Einrichten von AutoML zum Trainieren eines Zeitreihenvorhersagemodells mit Python (SDKv1)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie das AutoML-Training für Zeitreihenvorhersagemodelle mit dem automatisierten ML von Azure Machine Learning im Azure Machine Learning Python SDKeinrichten.
Dazu gehen Sie wie folgt vor:
- Vorbereiten von Daten für die Zeitreihenmodellierung
- Konfigurieren spezifischer Zeitreihenparameter in einem Objekt vom Typ
AutoMLConfig - Ausführen von Vorhersagen mit Zeitreihendaten
Für ein Vorgehen mit wenig Code folgen Sie dem Tutorial: Vorhersage des Bedarfs mithilfe von automatisiertem maschinellem Lernen für ein Zeitreihenvorhersagebeispiel mit automatisiertem ML im Azure Machine Learning Studio.
Im Gegensatz zu klassischen Methoden für Zeitreihen werden beim automatisierten maschinellen Lernen Zeitreihenwerte aus der Vergangenheit „pivotiert“ und dienen so zusammen mit anderen Vorhersageelementen als zusätzliche Dimensionen für den Regressor. Dieser Ansatz umfasst mehrere Kontextvariablen und deren Beziehung zueinander beim Training. Da sich mehrere Faktoren auf eine Vorhersage auswirken können, richtet sich diese Methode gut an realen Vorhersageszenarios aus. Wenn z. B. Verkaufszahlen vorhergesagt werden sollen, wird das Ergebnis auf der Grundlage von Wechselwirkungen zwischen historischen Trends, des Wechselkurses und des Preises berechnet.
Voraussetzungen
Für diesen Artikel ist Folgendes erforderlich:
Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen des Arbeitsbereichs finden Sie unter Schnellstart: So erstellen Sie Arbeitsbereichsressourcen, die Sie für die ersten Schritte mit Azure Machine Learning benötigen.
In diesem Artikel werden Grundkenntnisse in der Einrichtung eines Experiments mit automatisiertem maschinellem Lernen vorausgesetzt. Folgen Sie der Schrittanleitung, um die wichtigsten Entwurfsmuster für automatisierte ML-Experimente kennenzulernen.
Wichtig
Für die Python-Befehle in diesem Artikel ist die neueste
azureml-train-automl-Paketversion erforderlich.- Installieren Sie das neueste
azureml-train-automl-Paket in Ihrer lokalen Umgebung. - Einzelheiten zum neuesten
azureml-train-automl-Paket finden Sie in den Versionshinweisen.
- Installieren Sie das neueste
Trainings- und Überprüfungsdaten
Der wichtigste Unterschied zwischen einem Regressionsaufgabentyp für Vorhersagen und einem Regressionsaufgabentyp im automatisierten ML liegt in der Einbeziehung eines Features in Ihre Trainingsdaten, das eine gültige Zeitreihe darstellt. Eine reguläre Zeitreihe besitzt ein klar definiertes und konsistentes Intervall sowie einen Wert an jedem Stichprobenpunkt in einem ununterbrochenen Zeitraum.
Wichtig
Stellen Sie beim Trainieren eines Modells für die Vorhersage zukünftiger Werte sicher, dass alle während des Trainings verwendeten Features beim Ausführen von Vorhersagen für Ihren gewünschten Vorhersagehorizont verwendet werden können. Wenn Sie also beispielsweise eine Nachfrageprognose erstellen, lässt sich die Trainingsgenauigkeit durch die Einbeziehung eines Features für den aktuellen Aktienkurs erheblich verbessern. Wenn Sie bei Ihrer Vorhersage allerdings einen Vorhersagehorizont verwenden, der weit in der Zukunft liegt, lassen sich zukünftige Aktienkurse für zukünftige Zeitreihenpunkte ggf. nicht präzise vorhersagen, was sich nachteilig auf die Modellgenauigkeit auswirken kann.
Sie können separate Trainingsdaten und Überprüfungsdaten direkt im AutoMLConfig-Objekt angeben. Erfahren Sie mehr über AutoMLConfig.
Bei Zeitreihenprognosen wird standardmäßig nur die Kreuzvalidierung mit rollierendem Ursprung (ROCV) zur Überprüfung verwendet. Die ROCV teilt die Reihe in Trainings- und Validierungsdaten mit einem Ursprungszeitpunkt auf. Wenn der Ursprung zeitlich verschoben wird, werden Teilmengen für die Kreuzvalidierung erstellt. Mit dieser Strategie wird die Datenintegrität von Zeitreihen beibehalten und das Risiko von Datenlecks vermieden.
