Zugreifen auf Daten aus Azure-Cloudspeicher während der interaktiven Entwicklung
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Ein Projekt für maschinelles Lernen beginnt in der Regel mit der explorativen Datenanalyse (EDA) und der Datenvorverarbeitung (Bereinigung, Feature Engineering) und beinhaltet die Erstellung von ML-Modellprototypen zur Validierung von Hypothesen. Diese Phase für die Prototyperstellung des Projekts ist sehr interaktiv und eignet sich für die Entwicklung in einer Jupyter Notebook-Instanz oder einer IDE mit einer interaktiven Python-Konsole. In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Greifen Sie auf Daten über einen Azure Machine Learning-Datenspeicher-URI auf dieselbe Weise zu wie auf ein Dateisystem.
- Materialisieren Sie Daten mithilfe der Python-Bibliothek
mltablein Pandas. - Materialisieren Sie Azure Machine Learning-Datenobjekte mithilfe der Python-Bibliothek
mltablein Pandas. - Materialisieren Sie Daten durch einen expliziten Download mit dem Hilfsprogramm
azcopy.
Voraussetzungen
- Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen finden Sie unter Verwalten von Azure Machine Learning-Arbeitsbereichen im Portal oder mit dem Python SDK (v2).
- Ein Azure Machine Learning-Datenspeicher. Weitere Informationen finden Sie unter Erstellen von Datenspeichern.
Tipp
Im Leitfaden in diesem Artikel wird der Datenzugriff während der interaktiven Entwicklung beschrieben. Er gilt für jeden Host, der eine Python-Sitzung ausführen kann. Dazu kann Ihr lokaler Computer, eine Cloud-VM, ein GitHub-Codespace usw. sein. Wir empfehlen die Verwendung einer Azure Machine Learning-Compute-Instanz. Dabei handelt es sich um eine vollständig verwaltete und vorkonfigurierte Cloudarbeitsstation. Weitere Informationen finden Sie unter Erstellen einer Compute-Instanz von Azure Machine Learning.
Wichtig
Stellen Sie sicher, dass Sie die neuesten azure-fsspec-, mltable- und azure-ai-ml-Python-Bibliotheken in Ihrer Python-Umgebung installiert haben:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
Die aktuelle azure-fsspec-Paketversion kann sich im Laufe der Zeit ändern. Weitere Informationen zum azure-fsspec-Paket finden Sie in dieser Ressource.
Zugreifen auf Daten über einen Datenspeicher-URI wie mit einem Dateisystem
Ein Azure Machine Learning-Datenspeicher ist ein Verweis auf ein vorhandenes Azure-Speicherkonto. Die Erstellung und Verwendung von Datenspeichern hat u. a. folgende Vorteile:
- Sie verfügen über eine allgemeine, benutzerfreundliche API für die Interaktion mit verschiedenen Speichertypen (Blob/Files/ADLS).
- Einfache Ermittlung nützlicher Datenspeicher in Teamvorgängen
- Unterstützung für den Datenzugriff sowohl auf der Basis von Anmeldeinformationen (z. B. SAS-Token) als auch auf der Basis von Identitäten (Verwendung von Microsoft Entra ID oder einer verwalteten Identität)
- Für den auf Anmeldeinformationen basierenden Zugriff werden die Verbindungsinformationen geschützt, um die Offenlegung von Schlüsseln in Skripts zu vermeiden.
- Durchsuchen von Daten und Kopieren und Einfügen von Datenspeicher-URIs auf der Studio-Benutzeroberfläche
Ein Datenspeicher-URI ist ein Uniform Resource Identifier, bei dem es sich um einen Verweis auf einen Speicherort (Pfad) in Ihrem Azure-Speicherkonto handelt. Ein Datenspeicher-URI hat das folgende Format:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Diese Datenspeicher-URIs sind eine bekannte Implementierung der Dateisystemspezifikation (fsspec): eine einheitliche Python-Schnittstelle für lokale, remotebasierte und eingebettete Dateisysteme und Bytespeicher. Installieren Sie zunächst das Paket azureml-fsspec und das zugehörige Paket azureml-dataprep mit den Abhängigkeiten mit pip. Anschließend können Sie die fsspec-Implementierung des Azure Machine Learning-Datenspeichers verwenden.
