Ausführen von Batchvorhersagen mit dem Azure Machine Learning-Designer
In diesem Artikel erfahren Sie, wie Sie den Designer zum Erstellen einer Batchvorhersagepipeline verwenden können. Mithilfe der Batchvorhersage können Sie kontinuierlich große Datasets bei Bedarf mit einem Webdienst bewerten, der von jeder HTTP-Bibliothek ausgelöst werden kann.
In dieser Anleitung erfahren Sie, wie Sie die folgenden Aufgaben ausführen:
- Erstellen und Veröffentlichen einer Batchrückschlusspipeline
- Nutzen eines Pipelineendpunkts
- Verwalten von Endpunktversionen
Informationen zum Einrichten von Batchbewertungsdiensten mit dem SDK finden Sie in dem begleitenden Tutorial zur Pipelinebatchbewertung.
Voraussetzungen
Diese Anleitung geht davon aus, dass Sie bereits über eine Trainingspipeline verfügen. Eine Einführung in den Designer finden Sie im ersten Teil des Designer-Tutorials.
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
Erstellen einer Batchrückschlusspipeline
Zum Erstellen einer Rückschlusspipeline muss Ihre Trainingspipeline mindestens einmal ausgeführt werden.
Wechseln Sie zur Registerkarte Designer in Ihrem Arbeitsbereich.
Wählen Sie die Trainingspipeline aus, mit der das Modell trainiert wird, mit dem Sie eine Vorhersage treffen möchten.
Übermitteln der Pipeline
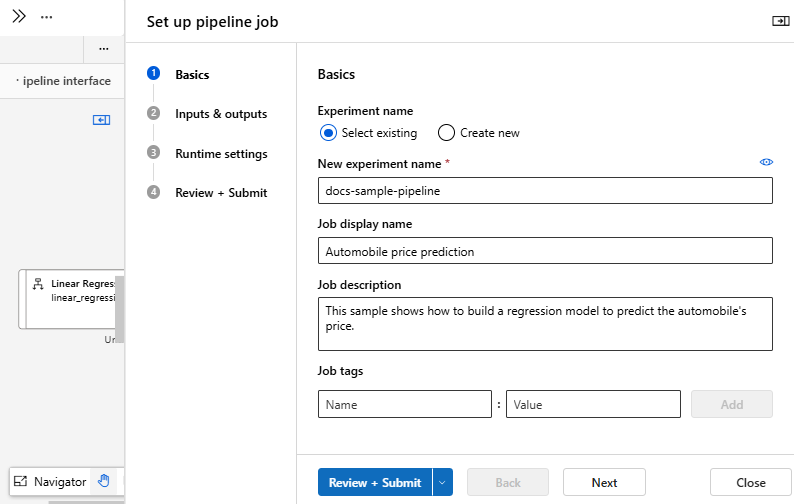

Auf der linken Seite der Canvas sehen Sie eine Übermittlungsliste. Sie können den Link zu den Auftragsdetails auswählen, um zur Detailseite des Auftrags zu wechseln. Nach Abschluss des Trainingspipelineauftrags können Sie eine Batchrückschlusspipeline erstellen.

Wählen Sie auf der Seite mit den Auftragsdetails oberhalb der Canvas die Dropdownliste Rückschlusspipeline erstellen aus. Wählen Sie Batchrückschlusspipeline aus.
Hinweis
Derzeit funktioniert die automatische Generierung einer Rückschlusspipeline nur für Trainingspipelines, die ausschließlich mit den im Designer integrierten Komponenten erstellt wurde.
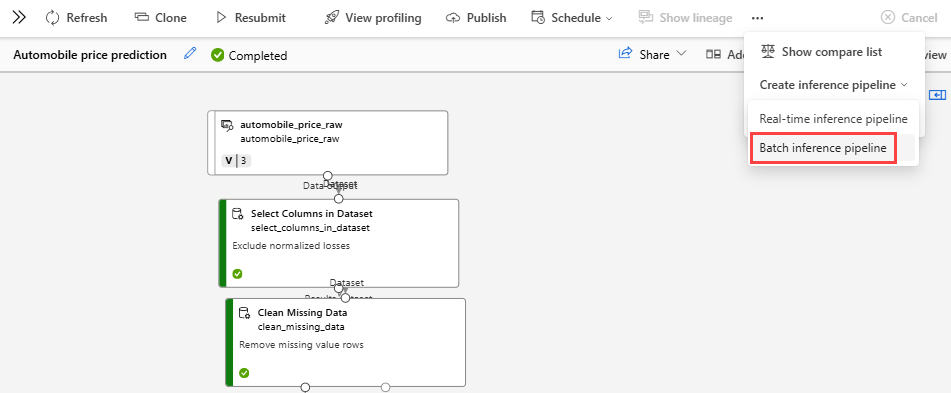
Dabei wird der Entwurf einer Batchrückschlusspipeline für Sie erstellt. Der Entwurf einer Batchrückschlusspipeline verwendet das trainierte Modell als MD-Knoten und Transformation als TD-Knoten aus dem Trainingspipelineauftrag.
Sie können diesen Entwurf der Rückschlusspipeline auch ändern, um Ihre Eingabedaten für den Batchrückschluss besser zu verarbeiten.
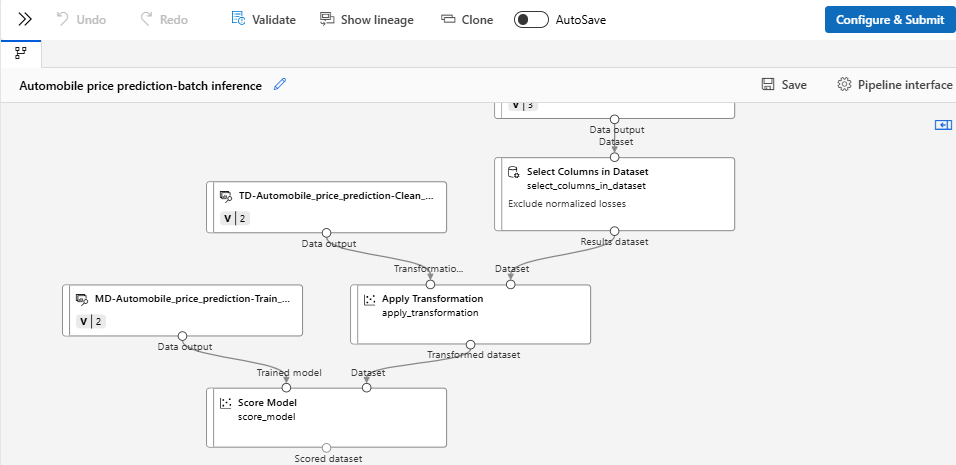


Hinzufügen eines Pipelineparameters
Um Vorhersagen für neue Daten zu erstellen, können Sie entweder manuell ein anderes Dataset in dieser Pipelineentwurfsansicht verbinden oder einen Parameter für Ihr Dataset erstellen. Mit Parametern können Sie das Verhalten des Batchrückschlussprozesses zur Laufzeit ändern.
In diesem Abschnitt erstellen Sie einen Datasetparameter, um ein anderes Dataset anzugeben, für das Vorhersagen gemacht werden sollen.
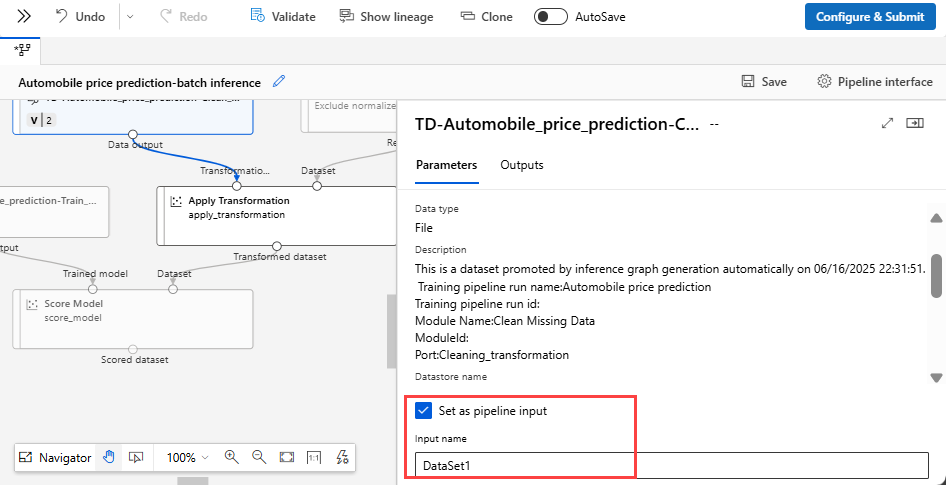
Wählen Sie die Dataset-Komponente aus.
Rechts neben der Canvas wird ein Bereich angezeigt. Wählen Sie am unteren Rand des Bereichs die Option Als Pipelineparameter festlegen aus.
Geben Sie einen Namen für den Parameter ein, oder akzeptieren Sie den Standardwert.
Übermitteln Sie die Batchrückschlusspipeline, und wechseln Sie zur Detailseite des Auftrags, indem Sie den Auftragslink im linken Bereich auswählen.

Veröffentlichen Ihrer Batchrückschlusspipeline
Jetzt sind Sie bereit, die Rückschlusspipeline bereitzustellen. Dadurch wird die Pipeline bereitgestellt und anderen zur Nutzung zur Verfügung gestellt.
Wählen Sie die Schaltfläche Veröffentlichen aus.
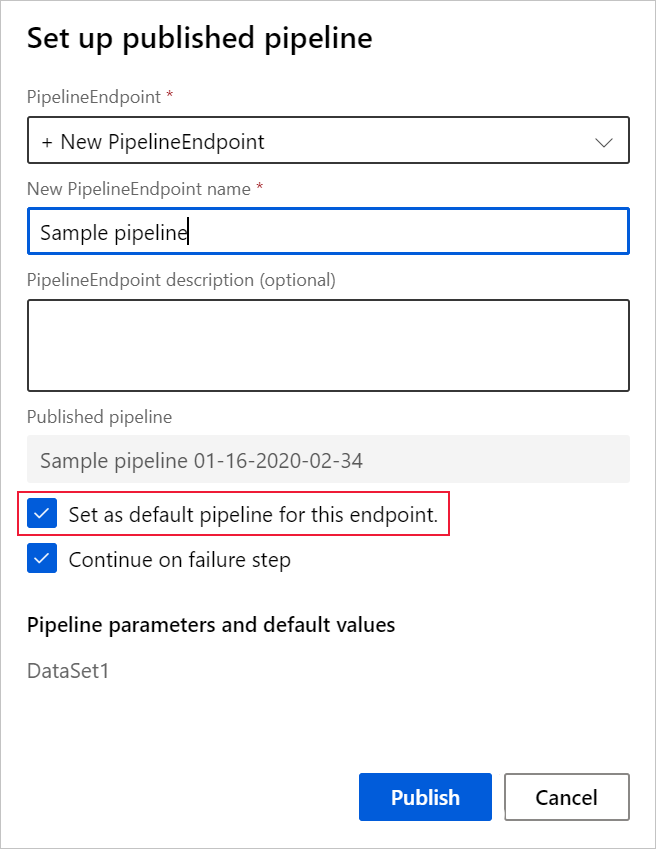
Erweitern Sie im angezeigten Dialogfeld die Dropdownliste für PipelineEndpoint, und wählen Sie Neuer PipelineEndpoint aus.
Geben Sie einen Endpunktnamen und eine optionale Beschreibung an.
Unten im Dialogfeld wird der von Ihnen konfigurierte Parameter mit einem Standardwert der während des Trainings verwendeten Datensatz-ID angezeigt.
Wählen Sie Veröffentlichen.

Nutzen eines Endpunkts
Jetzt verfügen Sie über eine veröffentlichte Pipeline mit einem Datasetparameter. Die Pipeline verwendet das trainierte Modell, das in der Trainingspipeline erstellt wurde, um das von Ihnen als Parameter bereitgestellte Dataset zu bewerten.
Übermitteln eines Pipelineauftrags
In diesem Abschnitt richten Sie einen manuellen Pipelineauftrag ein und ändern den Pipelineparameter, um neue Daten zu bewerten.
Nachdem die Bereitstellung abgeschlossen ist, wechseln Sie zum Abschnitt Endpunkte.
Wählen Sie Pipelineendpunkte aus.
Wählen Sie den Namen des von Ihnen erstellten Endpunkts aus.
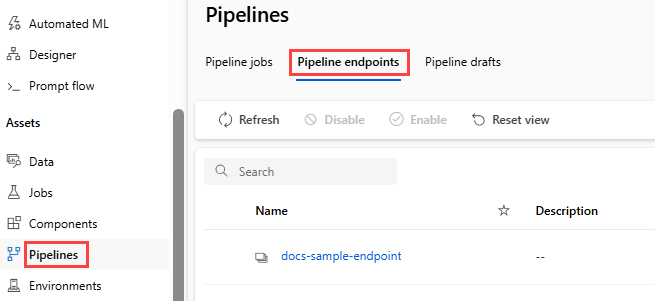
Wählen Sie Veröffentlichte Pipelines aus.
Auf diesem Bildschirm werden alle unter diesem Endpunkt veröffentlichten Pipelines angezeigt.
Wählen Sie die veröffentlichte Pipeline aus.
Auf der Seite mit den Pipelinedetails finden Sie ausführliche Informationen zum Auftragsverlauf und zur Verbindungszeichenfolge für die Pipeline.
Wählen Sie Übermitteln aus, um eine manuelle Ausführung der Pipeline zu erstellen.
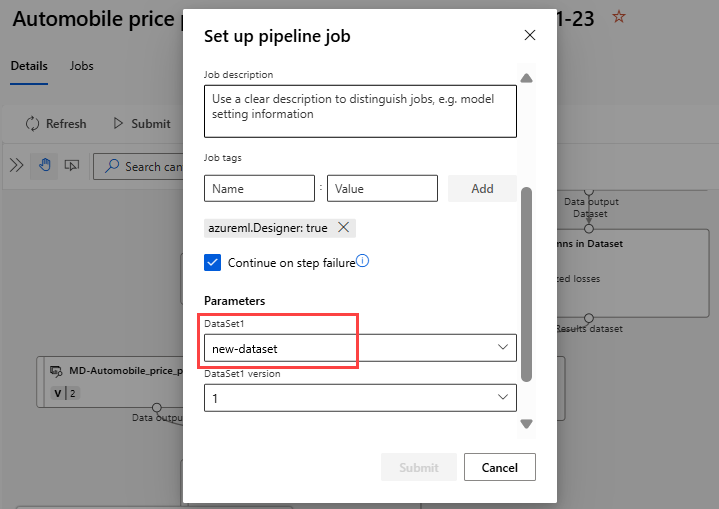
Ändern Sie den Parameter, um ein anderes Dataset zu verwenden.
Wählen Sie Übermitteln aus, um die Pipeline auszuführen.

Verwenden des REST-Endpunkts
Informationen zur Verwendung von Pipelineendpunkten und der veröffentlichten Pipeline finden Sie im Abschnitt Endpunkte.
Den REST-Endpunkt eines Pipelineendpunkts finden Sie im Bereich der Auftragsübersicht. Wenn Sie den Endpunkt aufrufen, nutzen Sie seine standardmäßig veröffentlichte Pipeline.
Sie können eine veröffentlichte Pipeline auch auf der Seite Veröffentlichte Pipelines nutzen. Wenn Sie eine veröffentlichte Pipeline auswählen, finden Sie den REST-Endpunkt der Pipeline im Panel zur Übersicht über die veröffentliche Pipeline rechts neben dem Diagramm.
Um einen REST-Aufruf auszuführen, benötigen Sie einen OAuth 2.0-Authentifizierungsheader vom Typ „Bearer“. Weitere Informationen zum Einrichten der Authentifizierung für Ihren Arbeitsbereich und zum Erstellen eines parametrisierten REST-Aufrufes finden Sie im folgenden Tutorialabschnitt.
Versionsverwaltungsendpunkte
Der Designer ordnet jeder nachfolgenden Pipeline, die Sie an einem Endpunkt veröffentlichen, eine Version zu. Sie können die auszuführende Pipelineversion als Parameter in Ihrem REST-Aufruf angeben. Wenn Sie keine Versionsnummer angeben, wird der Designer die Standardpipeline verwenden.
Wenn Sie eine Pipeline veröffentlichen, können Sie auswählen, dass sie zur neuen Standardpipeline für diesen Endpunkt wird.
Sie können auch eine neue Standardpipeline auf der Registerkarte Veröffentlichte Pipelines Ihres Endpunkts festlegen.
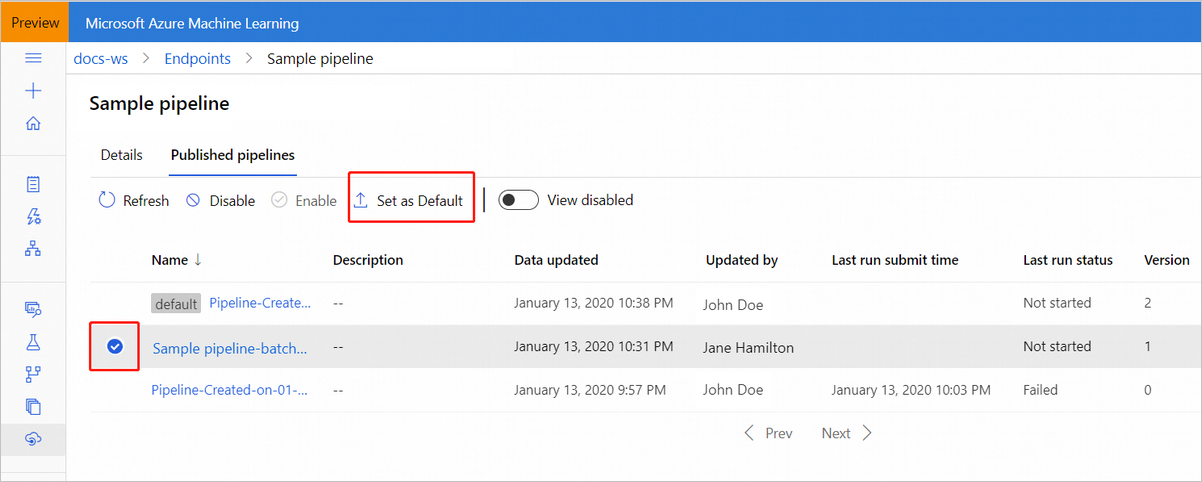
Aktualisieren des Pipelineendpunkts
Wenn Sie Änderungen an Ihrer Trainingspipeline vornehmen, sollten Sie das neu trainierte Modell auf den Pipelineendpunkt aktualisieren.
Nachdem Ihre geänderte Trainingspipeline erfolgreich abgeschlossen wurde, wechseln Sie zur Detailseite des Auftrags.
Klicken Sie mit der rechten Maustaste auf die Komponente Modell trainieren, und wählen Sie Daten registrieren aus.
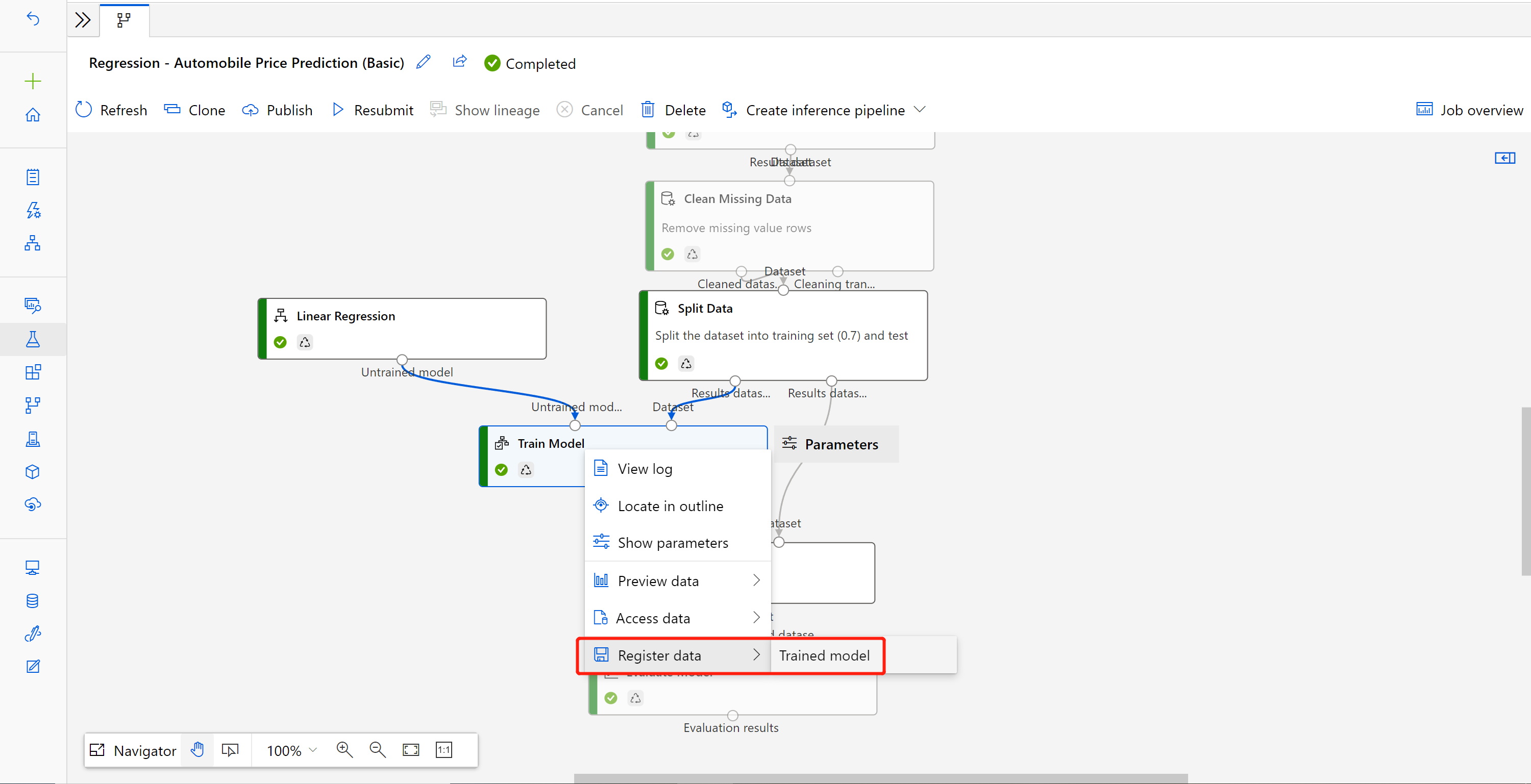
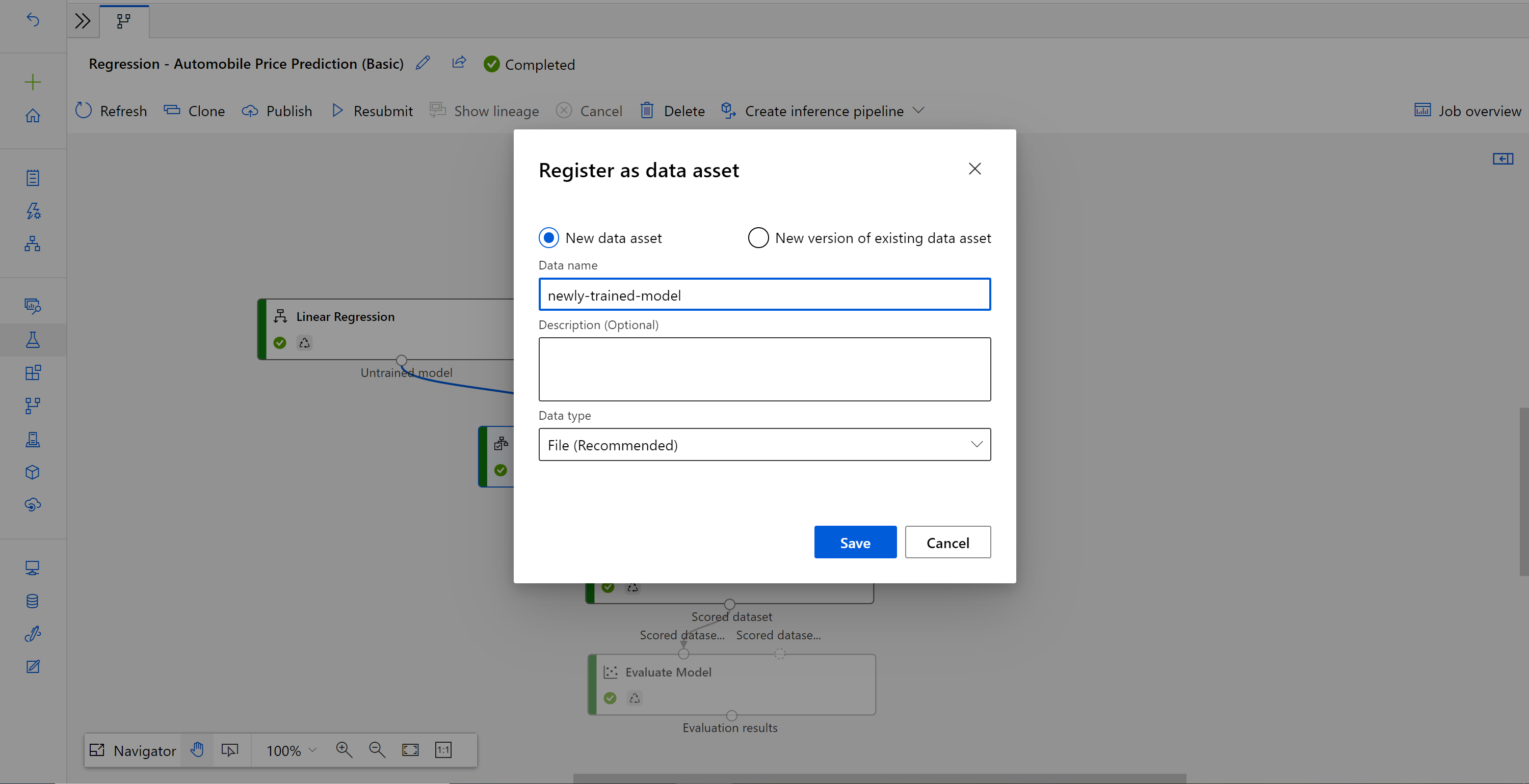
Geben Sie den Namen ein, und wählen Sie den Typ Datei aus.
Suchen Sie den vorherigen Entwurf der Batchrückschlusspipeline, oder Sie können auch einfach die veröffentlichte Pipeline in einen neuen Entwurf klonen.
Ersetzen Sie den MD-Knoten im Entwurf der Rückschlusspipeline durch die registrierten Daten aus dem obigen Schritt.
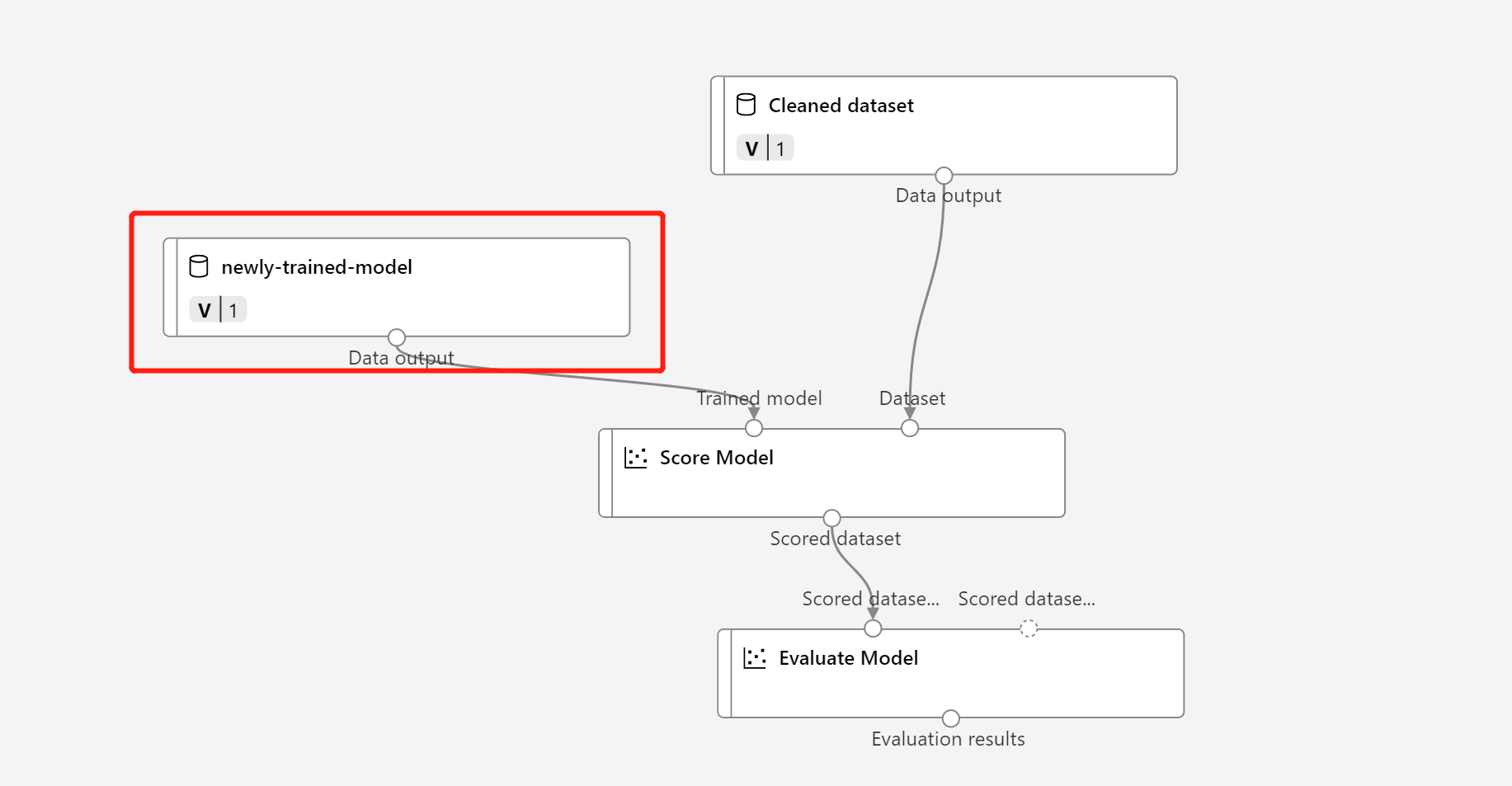
Das Aktualisieren des Datentransformationsknotens TD- ist dasselbe wie das trainierte Modell.
Anschließend können Sie die Rückschlusspipeline mit dem aktualisierten Modell und der aktualisierten Transformation übermitteln und erneut veröffentlichen.


Nächste Schritte
- Zum Trainieren und Bereitstellen eines Regressionsmodells befolgen Sie die Schritte im Designer-Tutorial.
- Informationen zum Veröffentlichen und Ausführen einer veröffentlichten Pipeline mit dem SDK v1 finden Sie in dem Artikel Bereitstellen von Pipelines.