Ein Textbeschriftungsprojekt einrichten und Beschriftungen exportieren
Erfahren Sie in Azure Machine Learning, wie Sie Datenbeschriftungsprojekte erstellen und ausführen, um Textdaten zu beschriften. Geben Sie entweder eine einzelne oder mehrere Beschriftungen an, die auf jedes Textelement angewendet werden sollen.
Sie können auch das Datenbeschriftungstool in Azure Machine Learning verwenden, um ein Bildbeschriftungsprojekt zu erstellen.
Funktionen zur Textbeschriftung
Die Azure Machine Learning-Datenbeschriftung ist ein Tool zum Erstellen, Verwalten und Überwachen von Datenbeschriftungsprojekten. Verwenden Sie es zu folgenden Zwecken:
- Koordinieren von Daten, Beschriftungen und Teammitgliedern, um Beschriftungsaufgaben effizient zu verwalten
- Nachverfolgen des Fortschritts und Verwalten der Warteschlange mit unvollständigen Beschriftungsaufgaben
- Starten und Beenden des Projekts und Steuern des Beschriftungsfortschritts
- Überprüfen und Exportieren der beschrifteten Daten als Azure Machine Learning-Dataset
Wichtig
Die Textdaten, mit denen Sie im Azure Machine Learning-Datenbeschriftungstool arbeiten, müssen in einem Azure Blob Storage-Datenspeicher verfügbar sein. Wenn Sie keinen vorhandenen Datenspeicher haben, können Sie Ihre Datendateien in einen neuen Datenspeicher hochladen, wenn Sie ein neues Projekt erstellen.
Diese Datenformate sind für Textdaten verfügbar:
- .txt: Jede Datei stellt ein Element dar, das beschriftet werden soll.
- .csv oder .tsv: Jede Zeile stellt ein Element dar, das dem Beschriftungsprogramm angezeigt wird. Sie entscheiden, welche Spalten dem Beschriftungsprogramm angezeigt werden können, wenn die Zeile beschriftet wird.
Voraussetzungen
Sie verwenden diese Elemente, um die Textbeschriftung in Azure Machine Learning einzurichten:
- Die zu beschriftenden Daten (entweder in lokalen Dateien oder in Azure Blob Storage).
- Der Satz von Beschriftungen, die Sie anwenden möchten.
- Die Anweisungen für die Beschriftung.
- Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen finden Sie unter Erstellen eines Azure Machine Learning-Arbeitsbereichs.
Erstellen Sie ein Textbeschriftungsprojekt
Beschriftungsprojekte werden in Azure Machine Learning verwaltet. Verwenden Sie die Seite Datenbeschriftung in Machine Learning, um Ihre Projekte zu verwalten.
Wenn sich Ihre Daten bereits in Azure Blob Storage befinden, sollten Sie sicherstellen, dass dieser als Datenspeicher verfügbar ist, bevor Sie das Beschriftungsprojekt erstellen.
Zum Erstellen eines Projekts wählen Sie Projekt hinzufügen aus.
Geben Sie unter Projektname einen Namen für das Projekt ein.
Sie können den Projektnamen nicht wiederverwenden, auch wenn Sie das Projekt löschen.
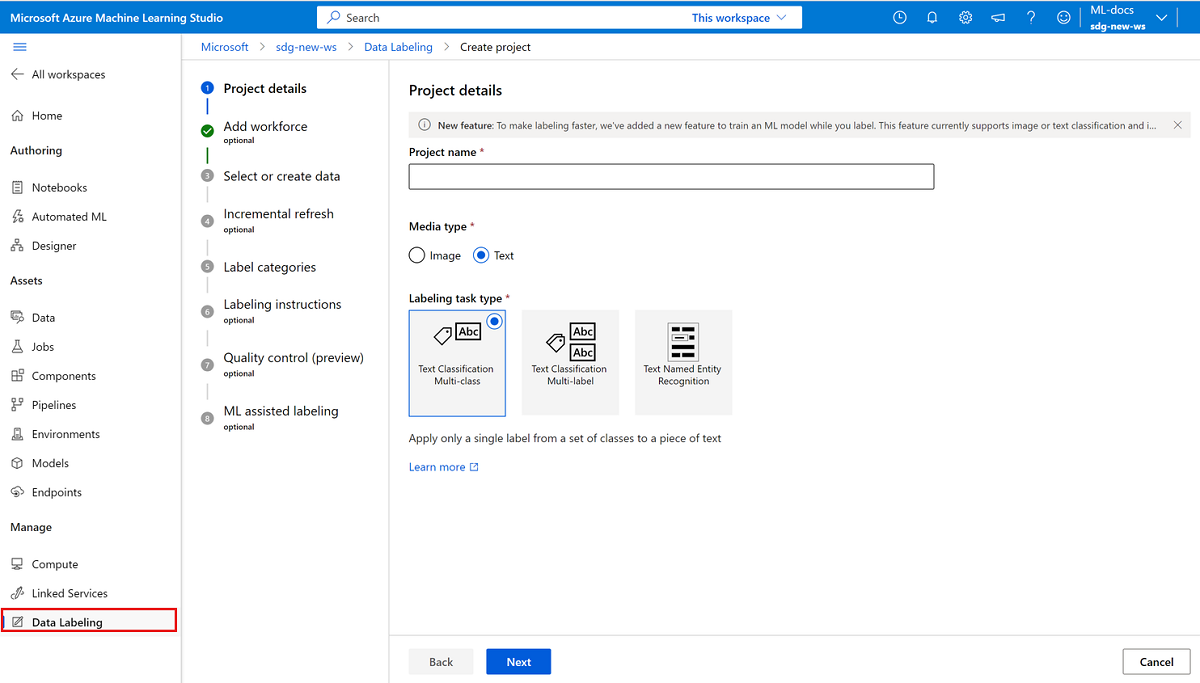
Um ein Textbeschriftungsprojekt zu erstellen, wählen Sie unter Medientypdie Option Text aus.
Wählen Sie unter Beschriftungsaufgabentyp eine Option für Ihr Szenario aus:
- Um nur eine einzelne Beschriftung auf jeden Textabschnitt aus einem Satz von Beschriftungen anzuwenden, wählen Sie Mehrere Klassen für Textklassifizierung aus.
- Um eine oder mehrere Beschriftungen auf jeden Textabschnitt aus einem Satz von Beschriftungen anzuwenden, wählen Sie Mehrfachbeschriftung zur Textklassifizierung aus.
- Um Beschriftungen auf einzelne Textwörter oder mehrere Textwörter in jedem Eintrag anzuwenden, wählen Sie Erkennung benannter Entitäten in Text aus.
Klicken Sie auf Weiter, um fortzufahren.
Arbeitskräfte hinzufügen (optional)
Wählen Sie Anbieterbezeichnungsunternehmen von Azure Marketplace verwenden nur dann aus, wenn Sie ein Datenbeschriftungsunternehmen von Azure Marketplace beauftragt haben. Wählen Sie dann den Anbieter aus. Wenn Ihr Anbieter nicht in der Liste angezeigt wird, löschen Sie diese Option.
Stellen Sie sicher, dass Sie sich zuerst an den Anbieter wenden und einen Vertrag unterzeichnen. Weitere Informationen finden Sie unter Arbeiten mit einem Datenbeschriftungsanbieterunternehmen (Vorschau).
Klicken Sie auf Weiter, um fortzufahren.
Auswählen oder Erstellen eines Datasets
Wenn Sie bereits ein Dataset mit Ihren Daten erstellt haben, wählen Sie dieses aus der Dropdownliste Vorhandenes Dataset auswählen aus. Sie können auch Dataset erstellen auswählen, um einen vorhandenen Azure-Datenspeicher auszuwählen oder lokale Dateien hochzuladen.
Hinweis
Ein Projekt kann nicht mehr als 500 000 Dateien enthalten. Wenn Ihr Dataset diese Dateianzahl überschreitet, werden nur die ersten 500 000 Dateien geladen.
Erstellen eines Datasets aus einem Azure-Datenspeicher
In vielen Fällen können Sie lokale Dateien hochladen. Azure Storage-Explorer bietet jedoch eine schnellere und stabilere Methode zum Übertragen großer Datenmengen. Es wird empfohlen, Storage-Explorer als Standardmethode zum Verschieben von Dateien zu verwenden.
So erstellen Sie ein Dataset aus Daten, die Sie bereits in einem Blob Storage gespeichert haben:
- Klicken Sie auf Erstellen.
- Geben Sie unter Name einen Namen für Ihr Dataset ein. Geben Sie optional eine Beschreibung ein.
- Wählen Sie den Datensatztyp:
- Wählen Sie Tabellarisch aus, wenn Sie eine .csv- oder .tsv-Datei verwenden, bei der jede Zeile eine Antwort enthält.
- Wählen Sie Datei aus, wenn Sie für jede Antwort separate .txt-Dateien verwenden.
- Wählen Sie Weiter aus.
- Wählen Sie Aus Azure-Speicher und dann Weiter aus.
- Wählen Sie den Datenspeicher und dann Weiter aus.
- Wenn sich Ihre Daten in einem Unterordner innerhalb von Blob Storage befinden, wählen Sie Durchsuchen aus, um den Pfad auszuwählen.
- Fügen Sie
/**an den Pfad an, um alle Dateien in den Unterordnern des ausgewählten Pfads einzubeziehen. - Fügen Sie
**/*.*an den Pfad an, um alle Daten im aktuellen Container und seinen Unterordnern einzubeziehen.
- Fügen Sie
- Klicken Sie auf Erstellen.
- Wählen Sie die von Ihnen erstellte Datenressource aus.
Erstellen eines Datasets aus hochgeladenen Daten
Direktes Hochladen Ihrer Daten:
- Klicken Sie auf Erstellen.
- Geben Sie unter Name einen Namen für Ihr Dataset ein. Geben Sie optional eine Beschreibung ein.
- Wählen Sie den Datensatztyp:
- Wählen Sie Tabellarisch aus, wenn Sie eine .csv- oder .tsv-Datei verwenden, bei der jede Zeile eine Antwort enthält.
- Wählen Sie Datei aus, wenn Sie für jede Antwort separate .txt-Dateien verwenden.
- Wählen Sie Weiter aus.
- Wählen Sie Aus lokalen Dateien und dann Weiter aus.
- (Optional) Wählen Sie einen Datenspeicher aus. Standardmäßig erfolgt der Upload in den Standardblobspeicher (workspaceblobstore) Ihres Machine Learning-Arbeitsbereichs.
- Wählen Sie Weiter aus.
- Wählen Sie Hochladen>Dateien hochladen oder Hochladen>Ordner hochladen aus, um die lokalen Dateien oder Ordner auszuwählen, die hochgeladen werden sollen.
- Suchen Sie Ihre Dateien oder Ordner im Browserfenster, und wählen Sie dann Öffnen aus.
- Wählen Sie weiterhin Hochladen aus, bis Sie alle Dateien und Ordner angegeben haben.
- Aktivieren Sie optional das Kontrollkästchen Überschreiben, wenn bereits vorhanden. Überprüfen Sie die Liste der Dateien und Ordner.
- Wählen Sie Weiter aus.
- Bestätigen Sie die Informationen. Wählen Sie Zurück, um Einstellungen zu ändern, oder Erstellen, um das Dataset zu erstellen.
- Wählen Sie abschließend die von Ihnen erstellte Datenressource aus.
Konfigurieren inkrementeller Aktualisierungen
Wenn Sie dem Dataset neue Datendateien hinzufügen möchten, verwenden Sie die inkrementelle Aktualisierung, um Ihrem Projekt die Dateien hinzuzufügen.
Wenn die Option Inkrementelle Aktualisierung in regelmäßigen Abständen aktivieren festgelegt ist, wird das Dataset auf der Grundlage der Vervollständigungsrate der Beschriftung regelmäßig auf neue Dateien überprüft, die einem Projekt hinzugefügt werden sollen. Die Überprüfung auf neue Daten wird beendet, wenn das Projekt die Obergrenze von 500.000 Dateien erreicht.
Wählen Sie das Kontrollkästchen Inkrementelle Aktualisierung in regelmäßigen Abständen aktivieren aus, wenn das Projekt den Datenspeicher kontinuierlich auf neue Daten überwachen soll.
Deaktivieren Sie diese Option, wenn neue Dateien im Datenspeicher dem Projekt nicht automatisch hinzugefügt werden sollen.
Wichtig
Wenn die inkrementelle Aktualisierung aktiviert ist, erstellen Sie keine neue Version für das Dataset, das Sie aktualisieren möchten. Andernfalls werden die Aktualisierungen nicht angezeigt, da das Datenbeschriftungsprojekt an die ursprüngliche Version angeheftet ist. Verwenden Sie stattdessen Azure Storage-Explorer, um Ihre Daten im entsprechenden Ordner in Blob Storage zu ändern.
Entfernen Sie außerdem keine Daten. Das Entfernen von Daten aus dem Dataset, das ihr Projekt verwendet, führt zu einem Fehler im Projekt.
Nachdem das Projekt erstellt wurde, verwenden Sie die Registerkarte Details, um die inkrementelle Aktualisierung zu ändern, den Zeitstempel für die letzte Aktualisierung anzuzeigen und eine sofortige Aktualisierung der Daten anzufordern.
Hinweis
Projekte, die tabellarische Dataseteingabe (.csv oder .tsv) verwenden, können die inkrementelle Aktualisierung verwenden. Die inkrementelle Aktualisierung fügt jedoch nur neue tabellarische Dateien hinzu. Die Aktualisierung erkennt keine Änderungen an vorhandenen tabellarischen Dateien.
Angeben von Bezeichnungskategorien
Auf der Seite Bezeichnungskategorien geben Sie den Satz von Klassen zum Kategorisieren Ihrer Daten an.
Die Genauigkeit und Geschwindigkeit Ihrer Bezeichnungsersteller wird durch ihre Möglichkeit der Auswahl zwischen den Klassen beeinflusst. Beispiel: Anstatt Gattung und Art von Pflanzen oder Tieren vollständig anzugeben, wird empfohlen, einen Feldcode zu verwenden oder die Gattung abzukürzen.
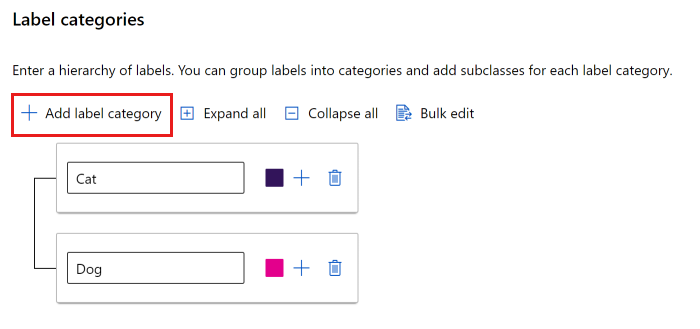
Sie können entweder eine flache Liste verwenden oder Gruppen von Bezeichnungen erstellen.
Um eine flache Liste zu erstellen, wählen Sie Bezeichnungskategorie hinzufügen aus, um die einzelnen Bezeichnungen zu erstellen.
Um Bezeichnungen in verschiedenen Gruppen zu erstellen, wählen Sie Bezeichnungskategorie hinzufügen aus, um die Bezeichnungen der obersten Ebene zu erstellen. Wählen Sie dann unter jeder obersten Ebene das Pluszeichen (+) aus, um die nächste Bezeichnungsebene für diese Kategorie zu erstellen. Sie können bis zu sechs Ebenen für jede Gruppierung erstellen.
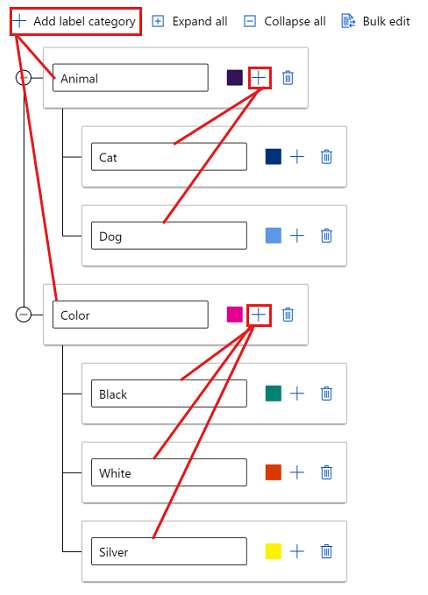
Sie können Bezeichnungen während des Taggingprozesses auf jeder Ebene auswählen. Beispielsweise sind die Bezeichnungen Animal, Animal/Cat, Animal/Dog, Color, Color/Black, Color/Whiteund Color/Silver alle verfügbaren Optionen für eine Bezeichnung. In einem Projekt mit mehreren Bezeichnungen muss nicht von jeder Kategorie eine ausgewählt werden. Wenn dies Ihre Absicht ist, nehmen Sie diese Informationen in Ihre Anweisungen auf.