Die fsspec-Implementierung des Azure Machine Learning-Datenspeichers verarbeitet automatisch den Passthrough von Anmelde- und Identitätsinformationen, die vom Azure Machine Learning-Datenspeicher verwendet werden. Sie können sowohl die Offenlegung von Kontoschlüsseln in Ihren Skripts als auch zusätzliche Anmeldeprozeduren in einer Compute-Instanz vermeiden.
Beispielsweise können Sie Datenspeicher-URIs direkt in Pandas verwenden. In diesem Beispiel wird gezeigt, wie Sie eine CSV-Datei lesen:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Tipp
Um sich nicht das Datenspeicher-URI-Format merken zu müssen, können Sie den Datenspeicher-URI von der Studio-Benutzeroberfläche über diese Schritte kopieren und einfügen:
- Wählen Sie im linken Menü die Option Daten und dann die Registerkarte Datenspeicher aus.
- Wählen Sie Ihren Datenspeichernamen und dann Durchsuchen aus.
- Suchen Sie die Datei/den Ordner, die bzw. den Sie in Pandas einlesen möchten, und wählen Sie die Auslassungspunkte (...) daneben aus. Wählen Sie im Menü URI kopieren aus. Sie können den Datenspeicher-URI auswählen, der in Ihr Notebook/Skript kopiert werden soll.
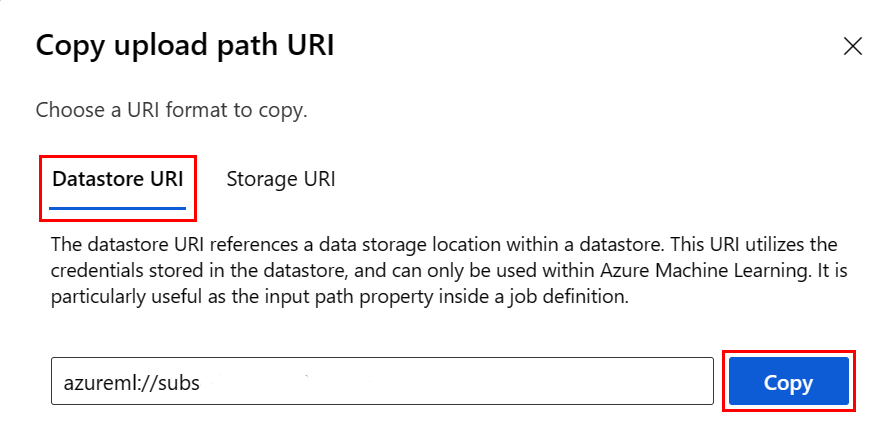
Sie können auch ein Azure Machine Learning-Dateisystem instanziieren, um dateisystemähnliche Befehle wie ls, glob, exists, open zu verarbeiten.
- Die
ls()-Methode listet Dateien in einem bestimmten Verzeichnis auf. Sie können ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) verwenden, um Dateien aufzulisten. In relativen Pfaden wird sowohl „.“ als auch „..“ unterstützt. - Die Methode
glob()unterstützt die Platzhalter „*“ und „**“. - Die Methode
exists()gibt einen booleschen Wert zurück, der angibt, ob eine angegebene Datei im aktuellen Stammverzeichnis existiert. - Die
open()-Methode gibt ein dateiähnliches Objekt zurück, das an eine beliebige andere Bibliothek übergeben werden kann, von der Python-Dateien erwartet werden. Ihr Code kann dieses Objekt auch verwenden, als wäre es ein normales Python-Dateiobjekt. Diese dateiähnlichen Objekte respektieren die Verwendung vonwith-Kontexten, wie im folgenden Beispiel gezeigt:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Hochladen von Dateien über AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath ist der lokale Pfad und rpath ist der Remotepfad.
