Tutorial: Trainieren und Bereitstellen eines Bildklassifizierungsmodells mit einer Jupyter Notebook-Beispielinstanz
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Tutorial wird ein Modell für maschinelles Lernen auf Remotecomputeressourcen trainiert. Sie verwenden den Trainings- und Bereitstellungsworkflow für Azure Machine Learning in einer Python Jupyter Notebook-Instanz. Anschließend können Sie das Notebook als Vorlage verwenden, um Ihr eigenes Machine Learning-Modell mit Ihren eigenen Daten zu trainieren.
In diesem Tutorial wird eine einfache logistische Regression anhand des MNIST-Datasets und scikit-learn mit Azure Machine Learning trainiert. MNIST ist ein populäres Dataset, das aus 70.000 Graustufenbildern besteht. Jedes Bild ist eine handgeschriebene Ziffer von null bis neun im Format von 28 × 28 Pixeln. Das Ziel besteht darin, einen Multiklassen-Klassifizierer zu erstellen, um die in einem bestimmten Bild dargestellte Ziffer zu erkennen.
Erfahren Sie, wie Sie die folgenden Maßnahmen durchführen:
- Laden Sie ein Dataset herunter, und sehen Sie sich die Daten an.
- Trainieren Sie ein Bildklassifizierungsmodell, und protokollieren Sie Metriken mithilfe von MLflow.
- Stellen Sie das Modell zur Durchführung von Echtzeitrückschlüssen bereit.
Voraussetzungen
- Arbeiten Sie Schnellstart: Erste Schritte mit Azure Machine Learning durch, um Folgendes durchzuführen:
- Erstellen eines Arbeitsbereichs.
- Erstellen einer cloudbasierten Compute-Instanz, die für Ihre Entwicklungsumgebung verwendet werden soll
Ausführen eines Notebooks aus Ihrem Arbeitsbereich
Azure Machine Learning enthält einen cloudbasierten Notebook-Server in Ihrem Arbeitsbereich als vorkonfigurierte Umgebung ohne Installation. Verwenden Sie Ihre eigene Umgebung, wenn Sie Ihre Umgebung, Pakete und Abhängigkeiten lieber selbst gestalten möchten.
Klonen eines Notebook-Ordners
Sie führen die folgenden Schritte zum Einrichten und Ausführen des Experiments in Azure Machine Learning Studio aus. Diese konsolidierte Benutzeroberfläche umfasst Tools für maschinelles Lernen zur Durchführung von Data Science-Szenarien für Datenwissenschaftler aller Qualifikationsstufen.
Melden Sie sich bei Azure Machine Learning Studio an.
Wählen Sie Ihr Abonnement und den erstellten Arbeitsbereich aus.
Wählen Sie links Notebooks aus.
Wählen Sie oben die Registerkarte Beispiele aus.
Öffnen Sie den Ordner SDK v1.
Wählen Sie rechts vom Ordner Tutorials die Auslassungspunkte ( ... ) und anschließend Klonen aus.
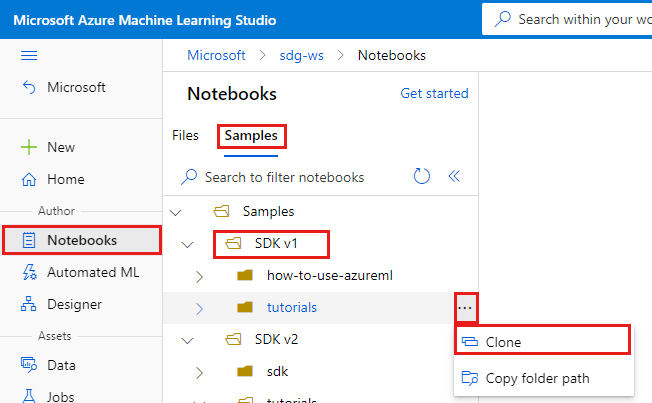
Eine Liste der Ordner mit den einzelnen Benutzern wird angezeigt, die auf den Arbeitsbereich zugreifen. Wählen Sie Ihren Ordner aus, um den Ordner tutorials dort zu klonen.