Beschreiben Sie die Aufgabe der Textbeschriftung
Es ist wichtig, die Beschriftungsaufgabe genau zu erläutern. Auf der Seite Beschriftungsanweisungen können Sie einen Link zu einer externen Website mit Beschriftungsanweisungen hinzufügen, oder Sie können Anweisungen im Bearbeitungsfeld auf der Seite bereitstellen. Stellen Sie Anweisungen bereit, die aufgabenorientiert und für die Zielgruppe geeignet sind. Stellen Sie sich die folgenden Fragen:
- Welche Bezeichnungen sehen die Beschriftungsersteller, und wie treffen sie ihre Auswahl? Gibt es einen Referenztext, auf den man sich beziehen kann?
- Was sollen sie tun, wenn keine Beschriftung geeignet erscheint?
- Was sollen sie tun, wenn mehrere Beschriftungen geeignet erscheinen?
- Welchen Konfidenzschwellenwert sollen sie einer Beschriftung zuweisen? Möchten Sie die beste Schätzung des Beschriftungserstellers, wenn er sich nicht sicher ist?
- Was sollen sie tun, wenn interessante Objekte teilweise verdeckt sind oder sich überlappen?
- Was sollen sie tun, wenn ein interessantes Objekt am Bildrand abgeschnitten ist?
- Was sollen sie tun, wenn sie glauben, dass sie einen Fehler gemacht haben, nachdem sie eine Bezeichnung eingereicht haben?
- Wie sollten sie vorgehen, wenn sie Probleme mit der Bildqualität entdecken, einschließlich schlechte Beleuchtungsbedingungen, Reflexionen, Fokusverlust, unerwünschte Hintergründe, ungewöhnliche Kamerawinkel und weitere?
- Was sollten sie tun, wenn mehrere Prüfer unterschiedliche Meinungen zum Anwenden einer Bezeichnung haben?
Hinweis
Beschriftungsersteller können die ersten neun Bezeichnungen mithilfe der Nummerntasten 1 bis 9 auswählen.
Qualitätslenkung (Vorschau)
Um genauere Bezeichnungen zu erhalten, verwenden Sie die Seite Qualitätslenkung, um jedes Element an mehrere Bezeichnungsersteller zu senden.
Wichtig
Die Konsensbezeichnung ist derzeit als öffentliche Vorschauversion verfügbar.
Die Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Wählen Sie Aktivieren der Konsensbeschriftung (Vorschau) aus, damit jedes Element an mehrere Beschriftungsersteller gesendet wird. Legen Sie dann die Werte für Mindestanzahl von Beschriftungsersteller und Höchstzahl von Beschriftungsersteller fest, um anzugeben, wie viele Beschriftungsersteller verwendet werden sollen. Stellen Sie sicher, dass die Höchstzahl von Beschriftungserstellern verfügbar ist. Sie können diese Einstellungen nach dem Start des Projekts nicht mehr ändern.
Wenn bei der Mindestanzahl von Bezeichnungserstellern ein Konsens erzielt wird, wird das Element bezeichnet. Wenn kein Konsens erreicht wird, wird das Element an weitere Beschriftungsersteller gesendet. Wenn kein Konsens besteht, nachdem das Element an die Höchstzahl von Beschriftungserstellern gesendet worden ist, ist sein Status Review erforderlich, und der Projektbesitzer ist für die Bezeichnung des Elements verantwortlich.
Verwenden der ML-gestützten Datenbeschriftung
Auf der Seite Durch ML unterstützte Beschriftung können Sie automatische Machine Learning-Modelle auslösen, um Beschriftungsaufgaben zu beschleunigen. Die ML-unterstützte (Machine Learning) Beschriftung kann sowohl Datei- (.,txt) als auch tabellarische (.csv) Textdateneingaben verarbeiten.
So verwenden Sie die ML-gestützte Beschriftung:
- Wählen Sie Enable ML assisted labeling (ML-gestützte Beschriftung aktivieren) aus.
- Wählen Sie Datasetsprache für das Projekt aus. In dieser Liste sind alle Sprachen aufgeführt, die von der TextDNNLanguages-Klasse unterstützt werden.
- Geben Sie ein zu verwendendes Computeziel an. Wenn Sie über kein Computeziel in Ihrem Arbeitsbereich verfügen, wird ein Computecluster erstellt, und dieser Computecluster wird Ihrem Arbeitsbereich hinzugefügt. Der Cluster wird mit einem Minimum von null Knoten erstellt, d. h. er kostet nichts, wenn er nicht verwendet wird.