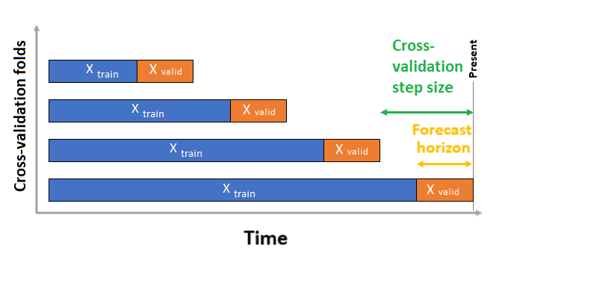
Übergeben Sie Ihre Trainings- und Validierungsdaten als ein Dataset an den Parameter training_data. Legen Sie die Anzahl der Kreuzüberprüfungsfalten mit dem Parameter n_cross_validations und die Anzahl der Perioden zwischen zwei aufeinander folgenden Kreuzvalidierungungsfalten mit cv_step_size fest. Sie können auch entweder einen oder beide Parameter leer lassen und von AutoML automatisch festlegen lassen.
GILT FÜR: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Sie können auch eigene Validierungsdaten importieren. Weitere Informationen finden Sie unter Konfigurieren von Datenaufteilungen und Kreuzvalidierung in AutoML.
Erfahren Sie mehr darüber, wie AutoML die Kreuzvalidierung anwendet, um eine Überanpassung von Modellen zu verhindern.
Konfigurieren des Experiments
Das Objekt AutoMLConfig definiert die erforderlichen Einstellungen und Daten für eine Aufgabe mit automatisiertem maschinellem Lernen. Die Konfiguration für ein Vorhersagemodell ähnelt der Einrichtung eines Standardregressionsmodells, aber bestimmte Modelle, Konfigurationsoptionen und Featurisierungsschritte gelten speziell für Zeitreihendaten.
Unterstützte Modelle
Beim automatisierten maschinellen Lernen werden im Rahmen des Modellerstellungs- und Optimierungsprozesses automatisch verschiedene Modelle und Algorithmen getestet. Als Benutzer müssen Sie den Algorithmus nicht angeben. Bei Vorhersageexperimenten sind sowohl native Zeitreihen- als auch Deep Learning-Modelle Teil des Empfehlungssystems.
Tipp
Herkömmliche Regressionsmodelle werden ebenfalls als Teil des Empfehlungssystems für Vorhersageexperimente getestet. Eine vollständige Liste der unterstützten Modelle finden Sie in der SDK-Referenzdokumentation.
Konfigurationseinstellungen
Sie definieren Standardtrainingsparameter wie Aufgabentyp, Iterationsanzahl, Trainingsdaten und Anzahl von Kreuzvalidierungen (ähnlich wie bei einem Regressionsproblem). Für Vorhersageaufgaben sind die Parameter time_column_name und forecast_horizon zum Konfigurieren Ihres Experiments erforderlich. Wenn die Daten mehrere Zeitreihen enthalten, z. B. Verkaufsdaten für mehrere Filialen oder Energiedaten über verschiedene Zustände hinweg, erkennt das automatisierte maschinelle Lernen dies automatisch und legt den Parameter time_series_id_column_names (Vorschau) für Sie fest. Sie können auch zusätzliche Parameter einschließen, um Ihre Ausführung besser zu konfigurieren. Weitere Informationen zu den Elementen, die einbezogen werden können, finden Sie im Abschnitt Optionale Konfigurationen.
Wichtig
Die automatische Zeitreihenidentifikation befindet sich derzeit in der öffentlichen Vorschauversion. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
| Parametername | BESCHREIBUNG |
|---|---|
time_column_name |
Dient zum Angeben der Datetime-Spalte in den Eingabedaten, die zum Erstellen der Zeitreihe sowie zum Ableiten des Intervalls verwendet wird. |
forecast_horizon |
Definiert die Anzahl der Zeiträume, die Sie vorhersagen möchten. Der Horizont wird in Einheiten der Zeitreihenhäufigkeit angegeben. Die Einheiten basieren auf dem Zeitintervall Ihrer Trainingsdaten, z. B. monatlich oder wöchentlich, die vorhergesagt werden sollen. |
Für den folgenden Code gilt:
- Es verwendet die
ForecastingParameters-Klasse, um die Prognoseparameter für Ihr Experimenttraining zu definieren - Er legt
time_column_nameauf das Feldday_datetimeim Dataset fest. - Er legt
forecast_horizonauf 50 fest, um die Prognose für den gesamten Testsatz durchzuführen.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Diese forecasting_parameters werden dann zusammen mit dem forecasting-Aufgabentyp, der primären Metrik, den Beendigungskriterien und den Trainingsdaten an das standardmäßige AutoMLConfig-Objekt weitergeleitet.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Die Menge der Daten, die für ein erfolgreiches Training eines Vorhersagemodells mit automatisiertem maschinellen Lernen erforderlich ist, wird durch die forecast_horizon-, n_cross_validations- und target_lags- oder target_rolling_window_size-Werte beeinflusst, die bei der Konfiguration Ihrer AutoMLConfig angegeben werden.
Die folgende Formel berechnet die Menge der Verlaufsdaten, die für die Konstruktion von Zeitreihenfeatures benötigt werden.
Mindestens erforderliche Verlaufsdaten: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Für jede Reihe im Dataset, die nicht die erforderliche Menge an Verlaufsdaten für die angegebenen relevanten Einstellungen erfüllt, wird eine Error exception ausgelöst.
