Transformieren von Daten in Azure Machine Learning-Designer
In diesem Artikel erfahren Sie, wie Sie Datasets im Azure Machine Learning-Designer transformieren und speichern, um Ihre eigenen Daten für das maschinelle Lernen vorzubereiten.
Sie verwenden das Datasetbeispiel Adult Census Income Binary Classification (Binäres Klassifizierungsdataset der Einkommenserhebung für Erwachsene), um zwei Datasets vorzubereiten: ein Dataset mit Erhebungsinformationen von Erwachsenen nur aus den USA und ein weiteres Dataset mit Erhebungsinformationen von Erwachsenen außerhalb der USA.
In diesem Artikel lernen Sie Folgendes:
- Transformieren eines Datasets, um es für das Training vorzubereiten
- Exportieren der resultierenden Datasets in einen Datenspeicher
- Zeigen Sie die Ergebnisse an.
Die Ausführung der in dieser Anleitung beschriebenen Schritte ist Voraussetzung für die Schritte im Artikel Erneutes Trainieren von Modellen mit Azure Machine Learning-Designer (Vorschau). In diesem Artikel erfahren Sie, wie Sie mithilfe von transformierten Datasets mehrere Modelle mit Pipelineparametern trainieren.
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene für den Arbeitsbereich. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
Transformieren eines Datasets
In diesem Abschnitt erfahren Sie, wie Sie das Beispieldataset importieren und die Daten in US-Datasets und Nicht-US-Datasets unterteilen. Weitere Informationen zum Importieren eigener Daten in den Designer finden Sie unter Importieren von Daten.
Daten importieren
Führen Sie die folgenden Schritte aus, um das Beispieldataset zu importieren:
Melden Sie sich bei Azure Machine Learning Studio an, und wählen Sie den Arbeitsbereich aus, den Sie verwenden möchten.
Wechseln Sie zum Designer. Wählen Sie Erstellen einer neuen Pipeline mithilfe von klassischen vordefinierten Komponenten aus, um eine neue Pipeline zu erstellen.
Erweitern Sie links neben der Pipelinecanvas auf der Registerkarte Komponente den Knoten Beispieldaten.
Ziehen Sie das Dataset Adult Census Income Binary classification (Binäres Klassifizierungsdataset der Einkommenserhebung für Erwachsene) per Drag & Drop auf die Canvas.
Klicken Sie mit der rechten Maustaste auf die Datasetkomponente Adult Census Income (Einkommen von Erwachsenen), und wählen Sie Vorschaudaten aus.
Verwenden Sie das Fenster „Datenvorschau“, um das Dataset zu untersuchen. Beachten Sie besonders die Werte in der Spalte „native-country“.
Teilen der Daten
In diesem Abschnitt verwenden Sie die Komponente Split Data (Daten aufteilen), um Zeilen zu identifizieren und aufzuteilen, die „United-States“ in der Spalte „native-country“ enthalten.
Erweitern Sie links neben der Canvas auf der Registerkarte „Komponente“ den Abschnitt Datentransformation, und suchen Sie nach der Komponente Split Data.
Ziehen Sie die Komponente Split Data per Drag & Drop unter die Datasetkomponente auf der Canvas.
Verbinden der Datasetkomponente mit der Komponente Split Data
Wählen Sie die Komponente Split Data aus, um den Bereich Daten aufteilen zu öffnen.
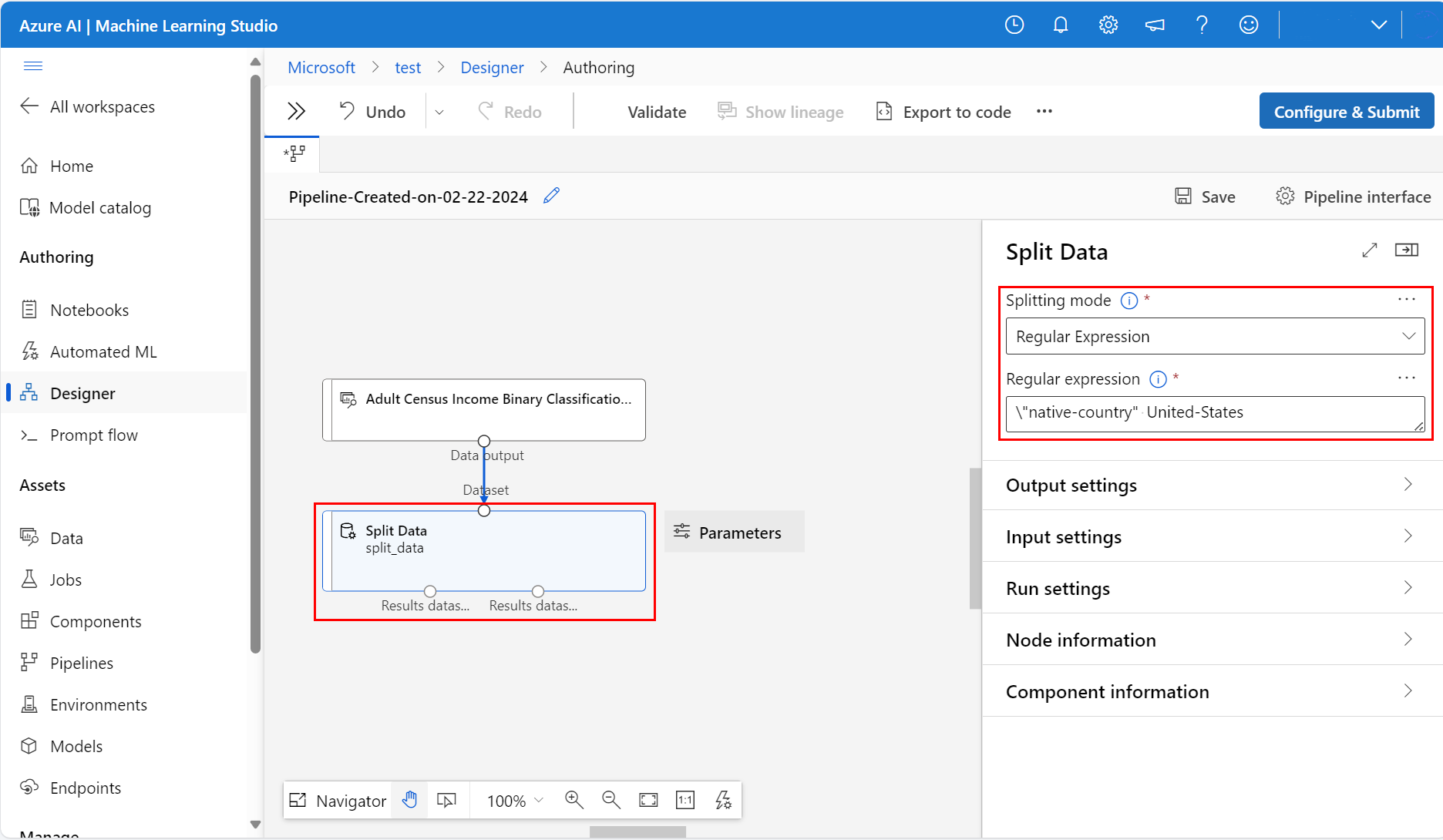
Legen Sie rechts neben der Canvas im Symbol Parameter die Option Aufteilungsmodus auf Regulärer Ausdruck fest.
Geben Sie einen Wert unter Regulärer Ausdruck ein:
\"native-country" United-StatesDer Modus Regulärer Ausdruck überprüft eine einzelne Spalte auf einen Wert. Weitere Informationen zur Komponente „Split Data“ finden Sie auf der entsprechenden Referenzseite für Algorithmen und Komponenten.
Ihre Pipeline sollte diesem Screenshot ähneln:
Speichern der Datasets
Nachdem Sie die Pipeline nun so eingerichtet haben, dass die Daten aufgeteilt werden, müssen Sie angeben, wo die Datasets gespeichert werden sollen. Verwenden Sie für dieses Beispiel die Komponente Daten exportieren, um das Dataset in einem Datenspeicher zu speichern. Weitere Informationen zu Datenspeichern finden Sie unter Herstellen einer Verbindung mit Azure-Speicherdiensten.
Erweitern Sie in der Komponentenpalette links neben der Canvas den Abschnitt Dateneingabe und -ausgabe, und suchen Sie nach der Komponente Export Data (Daten exportieren).
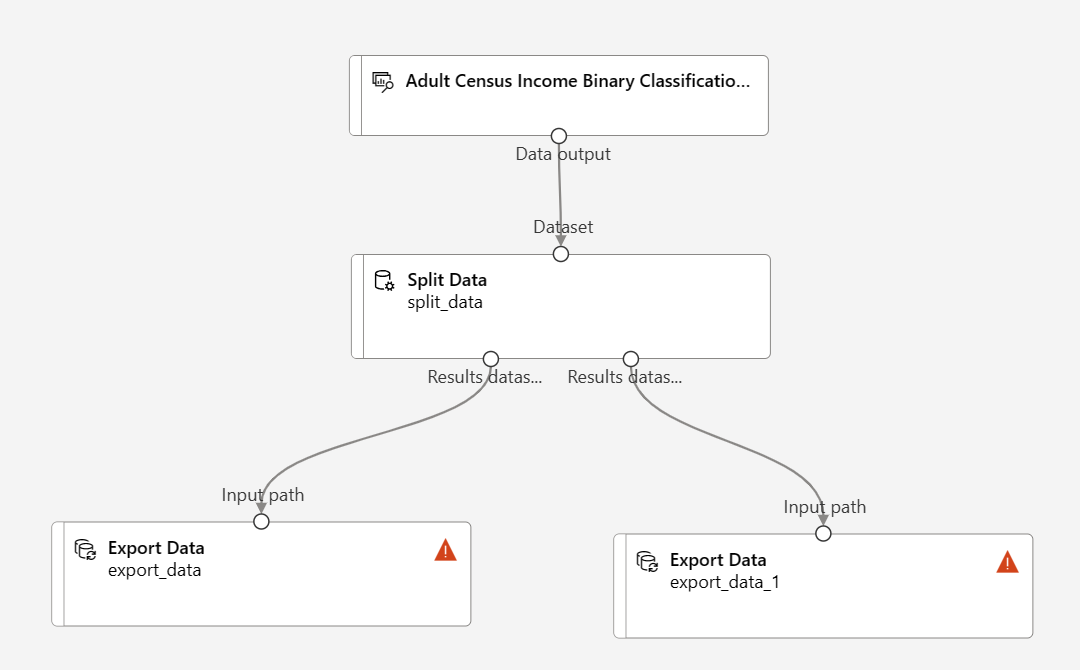
Ziehen Sie zwei Komponenten zum Exportieren von Daten per Drag &Drop unter die Komponente Split Data.
Verbinden Sie jeden Ausgabeport der Komponente Split Data mit jeweils einer Komponente vom Typ Export Data.
Ihre Pipeline sollte ungefähr wie folgt aussehen:
Wählen Sie die Komponente Export Data aus, die mit dem Port ganz links der Komponente Split Data verbunden ist, um den Konfigurationsbereich zum Exportieren von Daten zu öffnen.
Für die Komponente Split Data ist die Ausgabeportreihenfolge wichtig. Der erste Ausgabeport enthält die Zeilen, in denen der reguläre Ausdruck „true“ ist. In diesem Fall enthält der erste Port Zeilen für ein US-bezogenes Einkommen, und der zweite Port enthält Zeilen für Nicht-US-bezogenes Einkommen.
Wählen Sie rechts neben dem Zeichenbereich im Bereich mit den Komponentendetails die folgenden Optionen aus:
Datenspeichertyp: Azure Blob Storage
Datenspeicher: Wählen Sie einen vorhandenen Datenspeicher oder „Neuer Datenspeicher“ aus, um einen neuen Datenspeicher zu erstellen.
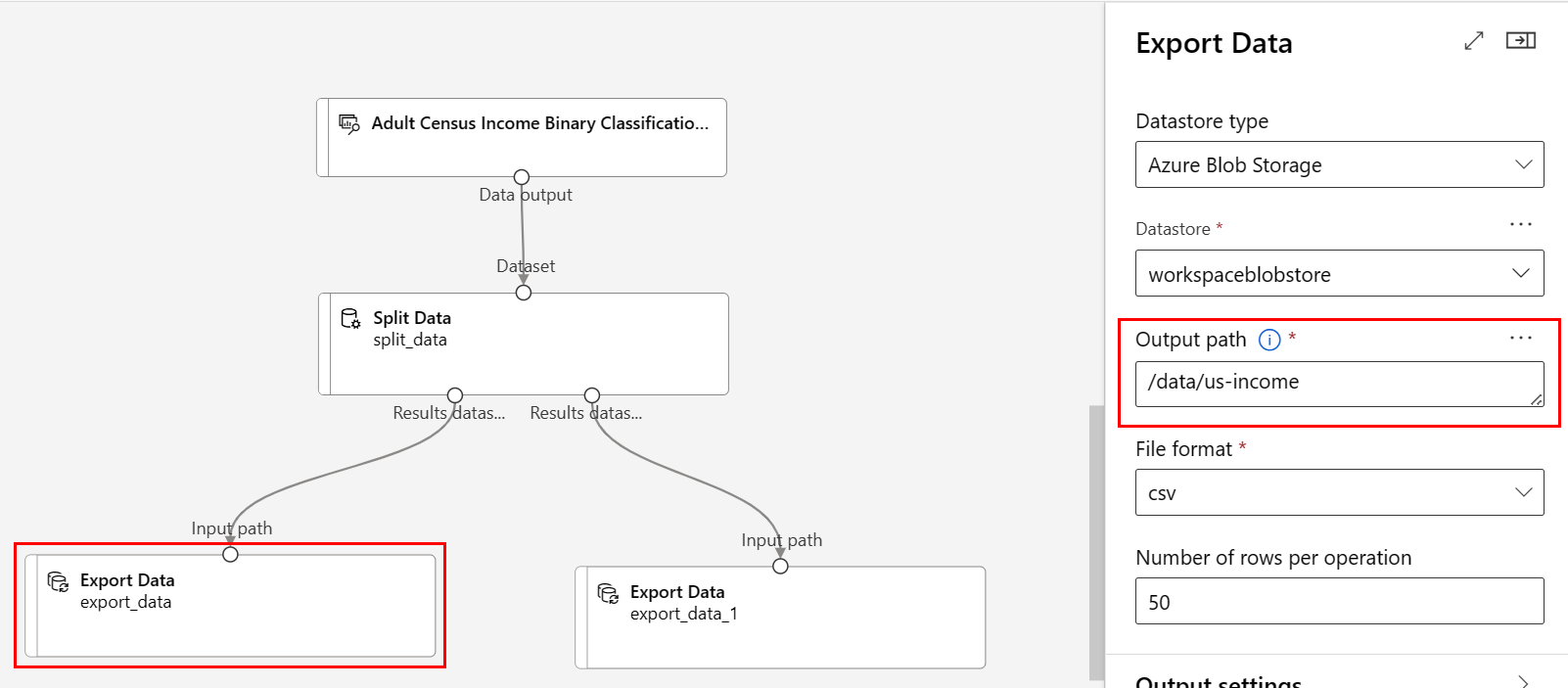
Pfad:
/data/us-incomeDateiformat: CSV
Hinweis
In diesem Artikel wird davon ausgegangen, dass Sie Zugriff auf einen Datenspeicher haben, der für den aktuellen Azure Machine Learning-Arbeitsbereich registriert ist. Anweisungen zum Einrichten von Datenspeichern finden Sie unter Herstellen einer Verbindung mit Azure-Speicherdiensten.
Wenn Sie über keinen Datenspeicher verfügen, können Sie nun einen erstellen. In diesem Artikel werden die Datasets beispielsweise im standardmäßigen BLOB-Speicherkonto gespeichert, das dem Arbeitsbereich zugeordnet ist. Die Datasets werden im Container
azuremlin einem neuen Ordner mit dem Namendatagespeichert.Wählen Sie die Komponente Export Data aus, die mit dem Port ganz rechts der Komponente Split Data verbunden ist, um den Konfigurationsbereich zum Exportieren von Daten zu öffnen.
Wählen Sie rechts neben dem Zeichenbereich im Detailbereich der Komponente die folgenden Optionen aus:
Datenspeichertyp: Azure Blob Storage
Datenspeicher: Wählen Sie den vorherigen Datenspeicher aus.
Pfad:
/data/non-us-incomeDateiformat: CSV
Überprüfen Sie, ob die Komponente Export Data, die mit dem linken Port der Komponente Split Data verbunden ist, den Pfad
/data/us-incomeaufweist.Überprüfen Sie, ob die Komponente Export Data, die mit dem rechten Port verbunden ist, den Pfad
/data/non-us-incomeaufweist.Die Pipeline und die Einstellungen sollten wie folgt aussehen:
Übermitteln des Auftrags
Nachdem Sie die Pipeline nun so eingerichtet haben, dass die Daten aufgeteilt und exportiert werden, übermitteln Sie einen Pipelineauftrag.
Wählen Sie im oberen Bereich der Canvas die Option Konfigurieren und Übermitteln aus.
Wählen Sie die Option Neu erstellen im Bereich „Grundlagen“ unter Pipelineauftrag einrichten aus, um ein Experiment zu erstellen.
Mit Experimenten werden zugehörige Pipelineaufträge logisch gruppiert. Wenn Sie diese Pipeline in Zukunft ausführen, sollten Sie für die Protokollierung und Nachverfolgung dasselbe Experiment verwenden.
Geben Sie einen beschreibenden Namen für das Experiment wie „split-census-data“ an.
Wählen Sie Überprüfen und übermitteln und dann Übermitteln aus.
Anzeigen der Ergebnisse
Nach Beendigung der Pipelineausführung können Sie im Azure-Portal zu Ihrem Blobspeicher navigieren, um die Ergebnisse anzuzeigen. Anhand der Zwischenergebnisse der Komponente Split Data können Sie zudem überprüfen, ob Ihre Daten korrekt aufgeteilt wurden.
Wählen Sie die Komponente Split Data aus.
Wählen Sie rechts neben der Canvas im Bereich mit den Komponentendetails die Registerkarte Ausgaben und Protokolle aus.
Wählen Sie das Dropdownmenü Datenausgaben anzeigen aus.
Wählen Sie das Symbol zum Visualisieren
 neben Results dataset1 (Ergebnisse von Dataset 1) aus.
neben Results dataset1 (Ergebnisse von Dataset 1) aus.Vergewissern Sie sich, dass die Spalte „native-country“ nur den Wert „United-States“ enthält.
Wählen Sie das Symbol zum Visualisieren
neben Results dataset2 (Ergebnisse von Dataset 2) aus.Vergewissern Sie sich, dass die Spalte „native-country“ nicht den Wert „United-States“ enthält.
Bereinigen von Ressourcen
Überspringen Sie diesen Abschnitt, um mit Teil 2 dieser Vorgehensweise zum erneuten Trainieren von Modellen mit dem Azure Machine Learning-Designer fortzufahren.
Wichtig
Sie können die von Ihnen bei der Vorbereitung erstellten Ressourcen auch in anderen Tutorials und Anleitungen für Azure Machine Learning verwenden.
Alles löschen
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie die gesamte Ressourcengruppe, damit Ihnen keine Kosten entstehen.
Wählen Sie im Azure-Portal links im Fenster Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Klicken Sie auf Ressourcengruppe löschen.
Durch das Löschen einer Ressourcengruppe werden auch alle im Designer erstellten Ressourcen gelöscht.
Löschen einzelner Objekte
In dem Designer, in dem Sie Ihr Experiment erstellt haben, können Sie einzelne Ressourcen löschen, indem Sie erst die gewünschten Ressourcen und dann die Schaltfläche Löschen auswählen.
Das hier erstellte Computeziel wird automatisch auf null Knoten skaliert, wenn es nicht verwendet wird. Diese Aktion wird durchgeführt, um Gebühren zu minimieren. Wenn Sie das Computeziel löschen möchten, führen Sie die folgenden Schritte aus:
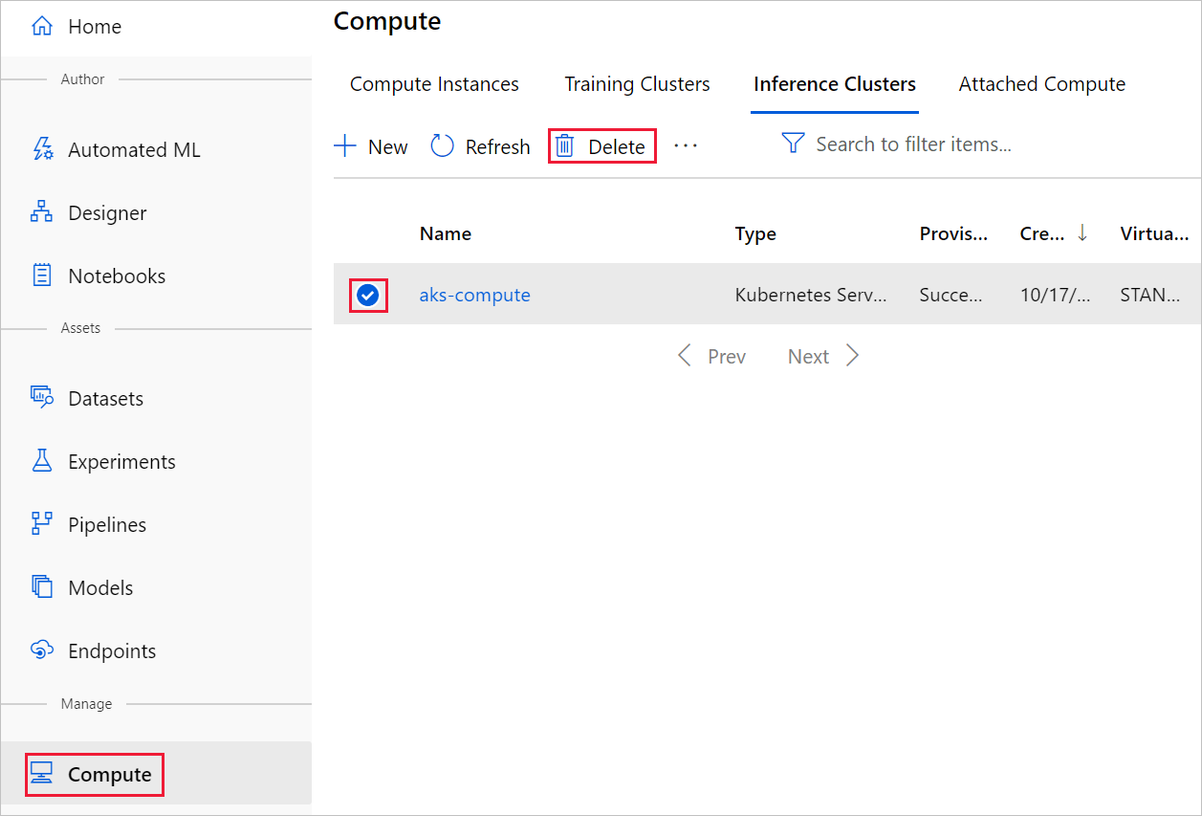
Die Registrierung von Datasets im Arbeitsbereich kann aufgehoben werden, indem Sie die einzelnen Datasets und anschließend Registrierung aufheben auswählen.
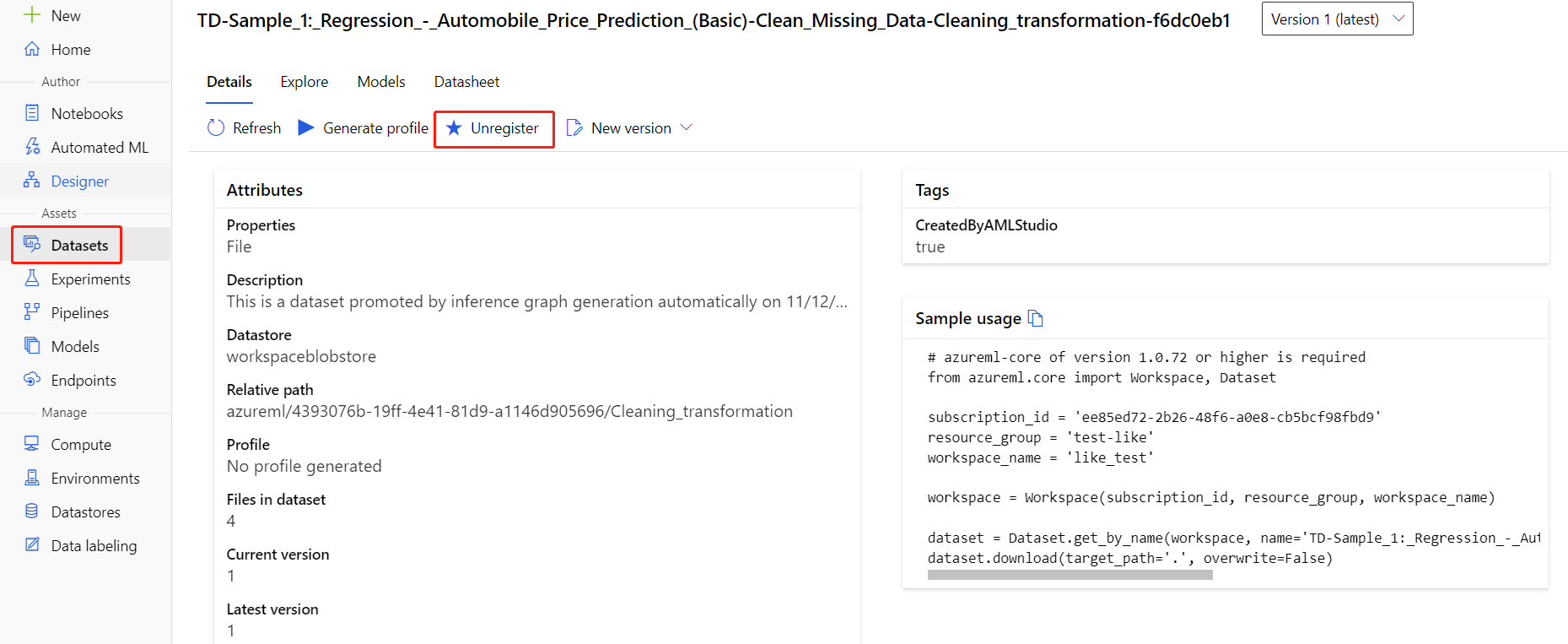
Zum Löschen eines Datasets wechseln Sie im Azure-Portal oder Azure Storage-Explorer zum Speicherkonto, und löschen Sie diese Ressourcen manuell.
Nächste Schritte
In diesem Artikel haben Sie erfahren, wie Sie ein Dataset transformieren und in einem registrierten Datenspeicher speichern.
Fahren Sie mit dem nächsten Teil des Leitfadens unter Erneutes Trainieren von Modellen mit dem Azure Machine Learning-Designer fort, um die transformierten Datasets und Pipelineparameter zum Trainieren von Machine Learning-Modellen zu verwenden.