Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
Dieser Artikel enthält Informationen zur Verwendung des Azure Machine Learning SDK v1. SDK v1 ist ab dem 31. März 2025 veraltet. Der Support für sie endet am 30. Juni 2026. Sie können SDK v1 bis zu diesem Datum installieren und verwenden. Ihre vorhandenen Workflows mit SDK v1 funktionieren weiterhin nach dem Enddatum des Supports. Sie können jedoch Sicherheitsrisiken oder Breaking Changes im Falle von Architekturänderungen im Produkt ausgesetzt sein.
Es wird empfohlen, vor dem 30. Juni 2026 zum SDK v2 zu wechseln. Weitere Informationen zu SDK v2 finden Sie unter Was ist Azure Machine Learning CLI und Python SDK v2? und die SDK v2-Referenz.
Wichtig
In diesem Artikel wird erläutert, wie Sie die Azure Machine Learning CLI (v1) und das Azure Machine Learning SDK für Python (v1) verwenden, um ein Modell bereitzustellen. Weitere Informationen zum empfohlenen Ansatz für v2 finden Sie unter Bereitstellen und Bewertung eines Machine Learning-Modells mithilfe eines Onlineendpunkts.
Erfahren Sie, wie Sie ein Modell mit Azure Machine Learning als Webdienst in Azure Kubernetes Service (AKS) bereitstellen. AKS eignet sich gut für umfangreiche Produktionsbereitstellungen. Verwenden Sie AKS, wenn Sie eine oder mehrere der folgenden Funktionen benötigen:
- Schnelle Antwortzeiten
- Autoskalierung des bereitgestellten Diensts
- Protokollierung
- Modelldatensammlung
- Authentifizierung
- TLS-Terminierung
- Optionen für die Hardwarebeschleunigung, beispielsweise GPU und FPGA (Field Programmable Gate Arrays)
Die Bereitstellung in AKS erfolgt in einem AKS-Cluster, der mit Ihrem Arbeitsbereich verbunden ist. Weitere Informationen zum Verbinden eines AKS-Clusters mit Ihrem Arbeitsbereich finden Sie unter Erstellen und Anfügen eines Azure Kubernetes Service-Clusters.
Wichtig
Es wird empfohlen, Debugvorgänge vor der Bereitstellung im Webdienst lokal durchzuführen. Weitere Informationen finden Sie unter Problembehandlung bei einer lokalen Modellimplementierung.
Hinweis
Azure Machine Learning-Endpunkte (v2) bieten eine verbesserte, einfachere Bereitstellungserfahrung. Endpunkte unterstützen Szenarien mit Echtzeit- und Batchrückschluss. Endpunkte verfügen über eine einheitliche Oberfläche zum übergreifenden Aufrufen und Verwalten von Modellimplementierungen für alle Computetypen. Siehe Was sind Azure Machine Learning-Endpunkte?.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen finden Sie unter Erstellen eines Azure Machine Learning-Arbeitsbereichs.
Ein Machine Learning-Modell, das in Ihrem Arbeitsbereich registriert ist. Wenn Sie kein registriertes Modell besitzen, lesen Sie Bereitstellen von Machine Learning-Modellen in Azure.
Die Azure CLI-Erweiterung (v1) für Machine Learning Service, das Azure Machine Learning Python SDK oder die Visual Studio Code-Erweiterung für Azure Machine Learning.
Wichtig
Einige Azure CLI-Befehle in diesem Artikel verwenden die Erweiterung
azure-cli-mloder v1 für Azure Machine Learning. Der Support für CLI v1 endete am 30. September 2025. Microsoft stellt keinen technischen Support oder keine Updates für diesen Dienst mehr bereit. Ihre vorhandenen Workflows, die CLI v1 verwenden, funktionieren weiterhin nach dem Enddatum des Supports. Sie können jedoch Sicherheitsrisiken oder Breaking Changes im Falle von Architekturänderungen im Produkt ausgesetzt sein.Es wird empfohlen, so bald wie möglich auf die
mlErweiterung bzw. v2 umzusteigen. Weitere Informationen zur v2-Erweiterung finden Sie unter Azure Machine Learning CLI-Erweiterung und Python SDK v2.Bei den in diesem Artikel verwendeten Python-Codeschnipseln wird davon ausgegangen, dass die folgenden Variablen festgelegt sind:
-
ws: Legen Sie diese Variable auf Ihren Arbeitsbereich fest. -
model: Legen Sie diese Variable auf Ihr registriertes Modell fest. -
inference_config: Legen Sie diese Variable auf die Rückschlusskonfiguration für das Modell fest.
Weitere Informationen zum Festlegen dieser Variablen finden Sie unter Wie und wo Modelle bereitgestellt werden.
-
Bei den CLI-Codeschnipseln in diesem Artikel wird davon ausgegangen, dass Sie bereits ein Dokument inferenceconfig.json erstellt haben. Weitere Informationen zum Erstellen dieses Dokuments finden Sie unter Bereitstellen von Machine Learning-Modellen in Azure.
Ein mit Ihrem Arbeitsbereich verbundener AKS-Cluster. Weitere Informationen finden Sie unter Erstellen und Anfügen eines Azure Kubernetes Service-Clusters.
- Wenn Sie Modelle auf GPU-Knoten oder FPGA-Knoten (oder einem bestimmten Produkt) bereitstellen möchten, müssen Sie einen Cluster mit dem jeweiligen Produkt erstellen. Das Erstellen eines sekundären Knotenpools in einem vorhandenen Cluster und das Bereitstellen von Modellen im sekundären Knotenpool wird nicht unterstützt.
Grundlegendes zu Bereitstellungsprozessen
Der Begriff Bereitstellung wird sowohl in Kubernetes als auch in Azure Machine Learning verwendet.
Bereitstellung hat in diesen beiden Kontexten unterschiedliche Bedeutungen. In Kubernetes ist eine Bereitstellung eine konkrete Entität, die mit einer deklarativen YAML-Datei angegeben wird. Eine Kubernetes-Bereitstellung verfügt über einen definierten Lebenszyklus und konkrete Beziehungen mit anderen Kubernetes-Entitäten wie Pods und ReplicaSets. Weitere Informationen zu Kubernetes in Form von Dokumenten und Videos finden Sie unter Was ist Kubernetes?.
In Azure Machine Learning wird „Bereitstellung“ allgemeiner für das Verfügbarmachen und Bereinigen Ihrer Projektressourcen verwendet. Folgende Schritte werden in Azure Machine Learning als Teil der Bereitstellung betrachtet:
- Zippen der Dateien in Ihrem Projektordner, wobei die in .amlignore oder .gitignore angegebenen Dateien ignoriert werden
- Hochskalieren Ihres Computeclusters (bezieht sich auf Kubernetes)
- Erstellen oder Herunterladen des Dockerfiles auf den Serverknoten (bezieht sich auf Kubernetes)
- Das System berechnet einen Hashwert aus:
- Dem Basisimage
- Benutzerdefinierten Docker-Schritten (siehe Bereitstellen eines Modells mithilfe eines benutzerdefinierten Docker-Basisimages)
- Der Conda-Definitions-YAML-Datei (siehe Erstellen und Verwenden von Softwareumgebungen in Azure Machine Learning)
- Das System verwendet diesen Hash als Schlüssel in einer Suche nach der ACR-Instanz (Azure Container Registry) für den Arbeitsbereich.
- Wenn sie nicht gefunden wird, wird nach einer Übereinstimmung in der globalen ACR gesucht
- Wenn keine gefunden wird, erstellt das System ein neues Image, das zwischengespeichert und an die ACR-Instanz des Arbeitsbereichs übermittelt wird.
- Das System berechnet einen Hashwert aus:
- Herunterladen der gezippten Projektdatei in den temporären Speicher auf dem Serverknoten
- Entzippen der Projektdatei
- Ausführen von
python <entry script> <arguments>auf dem Serverknoten - Speichern von Protokollen, Modelldateien und anderen Dateien, die in dem Speicherkonto, das dem Arbeitsbereich zugeordnet ist, in ./outputs geschrieben werden
- Herunterskalieren von Computeressourcen, einschließlich Entfernen des temporären Speichers (bezieht sich auf Kubernetes)
Azure Machine Learning-Router
Die Front-End-Komponente (azureml-fe), die eingehende Rückschlussanforderungen an bereitgestellte Dienste weiterleitet, wird automatisch nach Bedarf skaliert. Die Skalierung von azureml-fe basiert dem Zweck und der Größe (Anzahl der Knoten) des AKS-Clusters. Clusterzweck und -knoten werden konfiguriert, wenn Sie einen AKS-Cluster erstellen oder anfügen. Es gibt einen azureml-fe-Dienst pro Cluster, der auf mehreren Pods ausgeführt werden kann.
Wichtig
- Bei Verwendung eines als
dev-testkonfigurierten Clusters wird die Selbstskalierung deaktiviert. Auch für FastProd-/DenseProd-Cluster wird die Selbstskalierung nur aktiviert, wenn dies gemäß den Telemetriedaten erforderlich ist. - Azure Machine Learning lädt Protokolle nicht automatisch aus Containern (einschließlich Systemcontainern) hoch oder speichert sie. Für ein umfassendes Debuggen empfiehlt es sich, Container Insights für Ihren AKS-Cluster zu aktivieren. Auf diese Weise können Sie Containerprotokolle bei Bedarf speichern, verwalten und für das AML-Team freigeben. Andernfalls kann AML keine Unterstützung für Probleme im Zusammenhang mit azureml-fe garantieren.
- Die maximale Größe der Anforderungsnutzdaten beträgt 100 MB.
Azureml-fe wird sowohl (vertikal) hochskaliert, um mehr Kerne zu verwenden, als auch (horizontal) aufskaliert, um mehr Pods zu verwenden. Wenn Sie die Entscheidung zum zentralen Hochskalieren treffen, wird die Zeit herangezogen, die zum Weiterleiten eingehender Rückschlussanforderungen benötigt wird. Wenn diese Zeit den Schwellenwert überschreitet, erfolgt eine Hochskalierung. Wenn die Zeit zum Weiterleiten eingehender Anforderungen weiterhin den Schwellenwert überschreitet, erfolgt eine Aufskalierung.
Beim Herunter- und Abskalieren wird die CPU-Auslastung verwendet. Wenn der Schwellenwert für die CPU-Auslastung erreicht ist, wird zuerst das Front-End herunterskaliert. Wenn die CPU-Auslastung auf den Schwellenwert für die Abskalierung sinkt, erfolgt eine Abskalierung. Ein Hoch- und Aufskalieren erfolgt nur, wenn genügend Clusterressourcen verfügbar sind.
Beim Hoch- oder Herunterskalieren werden Pods vom Typ azureml-fe neu gestartet, um die Änderungen an CPU bzw. Arbeitsspeicher zu übernehmen. Neustarts wirken sich nicht auf Rückschlussanforderungen aus.
Grundlegendes zu Konnektivitätsanforderungen für AKS-Rückschlusscluster
Wenn Azure Machine Learning einen AKS-Cluster erstellt oder anfügt, wird der AKS-Cluster mit einem der beiden folgenden Netzwerkmodelle bereitgestellt:
- Kubenet-Netzwerke: Die Netzwerkressourcen werden normalerweise bei der Bereitstellung des AKS-Clusters erstellt und konfiguriert.
- Azure CNI-Netzwerke (Container Networking Interface): Der AKS-Cluster wird mit einer vorhandenen VNet-Ressource und -konfigurationen verbunden.
Für das Kubenet-Netzwerk wird das Netzwerk für Azure Machine Learning Service erstellt und ordnungsgemäß konfiguriert. Für das CNI-Netzwerk müssen Sie die Konnektivitätsanforderungen kennen und die DNS-Auflösung und die ausgehende Konnektivität für AKS-Rückschlüsse sicherstellen. So können Sie z. B. eine Firewall verwenden, um den Netzwerkdatenverkehr zu blockieren.
Das folgende Diagramm zeigt die Konnektivitätsanforderungen für AKS-Rückschlüsse. Die schwarzen Pfeile stehen für die tatsächliche Kommunikation und die blauen Pfeile für die Domänennamen. Möglicherweise müssen Sie Ihrer Firewall oder Ihrem benutzerdefinierten DNS-Server die Einträge für diese Hosts hinzufügen.
