Einrichten von AutoML für das Trainieren von Modellen für maschinelles Sehen mit Python (v1)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
Wichtig
Einige Azure CLI-Befehle in diesem Artikel verwenden die Erweiterung azure-cli-ml oder v1 für Azure Machine Learning. Der Support für die v1-Erweiterung endet am 30. September 2025. Sie können die v1-Erweiterung bis zu diesem Datum installieren und verwenden.
Es wird empfohlen, vor dem 30. September 2025 zur ml- oder v2-Erweiterung zu wechseln. Weitere Informationen zur v2-Erweiterung finden Sie unter Was sind die Azure Machine Learning CLI und das Python SDK v2?.
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel erfahren Sie, wie Sie Modelle für maschinelles Sehen mit Bilddaten mit automatisiertem ML im Python-SDK für Azure Machine Learning trainieren.
Automatisiertes ML unterstützt das Modelltraining für Aufgaben für maschinelles Sehen wie Bildklassifizierung, Objekterkennung und Instanzsegmentierung. Das Erstellen von AutoML-Modellen für Aufgaben des maschinellen Sehens wird derzeit über das Python-SDK für Azure Machine Learning unterstützt. Die resultierenden Versuchsausführungen, Modelle und Ergebnisse sind über die Benutzeroberfläche von Azure Machine Learning Studio zugänglich. Erfahren Sie mehr über automatisiertes ML für Aufgaben des maschinellen Sehens auf Bilddaten.
Hinweis
Aufgaben des automatisierten ML für maschinelles Sehen sind nur über das Python-SDK für Azure Machine Learning verfügbar.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen des Arbeitsbereichs finden Sie unter Schnellstart: So erstellen Sie Arbeitsbereichsressourcen, die Sie für die ersten Schritte mit Azure Machine Learning benötigen.
Installation des Azure Machine Learning Python SDK, zum Installieren des SDK können Sie wie folgt vorgehen:
Erstellen Sie eine Compute-Instanz, wodurch das SDK automatisch installiert und für ML-Workflows vorkonfiguriert wird. Weitere Informationen finden Sie unter Erstellen und Verwalten einer Azure Machine Learning-Compute-Instanz.
Installieren Sie das Paket
automlselbst. Es enthält die Standardinstallation des SDK.
Hinweis
Nur Python 3.7 und 3.8 sind mit der Unterstützung für automatisiertes maschinelles Lernen für Aufgaben des maschinellen Sehens kompatibel.
Auswählen des Aufgabentyps
Automatisiertes maschinelles Lernen für Bilder unterstützt die folgenden Aufgabentypen:
| Aufgabentyp | AutoMLImage-Konfigurationssyntax |
|---|---|
| Bildklassifizierung | ImageTask.IMAGE_CLASSIFICATION |
| Bildklassifizierung mit mehreren Beschriftungen | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| Bildobjekterkennung | ImageTask.IMAGE_OBJECT_DETECTION |
| Bildinstanzsegmentierung | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Dieser Aufgabentyp ist ein erforderlicher Parameter und wird mithilfe des task-Parameters in AutoMLImageConfig übergeben.
Zum Beispiel:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Trainings- und Überprüfungsdaten
Um Modelle für maschinelles Sehen zu erstellen, müssen Sie beschriftete Bilddaten als Eingabe für das Modelltraining in Form eines TabularDataset von Azure Machine Learning bereitstellen. Sie können entweder ein TabularDataset verwenden, das Sie aus einem Datenbeschriftungsprojekt exportiert haben, oder ein neues TabularDataset mit Ihren beschrifteten Trainingsdaten erstellen.
Wenn Ihre Trainingsdaten in einem anderen Format vorliegen (z. B. Pascal VOC oder COCO), können Sie die in den Beispielnotebooks enthaltenen Hilfsskripts anwenden, um die Daten in JSONL zu konvertieren. Erfahren Sie mehr darüber, wie Sie Daten für Aufgaben des maschinellen Sehens mit automatisiertem maschinellen Lernen vorbereiten.
Warnung
Die Erstellung von TabularDatasets aus Daten im JSONL-Format wird nur unterstützt, indem das SDK verwendet wird. Das Erstellen des Datasets über die Benutzeroberfläche wird derzeit nicht unterstützt. Ab sofort erkennt die Benutzeroberfläche den StreamInfo-Datentyp nicht, der für Bild-URLs im JSONL-Format verwendet wird.
Hinweis
Das Trainingsdataset muss über mindestens zehn Bilder verfügen, um eine AutoML-Ausführung übermitteln zu können.
JSONL-Schemabeispiele
Die Struktur von TabularDataset hängt von der Aufgabe ab. Bei den Aufgabentypen des maschinellen Sehens besteht sie aus den folgenden Feldern:
| Feld | BESCHREIBUNG |
|---|---|
image_url |
Enthält den Dateipfad als StreamInfo-Objekt |
image_details |
Die Informationen der Bildmetadaten bestehen aus Höhe, Breite und Format. Dieses Feld ist optional und daher möglicherweise nicht vorhanden. |
label |
Eine JSON-Darstellung der Bildbeschriftung basierend auf dem Aufgabentyp. |
Im Folgenden finden Sie eine JSONL-Beispieldatei für die Bildklassifizierung:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Der folgende Code ist ein Beispiel für eine JSONL-Datei zur Objekterkennung:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Nutzen von Daten
Sobald Ihre Daten im JSONL-Format vorliegen, können Sie mit dem folgenden Code ein TabularDataset erstellen:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Bei Aufgaben des maschinellen Sehens unterliegt die Größe der Trainings- oder Überprüfungsdaten keinerlei Beschränkungen durch das automatisierte maschinelle Lernen. Die maximale Größe des Datasets wird nur durch die Ebene hinter dem Dataset (d. h. den Blobspeicher) begrenzt. Es gibt keine Mindestanzahl von Bildern oder Bezeichnungen. Wir empfehlen jedoch, mit einem Minimum von 10-15 Stichproben pro Bezeichnung zu beginnen, um sicherzustellen, dass das Ausgabemodell ausreichend trainiert ist. Je höher die Gesamtzahl der Bezeichnungen/Klassen ist, desto mehr Stichproben benötigen Sie pro Bezeichnung.
Trainingsdaten sind erforderlich und werden mithilfe des training_data-Parameters übergeben. Sie können optional ein anderes TabularDataset als Überprüfungsdataset angeben, das Sie für Ihr Modell mit dem validation_data-Parameter der AutoMLImageConfig verwenden. Wenn kein Dataset für die Prüfung angegeben wird, werden standardmäßig 20 % der Trainingsdaten für die Prüfung verwendet, es sei denn, Sie übergeben ein validation_size-Argument mit einem anderen Wert.
Zum Beispiel:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Computeziel zum Ausführen des Experiments
Stellen Sie ein Computeziel für automatisiertes ML zur Durchführung des Modelltrainings bereit. Automatisierte ML-Modelle für Aufgaben des maschinellen Sehens erfordern GPU-SKUs und unterstützen NC- und ND-Familien. Für ein schnelleres Training wird die NCsv3-Serie (mit v100-GPUs) empfohlen. Ein Computeziel mit einer VM-SKU für mehrere GPUs nutzt mehrere GPUs, um das Training ebenfalls zu beschleunigen. Wenn Sie ein Computeziel mit mehreren Knoten einrichten, können Sie außerdem das Training des Modells durch Parallelität bei der Abstimmung der Hyperparameter für Ihr Modell beschleunigen.
Hinweis
Wenn Sie eine Compute-Instanz als Computeziel verwenden, stellen Sie sicher, dass nicht mehrere AutoML-Aufträge gleichzeitig ausgeführt werden. Vergewissern Sie sich auch, dass max_concurrent_iterations in Ihren Experimentressourcen auf 1 festgelegt ist.
