Was ist der verwaltete Feature Store?
In unserer Vision für den Managed Feature Store wollen wir Fachleute für maschinelles Lernen in die Lage versetzen, eigenständig Funktionen zu entwickeln und zu produzieren. Sie stellen eine Spezifikation der Funktionen bereit und überlassen dann dem System die Bereitstellung, Sicherung und Überwachung der Funktionen. Dies befreit Sie vom Aufwand für die Einrichtung und Verwaltung der zugrunde liegenden Feature-Engineering-Pipeline.
Dank der Integration unseres Funktionsspeichers in den Lebenszyklus des maschinellen Lernens können Sie schneller experimentieren und Modelle bereitstellen, die Zuverlässigkeit ihrer Modelle erhöhen und Ihre Betriebskosten senken. Die Neudefinition der Erfahrung des maschinellen Lernens bietet diese Vorteile.
Weitere Informationen zu Entitäten auf oberster Ebene im Feature Store, einschließlich Featuresatzspezifikationen, finden Sie unter Grundlegendes zu Entitäten auf oberste Ebene im verwalteten Feature Store.
Was sind Funktionen (Features)?
Merkmale dienen als Eingabedaten für Ihr Modell. Bei datengesteuerten Anwendungsfällen im Unternehmenskontext transformieren die Funktionen häufig historische Daten (einfache Aggregate, Fensteraggregate, Transformationen auf Zeilenebene usw.). Nehmen wir zum Beispiel ein maschinelles Lernmodell zur Kundenabwanderung. Die Modellinputs könnten Kundeninteraktionsdaten wie 7day_transactions_sum (Anzahl der Transaktionen in den letzten sieben Tagen) oder 7day_complaints_sum (Anzahl der Beschwerden in den letzten sieben Tagen) enthalten. Beide Aggregatfunktionen werden auf der Grundlage der Daten der letzten sieben Tage berechnet.
Vom Feature Store behobene Probleme
Um den Managed Feature Store besser zu verstehen, sollten Sie zunächst die Probleme verstehen, die Feature Store lösen kann.
Mit dem Feature Store können Sie von Ihrem Team erstellte Features suchen und wiederverwenden, um redundante Arbeit zu vermeiden und konsistente Vorhersagen zu liefern.
Sie können neue Features mit der Fähigkeit zu Transformationen erstellen, um die Anforderungen des Feature-Engineerings auf eine agile, dynamische Weise zu erfüllen.
Das System operationalisiert und verwaltet die für die Transformation und Materialisierung erforderlichen Feature-Engineering-Pipelines , um Ihr Team von den operativen Aspekten zu entlasten.
Sie können die gleiche Feature-Pipeline, die ursprünglich für die Generierung von Trainingsdaten verwendet wurde, für neue Inferenzzwecke verwenden, um Online-/Offline-Konsistenz zu gewährleisten und Trainings-/Servierungsverzerrungen zu vermeiden.
Freigeben des verwalteten Feature Stores
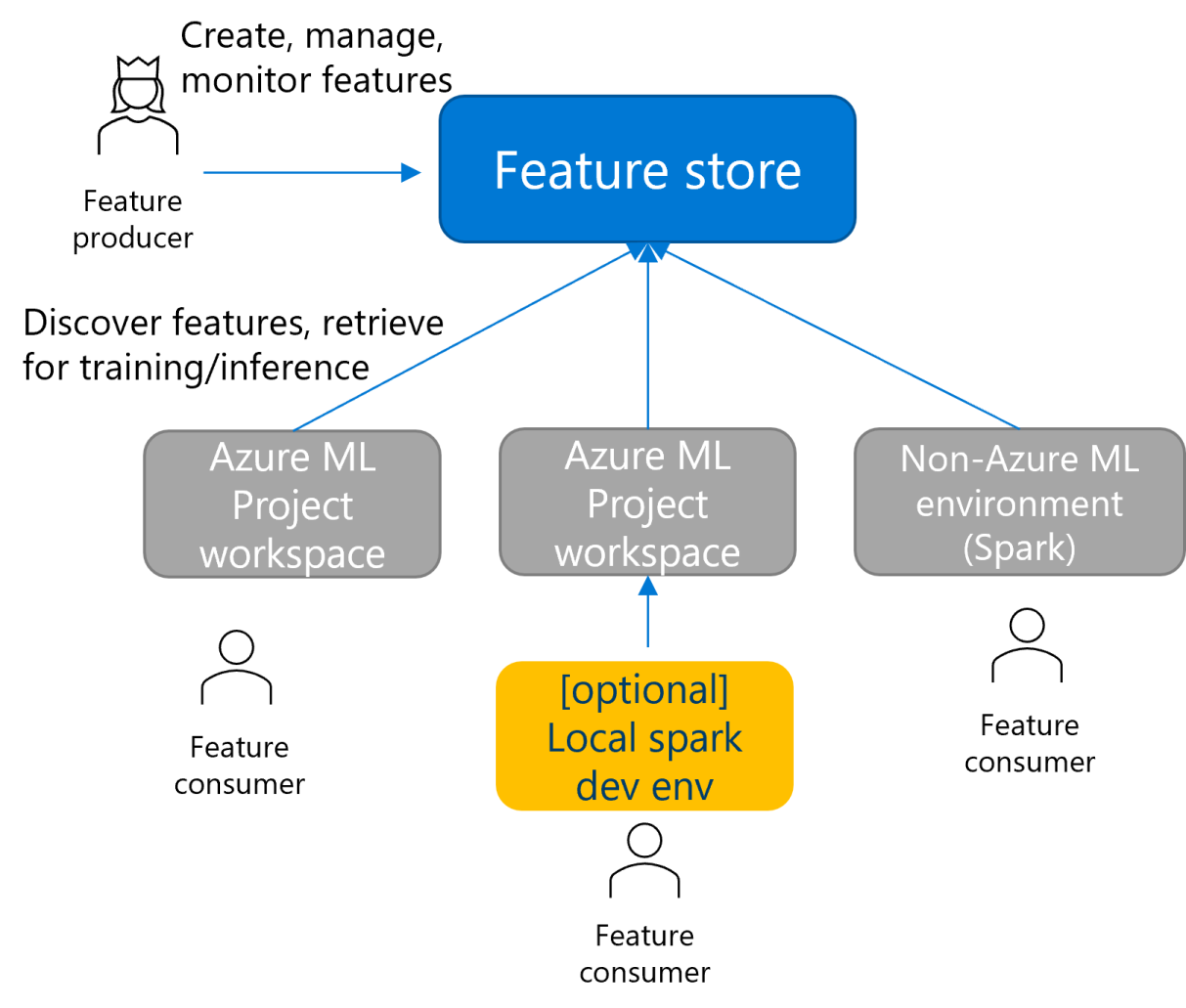
Der Feature-Speicher ist ein neuer Typ von Arbeitsbereich, den mehrere Projektarbeitsbereiche nutzen können. Sie können Features aus anderen Spark-basierten Umgebungen als Azure Machine Learning nutzen, z. B. Azure Databricks. Sie können auch eine lokale Entwicklung und Tests von Features durchführen.
Übersicht für den Feature Store
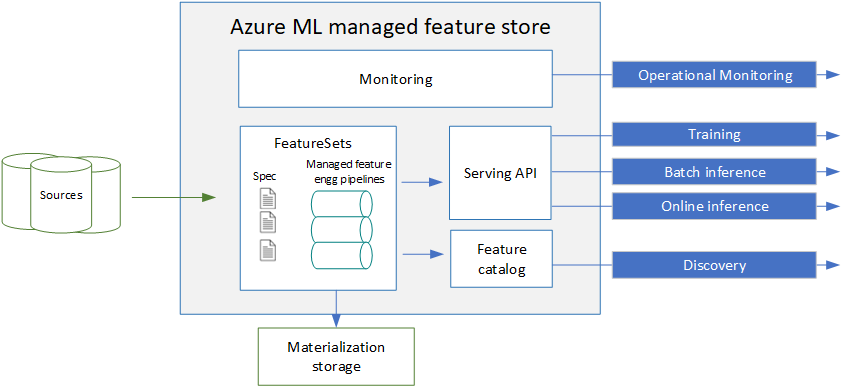
Für verwaltete Feature-Stores stellen Sie eine Feature-Set-Spezifikation bereit. Anschließend übernimmt das System die Bereitstellung, Sicherung und Überwachung Ihrer Funktionen. Eine Featuresatzspezifikation enthält Featuredefinitionen und optionale Transformationslogik. Sie können auch deklarativ Materialisierungseinstellungen für die Materialisierung in einem Offlinespeicher (ADLS Gen2) bereitstellen. Das System generiert und verwaltet die zugrunde liegenden Pipelines für die Featurematerialisierung. Im Featurekatalog können Sie Features suchen, freigeben und wiederverwenden. Mithilfe der Bereitstellungs-API können Benutzer nach Features suchen, um Daten für Training und Rückschluss zu generieren. Die Serving-API kann die Daten direkt aus der Quelle oder aus einem Offline-Materialisierungsspeicher für Training/Batch-Inferenz beziehen. Das System bietet auch Funktionen zum Überwachen von Featurematerialisierungsaufträgen.
Vorteile des verwalteten Feature Stores von Azure Machine Learning
- Mehr Agilität beim Ausliefern des Modells (Prototyperstellung bis Operationalisierung):
- Entdecken und Wiederverwenden von Funktionen, anstatt Funktionen von Grund auf neu zu erstellen
- Schnelleres Experimentieren mit lokaler Entwicklung/Test von neuen Merkmalen mit Transformationsunterstützung und Verwendung von Merkmalsspezifikationen als Bindegewebe im MLOps-Flow
- Deklarative Materialisierung und Abgleich
- Vordefinierte Konstrukte: Featureabrufkomponente und Featureabrufspezifikation
- Höhere Zuverlässigkeit von ML-Modellen
- Eine einheitliche Merkmalsdefinition für alle Geschäftsbereiche/Organisationen
- Funktionssätze sind versioniert und unveränderlich: Neuere Versionen von Modellen können neuere Funktionsversionen verwenden, ohne die ältere Version des Modells zu beeinträchtigen
- Materialisierung von Merkmalen überwachen
- Materialisierung vermeidet Trainings-/Bereitstellungsabweichung
- Der Featureabruf unterstützt zeitpunktbezogene Joins (auch als Zeitreise bezeichnet), um Datenlecks zu vermeiden.
- Kostensenkung
- Wiederverwenden von Features, die von anderen in der Organisation erstellt wurden
- Materialisierung und Überwachung sind systemgesteuert, um die Entwicklungskosten zu reduzieren
Ermitteln und Verwalten von Features
Der verwaltete Funktionsspeicher bietet diese Funktionen für die Erkennung und Verwaltung von Funktionen:
- Funktionen suchen und wiederverwenden - Sie können Merkmale in verschiedenen Merkmalsspeichern suchen und wiederverwenden
- Versionsunterstützung - Feature-Sets sind versioniert und unveränderlich, so dass Sie den Lebenszyklus des Feature-Sets unabhängig verwalten können. Sie können neue Modellversionen mit unterschiedlichen Leistungsmerkmalen bereitstellen und eine Unterbrechung der älteren Modellversion vermeiden
- Sichtkosten auf Feature-Store-Ebene - Die primären Kosten im Zusammenhang mit der Verwendung von Feature-Stores sind verwaltete Spark-Materialisierungsaufträge. Sie können diese Kosten auf der Ebene des Feature Store sehen
- Featuresatzverwendung: Sie können die Liste der registrierten Modelle mithilfe der Featuresätze einsehen.
