Trainieren Sie das PyTorch Modell
Dieser Artikel beschreibt, wie Sie die Komponente Train PyTorch Modell im Azure Machine Learning Designer verwenden, um PyTorch-Modelle wie DenseNet zu trainieren. Das Training findet statt, nachdem Sie ein Modell definiert und die zugehörigen Parameter festgelegt haben. Für das Training werden markierte Daten benötigt.
Derzeit unterstützt die Komponente Train PyTorch Model sowohl einzelne Knoten als auch verteiltes Training.
Wie das Train PyTorch-Modell verwendet wird
Fügen Sie die DenseNet-Komponente oder ResNet Ihrem Pipelineentwurf im Designer hinzu.
Fügen Sie der Pipeline die Komponente Train PyTorch Model (PyTorch-Modell trainieren) hinzu. Sie finden diese Komponente unter der Kategorie Modelltraining. Erweitern Sie Trainieren, und ziehen Sie dann die Komponente Train PyTorch-Model (PyTorch-Modell trainieren) in Ihre Pipeline.
Hinweis
Es ist besser, die Komponente Train PyTorch Model bei großen Datensätzen auf einem GPU-Rechner auszuführen, da sonst Ihre Pipeline versagt. Sie können im rechten Bereich der Komponente „Compute“ für eine bestimmte Komponente auswählen, indem Sie Anderes Computeziel verwenden festlegen.
Fügen Sie in der linken Eingabe ein untrainiertes Modell an. Hängen Sie den Trainingsdatensatz und den Validierungsdatensatz an die mittleren und rechte Eingabe vom Train PyTorch Modell an.
Bei einem untrainierten Modell muss es ein PyTorch-Modell wie DenseNet sein; andernfalls wird der Fehler „InvalidModelDirectoryError“ ausgelöst.
Für das Dataset muss das Trainingsdataset ein Bildverzeichnis mit Bezeichnungen sein. Weitere Informationen zum Abrufen eines Bildverzeichnisses mit Bezeichnungen finden Sie unter Konvertieren in ein Bildverzeichnis. Liegen keine Bezeichnungen vor, wird der Fehler „NotLabeledDatasetError“ ausgelöst.
Das Trainingsdataset und das Validierungsdataset weisen dieselben Bezeichnungskategorien auf; andernfalls wird der Fehler „InvalidDatasetError“ ausgelöst.
Geben Sie für Epochs (Epochen) an, wie viele Epochen trainiert werden sollen. Das gesamte Dataset wird in jeder Epoche (standardmäßig 5) durchlaufen.
Geben Sie für Batchgröße an, wie viele Instanzen in einem Batch trainiert werden sollen (standardmäßig 16).
Geben Sie als Aufwärmschritt-Nummer an, wie viele Perioden Sie das Training aufwärmen möchten, falls die anfängliche Lernrate etwas zu groß ist, um mit der Konvergenz zu beginnen, standardmäßig 0.
Geben Sie als Lernrate einen Wert für die Lernrate an, und der Standardwert ist 0,001. Die Lernrate steuert die Größe des Schrittes, der in Optimierern wie sgd jedes Mal verwendet wird, wenn das Modell getestet und korrigiert wird.
Indem Sie die Rate verkleinern, testen Sie das Modell häufiger, mit dem Risiko, dass Sie auf einem lokalen Plateau stecken bleiben könnten. Mit größeren Schritten können Sie schneller konvergieren, mit dem Risiko, den echten Mindestwert zu unterschreiten.
Hinweis
Wenn der Lernverlust während des Trainings nan wird, was durch eine zu große Lernrate verursacht werden kann, könnte eine Verringerung der Lernrate helfen. Beim verteilten Training wird, um den Gradienten-Abstieg stabil zu halten, die tatsächliche Lernrate durch
lr * torch.distributed.get_world_size()berechnet, da die Chargengröße der Prozessgruppe die Weltgröße mal der des Einzelprozesses ist. Der polynomiale Lernratenabfall wird angewendet und kann zu einem leistungsfähigeren Modell führen.Geben Sie für Random seed (Zufällig gewählter Startwert) optional einen ganzzahligen Wert ein, der als Startwert verwendet wird. Sie sollten einen Startwert verwenden, wenn Sie die Aufträge übergreifende Reproduzierbarkeit des Experiments sicherstellen möchten.
Geben Sie für Patience (Geduld) an, nach wie vielen Epochen das Training vorzeitig abgebrochen werden soll, wenn der Validierungsverlust nicht konsekutiv abnimmt. Die Standardeinstellung ist 3.
Geben Sie als Druckhäufigkeitdie Druckhäufigkeit des Trainingsprotokolls über Iterationen in jeder Epoche an, standardmäßig 10.
Übermitteln Sie die Pipeline. Wenn es sich um ein größeres Dataset handelt, kann dies eine Weile dauern, und es wird eine GPU-Computeressource empfohlen.
Verteiltes Training
Beim verteilten Training wird die Arbeitsauslastung zum Trainieren eines Modells auf mehrere Miniprozessoren, die als Workerknoten bezeichnet werden, verteilt. Diese Workerknoten werden parallel ausgeführt, um das Modelltraining zu beschleunigen. Derzeit unterstützt der Designer verteiltes Training für die Train PyTorch Model-Komponente.
Trainingsdauer
Das verteilte Training ermöglicht es, auf einem großen Datensatz wie ImageNet (1000 Klassen, 1,2 Millionen Abbildungen) in nur wenigen Stunden anhand dem Train PyTorch Model zu trainieren. Die folgende Tabelle zeigt die Trainingsdauer und die Leistung während des Trainings von 50 Perioden von Resnet50 auf ImageNet von Grund auf, basierend auf verschiedenen Geräten.
| Geräte | Trainingsdauer | Trainingsdurchsatz | Top-1-Überprüfungspräzision | Top-5-Überprüfungspräzision |
|---|---|---|---|---|
| 16 V100 GPUs | 6:22min | ~3200 Abbildungen/Sek | 68,83% | 88,84% |
| 8 V100 GPU | 12:21min | ~1670 Abbildungen/Sek | 68,84% | 88,74% |
Klicken Sie auf die Registerkarte „Metriken“ dieser Komponente, und sehen Sie Trainingsmetrik-Graphiken wie „Trainings-Abbildungen pro Sekunde“ und „Top 1-Präzision“.

Wie Sie verteiltes Training ermöglichen
Verteiltes Training für die Train PyTorch Model-Komponente können Sie im rechten Bereich der Komponente unter Auftragseinstellungen aktivieren. Nur der AML Compute-Cluster wird für verteiltes Training unterstützt.
Hinweis
Mehrere GPUs sind erforderlich, um verteiltes Training zu aktivieren, weil das NCCL-Backend, welches die PyTorch-Modellkomponente verwendet, cuda benötigt.
Wählen Sie die Komponente aus und öffnen Sie das rechte Fenster. Erweitern Sie den Abschnitt Auftragseinstellungen.
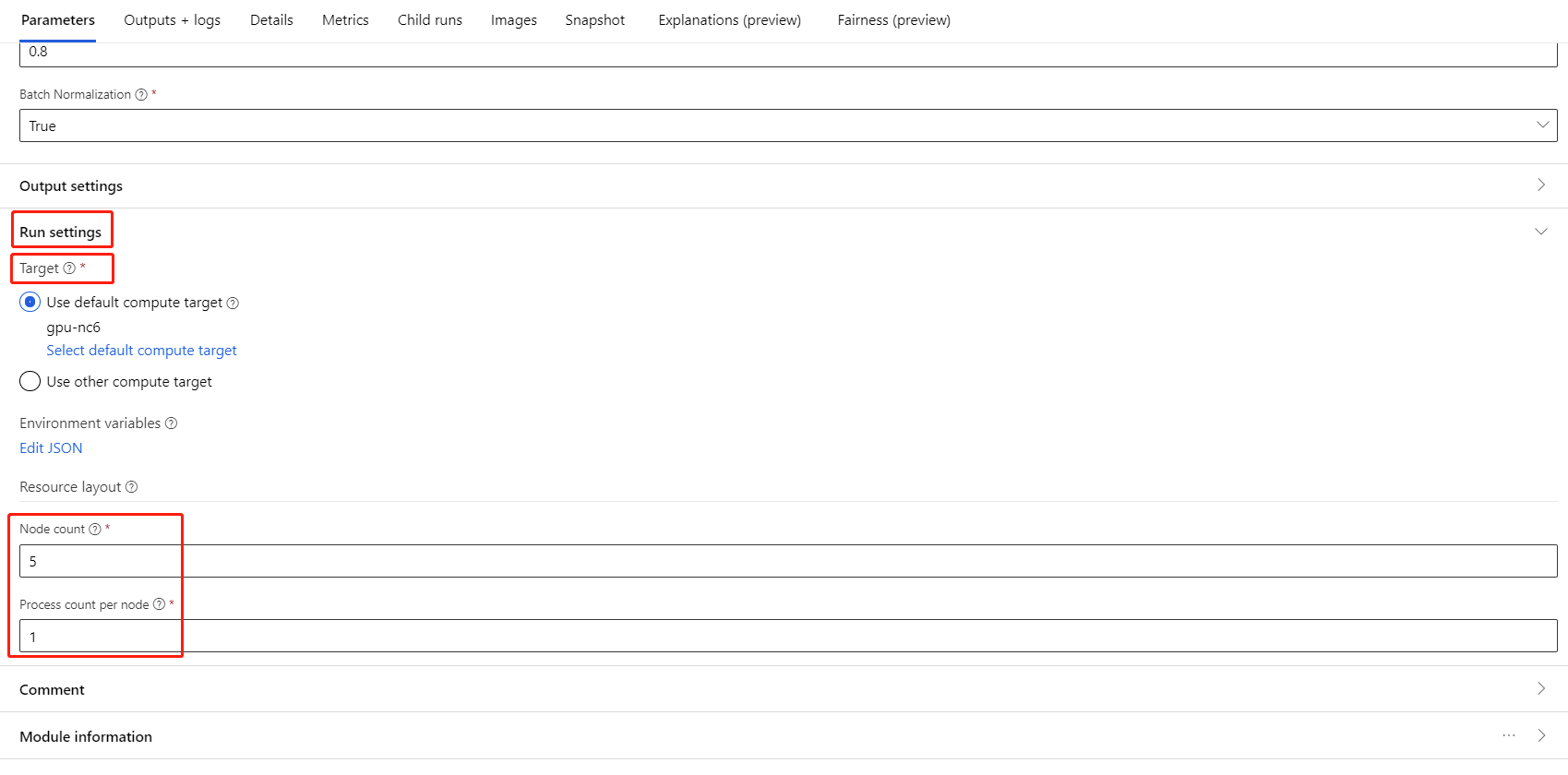
Stellen Sie sicher, dass Sie AML Compute als Rechenziel ausgewählt haben.
