Verwenden von Azure Machine Learning mit dem Open-Source-Paket Fairlearn zur Bewertung der Fairness von ML-Modellen (Vorschau)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In dieser Schrittanleitung erfahren Sie, wie Sie das Open-Source-Python-Paket Fairlearn mit Azure Machine Learning verwenden, um die folgenden Aufgaben auszuführen:
- Bewerten Sie die Fairness Ihrer Modellvorhersagen. Weitere Informationen zur Fairness im Bereich maschinelles Lernen finden Sie im Artikel Fairness bei Machine Learning-Modellen.
- Laden Sie Erkenntnisse aus der Fairnessbewertung in Azure Machine Learning Studio hoch, listen Sie sie dort auf, und laden Sie sie dort herunter.
- Sehen Sie sich ein Fairnessbewertungsdashboard in Azure Machine Learning Studio an, um mit den Erkenntnissen zur Fairness für Ihr(e) Modell(e) zu interagieren.
Hinweis
Eine Fairnessbewertung ist keine rein technische Angelegenheit. Dieses Paket kann Ihnen dabei helfen, die Fairness eines Machine Learning-Modells zu bewerten, aber nur Sie können das Modell konfigurieren und Entscheidungen in Bezug auf dessen Leistung treffen. Zwar hilft es dabei, quantitative Metriken zur Bewertung der Fairness zu identifizieren, Entwickler von Machine Learning-Modellen müssen jedoch auch eine qualitative Analyse durchführen, um die Fairness ihrer Modelle zu bewerten.
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Azure Machine Learning-Fairness-SDK
Das Azure Machine Learning-Fairness-SDK (azureml-contrib-fairness) integriert das Open-Source-Python-Paket Fairlearn in Azure Machine Learning. Weitere Informationen zur Integration von Fairlearn in Azure Machine Learning finden Sie in diesen Beispielnotebooks. Weitere Informationen zu Fairlearn finden Sie in der Anleitung mit Beispielen und den Beispielnotebooks.
Verwenden Sie die folgenden Befehle, um die Pakete azureml-contrib-fairness und fairlearn zu installieren:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Spätere Versionen von Fairlearn sollten auch im folgenden Beispielcode funktionieren.
Hochladen von Erkenntnissen zur Fairness für ein einzelnes Modell
Das folgende Beispiel zeigt die Verwendung des Fairnesspakets. Wir laden die Erkenntnisse zur Modellfairness in Azure Machine Learning hoch und sehen das Fairnessbewertungsdashboard in Azure Machine Learning Studio.
Trainieren Sie ein Beispielmodell in Jupyter Notebook.
Als Dataset verwenden Sie das bekannte Zensusdataset mit Angaben zu Erwachsenen, das Sie über OpenML abrufen. Unser Ausgangspunkt ist, dass bei der Kreditvergabeentscheidung ein Problem mit der Bezeichnung auftritt, die angibt, ob eine Person einen früheren Kredit zurückgezahlt hat. Wir trainieren ein Modell, um vorherzusagen, ob bisher unbekannte Personen einen Kredit zurückzahlen werden. Ein solches Modell kann für Kreditvergabeentscheidungen verwendet werden.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Melden Sie sich bei Azure Machine Learning an, und registrieren Sie Ihr Modell.
Das Fairnessdashboard kann mit registrierten oder nicht registrierten Modellen integriert werden. Registrieren Sie wie folgt Ihr Modell in Azure Machine Learning:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Berechnen Sie die Fairnessmetriken im Voraus.
Erstellen Sie mit dem Paket
metricsvon Fairlearn ein Dashboardwörterbuch. Die_create_group_metric_set-Methode verfügt über ähnliche Argumente wie der Dashboard-Konstruktor, mit dem Unterschied, dass die sensiblen Attribute als Wörterbuch übergeben werden (um sicherzustellen, dass Namen verfügbar sind). Außerdem müssen Sie beim Aufruf dieser Methode den Vorhersagetyp angeben (in diesem Fall Binärklassifizierung).# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Laden Sie die im Voraus berechneten Fairnessmetriken hoch.
Importieren Sie nun das Paket
azureml.contrib.fairness, um den Upload auszuführen:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idErstellen Sie ein Experiment, dann eine Ausführung, und laden Sie das Dashboard dort hoch:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Überprüfen Sie das Fairnessdashboard in Azure Machine Learning Studio.
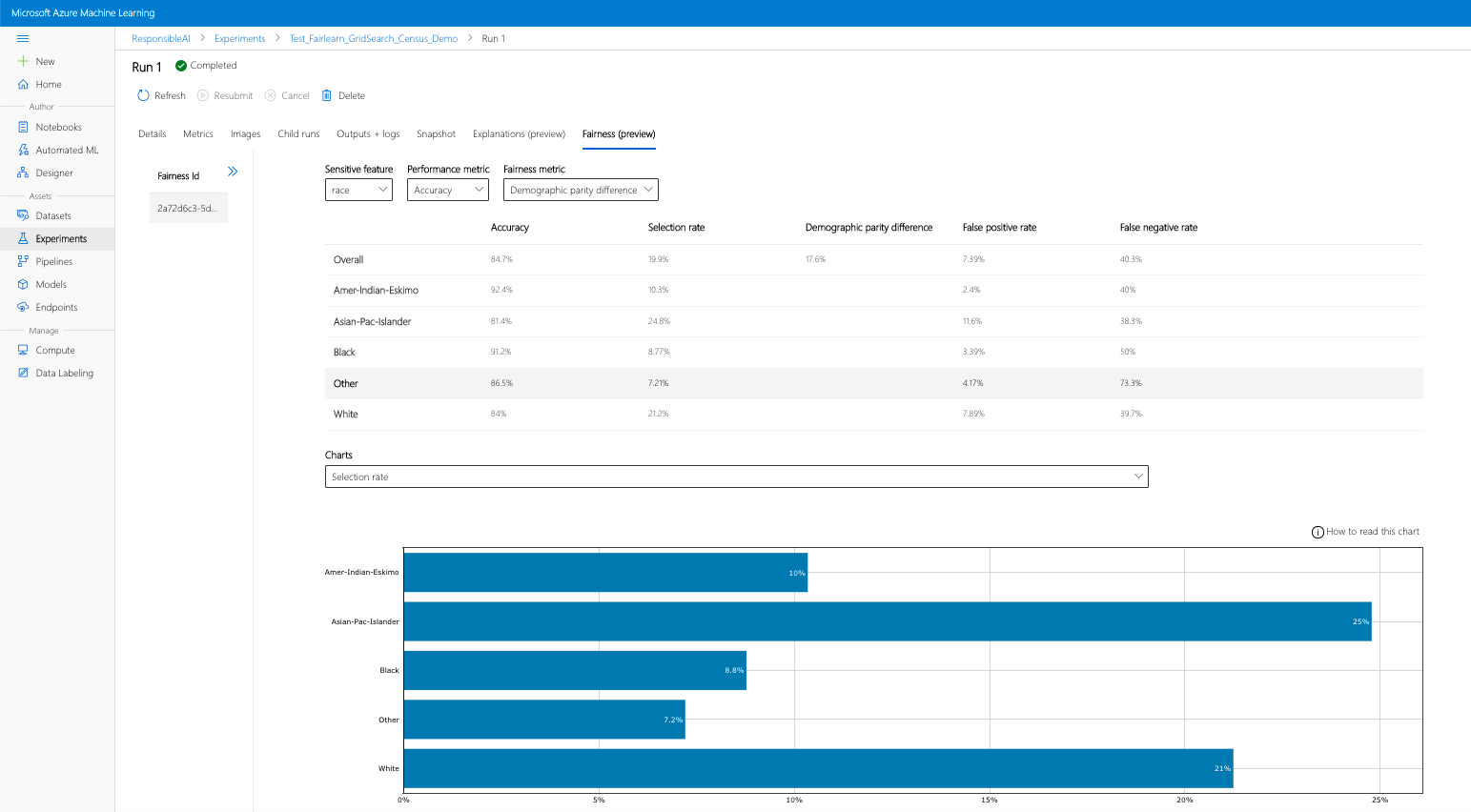
Wenn Sie die obigen Schritte ausführen (Hochladen generierter Erkenntnisse zur Fairness in Azure Machine Learning), können Sie das Fairnessdashboard in Azure Machine Learning Studio anzeigen. Dieses Dashboard ist das gleiche Visualisierungsdashboard, das auch in Fairlearn bereitgestellt wird, mit dem Sie die Unterschiede zwischen den Untergruppen Ihres sensiblen Attributs analysieren können (z. B. männlich vs. weiblich). Sie haben zwei Möglichkeiten, um auf das Visualisierungsdashboard in Azure Machine Learning-Studio zuzugreifen:
- Aufgabenbereich (Vorschau)
- Wählen Sie im linken Bereich die Option Aufträge aus, um eine Liste mit Experimenten anzuzeigen, die Sie in Azure Machine Learning ausgeführt haben.
- Wählen Sie ein bestimmtes Experiment aus, um alle Ausführungen in diesem Experiment anzuzeigen.
- Klicken Sie auf eine Ausführung und dann auf die Registerkarte Fairness, um das Dashboard zur Erklärungsvisualisierung anzuzeigen.
- Wenn Sie auf der Registerkarte Fairness gelandet sind, klicken Sie im Menü auf der rechten Seite auf eine Fairness-ID.
- Konfigurieren Sie das Dashboard, indem Sie das sensible Attribut, die Leistungsmetrik und die gewünschte Fairnessmetrik auswählen, um auf der Seite zur Fairnessbewertung zu landen.
- Wechseln Sie von einem Diagrammtyp zum anderen, um sowohl Schäden bei der Speicherbelegung als auch bei der Servicequalität zu beobachten.

- Bereich „Modelle“
- Wenn Sie Ihr ursprüngliches Modell mit den obigen Schritten registriert haben, können Sie im linken Bereich auf Modelle klicken, um es anzuzeigen.
- Klicken Sie auf ein Modell und dann auf die Registerkarte Fairness, um das Dashboard zur Erklärungsvisualisierung anzuzeigen.
Weitere Informationen zum Visualisierungsdashboard und den enthaltenen Funktionen finden Sie im Fairlearn-Benutzerhandbuch.


Hochladen von Erkenntnissen zur Fairness für mehrere Modelle
Um mehrere Modelle zu vergleichen und zu sehen, wie sich deren Fairnessbewertungen unterscheiden, können Sie mehrere Modelle an das Visualisierungsdashboard übergeben und ihre jeweiligen Kompromisse zwischen Leistung und Fairness vergleichen.
Trainieren Sie Ihre Modelle:
Erstellen Sie nun auf einem Support-Vector-Machine-Schätzer basierend einen zweiten Klassifizierer, und laden Sie mithilfe des Pakets
metricsvon Fairlearn ein Fairnessdashboard-Wörterbuch hoch. Wir gehen davon aus, dass das zuvor trainierte Modell weiterhin verfügbar ist.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Registrieren Sie Ihre Modelle.
Registrieren Sie als Nächstes beide Modelle in Azure Machine Learning. Speichern Sie die Ergebnisse zur Vereinfachung in einem Wörterbuch, das die
iddes registrierten Modells (Zeichenfolge im Formatname:version) dem Prädiktor selbst zuordnet:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorLaden Sie das Fairness-Dashboard lokal.
Bevor Sie die Erkenntnisse zur Fairness in Azure Machine Learning hochladen, können Sie die Vorhersagen in einem lokal aufgerufenen Fairness-Dashboard untersuchen.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Berechnen Sie die Fairnessmetriken im Voraus.
Erstellen Sie mit dem Paket
metricsvon Fairlearn ein Dashboardwörterbuch.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Laden Sie die im Voraus berechneten Fairnessmetriken hoch.
Importieren Sie nun das Paket
azureml.contrib.fairness, um den Upload auszuführen:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idErstellen Sie ein Experiment, dann eine Ausführung, und laden Sie das Dashboard dort hoch:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Wie im vorherigen Abschnitt können Sie auf eine der oben beschriebenen Arten (über Experimente oder Modelle) in Azure Machine Learning Studio auf das Visualisierungsdashboard zugreifen und die beiden Modelle hinsichtlich der Fairness und Leistung vergleichen.
Hochladen von nicht entschärften und entschärften Erkenntnissen zur Fairness
Sie können die Entschärfungsalgorithmen von Fairlearn verwenden, die von diesen generierten entschärften Modelle mit dem ursprünglichen, nicht entschärften Modell vergleichen und durch die jeweiligen Kompromisse zwischen Leistung und Fairness der verglichenen Modelle navigieren.
Ein Beispiel für die Verwendung des Rastersuche-Entschärfungsalgorithmus (der mehrere entschärfte Modelle mit unterschiedlichen Kompromissen zwischen Fairness und Leistung erstellt) finden Sie in diesem Beispielnotebook.
Das Hochladen von Erkenntnissen zur Fairness für mehrere Modelle in einer einzigen Ausführung ermöglicht einen Vergleich der Modelle in Bezug auf Fairness und Leistung. Sie können auf jedes der im Modellvergleichsdiagramm angezeigten Modelle klicken, um die Erkenntnisse zur Fairness des jeweiligen Modells im Detail anzuzeigen.

Nächste Schritte
Erfahren Sie mehr über Modellfairness.
Sehen Sie sich Azure Machine Learning-Beispielnotebooks zur Fairness an.