Wenn die Ordner, die Sie in rpath angeben, noch nicht existieren, erstellen wir die Ordner für Sie.
Wir unterstützen drei Überschreibungsmodi:
- APPEND: Wenn im Zielpfad bereits eine Datei mit demselben Namen vorhanden ist, wird mit APPEND die Originaldatei beibehalten.
- FAIL_ON_FILE_CONFLICT: Wenn im Zielpfad bereits eine Datei mit demselben Namen vorhanden ist, wird von FAIL_ON_FILE_CONFLICT ein Fehler ausgegeben.
- MERGE_WITH_OVERWRITE: Wenn im Zielpfad bereits eine Datei mit demselben Namen vorhanden ist, wird diese von MERGE_WITH_OVERWRITE mit der neuen Datei überschrieben.
Herunterladen von Dateien über AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Beispiele
In diesen Beispielen wird die Verwendung der Dateisystemspezifikation in gängigen Szenarien veranschaulicht.
Lesen einer einzelnen CSV-Datei in Pandas
Sie können eine einzelne CSV-Datei wie gezeigt in Pandas lesen:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Lesen eines Ordners mit CSV-Dateien in Pandas
Die Pandas-Methode read_csv() unterstützt das Lesen eines Ordners mit CSV-Dateien nicht. Globalisieren Sie zum Behandeln dieses Verhaltens die CSV-Pfade, und verketten Sie sie mithilfe der Pandas-Methode concat() zu einem Datenrahmen. Das nächste Codebeispiel veranschaulicht, wie Sie diese Verkettung mit dem Azure Machine Learning-Dateisystem erreichen:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Lesen von CSV-Dateien in Dask
In diesem Beispiel wird gezeigt, wie Sie eine CSV-Datei in einen Dask-Datenrahmen lesen:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Lesen eines Ordners mit Parquet-Dateien in Pandas
Im Rahmen eines ETL-Prozesses werden Parquet-Dateien in der Regel in einen Ordner geschrieben, und anschließend können Dateien ausgegeben werden, die sich auf das ETL beziehen, z. B. Fortschritt, Commits usw. Das folgende Beispiel zeigt Dateien, die mit einem ETL-Prozess erstellt wurden (mit _ beginnende Dateien) und dann eine Parquet-Datei mit Daten generieren.
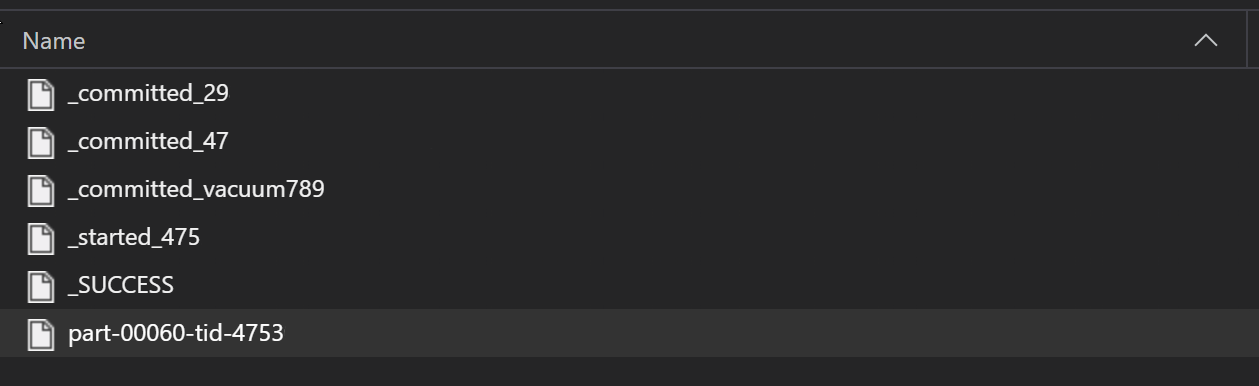
In diesen Szenarien lesen Sie nur die Parquet-Dateien im Ordner und ignorieren die ETL-Prozessdateien. Dieses Codebeispiel zeigt, wie Globmuster nur Parquet-Dateien in einem Ordner lesen können:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Zugreifen auf Daten aus Ihrem Azure Databricks-Dateisystem (dbfs)
Die Dateisystemspezifikation (fsspec) weist eine Reihe bekannter Implementierungen auf. Eine davon ist das Databricks-Dateisystem (dbfs).
Um auf Daten aus der dbfs-Ressource zuzugreifen, benötigen Sie Folgendes:
- Instanzname im Format
adb-<some-number>.<two digits>.azuredatabricks.net. Sie finden diesen Wert in der URL Ihres Azure Databricks-Arbeitsbereichs. - Persönliches Zugriffstoken (Personal Access Token, PAT). Weitere Informationen zum Erstellen eines PAT finden Sie unter Authentifizieren mit persönlichen Azure Databricks-Zugriffstoken.
Mit diesen Werten müssen Sie eine Umgebungsvariable für das PAT in Ihrer Compute-Instanz erstellen:
export ADB_PAT=<pat_token>
Sie können dann wie in diesem Beispiel gezeigt auf Daten in Pandas zugreifen:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Lesen von Images mit pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Beispiel für ein benutzerdefiniertes PyTorch-Dataset
In diesem Beispiel erstellen Sie ein benutzerdefiniertes PyTorch-Dataset zum Verarbeiten von Images. Es wird davon ausgegangen, dass eine Anmerkungsdatei (im CSV-Format) mit dieser Gesamtstruktur vorhanden ist:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Unterordner speichern diese Bilder gemäß ihren Bezeichnungen:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Eine benutzerdefinierte PyTorch-Datasetklasse muss die drei Funktionen __init__, __len__ und __getitem__ wie hier gezeigt implementieren:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Anschließend können Sie das Dataset wie hier gezeigt instanziieren:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materialisieren von Daten in Pandas mithilfe der Python-Bibliothek mltable
Die mltable-Bibliothek kann ebenfalls beim Zugriff auf Daten im Cloudspeicher helfen. Beim Lesen von Daten in Pandas mit mltable wird das folgende allgemeine Format verwendet:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Unterstützte Pfade
Die Bibliothek mltable unterstützt das Lesen von Tabellendaten aus verschiedenen Pfadtypen:
| Standort | Beispiele |
|---|---|
| Ein Pfad auf Ihrem lokalen Computer | ./home/username/data/my_data |
| Ein Pfad auf einem öffentlichen HTTP(S)-Server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ein Pfad in Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Azure Machine Learning-Datenspeicher in Langform | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Hinweis
mltable führt einen Passthrough der Anmeldeinformationen für Pfade in Azure Storage- und Azure Machine Learning-Datenspeichern durch. Wenn Sie nicht über die Berechtigung für den Zugriff auf die Daten im zugrunde liegenden Speicher verfügen, können Sie nicht auf die Daten zugreifen.
Dateien, Ordner und Globs
mltable unterstützt das Lesen aus:
- Dateien, z. B.
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - Ordnern, z. B.
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - Globmustern, z. B.
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - einer Kombination aus Dateien, Ordnern und/oder Globmustern
Dank der Flexibilität von mltable können Sie Daten aus einer Kombination aus lokalen und cloudbasierten Speicherressourcen und Kombinationen von Dateien/Ordnern/Globs in einem einzelnen Datenrahmen materialisieren. Beispiel:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Unterstützte Dateiformate
mltable unterstützt die folgenden Dateiformate:
- Durch Trennzeichen getrennter Text (z. B. CSV-Dateien):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - JSON-Zeilenformat:
mltable.from_json_lines_files(paths=[path])
Beispiele
Lesen einer CSV-Datei
Aktualisieren Sie die Platzhalter (<>) in diesem Codeschnipsel mit Ihren eigenen Details:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lesen von Parquet-Dateien in einem Ordner
Dieses Beispiel zeigt, wie mltable Globmuster (etwa Platzhalter) verwenden kann, um sicherzustellen, dass nur die Parquet-Dateien gelesen werden.