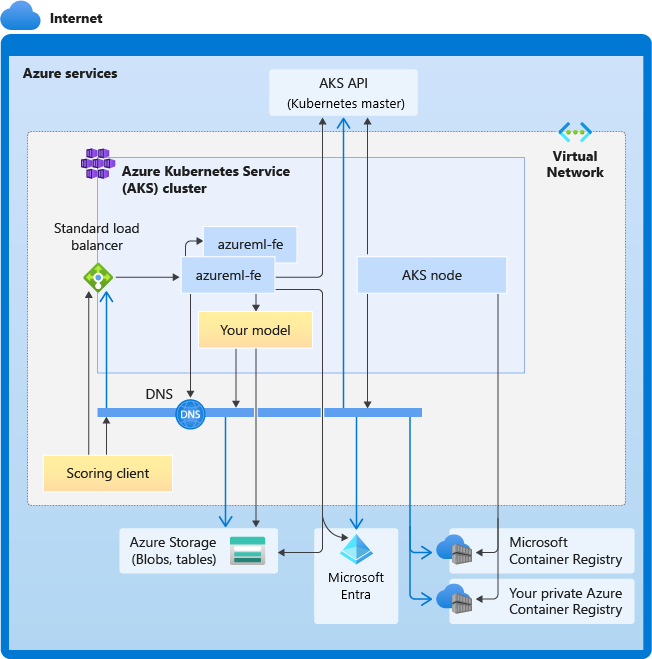
Allgemeine Anforderungen an die AKS-Konnektivität finden Sie unter Einschränken des Netzwerkdatenverkehrs mit Azure Firewall in AKS.
Weitere Informationen zum Zugreifen auf Azure Machine Learning-Dienste hinter einer Firewall finden Sie unter Konfigurieren von ein- und ausgehendem Netzwerkdatenverkehr.
Allgemeine Anforderungen an die DNS-Auflösung
Die DNS-Auflösung in einem vorhandenen virtuellen Netzwerk befindet sich unter Ihrer Kontrolle. Beispiel: Firewall oder benutzerdefinierter DNS-Server. Die folgenden Hosts müssen erreichbar sein:
| Hostname | Verwendet von |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS-API-Server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Ihre ACR-Instanz (Azure Container Registry) |
<account>.table.core.windows.net |
Azure Storage-Konto (Tabellenspeicher) |
<account>.blob.core.windows.net |
Azure Storage-Konto (Blob Storage) |
api.azureml.ms |
Microsoft Entra-Authentifizierung |
ingest-vienna<region>.kusto.windows.net |
Kusto-Endpunkt zum Hochladen von Telemetriedaten |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Domänenname des Endpunkts, wenn er von Azure Machine Learning automatisch generiert wird. Wenn Sie einen benutzerdefinierten Domänennamen verwendet haben, benötigen Sie diesen Eintrag nicht. |
Konnektivitätsanforderungen in chronologischer Reihenfolge
Beim Erstellen oder Anfügen von AKS wird der Azure Machine Learning-Router (azureml-fe) im AKS-Cluster bereitgestellt. Für die Bereitstellung des Azure Machine Learning-Routers sollte der AKS-Knoten Folgendes ausführen können:
- Auflösen von DNS für den AKS-API-Server
- Auflösen von DNS für MCR, um Docker-Images für Azure Machine Learning-Router herunterzuladen
- Herunterladen von Images aus MCR, wenn ausgehende Konnektivität erforderlich ist
Direkt nach der Bereitstellung von azureml-fe wird versucht, ihn zu starten. Dafür ist Folgendes erforderlich:
- Auflösen von DNS für den AKS-API-Server
- Fragen Sie den AKS-API-Server ab, um andere Instanzen von sich selbst zu ermitteln (es handelt sich um einen Multi-Pod-Dienst).
- Herstellen einer Verbindung mit anderen Instanzen von sich selbst
Nachdem azureml-fe gestartet wurde, benötigt es die folgende Konnektivität, um ordnungsgemäß zu funktionieren:
- Herstellen einer Verbindung mit Azure Storage zum Herunterladen einer dynamischen Konfiguration
- Führen Sie die DNS-Auflösung für den Microsoft Entra-Authentifizierungsserver api.azureml.ms aus, und kommunizieren Sie mit ihm, wenn der bereitgestellte Dienst die Microsoft Entra-Authentifizierung verwendet.
- Abfragen des AKS-API-Servers zum Ermitteln bereitgestellter Modelle
- Kommunizieren mit bereitgestellten Modell-PODs
Zum Zeitpunkt der Modellimplementierung sollte der AKS-Knoten zu Folgendem in der Lage sein:
- Auflösen von DNS für die ACR-Instanz des Kunden
- Herunterladen von Images aus der ACR des Kunden
- Auflösen von DNS für Azure-BLOBs, in denen das Modell gespeichert wird
- Herunterladen von Modellen aus Azure-Blobs
Nach der Bereitstellung des Modells und dem Start des Diensts wird azureml-fe automatisch mithilfe der AKS-API erkannt und ist damit bereit, Anforderungen an das Modell weiterzuleiten. Er muss in der Lage sein, mit den Modell-PODs zu kommunizieren.
Hinweis
Wenn das bereitgestellte Modell eine Konnektivität erfordert (z. B. zum Abfragen einer externen Datenbank oder eines anderen REST-Diensts oder zum Herunterladen eines Blobs), sollten sowohl die DNS-Auflösung als auch die ausgehende Kommunikation für diese Dienste aktiviert sein.
Bereitstellen in AKS
Um ein Modell in AKS bereitzustellen, erstellen Sie eine Bereitstellungskonfiguration, die die erforderlichen Computeressourcen beschreibt. Dies sind beispielsweise die Anzahl von Kernen und die Arbeitsspeichergröße. Außerdem benötigen Sie eine Rückschlusskonfiguration, in der die zum Hosten des Modells und des Webdiensts erforderliche Umgebung beschrieben wird. Weitere Informationen zum Erstellen der Rückschlusskonfiguration finden Sie unter Wie und wo Modelle bereitgestellt werden.
Hinweis
Die Anzahl der bereitzustellenden Modelle ist auf 1.000 Modelle pro Bereitstellung (pro Container) beschränkt.
GILT FÜR: Azure Machine Learning SDK v1 für Python
Azure Machine Learning SDK v1 für Python
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Weitere Informationen zu den in diesem Beispiel verwendeten Klassen, Methoden und Parametern finden Sie in den folgenden Referenzdokumenten:
Automatische Skalierung
GILT FÜR:Azure Machine Learning SDK v1 für Python
Die Komponente für die automatische Skalierung von Azure Machine Learning-Modellimplementierungen ist „azureml-fe“, ein intelligenter Anforderungsrouter. Da er von allen Rückschlussanforderungen durchlaufen wird, verfügt er über die zum automatischen Skalieren der bereitgestellten Modelle erforderlichen Daten.
Wichtig
Aktivieren Sie die horizontale automatische Kubernetes-Podskalierung (HPA) nicht für Modellimplementierungen. Andernfalls würden die beiden Komponenten für die automatische Skalierung miteinander konkurrieren. Azureml-fe ist für die automatische Skalierung von Modellen konzipiert, die von Azure Machine Learning bereitgestellt wurden. Dabei müsste HPA die Modellauslastung anhand einer generischen Metrik wie der CPU-Auslastung oder einer benutzerdefinierten Metrikkonfiguration schätzen oder näherungsweise ermitteln.
Azureml-fe skaliert die Anzahl der Knoten in einem AKS-Cluster nicht, da dies zu unerwarteten Kostensteigerungen führen könnte. Stattdessen erfolgt eine Skalierung der Anzahl der Replikate für das Modell innerhalb der physischen Clustergrenzen. Wenn Sie die Anzahl der Knoten im Cluster skalieren müssen, können Sie den Cluster manuell skalieren oder die Autoskalierung von AKS-Clustern konfigurieren.
Die automatische Skalierung kann durch Festlegen von autoscale_target_utilization, autoscale_min_replicas und autoscale_max_replicas für den AKS-Webdienst gesteuert werden. Die Aktivierung der automatischen Skalierung wird im folgenden Beispiel veranschaulicht:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Entscheidungen zum Hoch- oder Herunterskalieren werden auf der Grundlage der Auslastung der aktuellen Containerreplikate getroffen. Zur Ermittlung der aktuellen Auslastung wird die Anzahl ausgelasteter Replikate (Replikate, die eine Anforderung verarbeiten) durch die Gesamtanzahl aktueller Replikate geteilt. Übersteigt dieser Wert autoscale_target_utilization, werden weitere Replikate erstellt. Wenn es niedriger ist, werden Replikate reduziert. Die Zielauslastung ist standardmäßig auf 70 % festgelegt.
Entscheidungen zum Hinzufügen von Replikaten sind eifrig und schnell (ungefähr 1 Sekunde). Die Entscheidung, Replikate zu entfernen, erfolgt zurückhaltend (etwa 1 Minute).
Die erforderlichen Replikate können Sie mithilfe des folgenden Codes berechnen:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Weitere Informationen zum Festlegen von autoscale_target_utilization, autoscale_max_replicas und autoscale_min_replicas finden Sie in der Modulreferenz zu AksWebservice.
Webdienstauthentifizierung
Bei der Bereitstellung in Azure Kubernetes Service ist die schlüsselbasierte Authentifizierung standardmäßig aktiviert. Sie können auch die tokenbasierte Authentifizierung aktivieren. Für die tokenbasierte Authentifizierung müssen Clients ein Microsoft Entra-Konto verwenden, um ein Authentifizierungstoken anzufordern, mit dem Anforderungen an den bereitgestellten Dienst gesendet werden.
Um die Authentifizierung zu deaktivieren, legen Sie den auth_enabled=False-Parameter beim Erstellen der Bereitstellungskonfiguration fest. Im folgenden Beispiel wird die Authentifizierung mithilfe des SDK deaktiviert:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Weitere Informationen zum Authentifizieren aus einer Clientanwendung finden Sie unter Verwenden eines als Webdienst bereitgestellten Azure Machine Learning-Modells.
Authentifizierung mit Schlüsseln
Bei aktivierter Schlüsselauthentifizierung können Sie mithilfe der get_keys-Methode einen primären und einen sekundären Authentifizierungsschlüssel abrufen:
primary, secondary = service.get_keys()
print(primary)
Wichtig
Wenn Sie einen Schlüssel erneut generieren müssen, verwenden Sie service.regen_key.
Authentifizierung mit Token
Um die Tokenauthentifizierung zu aktivieren, legen Sie den token_auth_enabled=True Parameter fest, wenn Sie eine Bereitstellung erstellen oder aktualisieren. Im folgenden Beispiel wird die Authentifizierung mithilfe des SDK aktiviert:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Wenn die Tokenauthentifizierung aktiviert ist, können Sie die get_token Methode verwenden, um ein JWT und die Ablaufzeit dieses Tokens abzurufen:
token, refresh_by = service.get_token()
print(token)
Wichtig
Nach Ablauf der für den Token festgelegten refresh_by-Zeit müssen Sie ein neues Token anfordern.
Microsoft empfiehlt dringend, den Azure Machine Learning-Arbeitsbereich in der gleichen Region zu erstellen wie den AKS-Cluster. Im Zuge der Tokenauthentifizierung richtet der Webdienst einen Aufruf an die Region, in der Ihr Azure Machine Learning-Arbeitsbereich erstellt wird. Ist die Region Ihres Arbeitsbereichs nicht verfügbar, können Sie kein Token für Ihren Webdienst abrufen (auch dann nicht, wenn sich Ihr Cluster in einer anderen Region befindet als Ihr Arbeitsbereich). Die tokenbasierte Authentifizierung ist dann erst wieder verfügbar, wenn die Region Ihres Arbeitsbereichs wieder verfügbar wird. Außerdem wirkt sich die Entfernung zwischen der Region Ihres Clusters und der Region Ihres Arbeitsbereichs direkt auf die Tokenabrufdauer aus.
Zum Abrufen eines Tokens müssen Sie das Azure Machine Learning SDK oder den Befehl az ml service get-access-token verwenden.
Überprüfung auf Sicherheitsrisiken
Microsoft Defender for Cloud bietet eine einheitliche Sicherheitsverwaltung und erweiterten Bedrohungsschutz für Hybrid Cloud-Workloads. Sie sollten Microsoft Defender for Cloud erlauben, Ihre Ressourcen zu überprüfen, und die Empfehlungen befolgen. Weitere Informationen finden Sie unter Containersicherheit in Microsoft Defender for Containers.
Verwandte Inhalte
- Verwenden der rollenbasierten Zugriffssteuerung in Azure für die Kubernetes-Autorisierung
- Schützen einer Azure Machine Learning-Rückschlussumgebung mit virtuellen Netzwerken
- Verwenden eines benutzerdefinierten Containers zum Bereitstellen eines Modells auf einem Onlineendpunkt
- Behandeln von Problemen bei der Remotemodellimplementierung
- Aktualisieren eines bereitgestellten Webdiensts
- Verwenden von TLS zum Schützen eines Webdiensts mit Azure Machine Learning
- Verwenden eines als Webdienst bereitgestellten Azure Machine Learning-Modells
- Überwachen und Erfassen von Daten von ML-Webdienst-Endpunkten
- Sammeln von Daten von Modellen in der Produktion