, können Sie die Schritte als Normalisierungstransformation speichern und auf andere Datasets anwenden, die das gleiche Schema haben.
Warnung
Einige Algorithmen erfordern, dass Daten vor dem Trainieren eines Modells normalisiert werden. Andere Algorithmen führen ihre eigenen Datenskalierung oder -normalisierung durch. Wenn Sie also einen Algorithmus für maschinelles Lernen wählen, der beim Erstellen eines prädiktiven Modells verwendet werden soll, überprüfen Sie unbedingt die Datenanforderungen des Algorithmus, bevor Sie die Normalisierung auf die Trainingsdaten anwenden.
Konfigurieren von „Normalize Data“
Mithilfe dieser Komponente können Sie jeweils nur eine Normalisierungsmethode anwenden. Aus diesem Grund wird die gleiche Normalisierungsmethode auf alle Spalten angewendet, die Sie auswählen. Um andere Normalisierungsmethoden anzuwenden, verwenden Sie eine zweite Instanz von Normalize Data.
Fügen Sie die Komponente Normalize Data Ihrer Pipeline hinzu. Sie finden die Komponente in Azure Machine Learning unter Data Transformation (Datentransformation) in der Kategorie Scale and Reduce (Skalieren und reduzieren).
Stellen Sie eine Verbindung mit einem Dataset her, das mindestens eine Spalte mit allen Zahlen enthält.
Wählen Sie die zu normalisierenden Spalten mithilfe der Spaltenauswahlfunktion aus. Wenn Sie keine einzelnen Spalten auswählen, werden standardmäßig alle numerischen Spalten in der Eingabe berücksichtigt. Der gleiche Normalisierungsprozess wird auf alle ausgewählten Spalten angewendet.
Dies kann zu unerwünschten Ergebnissen führen, wenn Sie numerische Spalten einbeziehen, die nicht normalisiert werden sollten! Überprüfen Sie die Spalten stets sorgfältig.
Wenn keine numerischen Spalten erkannt werden, überprüfen Sie die Metadaten der Spalte, um sicherzustellen, dass der Datentyp der Spalte ein unterstützter numerischer Typ ist.
Tipp
Um sicherzustellen, dass Spalten eines bestimmten Typs als Eingabe zur Verfügung gestellt werden, sollten Sie die Komponente Select Columns in Dataset (Spalten im Datensatz auswählen) vor Normalize Data verwenden.
Use 0 for constant columns when checked (0 für konstante Spalten verwenden, falls aktiviert): Aktivieren Sie diese Option, wenn eine numerische Spalte einen einzelnen unveränderlichen Wert enthält. Dadurch wird sichergestellt, dass solche Spalten bei Normalisierungsvorgängen nicht berücksichtigt werden.
Wählen Sie in der Dropdownliste Transformation method (Transformationsmethode) eine einzelne mathematische Funktion, die auf alle ausgewählten Spalten angewendet wird.
Zscore: Konvertiert alle Werte in ein Z-Ergebnis.
Die Werte in der Spalte werden mithilfe der folgenden Formel transformiert:
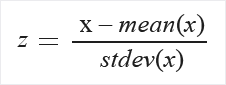
Mittlere und Standardabweichung werden für jede Spalte getrennt berechnet. Die Standardabweichung der Grundgesamtheit wird verwendet.
MinMax: Die Min-Max Normalisierungsfunktion skaliert jede Funktion linear auf das Intervall [0,1].
Die Umskalierung in das Intervall [0,1] erfolgt durch Verschieben der Werte jedes Features, sodass der Minimalwert 0 ist. Anschließend erfolgt eine Division durch den neuen Maximalwert (was die Differenz zwischen dem ursprünglichen Maximal- und Minimalwert ergibt).
Die Werte in der Spalte werden mithilfe der folgenden Formel transformiert:

Logistic: Die Werte in der Spalte werden mithilfe der folgenden Formel transformiert:

LogNormal: Diese Option konvertiert alle Werte in eine logarithmische Normalverteilung.
Die Werte in der Spalte werden mithilfe der folgenden Formel transformiert:

Hier sind μ und σ die Parameter der Verteilung, die empirisch anhand der Daten als Maximum-Likelihood-Schätzungen berechnet werden, und zwar für jede Spalte einzeln.
TanH: Alle Werte werden in einen hyperbolischen Tangens konvertiert.
Die Werte in der Spalte werden mithilfe der folgenden Formel transformiert:

Übermitteln Sie die Pipeline oder klicken Sie doppelt auf die Komponente Normalize Data und wählen Sie Run Selected (Auswahl ausführen) aus.
Ergebnisse
Die Komponente Normalize Data generiert zwei Ausgaben:
Um die transformierten Werte anzuzeigen, klicken Sie mit der rechten Maustaste auf die Komponente und wählen Sie Visualisieren aus.
Standardmäßig werden Werte direkt transformiert. Wenn Sie die transformierten Werte mit den Originalwerten vergleichen möchten, verwenden Sie die Komponente Add Columns (Spalten hinzufügen), um die Datasets neu zu kombinieren und die Spalten nebeneinander zu betrachten.
Um dieselbe Normalisierungsmethode auf ein anderes Dataset anwenden zu können, wählen Sie zum Speichern der Transformation die Komponente aus und wählen Sie Dataset registrieren unter der Registerkarte Ausgaben im rechten Fensterbereich aus.
Anschließend können Sie die gespeicherten Transformationen aus der Gruppe " Transformationen" des linken Bereichs laden und auf ein Dataset mit demselben Schema anwenden, indem Sie die Transformation anwenden.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.