Featurisierungsschritte
Standardmäßig werden in jedem Experiment mit automatisiertem maschinellem Lernen automatische Skalierungs- und Normalisierungstechniken auf Ihre Daten angewandt. Bei diesen Techniken handelt es sich um Formen der Featurisierung, die für bestimmte Algorithmen hilfreich sind, die auf Features unterschiedlicher Größenordnungen reagieren. Weitere Informationen zu den Standardfeaturisierungsschritten finden Sie unter Featurisierung in AutoML.
Die folgenden Schritte werden jedoch nur für forecasting-Aufgabentypen ausgeführt:
- Erkennen des Intervalls der Zeitreihenstichprobe (z. B. stündlich, täglich, wöchentlich) und Erstellen neuer Datensätze für fehlende Zeitpunkte, um eine ununterbrochene Reihe zu erhalten.
- Imputieren fehlender Werte in der Zielspalte (mittels Forward-Fill) und der Featurespalte (mittels Median-Spaltenwerten)
- Erstellen von Features auf der Basis von Zeitreihenbezeichnern zum Ermöglichen von reihenübergreifenden festen Effekten
- Erstellen zeitbasierter Features zur Ermittlung saisonaler Muster
- Codieren kategorischer Variablen zu numerischen Mengen
- Erkennen Sie die nicht stationären Zeitreihen, und unterscheiden Sie sie automatisch, um die Auswirkungen der Einheitswurzeln zu verringern.
Eine vollständige Liste der möglichen entwickelten Features, die aus Zeitreihendaten generiert wurden, finden Sie unter TimeIndexFeaturizer-Klasse.
Hinweis
Die Schritte zur Featurebereitstellung bei automatisiertem maschinellen Lernen (Featurenormalisierung, Behandlung fehlender Daten, Umwandlung von Text in numerische Daten usw.) werden Teil des zugrunde liegenden Modells. Bei Verwendung des Modells für Vorhersagen werden die während des Trainings angewendeten Schritte zur Featurebereitstellung automatisch auf Ihre Eingabedaten angewendet.
Anpassen der Featurisierung
Sie können die Featurisierungseinstellungen auch anpassen, um sicherzustellen, dass die Daten und Features zum Trainieren Ihres ML-Modells zu relevanten Vorhersagen führen.
Unterstützte Anpassungen für forecasting-Aufgaben umfassen:
| Anpassung | Definition |
|---|---|
| Aktualisierung des Spaltenzwecks | Außerkraftsetzen des automatisch erkannten Featuretyps für die angegebene Spalte. |
| Aktualisierung von Transformationsparametern | Aktualisieren der Parameter für den angegebenen Transformator. Unterstützt derzeit Imputer (fill_value und median). |
| Löschen von Spalten | Gibt Spalten an, die aus der Featureverwendung gelöscht werden sollen. |
Um die Featurisierung mit dem SDK anzupassen, geben Sie "featurization": FeaturizationConfig in Ihrem AutoMLConfig-Objekt an. Erfahren Sie mehr über benutzerdefinierte Featurisierungen.
Hinweis
Die Funktion Spalten löschen ist seit SDK-Version 1.19 veraltet. Löschen Sie Spalten im Rahmen der Datenbereinigung aus Ihrem Dataset, bevor Sie es in Ihrem automatisierten ML-Experiment nutzen.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Wenn Sie Azure Machine Learning Studio für Ihr Experiment verwenden, finden Sie weitere Informationen unter Anpassen der Featurisierung in Studio.
Optionale Konfigurationen
Für Vorhersageaufgaben sind weitere optionale Konfigurationen verfügbar, z. B. das Aktivieren von Deep Learning und das Angeben einer rollierenden Zielfensteraggregation. Eine vollständige Liste der weiteren Parameter finden Sie in der Referenzdokumentation zum ForecastingParameters SDK.
Häufigkeit und Zieldatenaggregation
Verwenden Sie den Häufigkeitsparameter freq, um Fehler zu vermeiden, die durch unregelmäßige Daten verursacht werden. Unregelmäßige Daten umfassen Daten, die keinem festgelegten Rhythmus, z. B. stündliche oder tägliche Daten, folgen.
Für sehr unregelmäßige Daten oder für variierende Geschäftsanforderungen können Benutzer die gewünschte Vorhersagehäufigkeit freq festlegen und die target_aggregation_function angeben, um die Zielspalte der Zeitreihe zu aggregieren. Die Verwendung dieser beiden Einstellungen im AutoMLConfig-Objekt, können Ihnen bei der Datenaufbereitung Zeit sparen.
Unterstützte Aggregationsvorgänge für Zielspaltenwerte:
| Funktion | BESCHREIBUNG |
|---|---|
sum |
Summe der Zielwerte |
mean |
Mittelwert oder Durchschnitt der Zielwerte |
min |
Minimalwert eines Ziels |
max |
Maximalwert eines Ziels |
Aktivieren von Deep Learning
Hinweis
Die DNN-Unterstützung für Vorhersagen in Automated Machine Learning befindet sich in der Vorschau und wird für lokale oder in Databricks initiierte Läufe nicht unterstützt.