Featuretransformation
Bei der Merkmalstransformation werden die Merkmale des Datensatzes verändert, um die Modellleistung zu verbessern. Der Transformationscode, der in einer Feature-Spezifikation definiert ist, dient der Transformation von Features. Um schneller zu experimentieren, führt der Transformationscode Berechnungen mit Quelldaten durch und ermöglicht die lokale Entwicklung und Prüfung von Transformationen.
Der verwaltete Feature-Speicher bietet diese Möglichkeiten der Feature-Transformation:
- Unterstützung für benutzerdefinierte Transformationen - Sie können einen Spark-Transformer schreiben, um Funktionen mit benutzerdefinierten Transformationen zu entwickeln, z. B. fensterbasierte Aggregate.
- Unterstützung für vorberechnete Features - Sie können vorberechnete Features in den Feature-Speicher bringen und sie bedienen, ohne Code zu schreiben
- Lokale Entwicklung und Tests: In einer Spark-Umgebung können Sie Featuresätze vollständig lokal entwickeln und testen.
Materialisierung von Features
Die Materialisierung umfasst die Berechnung von Merkmalswerten für ein bestimmtes Merkmalsfenster und die Speicherung dieser Werte in einem Materialisierungsspeicher. Nun können Merkmalsdaten für Trainings- und Inferenzzwecke schneller und zuverlässiger abgerufen werden.
- Verwaltete Materialisierungspipeline für Merkmale - Sie geben den Materialisierungszeitplan deklarativ an, und das System übernimmt dann die Planung, Vorberechnung und Materialisierung der Werte in den Materialisierungsspeicher.
- Abgleichunterstützung: Sie können die bedarfsgesteuerte Materialisierung von Featuresätzen für ein bestimmtes Featurefenster durchführen.
- Managed Spark-Unterstützung für Materialisierung - Azure Machine Learning verwaltet Spark (in serverlosen Recheninstanzen) führt die Materialisierungsaufträge aus. Es befreit Sie von der Einrichtung und Verwaltung der Spark-Infrastruktur.
Hinweis
Sowohl die Materialisierung des Offlinespeichers (ADLS Gen2) als auch die des Onlinespeichers (Redis) werden derzeit unterstützt.
Featureabruf
Azure Machine Learning enthält eine integrierte Komponente, die den Abruf von Offline-Features übernimmt. Sie ermöglicht die Verwendung der Features in den Trainings- und Batch-Inferenzschritten eines Azure Machine Learning Pipeline-Jobs.
Der verwaltete Merkmalspeicher bietet diese Funktionen zum Abrufen von Merkmalen:
- Deklarative Trainingsdatengenerierung - Mit der integrierten Feature Retrieval Komponente können Sie Trainingsdaten in Ihren Pipelines generieren, ohne Code zu schreiben
- Erzeugung von Batch-Inferenzdaten - Mit der gleichen eingebauten Komponente für die Merkmalsabfrage können Sie Batch-Inferenzdaten erzeugen
- Programmatische Merkmalsabfrage - Sie können auch Python SDK
get_offline_features()verwenden, um die Trainings-/Inferenzdaten zu erzeugen
Überwachung
Der verwaltete Feature Store bietet die folgenden Überwachungsmöglichkeiten:
- Status von Materialisierungsaufträgen: Sie können den Status von Materialisierungsaufträgen auf der Benutzeroberfläche, über die CLI oder das SDK anzeigen.
- Benachrichtigung zu Materialisierungsaufträgen: Sie können E-Mail-Benachrichtigungen zu den verschiedenen Status der Materialisierungsaufträge einrichten.
Sicherheit
Der verwaltete Feature Store bietet die folgenden sicherheitsbezogenen Möglichkeiten:
- RBAC: rollenbasierte Zugriffssteuerung für Feature Store, Featuresätze und Entitäten.
- Abfrage über Merkmalspeicher - Sie können mehrere Merkmalspeicher mit unterschiedlichen Zugriffsberechtigungen für Benutzer erstellen, aber die Abfrage (z. B. die Generierung von Trainingsdaten) von mehreren Merkmalspeichern aus ermöglichen
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für