Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Machine Learning SDK v1 für Python
Azure Machine Learning SDK v1 für Python
Wichtig
Dieser Artikel enthält Informationen zur Verwendung des Azure Machine Learning SDK v1. SDK v1 ist ab dem 31. März 2025 veraltet. Der Support für sie endet am 30. Juni 2026. Sie können SDK v1 bis zu diesem Datum installieren und verwenden.
Es wird empfohlen, vor dem 30. Juni 2026 zum SDK v2 zu wechseln. Weitere Informationen zu SDK v2 finden Sie unter Was ist Azure Machine Learning CLI und Python SDK v2? und die SDK v2-Referenz.
In diesem Artikel wird beschrieben, wie Sie eine Machine Learning-Pipeline für Ihre Kollegen oder Kunden freigeben.
Pipelines für maschinelles Lernen sind wiederverwendbare Workflows für Aufgaben beim maschinellem Lernen. Ein Vorteil von Pipelines ist die verstärkte Kollaboration. Sie können auch Versionspipelines verwenden, damit Kunden das aktuelle Modell verwenden können, während Sie an einer neuen Version arbeiten.
Voraussetzungen
Erstellen Sie einen Azure Machine Learning-Arbeitsbereich , der Ihre Pipelineressourcen enthält.
Konfigurieren Sie Ihre Entwicklungsumgebung , indem Sie das Azure Machine Learning SDK installieren oder eine Azure Machine Learning-Computeinstanz verwenden, die bereits das SDK installiert hat.
Erstellen und Ausführen einer Machine Learning-Pipeline. Eine Möglichkeit, diese Anforderung zu erfüllen, ist das Abschließen des Lernprogramms: Erstellen einer Azure Machine Learning-Pipeline für die Batchbewertung. Weitere Optionen finden Sie unter Erstellen und Ausführen von Machine Learning-Pipelines mit dem Azure Machine Learning SDK.
Veröffentlichen einer Pipeline
Nachdem Sie über eine ausgeführte Pipeline verfügen, können Sie sie veröffentlichen, damit sie mit unterschiedlichen Eingaben ausgeführt wird. Damit der REST-Endpunkt einer veröffentlichten Pipeline Parameter akzeptiert, müssen Sie die Pipeline PipelineParameter so konfigurieren, dass Objekte für die Argumente verwendet werden, die variieren.
Verwenden Sie zum Erstellen eines Pipelineparameters ein PipelineParameter-Objekt mit einem Standardwert:
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Fügen Sie das
PipelineParameterObjekt als Parameter zu einem der Schritte in der Pipeline hinzu, wie hier gezeigt:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Veröffentlichen Sie diese Pipeline, die beim Aufrufen einen Parameter akzeptiert:
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Nachdem Sie Ihre Pipeline veröffentlicht haben, können Sie sie in der Benutzeroberfläche überprüfen. Die Pipeline-ID ist der eindeutige Bezeichner der veröffentlichten Pipeline.
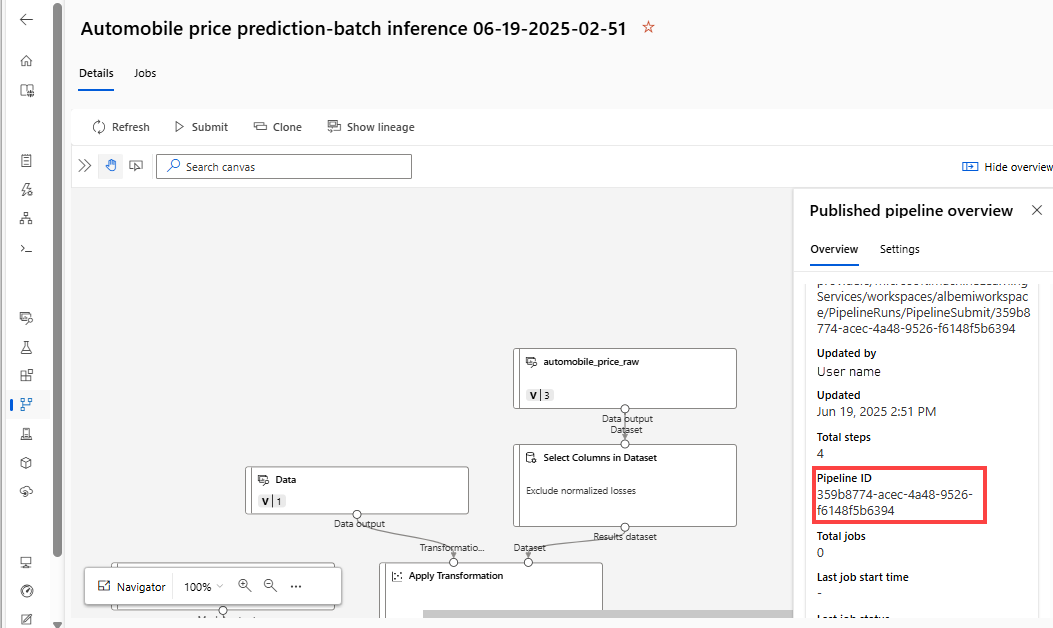

Ausführen einer veröffentlichten Pipeline
Alle veröffentlichten Pipelines weisen einen REST-Endpunkt auf. Mithilfe des Pipelineendpunkts können Sie eine Ausführung der Pipeline von externen Systemen auslösen, einschließlich nicht-Python-Clients. Dieser Endpunkt ermöglicht die verwaltete Wiederholbarkeit in Batchbewertungs- und Umschulungsszenarien.