Weitere Informationen zu ML-unterstützten Beschriftungen
Zu Beginn Ihres Beschriftungsprojekts werden die Elemente in eine zufällige Reihenfolge gebracht, um potenzielle Verzerrungen zu verringern. Das trainierte Modell spiegelt jedoch alle im Dataset vorhandenen Trends wider. Wenn also beispielsweise 80 Prozent der Elemente aus einer einzelnen Klasse stammen, landen ungefähr 80 Prozent der Daten, die zum Trainieren des Modells verwendet werden, in dieser Klasse.
Zum Trainieren des DNN-Textmodells, das von der ML-unterstützten Beschriftung verwendet wird, wird der Eingabetext pro Trainingsbeispiel auf ungefähr die ersten 128 Wörter im Dokument beschränkt. Bei tabellarischen Eingaben werden alle Textspalten zuerst verkettet, bevor dieser Grenzwert verwendet wird. Diese praktische Grenze ermöglicht es, das Modelltraining in einem angemessenen Zeitraum abzuschließen. Der tatsächliche Text in einem Dokument (für Dateieingaben) oder einer Gruppe von Textspalten (für tabellarische Eingaben) kann 128 Wörter überschreiten. Der Grenzwert bezieht sich nur auf das, was das Modell intern während des Trainings verwendet.
Die genaue Anzahl der bezeichneten Elemente, die zum Starten der unterstützten Beschriftung erforderlich sind, ist nicht festgelegt. Dieser Wert kann zwischen Beschriftungsprojekten stark variieren. Die Varianz hängt von vielen Faktoren ab, einschließlich der Anzahl der Beschriftungsklassen und der Beschriftungsverteilung.
Wenn Sie die Konsensbeschriftung verwenden, wird sie für das Training verwendet.
Da die abschließenden Bezeichnungen weiterhin von den Eingaben des Beschriftungserstellers abhängig sind, wird diese Technologie manchmal auch als Mensch in der Mitte-Beschriftung bezeichnet.
Hinweis
Die ML-unterstützten Datenbeschriftung unterstützt keine Standardspeicherkonten, die hinter einem virtuellen Netzwerk gesichert sind. Sie müssen ein nicht standardmäßiges Speicherkonto für die ML-unterstützte Datenbeschriftung verwenden. Das nicht standardmäßige Speicherkonto kann hinter dem virtuellen Netzwerk gesichert werden.
Vorbeschriftung
Nachdem genügend Beschriftungen zum Training übermittelt wurden, wird das trainierte Modell zur Vorhersage von Tags verwendet. Dem Beschriftungsersteller werden nun Seiten angezeigt, auf denen bereits vorhergesagte Beschriftungen für die einzelnen Elemente vorhanden sind. Die Aufgabe umfasst dann die Überprüfung dieser Vorhersagen und die Korrektur aller falsch beschrifteten Elemente vor der Seitenübermittlung.
Nachdem Sie das Machine Learning-Modell mit Ihren manuell beschrifteten Daten trainiert haben, wird es anhand eines Testsatzes manuell beschrifteter Elemente ausgewertet. Die Auswertung hilft dabei, die Genauigkeit des Modells bei unterschiedlichen Konfidenzschwellenwerten zu bestimmen. Dieser Auswertungsprozess legt einen Konfidenzschwellenwert fest, über dem das Modell genau genug ist, um Vorabbezeichnungen anzuzeigen. Anschließend wird das Modell anhand von nicht beschrifteten Daten ausgewertet. Elemente, die über Vorhersagen verfügen, die sicherer als der Schwellenwert sind, werden für die Vorbeschriftung verwendet.
Initialisieren Sie das Textbeschriftungsprojekt
Nach dem Initialisieren das Beschriftungsprojekts sind einige Aspekte des Projekts unveränderlich. Sie können den Aufgabentyp oder das Dataset nicht ändern. Beschriftungen sowie die URL für die Aufgabenbeschreibung können dagegen geändert werden. Überprüfen Sie die Einstellungen sorgfältig, bevor Sie das Projekt erstellen. Nachdem Sie das Projekt übermittelt haben, kehren Sie zur Übersichtsseite für die Datenbeschriftung zurück, auf der das Projekt als Wird initialisiert angezeigt wird.
Hinweis
Die Übersichtsseite wird möglicherweise nicht automatisch aktualisiert. Aktualisieren Sie die Seite nach einer Pause manuell, um den Status des Projekts als Erstellt anzuzeigen.
Problembehandlung
Wenn Sie Probleme beim Erstellen eines Projekts oder beim Zugreifen auf Daten haben, finden Sie weitere Informationen unter Problembehandlung bei der Datenbeschriftung.