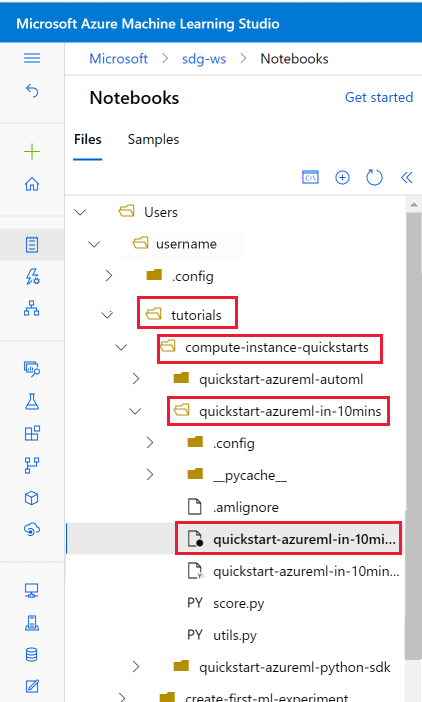
Öffnen des geklonten Notebooks
Öffnen Sie den Ordner tutorials, den Sie im Abschnitt Benutzerdateien geklont haben.
Wählen Sie die Datei quickstart-azureml-in-10mins.ipynb aus Ihrem Ordner tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins aus.
Installieren von Paketen
Sobald die Computeinstanz ausgeführt und der Kernel angezeigt wird, fügen Sie eine neue Codezelle hinzu, um Pakete zu installieren, die für dieses Tutorial erforderlich sind.
Fügen Sie oben im Notizbuch eine Codezelle hinzu.
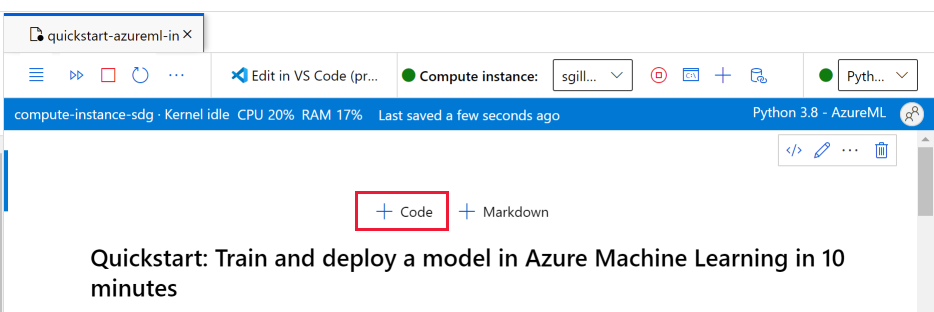
Fügen Sie die folgende Funktion in die Zelle ein, und führen Sie die Zelle dann entweder mithilfe des Tools Ausführen oder mithilfe von UMSCHALT+EINGABETASTE aus.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Möglicherweise werden einige Installationswarnungen angezeigt. Diese können ignoriert werden.
Ausführen des Notebooks
Dieses Tutorial und die zugehörige Datei utils.py sind auch auf GitHub verfügbar, falls Sie sie in Ihrer eigenen lokalen Umgebung verwenden möchten. Wenn Sie die Computeinstanz nicht verwenden, fügen Sie der obigen Installation %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib hinzu.
Wichtig
Der Rest dieses Artikels enthält denselben Inhalt, den Sie auch im Notebook sehen.
Wechseln Sie jetzt zum Jupyter Notebook, wenn Sie den Code beim Weiterlesen ausführen möchten. Klicken Sie zum Ausführen einer einzelnen Codezelle in einem Notebook auf die gewünschte Codezelle, und drücken Sie UMSCHALT+EINGABE. Oder führen Sie das gesamte Notebook aus, indem Sie auf der oberen Symbolleiste Alle ausführen auswählen.
Daten importieren
Bevor Sie ein Modell trainieren, müssen Sie die Daten verstehen, die zum Trainieren verwendet werden. In diesem Abschnitt lernen Sie Folgendes:
- Laden des MNIST-Datasets
- Anzeigen einiger Beispielbilder
Sie verwenden Azure Open Datasets, um die unformatierten MNIST-Datendateien abzurufen. Azure Open Datasets sind kuratierte öffentliche Datasets, die Sie verwenden können, um szenariospezifische Features zu Machine Learning-Lösungen hinzuzufügen, um bessere Modelle zu erhalten. Jedes Dataset verfügt über eine entsprechende Klasse (hier MNIST), um die Daten auf unterschiedliche Weise abzurufen.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Werfen Sie einen Blick auf die Daten:
Laden Sie die komprimierten Dateien in numpy-Arrays. Verwenden Sie dann matplotlib, um 30 zufällige Bilder aus dem Dataset mit den zugehörigen Bezeichnungen darüber zu zeichnen.
Für diesen Schritt ist eine load_data-Funktion erforderlich, die in einer Datei utils.py enthalten ist. Diese Datei befindet sich in demselben Ordner wie dieses Notebook. Die load_data-Funktion analysiert einfach die komprimierten Dateien in NumPy-Arrays.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Der Code zeigt eine zufällige Reihe von Bildern mit ihren Bezeichnungen an, ähnlich wie hier:

Trainieren von Modell- und Protokollmetriken mit MLflow
Trainieren Sie das Modell mit dem folgenden Code. Dieser Code verwendet die automatische Protokollierung von MLflow, um Metriken nachzuverfolgen und Modellartefakte zu protokollieren.
Sie verwenden den LogisticRegression-Klassifizierer aus dem SciKit-learn-Framework, um die Daten zu klassifizieren.
Hinweis
Das Training des Modells dauert etwa zwei Minuten.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Anzeigen des Experiments
Wählen Sie im linken Menü von Azure Machine Learning Studio Aufträge und dann Ihren Auftrag (azure-ml-in10-mins-tutorial) aus. Ein Auftrag ist eine Gruppierung von vielen Ausführungen eines bestimmten Skripts oder Codes. Mehrere Aufträge können zu einem Experiment gruppiert werden.
Die Informationen für die Ausführung werden unter diesem Auftrag gespeichert. Wenn der Name beim Übermitteln eines Auftrags nicht vorhanden ist, werden verschiedene Registerkarten mit Metriken, Protokollen, Erklärungen usw. angezeigt, wenn Sie Ihre Ausführung auswählen.
Versionskontrolle für Ihre Modelle mit der Modellregistrierung
Sie können die Modellregistrierung verwenden, um Ihre Modelle in Ihrem Arbeitsbereich zu speichern und in die Versionsverwaltung aufzunehmen. Registrierte Modelle werden anhand des Namens und der Version identifiziert. Jedes Mal, wenn Sie ein Modell mit dem gleichen Namen wie ein bereits vorhandenes Modell registrieren, erhöht die Registrierung die Versionsnummer. Der folgende Code registriert das Modell, das Sie oben trainiert haben, und nimmt es in die Versionsverwaltung auf. Sobald Sie die folgende Codezelle ausgeführt haben, können Sie das Modell in der Registrierung sehen, indem Sie im linken Menü von Azure Machine Learning Studio die Option Modelle auswählen.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Bereitstellen des Modells für Echtzeitrückschlüsse
In diesem Abschnitt erfahren Sie, wie Sie ein Modell bereitstellen, sodass eine Anwendung das Modell über REST nutzen kann (Rückschluss).
Erstellen der Bereitstellungskonfiguration
Die Codezelle erhält eine kuratierte Umgebung, in der alle Abhängigkeiten angegeben sind, die für das Hosten des Modells erforderlich sind (z. B. die Pakete wie Scikit-learn). Außerdem erstellen Sie eine Bereitstellungskonfiguration, die die Computekapazität angibt, die zum Hosten des Modells erforderlich ist. In diesem Fall verfügt die Compute-Instanz über 1 CPU und 1 GB Speicher.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Bereitstellen des Modells
In dieser nächsten Codezelle wird das Modell in Azure Container Instances bereitgestellt.
Hinweis
Es dauert ungefähr drei Minuten, bis diese Bereitstellung abgeschlossen ist. Aber es kann länger dauern, bis sie zur Verfügung steht, vielleicht sogar bis zu 15 Minuten.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Die Bewertungsskriptdatei, auf die im vorangegangenen Code verwiesen wird, befindet sich im selben Ordner wie dieses Notizbuch und hat zwei Funktionen:
- Eine
init-Funktion, die einmal ausgeführt wird, wenn der Dienst gestartet wird. In dieser Funktion erhalten Sie normalerweise das Modell aus der Registrierung und legen globale Variablen fest. - Eine
run(data)-Funktion, die bei jedem Aufruf des Diensts ausgeführt wird. In dieser Funktion formatieren Sie normalerweise die Eingabedaten, führen eine Vorhersage aus und geben das vorhergesagte Ergebnis aus.
Anzeigen des Endpunkts
Sobald das Modell erfolgreich bereitgestellt ist, können Sie den Endpunkt anzeigen, indem Sie im linken Menü von Azure Machine Learning Studio zu Endpunkte navigieren. Sie sehen den Zustand des Endpunkts (fehlerfrei/fehlerhaft), die Protokolle und die Nutzung (wie Anwendungen das Modell nutzen können).
Testen des Modelldiensts
Sie können das Modell testen, indem Sie eine unformatierte HTTP-Anforderung zum Testen des Webdiensts senden.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Bereinigen von Ressourcen
Wenn Sie dieses Modell nicht mehr verwenden möchten, löschen Sie den Modelldienst wie folgt:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Wenn Sie die Kosten weiter kontrollieren möchten, beenden Sie die Compute-Instanz, indem Sie die Schaltfläche „Computer-Instanz beenden“ neben der Dropdownliste Compute auswählen. Starten Sie dann die Compute-Instanz erneut, wenn Sie sie das nächste Mal benötigen.
Alles löschen
Verwenden Sie diese Schritte, um Ihren Azure Machine Learning-Arbeitsbereich und alle Computeressourcen zu löschen.
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
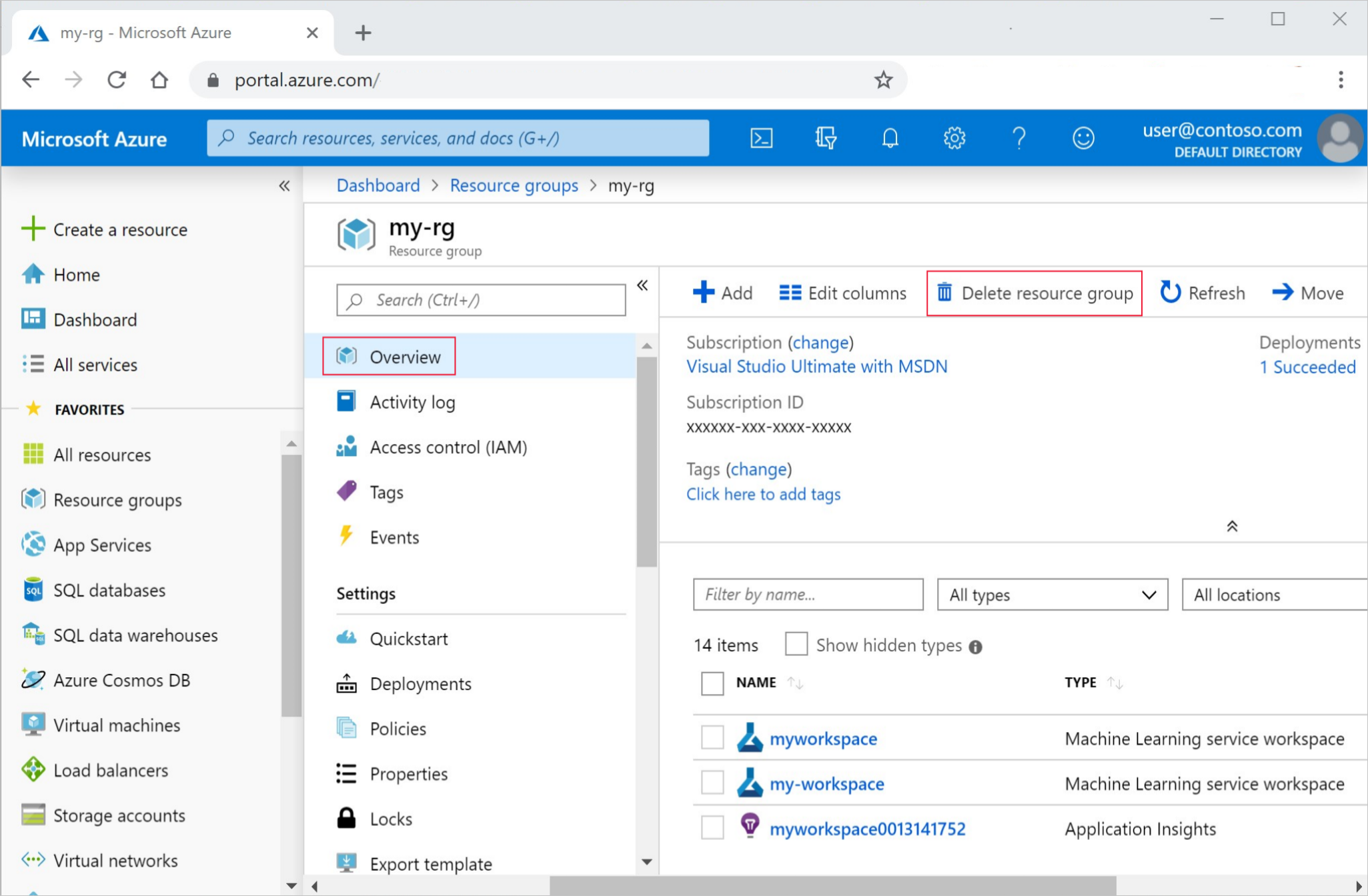
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.
Zugehörige Ressourcen
- Weitere Informationen zu den Bereitstellungsoptionen für Azure Machine Learning finden Sie hier.
- Erfahren Sie, wie Sie sich bei dem bereitgestellten Modell authentifizieren können.
- Treffen Sie asynchron Vorhersagen für große Datenmengen.
- Überwachen Sie Ihre Azure Machine Learning-Modelle mit Application Insights.