Sie können auch Deep Learning mit Deep Neural Networks (DNNs) anwenden, um die Scores des Modells zu verbessern. Deep Learning mit automatisiertem maschinellem Lernen ermöglicht das Vorhersagen von ein- und mehrdimensionalen Zeitreihendaten.
Deep Learning-Modelle weisen drei intrinsische Funktionen auf:
- Sie können von beliebigen Zuordnungen von Eingaben zu Ausgaben lernen.
- Sie unterstützen mehrere Eingaben und Ausgaben.
- Sie können automatisch Muster in Eingabedaten extrahieren, die lange Folgen umfassen.
Um Deep Learning zu aktivieren, legen Sie enable_dnn=True im AutoMLConfig-Objekt fest.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Warnung
Wenn Sie DNN für mit dem SDK erstellte Experimente aktivieren, sind Erläuterungen des besten Modells deaktiviert.
Informationen zum Aktivieren von DNN für ein AutoML-Experiment, das in Azure Machine Learning Studio erstellt wurde, finden Sie in der Schrittanleitung für Aufgabentypeinstellungen in Studio.
Rollierende Zeitfensteraggregationen als Ziel
Häufig sind die besten Informationen, die ein Vorhersagemodell liefern kann, der aktuelle Wert des Ziels. Wenn Sie rollierende Zeitfensteraggregationen als Ziel verwenden, können Sie eine rollierende Aggregation von Datenwerten als Features hinzufügen. Durch Erzeugen und Verwenden dieser Features als zusätzliche Kontextdaten wird die Genauigkeit des Trainingsmodells gesteigert.
Angenommen, Sie möchten den Energiebedarf vorhersagen. Sie können ein Feature für rollierende Zeitfenster von drei Tagen hinzufügen, um thermische Änderungen beheizter Räume zu erfassen. In diesem Beispiel erstellen Sie dieses Fenster, indem Sie im AutoMLConfig-Konstruktor target_rolling_window_size= 3 festlegen.
In der Tabelle wird das resultierende Feature Engineering dargestellt, das auftritt, wenn die Zeitfensteraggregation angewandt wird. Spalten für die Werte minimum, maximum und sum werden in einem gleitenden Fenster über drei Einträge basierend auf den definierten Einstellungen generiert. Jede Zeile verfügt über ein neues berechnetes Feature. Für den Zeitstempel „8. September 2017, 4:00 Uhr“ werden die Werte „maximum“, „minimum“ und „sum“ mithilfe der Anforderungswerte für den 8. September 2017, 1:00 Uhr bis 3:00 Uhr, berechnet. Dieses drei Einträge umfassende Fenster wird verschoben, um die verbleibenden Zeilen mit Daten aufzufüllen.

Sehen Sie sich ein Python-Codebeispiel an, in dem das Feature für rollierende Zeitfensteraggregationen als Ziel angewendet wird.
Verarbeitung kurzer Reihen
Beim automatisierten ML gilt eine Zeitreihe als kurze Reihe, wenn nicht genügend Datenpunkte vorhanden sind, um die Trainings- und Validierungsphasen der Modellentwicklung durchzuführen. Die Anzahl von Datenpunkten variiert je nach Experiment und hängt vom max_horizon-Wert, der Anzahl von Kreuzvalidierungsteilungen und der Länge des Rückblickzeitraums des Modells ab, d. h. den maximalen Verlaufsdaten, die zum Erstellen der Zeitreihenfeatures erforderlich sind.
Automatisiertes maschinelles Lernen bietet mit dem short_series_handling_configuration-Parameter im ForecastingParameters-Objekt standardmäßig eine Verarbeitung kurzer Reihen.
Zum Aktivieren der Verarbeitung kurzer Reihen muss auch der freq-Parameter definiert werden. Zum Definieren einer stündlichen Häufigkeit legen Sie freq='H' fest. Die Optionen für die Häufigkeitszeichenfolge können Sie im Abschnitt zu DataOffset-Objekten auf der Seite über Pandas-Zeitreihen einsehen. Wenn Sie das Standardverhalten (short_series_handling_configuration = 'auto') ändern möchten, aktualisieren Sie den short_series_handling_configuration-Parameter in Ihrem ForecastingParameter-Objekt.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
In der folgenden Tabelle finden Sie eine Zusammenfassung der verfügbaren Einstellungen für short_series_handling_config.
| Einstellung | BESCHREIBUNG |
|---|---|
auto |
Der Standardwert für die Verarbeitung kurzer Reihen. - Wenn alle Reihen kurz sind, werden die Daten aufgefüllt. - Wenn nicht alle Reihen kurz sind, werden die kurzen Reihen gelöscht. |
pad |
Wenn short_series_handling_config = pad festgelegt ist, fügt das automatisierte maschinelle Lernen allen gefundenen kurzen Reihen Zufallswerte hinzu. Im Folgenden sind die Spaltentypen und die Werte aufgeführt, mit denen sie aufgefüllt werden: – Objektspalten mit nicht numerischen Werten – Numerische Spalten mit 0 – Boolesche/logische Spalten mit „False“ – Die Zielspalte wird mit Zufallswerten mit dem Mittelwert 0 und der Standardabweichung 1 aufgefüllt. |
drop |
Wenn short_series_handling_config = drop festgelegt ist, werden die kurzen Reihen vom automatisierten maschinellen Lernen gelöscht und nicht für Trainings- oder Vorhersagezwecke verwendet. Bei Vorhersagen für diese Reihen werden NaN-Werte zurückgegeben. |
None |
Es werden keine Reihen aufgefüllt oder gelöscht. |
Warnung
Das Auffüllen kann sich auf die Genauigkeit des resultierenden Modells auswirken, da künstliche Daten genutzt werden, um vergangene Trainings ohne Fehler abzurufen. Wenn viele der Reihen kurz sind, kann sich dies auch auf die Erklärbarkeit der Ergebnisse auswirken.
Erkennung und Verarbeitung von Nicht-Stationaritäts-Zeitreihen
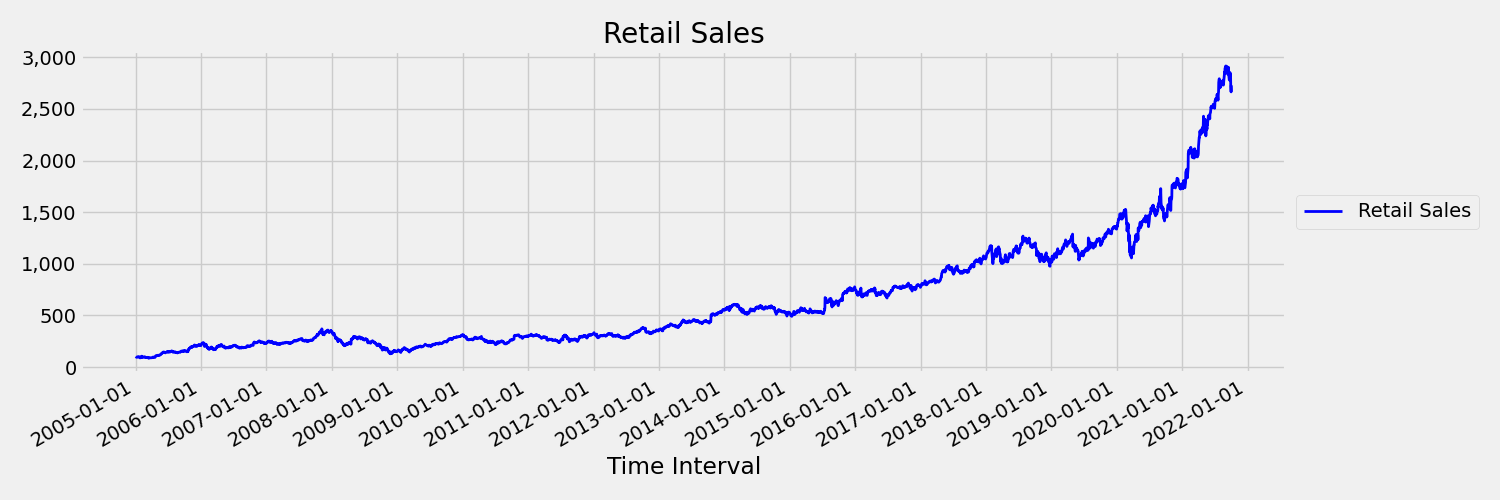
Eine Zeitreihe, deren Momente (Mittelwert und Varianz) sich im Laufe der Zeit ändern, wird als nicht stationär bezeichnet. Zeitreihen, die stochastische Trends aufweisen, sind beispielsweise von Natur aus nicht stationär. Zur Visualisierung ist in der folgenden Abbildung eine Reihe dargestellt, deren Trend im Allgemeinen nach oben geht. Berechnen und vergleichen Sie nun die Mittelwerte (Durchschnitt) für die erste und die zweite Hälfte der Reihe. Sind sie identisch? Hier ist der Mittelwert der Reihe in der ersten Hälfte der Darstellung kleiner als in der zweiten Hälfte. Die Tatsache, dass der Mittelwert der Reihe vom Zeitintervall abhängt, das betrachtet wird, ist ein Beispiel für die zeitbezogenen Momente. Hier ist der Mittelwert einer Reihe der erste Moment.
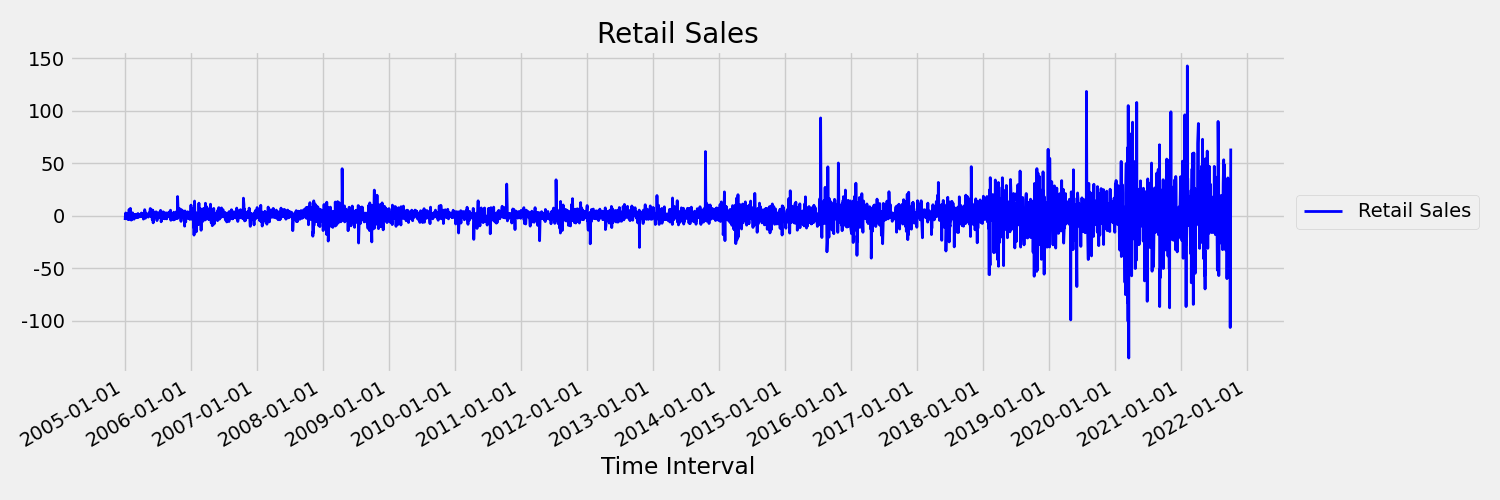
Als Nächstes sehen wir uns die Abbildung an, in der die ursprüngliche Reihe in ersten Differenzen dargestellt wird: $x_t = y_t - y_{t-1}$. Dabei ist $x_t$ die Änderung des Einzelhandelsumsatzes, und $y_t$ und $y_{t-1}$ stellen die ursprüngliche Reihe bzw. ihre erste Verzögerung dar. Der Mittelwert der Reihe ist ungefähr konstant, unabhängig vom betrachteten Zeitrahmen. Dies ist ein Beispiel für eine stationäre Zeitreihe der ersten Bestellung. Der Grund dafür, dass wir den Begriff „erste Bestellung“ hinzugefügt haben, ist, dass sich der erste Moment (Mittelwert) nicht mit dem Zeitintervall ändert. Dasselbe kann jedoch nicht über die Varianz gesagt werden, bei der es sich um den zweiten Moment handelt.
AutoML Machine Learning-Modelle können stochastische Trends oder andere bekannte Probleme im Zusammenhang mit nicht stationären Zeitreihen nicht inhärent behandeln. Infolgedessen ist ihre Prognosegenauigkeit außerhalb von Stichproben „schlecht“, wenn solche Trends vorhanden sind.
AutoML analysiert automatisch Zeitreihendatasets, um zu überprüfen, ob sie stationär sind. Wenn nicht-stationäre Zeitreihen erkannt werden, wendet automatisiertes ML automatisch eine unterscheidende Transformation an, um die Auswirkungen nicht-stationärer Zeitreihen zu mindern.
Ausführen des Experiments
Wenn das AutoMLConfig-Objekt bereit ist, können Sie das Experiment übermitteln. Rufen Sie nach Fertigstellung des Modells die Iteration mit der besten Ausführung ab.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Vorhersagen mit dem besten Modell
Verwenden Sie die beste Modelliteration, um Werte für Daten vorherzusagen, die nicht zum Trainieren des Modells verwendet wurden.
Auswerten der Modellgenauigkeit mit einer rollierenden Vorhersage
Bevor Sie ein Modell in die Produktion aufnehmen, sollten Sie seine Genauigkeit für einen Testsatz aus den Trainingsdaten auswerten. Ein bewährtes Verfahren ist eine sogenannte rollierende Auswertung, welche die trainierte Vorhersagefunktion über einen Zeitraum auf den Testsatz überträgt, wobei der Durchschnitt für Fehlermetriken über mehrere Vorhersagefenster berechnet wird, um statistisch stabile Schätzungen für einige ausgewählte Metriken zu ermitteln. Im Idealfall ist der Testsatz für die Auswertung relativ zum Vorhersagehorizont des Modells lang. Schätzungen von Vorhersagefehlern können andernfalls statistisch beeinträchtigend und daher weniger zuverlässig sein.
Angenommen, Sie trainieren ein Modell für den täglichen Umsatz, um die Nachfrage für bis zu zwei Wochen (14 Tage) in der Zukunft vorherzusagen. Wenn genügend Verlaufsdaten verfügbar sind, können Sie die letzten Monate bis zu einem Jahr der Daten für den Testsatz reservieren. Die rollierende Auswertung beginnt mit der Erstellung einer Prognose 14 Tage im Voraus für die ersten beiden Wochen des Testsatzes. Anschließend wird die Vorhersagefunktion um eine gewisse Anzahl von Tagen im Testsatz vorgerückt, und Sie generieren eine weitere Prognose für 14 Tage im Voraus aus der neuen Position. Der Prozess wird fortgesetzt, bis Sie das Ende des Testsatzes erreichen.
Um eine rollierende Auswertung durchführen zu können, rufen Sie die rolling_forecast-Methode von fitted_model auf, und berechnen dann die gewünschten Metriken für das Ergebnis. Angenommen, Sie verfügen über Testsatzfeatures in einem Pandas-DataFrame namens test_features_df und den Testsatz mit tatsächlichen Werten des Ziels in einem Numpy-Array namens test_target. Eine fortlaufende Auswertung mit der mittleren quadratischen Abweichung wird im folgenden Codebeispiel gezeigt:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
In dieser Stichprobe wird die Schrittgröße für die rollierende Vorhersage auf 1 festgelegt, was bedeutet, dass die Vorhersagefunktion bei jeder Iteration um einen Zeitraum oder einen Tag in unserem Beispiel für die Bedarfsvorhersage fortgeschritten ist. Die Gesamtzahl der von rolling_forecast zurückgegebenen Prognosen hängt daher von der Länge des Testsatzes und dieser Schrittgröße ab. Weitere Details und Beispiele finden Sie in der Dokumentation zu rolling_forecast() und im Notebook zur Vorhersage über Trainingsdaten.
Vorhersagen für die Zukunft
Die Funktion forecast_quantiles() ermöglicht anzugeben, wann Vorhersagen gestartet werden sollten. Im Gegensatz dazu wird die predict()-Methode in der Regel für Klassifizierungs- und Regressionsaufgaben verwendet. Die Methode „forecast_quantiles()“ generiert standardmäßig eine Punkt- oder eine Mittelwertvorhersage, die nicht von einem Kegel der Unsicherheit umgeben ist. Weitere Informationen finden Sie im Notebook zur Vorhersage über Trainingsdaten.
Im folgenden Beispiel ersetzen Sie zunächst alle Werte in y_pred durch NaN. Der Ursprung der Vorhersage liegt in diesem Fall am Ende der Trainingsdaten. Wenn Sie jedoch nur die zweite Hälfte von y_pred durch NaN ersetzen, lässt die Funktion die numerischen Werte in der ersten Hälfte unverändert, sagt aber die NaN-Werte in der zweiten Hälfte voraus. Die Funktion gibt sowohl die vorhergesagten Werte als auch die angepassten Features zurück.
Sie können den Parameter forecast_destination in der Funktion forecast_quantiles() auch verwenden, um Werte bis zu einem bestimmten Datum vorherzusagen.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Häufig möchten Kunden die Vorhersagen für ein bestimmtes Quantil der Verteilung verstehen. Wenn z. B. die Vorhersage verwendet wird, um den Bestand an Lebensmitteln oder virtuellen Computern für einen Clouddienst zu kontrollieren. In solchen Fällen lautet der Steuerungspunkt in der Regel: „Wir möchten, dass der Artikel zu 99 % der Zeit auf Lager ist und nicht ausgeht“. Im Folgenden wird gezeigt, wie Sie angeben, welche Quantilen Sie für Ihre Vorhersagen sehen möchten, z. B. das 50. oder 95. Perzentil. Wenn Sie kein Quantil angeben, wie im oben genannten Codebeispiel, werden nur die Vorhersagen für das 50. Perzentil erstellt.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Sie können Modellmetriken wie die mittlere quadratische Gesamtabweichung (Root Mean Squared Error, RMSE) oder die mittlere absolute prozentuale Abweichung (Mean Absolute Percentage Error, MAPE) berechnen, um die Modellleistung einzuschätzen. Ein Beispiel finden Sie im Notebook zum Auswerten des Fahrradsharingbedarfs.
Nach dem Ermitteln der allgemeinen Modellgenauigkeit besteht der nächste Schritt in der Regel darin, mithilfe des Modells unbekannte zukünftige Werte vorherzusagen.
Stellen Sie ein Dataset im gleichen Format wie das Testdataset test_dataset, aber mit zukünftigen Datums-/Uhrzeitwerten bereit, um einen Vorhersagesatz mit Vorhersagewerten für die einzelnen Zeitreihenschritte zu erhalten. Angenommen, die letzten Zeitreihendatensätze im Dataset waren für den 31.12.2018. Wenn Sie die Nachfrage für den Folgetag (oder für beliebig viele Vorhersagezeiträume <= forecast_horizon) vorhersagen möchten, erstellen Sie für jede Filiale einen einzelnen Zeitreihendatensatz für den 01.01.2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Wiederholen Sie die erforderlichen Schritte, um diese zukünftigen Daten in einen Datenrahmen zu laden, und führen Sie anschließend best_run.forecast_quantiles(test_dataset) aus, um zukünftige Werte vorherzusagen.
Hinweis
In-Sample-Vorhersagen werden für die Vorhersage mit automatisiertem maschinellen Lernen nicht unterstützt, wenn target_lags und/oder target_rolling_window_size aktiviert sind.
Vorhersagen im großen Stil
Es gibt Szenarios, in denen ein einzelnes Machine Learning-Modell nicht ausreicht und mehrere Machine Learning-Modelle benötigt werden. Beispiele hierfür sind die Vorhersage des Umsatzes für jedes einzelne Geschäft einer Marke oder das Anpassen einer Benutzeroberfläche an die einzelnen Benutzer*innen. Das Erstellen eines Modells für jede Instanz kann bei vielen Problemen im Bereich des maschinellen Lernens zu besseren Ergebnissen führen.
Das Gruppieren ist ein Konzept bei der Zeitreihenvorhersage, bei dem Zeitreihen kombiniert werden können, um ein einzelnes Modell pro Gruppe zu trainieren. Dieser Ansatz kann besonders hilfreich sein, wenn Sie über Zeitreihen verfügen, bei denen eine Glättung, eine Füllung oder Entitäten in der Gruppe erforderlich sind, die vom Verlauf oder Trends für andere Entitäten profitieren können. Viele Modelle und hierarchische Zeitreihenvorhersagen sind Lösungen, die durch automatisiertes maschinelles Lernen für diese umfangreichen Vorhersageszenarios unterstützt werden.
Viele Modelle
Die Azure Machine Learning-Lösung mit vielen Modellen mit automatisiertem maschinellem Lernen ermöglicht Benutzern das gleichzeitige Trainieren und Verwalten von Millionen von Modellen. Der Many Models Solution Accelerator verwendet Azure Machine Learning-Pipelines zum Trainieren der Modelle. Genauer gesagt werden ein Pipeline-Objekt und ParallelRunStep verwendet, und es müssen bestimmte Konfigurationsparameter über ParallelRunConfig festgelegt werden.
Das folgende Diagramm zeigt den Workflow für die Lösung mit vielen Modellen.

Der folgende Code enthält die wichtigsten Parameter, die Benutzer*innen benötigen, um das Ausführen der vielen Modelle einzurichten. Im Notebook für viele Modelle – Automatisiertes ML finden Sie ein Beispiel für die Vorhersage vieler Modelle.
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Hierarchische Zeitreihenvorhersage
In den meisten Anwendungen müssen Kunden ihre Prognosen auf einer Makro- und Mikroebene des Unternehmens verstehen. Prognosen können den Umsatz von Produkten an verschiedenen geografischen Standorten vorhersagen oder die erwartete Mitarbeiternachfrage für verschiedene Organisationen in einem Unternehmen verstehen. Die Fähigkeit, ein Machine Learning-Modell so zu trainieren, dass es intelligente Vorhersagen basierend auf Hierarchiedaten trifft, ist von zentraler Bedeutung.
Eine hierarchische Zeitreihe ist eine Struktur, in der alle Reihen basierend auf Dimensionen wie Geografie oder Produkttyp in einer Hierarchie angeordnet sind. Das folgende Beispiel zeigt Daten mit eindeutigen Attributen, die hierarchisch angeordnet sind. Die Hierarchie in diesem Fall wird basierend auf dem Produkttyp (z. B. Kopfhörer oder Tablets), der Produktkategorie, die die Produkttypen weiter in Zubehör und Geräte unterteilt, und der Region definiert, in der die Produkte verkauft werden.

Zur weiteren Veranschaulichung enthalten die Blattebenen der Hierarchie alle Zeitreihen mit eindeutigen Kombinationen aus Attributwerten. Jede nächsthöhere Ebene in der Hierarchie berücksichtigt eine Dimension weniger beim Definieren der Zeitreihe und aggregiert jede Gruppe untergeordneter Knoten auf der Ebene darunter in einem übergeordneten Knoten.

Die hierarchische Zeitreihenlösung baut auf der Lösung mit vielen Modellen auf und verwendet ein ähnliches Konfigurationssetup.
Der folgende Code enthält die wichtigsten Parameter, die Sie benötigen, um das Ausführen der hierarchischen Zeitreihenvorhersagen einzurichten. Ein umfassendes Beispiel finden Sie im Notebook für hierarchische Zeitreihen – Automatisiertes ML.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Beispielnotebooks
Sehen Sie sich die Notebooks zum Vorhersagebeispiel an. Dort finden Sie ausführliche Codebeispiele zu einer erweiterten Vorhersagekonfiguration, einschließlich:
- Feiertagserkennung und Erstellen zusätzlicher Merkmale (Featurization)
- Kreuzvalidierung mit rollierendem Ursprung (Rolling Origin Validation)
- Konfigurierbare Verzögerungen (Lags)
- Aggregierte Zeitfenstermerkmale (Rolling Window Features)
Nächste Schritte
- Erfahren Sie mehr darüber, Wie Sie ein automatisiertes ML-Modell an einem Online-Endpunkt bereitstellt.
- Informieren Sie sich über Interpretierbarkeit: Modellerklärungen beim automatisierten maschinellen Lernen (Vorschau).
- Erfahren Sie, wie automatisiertes ML Vorhersagemodelle erstellt.