Im Abschnitt Ressourcenlayout müssen Sie die folgenden Werte einstellen:
Knotenanzahl : Anzahl der Knoten im Rechenziel, die für das Training verwendet werden. Sie sollte kleiner oder gleich der maximalen Anzahl von Knoten Ihres Rechenclusters sein. Standardmäßig ist dies 1, was Einzelknotenauftrag bedeutet.
Anzahl der Prozesse pro Knoten: Anzahl der pro Knoten ausgelösten Prozesse. Er sollte kleiner oder gleichder Prozessoreinheit Ihres Computers sein. Standardmäßig ist es 1, was einem einzelnen Prozessjob entspricht.
Sie können die maximale Anzahl von Knoten und die Prozessoreinheit Ihres Computers überprüfen, indem Sie auf der Seite mit den Rechendetails in der Rechendetailseite klicken.



Mehr über verteiltes Training in Azure Machine Learning erfahren Sie hier.
Fehlerbehebung für das verteilte Training
Wenn Sie das verteilte Training für diese Komponente aktivieren, sind Treiberprotokolle für jedes Verfahren vorhanden. 70_driver_log_0 ist für das Master-Verfahren. Sie können die Treiberprotokolle auf Fehlerdetails jedes Prozesses unter der Registerkarte Ausgaben+Protokolle in der rechten Anzeige überprüfen.

Wenn die Komponente „Aktiviertes verteiltes Training“ ohne 70_driverProtokolle fehlschlägt, können Sie nach70_mpi_log Fehlerdetails suchen.
Das folgende Beispiel zeigt einen häufigen Fehler an, nämlich, die Anzahl der Prozesse pro Knoten ist grösser als die Prozessoreinheit des Rechners.

In diesem Artikel finden Sie weitere Details bzgl. der Fehlerbehebung bei Komponenten.
Ergebnisse
Nachdem der Pipelineauftrag abgeschlossen ist und um das Modell für die Bewertung zu verwenden, verbinden Sie das Train PyTorch Model mit dem Score Image Model, um Werte für neue Eingabebeispiele vorherzusagen.
Technische Hinweise
Erwartete Eingaben
| Name | type | BESCHREIBUNG |
|---|---|---|
| Untrainiertes Modell | UntrainedModelDirectory | Untrainiertes Modell, PyTorch erforderlich |
| Trainingsdataset | ImageDirectory | Trainingsdataset |
| Validierungsdataset | ImageDirectory | Validierungsdataset für die Bewertung jeder Epoche |
Komponentenparameter
| Name | Range | type | Standard | BESCHREIBUNG |
|---|---|---|---|---|
| Epochs (Epochen) | >0 | Integer | 5 | Auswählen der Spalte, die die Bezeichnung enthält, oder der Ergebnisspalte |
| Batchgröße | >0 | Integer | 16 | Anzahl der Instanzen, die in einem Batch trainiert werden sollen |
| Nummer des Aufwärmschritts | >=0 | Integer | 0 | Wieviele Perioden für das Aufwärmtraining |
| Learning rate (Lernrate) | >=double.Epsilon | Float | 0,1 | Die anfängliche Lernrate für den Stochastic Gradient Descent-Optimierer (stochastischer Gradientenabfall) |
| Random seed (Zufälliger Ausgangswert) | Any | Integer | 1 | Der Ausgangswert für den Zufallszahlen-Generator, der vom Modell verwendet wird |
| Patience (Geduld) | >0 | Integer | 3 | Anzahl der Epochen bis zum vorzeitigen Abbruch des Trainings |
| Druckhäufigkeit | >0 | Integer | 10 | Druckhäufigkeit des Trainingsprotokolls über Iterationen in jeder Periode |
Ausgaben
| Name | type | BESCHREIBUNG |
|---|---|---|
| Trainiertes Modell | ModelDirectory | Trainiertes Modell |
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.