Aktualisieren Sie die Platzhalter (<>) in diesem Codeschnipsel mit Ihren eigenen Details:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lesen von Datenressourcen
In diesem Abschnitt erfahren Sie, wie Sie auf Ihre Azure Machine Learning-Datenobjekte in Pandas zugreifen.
Tabellenressource
Wenn Sie zuvor ein Tabellenobjekt in Azure Machine Learning erstellt haben (mltable oder V1-TabularDataset), können Sie dieses mit dem folgenden Code in Pandas laden:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Dateiressource
Wenn Sie ein Dateiobjekt (z. B. eine CSV-Datei) registriert haben, können Sie dieses Objekt mit dem folgenden Code in einen Pandas-Datenrahmen lesen:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Ordnerressource
Wenn Sie ein Ordnerobjekt (uri_folder oder V1-FileDataset) wie einen Ordner, der eine CSV-Datei enthält, registriert haben, können Sie dieses Objekt mit dem folgenden Code in einen Pandas-Datenrahmen lesen:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Hinweis zum Lesen und Verarbeiten großer Datenmengen mit Pandas
Tipp
Pandas ist nicht für die Verarbeitung großer Datasets konzipiert. Pandas kann nur Daten verarbeiten, die in den Arbeitsspeicher der Compute-Instanz passen.
Für große Datasets wird die Verwendung von Spark mit Azure Machine Learning-Verwaltung empfohlen. Dadurch wird die PySpark Pandas-API bereitgestellt.
Möglicherweise möchten Sie eine kleinere Teilmenge eines großen Datasets schnell durchlaufen, bevor Sie auf einen asynchronen Remoteauftrag hochskalieren. mltable bietet integrierte Funktionen zum Abrufen von Beispielen großer Datenmengen mithilfe der Methode take_random_sample:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Sie können auch Teilmengen großer Datenmengen mit den folgenden Vorgängen abrufen:
Herunterladen von Daten mithilfe des Hilfsprogramms azcopy
Verwenden Sie das Hilfsprogramm azcopy, um die Daten auf das lokale SSD Ihres Hosts (lokaler Computer, Cloud-VM, Azure Machine Learning-Compute-Instanz usw.) im lokalen Dateisystem herunterzuladen. Das Hilfsprogramm azcopy, das in einer Azure Machine Learning-Compute-Instanz vorinstalliert ist, übernimmt den Datendownload. Wenn Sie keine Azure Machine Learning-Compute-Instanz oder DSVM-Instanz (Data Science Virtual Machine) verwenden, müssen Sie möglicherweise azcopy installieren. Weitere Informationen finden Sie unter azcopy.
Achtung
Wir empfehlen keine Datendownloads an den Speicherort /home/azureuser/cloudfiles/code in einer Compute-Instanz. Dieser Speicherort dient zum Speichern von Notebook- und Codeartefakten, nicht zum Speichern von Daten. Das Lesen von Daten an diesem Speicherort verursacht beim Training einen erheblichen Mehraufwand. Stattdessen wird empfohlen, Ihre Daten in home/azureuser zu speichern. Dabei handelt es sich um das lokale SSD des Serverknotens.
Öffnen Sie ein Terminal, und erstellen Sie ein neues Verzeichnis. Beispiel:
mkdir /home/azureuser/data
Melden Sie sich mithilfe des folgenden Befehls bei azcopy an:
azcopy login
Als Nächstes können Sie Daten mithilfe eines Speicher-URI kopieren:
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST