Verwalten von Eingaben und Ausgaben von Komponenten und Pipelines
In diesem Artikel wird Folgendes behandelt:
- Übersicht über Eingaben und Ausgaben in Komponenten und Pipelines
- Höherstufen von Komponenteneingaben/-ausgaben zu Pipelineeingaben/-ausgaben
- Definieren optionaler Eingaben
- Anpassen des Ausgabepfads
- Herunterladen von Ausgaben
- Registrieren von Ausgaben als benannte Ressource
Übersicht über Eingaben und Ausgaben
Azure Machine Learning-Pipelines unterstützen Eingaben und Ausgaben sowohl auf Komponenten- als auch auf Pipelineebene.
Auf Komponentenebene definieren die Ein- und Ausgaben die Schnittstelle einer Komponente. Die Ausgabe einer Komponente kann als Eingabe für eine andere Komponente in derselben übergeordneten Pipeline verwendet werden, sodass Daten oder Modelle zwischen Komponenten übergeben werden können. Diese Interkonnektivität bildet einen Graphen, der den Datenfluss innerhalb der Pipeline veranschaulicht.
Auf Pipelineebene sind Eingaben und Ausgaben nützlich, um Pipelineaufträge mit unterschiedlichen Dateneingaben oder Parametern zu übermitteln, die die Trainingslogik steuern (z. B learning_rate). Sie sind besonders nützlich, wenn sie die Pipeline über einen REST-Endpunkt aufrufen. Mit diesen Ein- und Ausgaben können Sie der Pipelineeingabe unterschiedliche Werte zuweisen oder über den REST-Endpunkt auf die Ausgabe von Pipelineaufträgen zugreifen. Weitere Informationen finden Sie unter Erstellen von Aufträgen und Eingabedaten für den Batchendpunkt.
Typen von Eingaben und Ausgaben
Die folgenden Typen werden als Ausgaben einer Komponente oder einer Pipeline unterstützt.
Datentypen Überprüfen Sie Datentypen in Azure Machine Learning, um mehr über Datentypen zu erfahren.
uri_fileuri_foldermltable
Modelltypen.
mlflow_modelcustom_model
Bei der Verwendung von Daten- oder Modellausgaben werden die Ausgaben im Wesentlichen serialisiert und als Dateien an einem Speicherort gespeichert. In nachfolgenden Schritten kann dieser Speicherort in das Computeziel-Dateisystem eingebunden, heruntergeladen oder hochgeladen werden, sodass der nächste Schritt während der Auftragsausführung auf die Dateien zugreifen kann.
Dieser Prozess erfordert, dass der Quellcode der Komponente das gewünschte Ausgabeobjekt – normalerweise im Arbeitsspeicher gespeichert – in Dateien serialisiert. Beispielsweise könnten Sie einen Pandas-Datenrahmen als CSV-Datei serialisieren. Beachten Sie, dass Azure Machine Learning keine standardisierten Methoden für die Objektserialisierung definiert. Als Benutzer haben Sie die Flexibilität, Ihre bevorzugte Methode zum Serialisieren von Objekten in Dateien auszuwählen. Danach können Sie in der nachgelagerten Komponente diese Dateien unabhängig deserialisieren und lesen. Hier sind einige Beispiele zu Ihrer Information:
- Im Beispiel nyc_taxi_data_regression verfügt die Vorbereitungskomponente über eine
uri_folder-Typausgabe. Im Quellcode der Komponente liest sie die CSV-Dateien aus dem Eingabeordner, verarbeitet die Dateien und schreibt verarbeitete CSV-Dateien in den Ausgabeordner. - Im Beispiel nyc_taxi_data_regression verfügt die Trainieren-Komponente über eine