Wichtig
Wenn Sie azure role-based access control (RBAC) zum Verwalten des Zugriffs auf Ihre Pipeline verwenden, legen Sie die Berechtigungen für Ihr Pipelineszenario (Schulung oder Bewertung) fest.
Um die Ausführung der vorhergehenden Pipeline aufrufen zu können, benötigen Sie ein Headertoken für die Microsoft Entra-Authentifizierung. Der Prozess zum Abrufen eines Tokens wird in der AzureCliAuthentication-Klassenreferenz und im Authentifizierungsnotizbuch in Azure Machine Learning beschrieben.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Das json Argument für die POST-Anforderung muss für den ParameterAssignments Schlüssel ein Wörterbuch enthalten, das die Pipelineparameter und deren Werte enthält. Darüber hinaus kann das json Argument die folgenden Schlüssel enthalten:
| Schlüssel | Beschreibung |
|---|---|
ExperimentName |
Der Name des Experiments, das dem Endpunkt zugeordnet ist. |
Description |
Freitext, der den Endpunkt beschreibt. |
Tags |
Freiform-Schlüssel-Wert-Paare, die zum Bezeichnen und Kommentieren von Anforderungen verwendet werden können. |
DataSetDefinitionValueAssignments |
Ein Wörterbuch, das zum Ändern von Datasets ohne Umschulung verwendet wird. (Weitere Informationen finden Sie weiter unten in diesem Artikel.) |
DataPathAssignments |
Ein Wörterbuch, das zum Ändern von Datenpfaden ohne Umschulung verwendet wird. (Weitere Informationen finden Sie weiter unten in diesem Artikel.) |
Ausführen einer veröffentlichten Pipeline mithilfe von C#
Der folgende Code zeigt, wie eine Pipeline von C# asynchron aufgerufen wird. Der Partielle Codeausschnitt zeigt lediglich die Aufrufstruktur an. Vollständige Klassen oder die Fehlerbehandlung werden nicht dargestellt. Es ist nicht Teil eines Microsoft-Beispiels.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// Submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Ausführen einer veröffentlichten Pipeline mithilfe von Java
Der folgende Code zeigt einen Aufruf einer Pipeline, die eine Authentifizierung erfordert. (Siehe Einrichten der Authentifizierung für Azure Machine Learning-Ressourcen und -Workflows.) Wenn Ihre Pipeline öffentlich bereitgestellt wird, benötigen Sie nicht die Aufrufe, die erzeugt werden authKey. Der partielle Codeschnipsel zeigt weder eine Java-Klasse noch Bausteine für die Ausnahmebehandlung. Der Code verwendet Optional.flatMap zum Verketten von Funktionen, die möglicherweise eine leere OptionalFunktion zurückgeben. Die Verwendung von flatMap verkürzt und verdeutlicht den Code, aber beachten Sie, dass getRequestBody() Ausnahmen abfängt.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token));
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc. (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Ändern von Datasets und Datenpfaden ohne Umschulung
Möglicherweise sollten Sie unterschiedliche Datasets und Datenpfade trainieren und zum Rückschließen verwenden. Sie können beispielsweise ein kleineres Dataset trainieren, aber die Rückschlüsse aus dem vollständigen Dataset ziehen. Sie können Datensätze mithilfe der DataSetDefinitionValueAssignments Taste im Argument json der Anforderung wechseln. Sie können Datenpfade mit DataPathAssignments wechseln. Die Technik ist für beide ähnlich:
Erstellen Sie im Pipelinedefinitionsskript einen
PipelineParameterfür das Dataset. Erstellen Sie eineDatasetConsumptionConfigoder einenDataPathaus demPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Greifen Sie in Ihrem Skript zum Maschinellen Lernen mithilfe von
Run.get_context().input_datasetsauf den dynamisch spezifizierten Datensatz zu:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc. ...Beachten Sie, dass das Machine Learning-Skript auf den für (
DatasetConsumptionConfig) angegebenentabular_datasetWert und nicht auf den Wert vonPipelineParameter(tabular_ds_param) zugreift.Legen Sie
DatasetConsumptionConfigin Ihrem Pipelinedefinitionsskript als Parameter aufPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Verwenden Sie
DataSetDefinitionValueAssignments, um Datasets im zum Rückschließen verwendeten REST-Aufruf dynamisch zu wechseln:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Die Notizbücher Showcasing Dataset und PipelineParameter und Showcasing DataPath und PipelineParameter enthalten vollständige Beispiele für diese Technik.
Erstellen eines Pipelineendpunkts mit Versionsangabe
Sie können einen Pipelineendpunkt erstellen, der mehrere veröffentlichte Pipelines dahinter hat. Mit dieser Technik erhalten Sie einen festen REST-Endpunkt, während Sie Ihre Machine Learning-Pipelines durchlaufen und aktualisieren.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Übermitteln eines Auftrags an einen Pipelineendpunkt
Sie können einen Auftrag an die Standardversion eines Pipelineendpunkts übermitteln:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Sie können einen Auftrag auch an eine bestimmte Version übermitteln:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Sie können dasselbe erreichen, indem Sie die REST-API verwenden:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Verwenden von veröffentlichten Pipelines in Studio
Sie können in Studio auch eine veröffentlichte Pipeline ausführen:
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie im linken Menü "Endpunkte" aus.
Auswählen von Pipelineendpunkten:
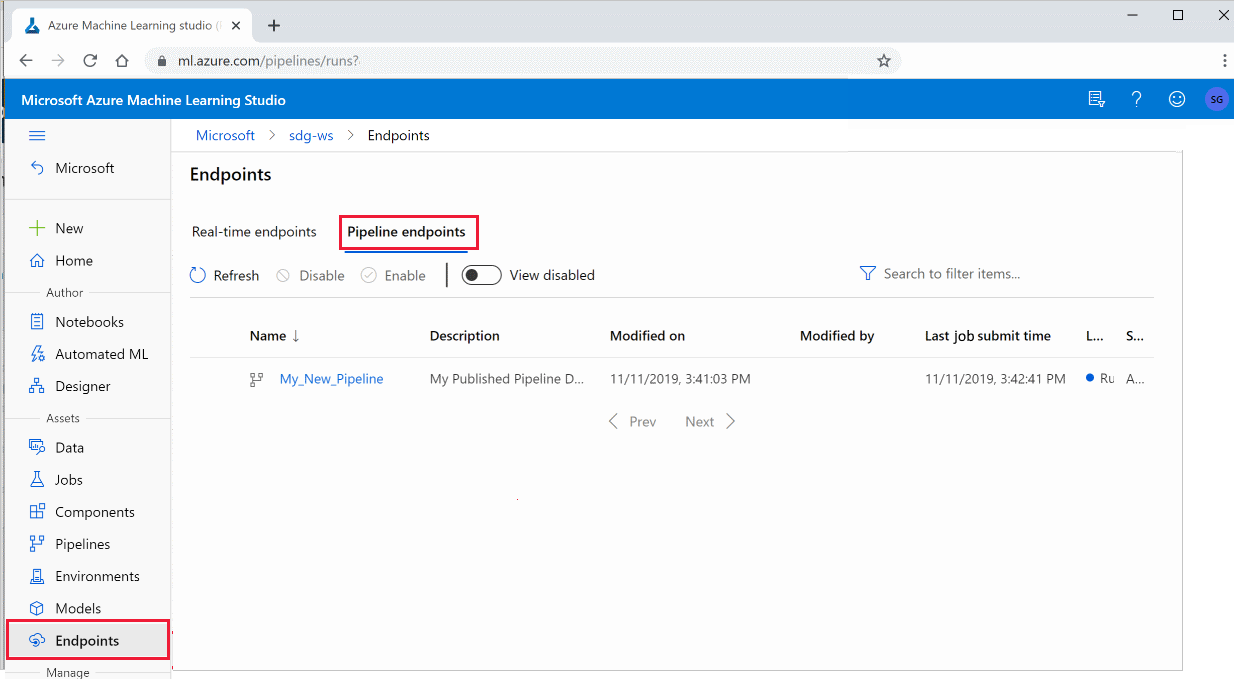
Wählen Sie eine bestimmte Pipeline aus, um einen Pipelineendpunkt auszuführen, zu nutzen oder die Ergebnisse früherer Ausführungen des Pipelineendpunkts zu überprüfen.

Deaktivieren einer veröffentlichten Pipeline
Um eine Pipeline aus Ihrer Liste der veröffentlichten Pipelines auszublenden, deaktivieren Sie sie entweder im Studio oder über das SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Sie können es erneut aktivieren, indem Sie es verwenden p.enable(). Weitere Informationen finden Sie in der Referenz zur PublishedPipeline-Klasse .
Nächste Schritte
- Verwenden Sie diese Jupyter-Notizbücher auf GitHub , um Machine Learning-Pipelines weiter zu erkunden.
- Weitere Informationen finden Sie in der SDK-Referenz für das Paket "azureml-pipelines-core " und das Paket "azureml-pipelines-steps ".
- Tipps zum Debuggen und Zur Problembehandlung von Pipelines finden Sie unter "Debuggen von Pipelines" .