Das Computeziel ist ein obligatorischer Parameter und wird mithilfe des compute_target-Parameters von AutoMLImageConfig übergeben. Zum Beispiel:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Konfigurieren von Modellalgorithmen und Hyperparametern
Mit der Unterstützung für Aufgaben des maschinellen Sehens können Sie den Modellalgorithmus steuern und Hyperparameter bereinigen. Diese Modellalgorithmen und Hyperparameter werden als Parameterraum für den Sweep übergeben.
Der Modellalgorithmus ist erforderlich und wird als model_name-Parameter übergeben. Sie können entweder eine einzelne model_name-Instanz angeben oder zwischen mehreren Instanzen auswählen.
Unterstützte Modellalgorithmen
In der folgenden Tabelle sind die unterstützten Modelle für jede Aufgabe des maschinellen Sehens zusammengefasst.
| Aufgabe | Modellalgorithmen | Syntax des Zeichenfolgenliteralsdefault_model* bezeichnet mit * |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Bezeichnungen) |
MobileNet: Einfache Modelle für mobile Anwendungen ResNet: Verbleibende Netzwerke ResNeSt: Netzwerke mit geteilter Aufmerksamkeit SE-ResNeXt50: Squeeze-and-Excitation-Netzwerke ViT: Vision-Transformer-Netzwerke |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (klein) vitb16r224* (Basis) vitl16r224 (groß) |
| Objekterkennung | YOLOv5: Einstufiges Objekterkennungsmodell Faster RCNN ResNet FPN: Zweistufige Objekterkennungsmodelle RetinaNet ResNet FPN: Klassenungleichgewicht mit Fokusverlust beheben Hinweis: YOLOv5-Modellgrößen finden Sie unter model_size-Hyperparameter. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Instanzsegmentierung | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Zusätzlich zur Steuerung des Modellalgorithmus können Sie auch Hyperparameter optimieren, die für das Modelltraining verwendet werden. Während viele der verfügbar gemachten Hyperparameter modellunabhängig sind, gibt es Instanzen, in denen Hyperparameter aufgaben- oder modellspezifisch sind. Hier erfahren Sie mehr über die verfügbaren Hyperparameter für diese Instanzen.
Datenerweiterung
Im Allgemeinen kann die Leistung von Deep-Learning-Modellen mit mehr Daten verbessert werden. Die Datenerweiterung ist ein praktisches Verfahren zur Vergrößerung des Datenumfangs und der Variabilität eines Datasets, das dazu beiträgt, eine Überanpassung zu verhindern und die Verallgemeinerungsfähigkeit des Modells auf unbekannte Daten zu verbessern. Automatisiertes ML wendet je nach Aufgabe des maschinellen Sehens verschiedene Verfahren zur Datenerweiterung an, bevor die Eingabebilder dem Modell zugeführt werden. Derzeit gibt es keine Hyperparameter zur Steuerung von Datenerweiterungen.
| Aufgabe | Betroffenes Dataset | Angewendete Verfahren zur Datenerweiterung |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Beschriftungen) | Weiterbildung Validierung und Test |
Zufällige Größenänderung und Zuschnitt, horizontales Spiegeln, Farbverschiebung (Helligkeit, Kontrast, Sättigung und Farbton), Normalisierung unter Verwendung des Mittelwerts und der Standardabweichung von ImageNet nach Kanälen Größenänderung, zentraler Zuschnitt, Normalisierung |
| Objekterkennung, Instanzsegmentierung | Weiterbildung Validierung und Test |
Zufälliger Zuschnitt um Begrenzungsrahmen, Erweiterung, horizontale Spiegelung, Normalisierung, Größenänderung Normalisierung, Größenänderung |
| Objekterkennung mit yolov5 | Weiterbildung Validierung und Test |
Mosaik, zufällige Affinität (Rotation, Übersetzung, Skalierung, Neigung), horizontale Spiegelung Größenänderung für Letterbox |
Konfigurieren der Experimenteinstellungen
Bevor Sie einen großen Sweep durchführen, um die optimalen Modelle und Hyperparameter zu finden, empfehlen wir Ihnen, die Standardwerte auszuprobieren, um eine erste Baseline zu erhalten. Als nächstes können Sie mehrere Hyperparameter für dasselbe Modell untersuchen, bevor Sie über mehrere Modelle und deren Parameter einen Sweep durchführen. Auf diese Weise können Sie einen iterativen Ansatz auswählen, denn bei mehreren Modellen und mehreren Hyperparametern für jedes Modell wächst der Suchraum exponentiell und Sie benötigen mehr Iterationen, um optimale Konfigurationen zu finden.
Wenn Sie die standardmäßigen Hyperparameterwerte für einen bestimmten Algorithmus (z. B. yolov5) verwenden möchten, können Sie die Konfiguration für Ihre AutoML-Bildausführungen wie folgt festlegen:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Sobald Sie ein Baselinemodell erstellt haben, möchten Sie vielleicht die Modellleistung optimieren, um einen Sweep über den Modellalgorithmus und den Hyperparameterraum durchzuführen. Sie können die folgende Beispielkonfiguration verwenden, um einen Sweep über die Hyperparameter für jeden Algorithmus durchzuführen und aus einer Reihe von Werten für learning_rate, optimizer, lr_scheduler usw. auszuwählen, um ein Modell mit der optimalen primären Metrik zu erstellen. Ohne Angabe von Hyperparameterwerten werden für den angegebenen Algorithmus Standardwerte verwendet.
Primary metric (Primäre Metrik)
Die primäre Metrik, die für die Modelloptimierung und die Abstimmung der Hyperparameter verwendet wird, hängt von der Art der Aufgabe ab. Die Verwendung anderer primärer Metrikwerte wird derzeit nicht unterstützt.
accuracyfür IMAGE_CLASSIFICATIONioufür IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionfür IMAGE_OBJECT_DETECTIONmean_average_precisionfür IMAGE_INSTANCE_SEGMENTATION
Experimentbudget
Sie können optional das maximale Zeitbudget für Ihr AutoML Vision-Experiment angeben, indem Sie experiment_timeout_hours verwenden – die Zeitspanne in Stunden, bevor das Experiment beendet wird. Ohne eine Angabe beträgt der Standardtimeout für Experimente sieben Tage (maximal 60 Tage).
Durchführen von Sweeps für Hyperparameter für Ihr Modell
Beim Training von Modellen für maschinelles Sehen hängt die Leistung des Modells stark von den gewählten Hyperparametern ab. Häufig möchten Sie vielleicht die Hyperparameter abstimmen, um eine optimale Leistung zu erzielen. Mit der Unterstützung für Aufgaben des maschinellen Sehens in automatisiertem ML können Sie für Hyperparameter einen Sweep durchführen, um die optimalen Einstellungen für Ihr Modell zu finden. Dieses Feature wendet Abstimmungsfunktionen für Hyperparameter in Azure Machine Learning an. Erfahren Sie, wie Sie Hyperparameter abstimmen.
Definieren des Suchbereichs für Parameter
Sie können die Modellalgorithmen und Hyperparameter definieren, die im Parameterraum durchsucht werden sollen.
- Unter Konfigurieren von Modellalgorithmen und Hyperparametern finden Sie die Liste der unterstützten Modellalgorithmen für jeden Aufgabentyp.
- Unter Hyperparameter für Aufgaben des maschinellen Sehens finden Sie die Hyperparameter für jeden Aufgabentyp des maschinellen Sehens.
- Weitere Informationen finden Sie unter Details zu unterstützten Verteilungen für diskrete und kontinuierliche Hyperparameter.
Samplingmethoden für den Sweep
Beim Sweepen von Hyperparametern müssen Sie die Samplingmethode angeben, die für das Sweepen über den definierten Parameterraum verwendet werden soll. Derzeit werden die folgenden Samplingmethoden mit dem hyperparameter_sampling-Parameter unterstützt:
Hinweis
Derzeit unterstützen nur das zufällige und das Rastersampling bedingte Hyperparameterräume.
Richtlinien zum vorzeitigen Beenden
Sie können Ausführungen mit schlechter Leistung mit einer Richtlinie für vorzeitige Beendigung automatisch beenden. Eine vorzeitige Beendigung verbessert die Effizienz der Berechnungen und spart Computeressourcen, die sonst für weniger vielversprechende Konfigurationen verwendet worden wären. Automatisiertes ML für Bilder unterstützt die folgenden Richtlinien zur vorzeitigen Beendigung mithilfe des early_termination_policy-Parameters. Wenn keine Richtlinie für die Beendigung angegeben wird, werden alle Konfigurationen bis zum Ende ausgeführt.
Erfahren Sie mehr darüber, wie Sie die Richtlinie für die vorzeitige Beendigung Ihres Hyperparameter-Sweeps konfigurieren.
Ressourcen für den Sweep
Sie können die für Ihren Hyperparameter-Sweep verwendeten Ressourcen steuern, indem Sie iterations und max_concurrent_iterations für den Sweep angeben.
| Parameter | Detail |
|---|---|
iterations |
Erforderlicher Parameter für die maximale Anzahl der Konfigurationen, für die der Sweep durchgeführt wird. Muss eine ganze Zahl zwischen 1 und 1000 sein. Wenn Sie nur die Standardhyperparameter für einen bestimmten Modellalgorithmus untersuchen, legen Sie diesen Parameter auf 1 fest. |
max_concurrent_iterations |
Maximale Anzahl von Ausführungen, die gleichzeitig ausgeführt werden können. Wenn dieser Wert nicht angegeben wird, werden alle Ausführungen parallel gestartet. Wenn dieser Wert angegeben wird, muss es sich dabei um eine ganze Zahl zwischen 1 und 100 handeln. HINWEIS: Die Anzahl der gleichzeitigen Ausführungen wird durch die im angegebenen Computeziel verfügbaren Ressourcen beschränkt. Stellen Sie sicher, dass das Computeziel die verfügbaren Ressourcen für die gewünschte Parallelität aufweist. |
Hinweis
Ein vollständiges Beispiel für die Sweep-Konfiguration finden Sie in diesem Tutorial.
Argumente
Sie können feste Einstellungen oder Parameter, die sich während der Durchführung des Sweeps für den Parameterraum nicht ändern, als Argumente übergeben. Argumente werden in Name-Wert-Paaren übergeben, wobei dem Namen ein Doppelstrich vorangestellt werden muss.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Inkrementelles Training (optional)
Nachdem der Trainingslauf durchgeführt wurde, haben Sie die Möglichkeit, das Modell weiter zu trainieren, indem Sie den Prüfpunkt des trainierten Modells laden. Sie können entweder das gleiche Dataset oder ein anderes Dataset für das inkrementelle Training verwenden.
Es stehen zwei Optionen für das inkrementelle Training zur Verfügung. Sie haben folgende Möglichkeiten:
- Übergeben der Ausführungs-ID, aus der Sie den Prüfpunkt laden möchten
- Übergeben der Prüfpunkte über ein FileDataset
Übergeben des Prüfpunkts über die Ausführungs-ID
Um die Ausführungs-ID aus dem gewünschten Modell zu suchen, können Sie den folgenden Code verwenden.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Um einen Prüfpunkt über die Ausführungs-ID zu übergeben, müssen Sie den checkpoint_run_id-Parameter verwenden.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Übergeben des Prüfpunkts über FileDataset
Um einen Prüfpunkt über ein FileDataset zu übergeben, müssen Sie die Parameter checkpoint_dataset_id und checkpoint_filename verwenden.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Übermitteln der Ausführung
Wenn das AutoMLImageConfig-Objekt bereit ist, können Sie das Experiment übermitteln.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Ausgaben und Auswertungsmetriken
Die Trainingsausführungen für das automatisierte ML generieren Ausgabemodelldateien, Bewertungsmetriken, Protokolle und Bereitstellungsartefakte wie die Bewertungsdatei und die Umgebungsdatei, die auf der Registerkarte für Ausgaben, Protokolle und Metriken der untergeordneten Ausführungen angezeigt werden können.
Tipp
Prüfen Sie im Abschnitt Anzeigen von Auftragsergebnissen, wie Sie zu den Auftragsergebnissen navigieren können.
Definitionen und Beispiele für die Leistungsdiagramme und Metriken, die für jede Ausführung bereitgestellt werden, finden Sie unter Auswerten der Ergebnisse von Experimenten des automatisierten maschinellen Lernens.
Registrieren und Bereitstellen von Modellen
Nach Abschluss der Ausführung können Sie das Modell registrieren, das aus der besten Ausführung erstellt wurde (Konfiguration, die zur besten primären Metrik führte).
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Nachdem Sie das Modell registriert haben, das Sie verwenden möchten, können Sie es als Webdienst in Azure Container Instances (ACI) oder Azure Kubernetes Service (AKS) bereitstellen. ACI eignet sich perfekt zum Testen von Bereitstellungen, während AKS besser zur umfangreichen Nutzung in der Produktion geeignet ist.
In diesem Beispiel wird das Modell als Webdienst in AKS bereitgestellt. Erstellen Sie zum Bereitstellen in AKS zunächst einen AKS-Computecluster, oder verwenden Sie einen vorhandenen AKS-Cluster. Sie können entweder GPU- oder CPU-VM-SKUs für Ihren Bereitstellungscluster verwenden.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Als nächstes können Sie die Rückschlusskonfiguration definieren, um die Einrichtung des Webdiensts zu beschreiben, der Ihr Modell enthält. In Ihrer Rückschlusskonfiguration können Sie das Bewertungsskript und die Umgebung aus der Trainingsausführung verwenden.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Anschließend können Sie das Modell als AKS-Webdienst bereitstellen.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Alternativ können Sie das Modell über die Azure Machine Learning Studio-Benutzeroberfläche bereitstellen. Navigieren Sie auf der Registerkarte Modelle der automatisierten ML-Ausführung zu dem Modell, das Sie bereitstellen möchten, und wählen Sie die Option Bereitstellen aus.
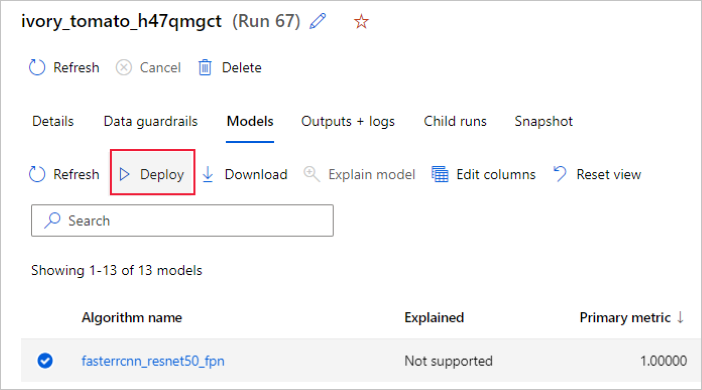
Sie können den Namen des Modellbereitstellungsendpunkts und den Rückschlusscluster für Ihre Modellimplementierung im Bereich Modell bereitstellen konfigurieren.
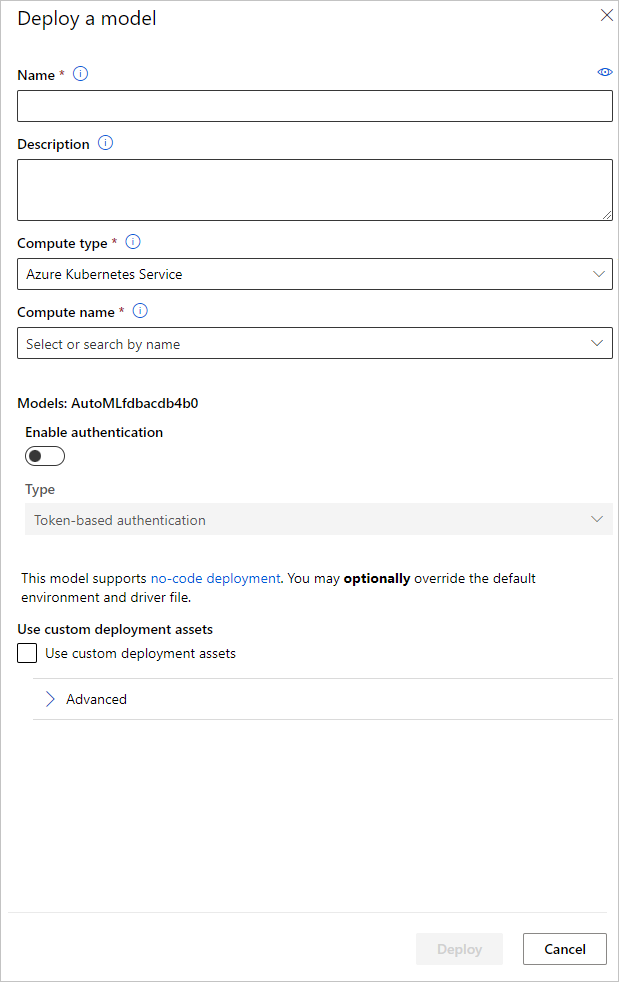
Aktualisieren der Rückschlusskonfiguration
Im vorangegangenen Schritt haben wir die Bewertungsdatei outputs/scoring_file_v_1_0_0.py des besten Modells in eine lokale score.py-Datei heruntergeladen und sie zum Erstellen eines InferenceConfig-Objekts verwendet. Dieses Skript kann bei Bedarf geändert werden, um die modellspezifischen Einstellungen für den Rückschluss zu ändern, nachdem es heruntergeladen wurde und bevor die InferenceConfig erstellt wurde. Dies ist beispielsweise der Codeabschnitt, der das Modell in der Bewertungsdatei initialisiert:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Jede der Aufgaben (und einige Modelle) verfügt über einen Satz von Parametern im model_settings-Wörterbuch. Standardmäßig verwenden wir dieselben Werte für die Parameter, die während des Trainings und der Validierung verwendet wurden. Abhängig vom Verhalten, das beim Verwenden des Modells für Rückschlüsse benötigt wird, können wir diese Parameter ändern. Im Folgenden finden Sie eine Liste der Parameter für jeden Aufgabentyp und jedes Modell.
| Aufgabe | Parametername | Standard |
|---|---|---|
| Bildklassifizierung (mehrere Klassen und mehrere Beschriftungen) | valid_resize_sizevalid_crop_size |
256 224 |
| Objekterkennung | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0.5 100 |
Objekterkennung mit yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 mittel 0,1 0.5 |
| Instanzsegmentierung | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0.5 100 0.5 100 False JPG |
Eine ausführliche Beschreibung zu aufgabenspezifischen Hyperparametern finden Sie unter Hyperparameter für Aufgaben im Bereich maschinelles Sehen beim automatisierten maschinellen Lernen.
Wenn Sie Kacheln verwenden und das Kachelverhalten steuern möchten, sind die folgenden Parameter verfügbar: tile_grid_size, tile_overlap_ratio und tile_predictions_nms_thresh. Weitere Informationen zu diesen Parametern finden Sie unter Trainieren eines Erkennungsmodells für kleine Objekte mit AutoML.
Beispielnotebooks
Überprüfen Sie detaillierte Codebeispiele und Anwendungsfälle im GitHub-Notebook-Repository für Beispiele zum automatisierten maschinellen Lernen. Überprüfen Sie die Ordner mit dem Präfix „image-“ auf spezifische Beispiele für die Erstellung von Modellen für maschinelles Sehen.