mlflow_model-Typausgabe. Im Quellcode der Komponente wird das trainierte Modell mithilfe dermlflow.sklearn.save_model-Methode gespeichert.
Zusätzlich zu den obigen Daten- oder Modelltypen können Eingaben von Pipelines oder Komponenten auch primitiven Typen folgen.
stringnumberintegerboolean
Im Beispiel nyc_taxi_data_regression weist die Trainieren-Komponente eine number-Eingabe mit Namen test_split_ratio auf.
Hinweis
Die Ausgabe primitiver Typen wird nicht unterstützt.
Pfad und Modus für Dateneingaben/-ausgaben
Wenn Sie eine Datenressource erstellen, müssen Sie einen path-Parameter angeben, der auf den Speicherort der Daten verweist. In dieser Tabelle werden die verschiedenen in der Azure Machine Learning-Pipeline unterstützten Datenspeicherorte sowie Beispiele für den Path-Parameter aufgeführt:
| Standort | Beispiele | Eingabe | Ausgabe |
|---|---|---|---|
| Ein Pfad auf Ihrem lokalen Computer | ./home/username/data/my_data |
✓ | |
| Ein Pfad auf einem öffentlichen HTTP(S)-Server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
✓ | |
| Ein Pfad in Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Nicht empfohlen, da zum Lesen der Daten möglicherweise eine zusätzliche Identitätskonfiguration erforderlich ist. | |
| Ein Pfad in einem Azure Machine Learning-Datenspeicher | azureml://datastores/<data_store_name>/paths/<path> |
✓ | ✓ |
| Ein Pfad zu einer Datenressource | azureml:<my_data>:<version> |
✓ | ✓ |
Hinweis
Für die Eingabe/Ausgabe im Speicher wird dringend empfohlen, den Azure Machine Learning-Datenspeicherpfad anstelle des direkten Azure Storage-Pfads zu verwenden. Der Datenspeicherpfad wird für verschiedene Auftragstypen in der Pipeline unterstützt.
Für die Dateneingabe/-ausgabe können Sie aus verschiedenen Modi (herunterladen, einbinden oder hochladen) wählen, um zu definieren, wie auf die Daten im Computeziel zugegriffen wird. In der folgenden Tabelle sind die möglichen Modi für verschiedene Kombinationen von Typ, Modus, Eingabe und Ausgabe aufgeführt.
| Typ | Eingabe/Ausgabe | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Eingabe | ✓ | ✓ | ✓ | ||||
uri_file |
Eingabe | ✓ | ✓ | ✓ | ||||
mltable |
Eingabe | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Ausgabe | ✓ | ✓ | |||||
uri_file |
Ausgabe | ✓ | ✓ | |||||
mltable |
Ausgabe | ✓ | ✓ | ✓ |
Hinweis
In den meisten Fällen empfehlen wir die Verwendung des ro_mount- oder rw_mount-Modus. Weitere Informationen zum Modus finden Sie unter Datenressourcenmodi.
Visuelle Darstellung in Azure Machine Learning Studio
Die folgenden Screenshots enthalten ein Beispiel dafür, wie Eingaben und Ausgaben in einem Pipelineauftrag in Azure Machine Learning Studio angezeigt werden. Dieser spezielle Auftrag mit dem Namen nyc-taxi-data-regressionfinden Sie in azureml-example.
Auf der Seite „Pipelineauftrag“ von Studio werden die Eingaben/Ausgaben von Daten-/Modelltypen einer Komponente als kleine Kreise in der entsprechenden Komponente angezeigt, was als Input/Output-Port bekannt ist. Diese Ports stellen den Datenfluss in einer Pipeline dar.
Die Ausgabe auf Pipelineebene wird zur einfachen Identifizierung als violettes Feld angezeigt.

Wenn Sie mit der Maus auf einen Eingabe-/Ausgabeport zeigen, wird der Typ angezeigt.

Die Eingaben des primitiven Typs werden im Diagramm nicht angezeigt. Sie finden sie auf der Registerkarte Einstellungen des Übersichtsbereichs für Pipelineaufträge (für Eingaben auf Pipelineebene) oder im Komponentenbereich (für Eingaben auf Komponentenebene). Der folgende Screenshot zeigt die Registerkarte Einstellungen eines Pipelineauftrags, der durch Auswählen des Links Auftragsübersicht geöffnet werden kann.
Wenn Sie die Eingaben für eine Komponente überprüfen möchten, doppelklicken Sie auf die Komponente, um den Komponentenbereich zu öffnen.

Ebenso finden Sie beim Bearbeiten einer Pipeline im Designer die Eingaben und Ausgaben der Pipeline im Bereich Pipelineschnittstelle und die Komponenteneingaben und -ausgaben im Bereich der Komponente (Auslösung durch Doppelklicken auf die Komponente).

Höherstufen von Komponenteneingaben und -ausgaben auf Pipelineebene
Durch Höherstufen der Eingabe/Ausgabe einer Komponente auf Pipelineebene können Sie die Eingabe/Ausgabe der Komponente beim Übermitteln eines Pipelineauftrags überschreiben. Dies ist auch nützlich, wenn Sie die Pipeline mithilfe des REST-Endpunkts auslösen möchten.
Im Folgenden werden Beispiele zum Heraufstufen von Komponenteneingaben/-ausgaben zu Ein-/Ausgaben auf Pipelineebene aufgeführt.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Das vollständige Beispiel finden Sie unter train-score-eval-Pipeline mit registrierten Komponenten. Diese Pipeline stuft drei Eingaben und drei Ausgaben auf Pipelineebene hoch. Nehmen wir pipeline_job_training_max_epocs als Beispiel. Sie wird unter dem Abschnitt inputs auf Stammebene deklariert, d. h., es handelt sich um eine Eingabe auf Pipelineebene. Im jobs -> train_job Abschnitt wird auf die Eingabe mit dem Namen max_epocs als ${{parent.inputs.pipeline_job_training_max_epocs}} verwiesen, was angibt, dass max_epocs, die Eingabe von train_job, auf die Eingabe pipeline_job_training_max_epocs auf Pipelineebene verweist. Ebenso können Sie die Pipelineausgabe anhand desselben Schemas heraufstufen.
Studio
Sie können die Komponenteneingabe in die Eingabe auf Pipelineebene auf der Designererstellungsseite heraufstufen. Navigieren Sie zum Einstellungsbereich der Komponente, indem Sie auf die Komponente doppelklicken. -> Suchen Sie die Eingabe, die Sie höherstufen möchten. -> Wählen Sie die drei Punkte auf der rechten Seite aus. -> Wählen Sie „Zur Pipelineeingabe hinzufügen“ aus.

Optionale Eingabe
Standardmäßig sind alle Eingaben erforderlich und müssen jedes Mal, wenn Sie einen Pipelineauftrag übermitteln, mit einem Wert (oder einem Standardwert) versehen werden. Es kann jedoch vorkommen, dass Sie optionale Eingaben benötigen. In solchen Fällen haben Sie die Flexibilität, der Eingabe beim Übermitteln eines Pipelineauftrags keinen Wert zuzuweisen.
Optionale Eingaben können in den folgenden zwei Szenarios nützlich sein:
Wenn Sie über eine optionale Daten- bzw. Modelltypeingabe verfügen und ihr beim Übermitteln des Pipelineauftrags keinen Wert zuweisen, gibt es eine Komponente in der Pipeline, der eine vorherige Datenabhängigkeit fehlt. Anders ausgedrückt: Der Eingabeport ist nicht mit einer Komponente oder einem Daten- bzw. Modellknoten verknüpft. Dies bewirkt, dass der Pipelinedienst diese Komponente direkt aufruft, anstatt darauf zu warten, dass die vorherige Abhängigkeit bereit ist.
Der folgende Screenshot enthält ein deutliches Beispiel für das zweite Szenario. Wenn Sie
continue_on_step_failure = Truefür die Pipeline festlegen und über einen zweiten Knoten (node2) verfügen, der die Ausgabe des ersten Knotens (node1) als optionale Eingabe verwendet, wird „node2“ auch dann ausgeführt, wenn „node1“ fehlschlägt. Wenn „node2“ jedoch die erforderliche Eingabe von „node1“ verwendet, wird sie nicht ausgeführt, wenn „node1“ fehlschlägt.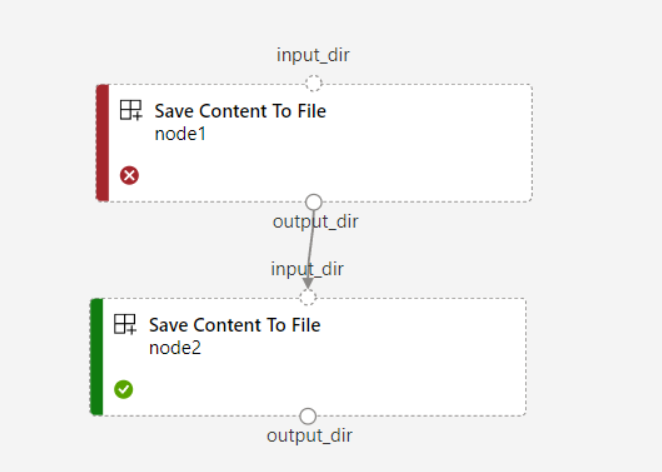

Im Folgenden finden Sie Beispiele zum Definieren optionaler Eingaben.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
version: 9
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}
Wenn die Eingabe als optional = true festgelegt ist, müssen Sie $[[]] verwenden, um die Befehlszeile mit Eingaben zu nutzen. Siehe hervorgehobene Zeile im obigen Beispiel.
Hinweis
Die optionale Ausgabe wird nicht unterstützt.
Im Pipelinediagramm werden optionale Eingaben des Datenmodelltyps durch einen gepunkteten Kreis dargestellt. Optionale Eingaben primitiver Typen finden Sie auf der Registerkarte Einstellungen. Im Gegensatz zu erforderlichen Eingaben enthalten optionale Eingaben kein Sternchen neben ihnen, was bedeutet, dass sie nicht obligatorisch sind.

Anpassen des Ausgabepfads
Standardmäßig wird die Ausgabe einer Komponente in azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}} gespeichert. Der {default_datastore} ist der Standarddatenspeicher, der vom Kunden für die Pipeline festgelegt ist. Wenn nicht festgelegt, handelt es sich um arbeitsbereichsbasierten Blobspeicher. {name} ist der Auftragsname, der zum Zeitpunkt der Auftragsausführung aufgelöst wird. {output_name} ist der Ausgabename, der vom Kunden in der YAML-Komponente definiert wird.
Sie können aber auch anpassen, wo die Ausgabe gespeichert werden soll, indem Sie den Pfad einer Ausgabe definieren. Im Folgenden finden Sie Beispiele:
pipeline.yaml definiert eine Pipeline mit drei Ausgaben auf Pipelineebene. Die vollständige YAML finden Sie im Beispiel train-score-eval-Pipeline mit registrierten Komponenten.
Sie können den folgenden Befehl verwenden, um den benutzerdefinierten Ausgabepfad für die pipeline_job_trained_model-Ausgabe festzulegen.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path
Herunterladen der Ausgabe
Sie können die Ausgabe einer Komponente oder einer Pipeline wie im folgenden Beispiel beschrieben herunterladen.
Herunterladen der Ausgabe auf Pipelineebene
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
Herunterladen der Ausgabe des untergeordneten Auftrags
Wenn Sie die Ausgabe eines untergeordneten Auftrags herunterladen müssen (eine Komponentenausgabe, die nicht auf Pipelineebene heraufgestuft ist), sollten Sie zunächst alle untergeordneten Auftragsentitäten eines Pipelineauftrags auflisten und dann ähnlichen Code verwenden, um die Ausgabe herunterzuladen.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select needed child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
Registrieren von Ausgaben als benannte Ressource
Sie können die Ausgabe einer Komponente oder Pipeline als benannte Ressource registrieren, indem Sie der Ausgabe name und version zuweisen. Die registrierte Ressource kann in Ihrem Arbeitsbereich über Studio UI/CLI/SDK aufgelistet und auch in zukünftigen Aufträgen referenziert werden.
Registrieren der Pipelineausgabe
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Registrieren der Ausgabe eines untergeordneten Auftrags
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster