Datenerfassung mit Azure Data Factory
In diesem Artikel erfahren Sie, welche Optionen für das Erstellen einer Datenerfassungspipeline mit Azure Data Factory verfügbar sind. Diese Azure Data Factory-Pipeline wird für die Erfassung von Daten zur Verwendung mit Azure Machine Learning verwendet. Mit Data Factory können Sie auf einfache Weise Daten extrahieren, transformieren und laden (ETL). Nachdem die Daten transformiert und in den Speicher geladen wurden, können sie zum Trainieren Ihrer Machine Learning-Modelle in Azure Machine Learning verwendet werden.
Die einfache Datentransformation kann mit nativen Data Factory-Aktivitäten und -Verfahren, z. B. Datenfluss, durchgeführt werden. Bei komplizierteren Szenarien können die Daten mit etwas benutzerdefiniertem Code verarbeitet werden. Beispiel: Python- oder R-Code.
Vergleichen von Pipelines für die Azure Data Factory-Datenerfassung
Es gibt verschiedene gängige Verfahren, um die Daten während der Erfassung mit Data Factory zu transformieren. Jedes Verfahren hat Vor- und Nachteile, anhand derer festgestellt werden kann, ob sie für einen bestimmten Anwendungsfall geeignet ist:
| Verfahren | Vorteile | Nachteile |
|---|---|---|
| Data Factory und Azure Functions | Nur geeignet für die Verarbeitung kurzzeitiger Prozesse | |
| Data Factory und benutzerdefinierte Komponente | ||
| Data Factory und Azure Databricks-Notebook |
Azure Data Factory mit Azure Functions
Azure Functions ermöglicht das Ausführen kleiner Codeelemente (Funktionen), ohne sich Gedanken über die Anwendungsinfrastruktur machen zu müssen. Bei dieser Option werden die Daten mit benutzerdefiniertem Python-Code verarbeitet, der von einer Azure-Funktion umschlossen ist.
Die Funktion wird mit der Aktivität „Azure Function“ in Azure Data Factory aufgerufen. Dieser Ansatz ist eine gute Option für leichte Datentransformationen.
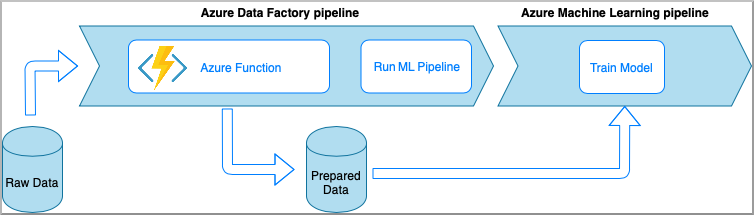
- Vorteile:
- Die Daten werden auf einem serverlosen Compute mit einer relativ niedrigen Wartezeit verarbeitet
- Die Data Factory-Pipeline kann eine Durable Azure Function aufrufen, die einen komplexen Datentransformationsfluss implementieren kann
- Die Details der Datentransformation werden durch die Azure-Funktion abstrahiert, die wiederverwendet und von anderen Stellen aus aufgerufen werden kann
- Nachteile:
- Azure Functions muss vor der Verwendung mit ADF erstellt werden
- Azure Functions ist nur für die kurzzeitige Datenverarbeitung geeignet
Azure Data Factory mit Aktivität vom Typ „Benutzerdefinierte Komponente“
Bei dieser Option werden die Daten mit benutzerdefiniertem Python-Code verarbeitet, der von einer ausführbaren Datei umschlossen ist. Sie wird mit einer Azure Data Factory-Aktivität für benutzerdefinierte Komponenten aufgerufen. Dieser Ansatz eignet sich besser für große Datenmengen als das vorherige Verfahren.
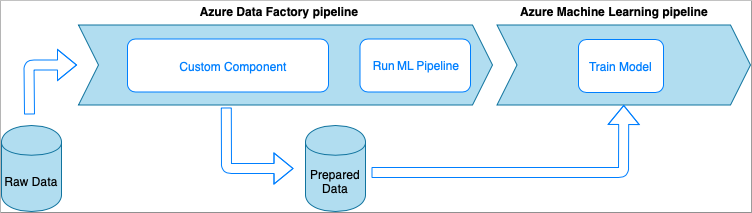
- Vorteile:
- Die Daten werden im Azure Batch-Pool verarbeitet, der paralleles und leistungsstarkes Computing in großem Umfang ermöglicht
- Kann zum Ausführen komplexer Algorithmen und zur Verarbeitung großer Datenmengen verwendet werden
- Nachteile:
- Der Azure Batch-Pool muss vor der Verwendung mit Data Factory erstellt werden
- Übermäßige Entwicklung hinsichtlich der Umschließung von Python-Code in einer ausführbaren Datei. Komplexität der Verarbeitung von Abhängigkeiten und Eingabe-/Ausgabeparametern
Azure Data Factory mit Azure Databricks-Python-Notebook
Azure Databricks ist eine Apache Spark-basierte Analyseplattform in der Microsoft-Cloud.
Bei diesem Verfahren wird die Datentransformation von einem Python-Notebook ausgeführt, das in einem Azure Databricks-Cluster ausgeführt wird. Dies ist wahrscheinlich der häufigste Ansatz, der die volle Leistung eines Azure Databricks-Diensts nutzt. Es ist für die verteilte Datenverarbeitung in großem Maßstab konzipiert.
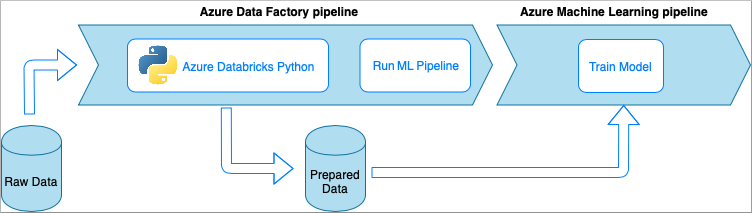
- Vorteile:
- Die Daten werden über den leistungsfähigsten Azure-Dienst für die Datenverarbeitung transformiert, der von der Apache Spark-Umgebung unterstützt wird
- Native Unterstützung von Python zusammen mit Data Science-Frameworks und Bibliotheken wie TensorFlow, PyTorch und scikit-learn
- Der Python-Code muss nicht in Funktionen oder ausführbare Module verpackt werden. Der Code funktioniert so, wie er ist.
- Nachteile:
- Die Azure Databricks-Infrastruktur muss vor der Verwendung mit Data Factory erstellt werden
- Kann je nach Azure Databricks-Konfiguration teuer sein
- Das Hochfahren von Computeclustern aus dem „kalten“ Modus dauert einige Zeit, was eine hohe Wartezeit für die Lösung bedeutet
Nutzen von Daten in Azure Machine Learning
Die Data Factory-Pipeline speichert die vorbereiteten Daten in Ihrem Cloudspeicher (z. B. Azure Blob oder Azure Data Lake).
Nutzen Sie Ihre aufbereiteten Daten in Azure Machine Learning wie folgt:
- Aufrufen einer Azure Machine Learning-Pipeline aus Ihrer Data Factory-Pipeline
OR - Erstellen eines Azure Machine Learning-Datenspeichers.
Aufrufen einer Azure Machine Learning-Pipeline aus Data Factory
Diese Methode wird für Workflows mit Machine Learning-Vorgängen (MLOps) empfohlen. Falls Sie keine Azure Machine Learning-Pipeline einrichten möchten, helfen Ihnen die Informationen unter Direktes Lesen von Daten aus dem Speicher weiter.
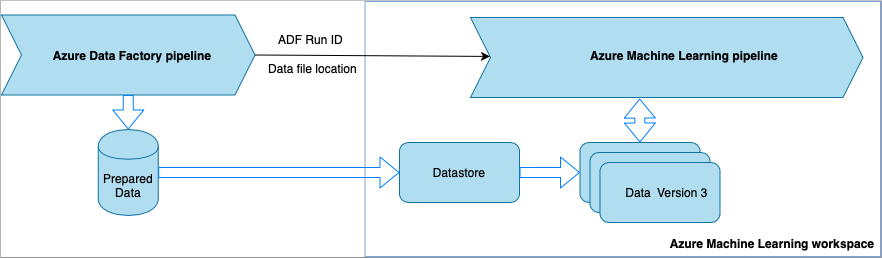
Bei jeder Ausführung der Data Factory-Pipeline passiert Folgendes:
- Die Daten werden an einem anderen Ort im Speicher gespeichert.
- Um den Speicherort an Azure Machine Learning zu übergeben, ruft die Data Factory-Pipeline eine Azure Machine Learning-Pipeline auf. Beim Aufruf der ML-Pipeline werden der Datenspeicherort und die Auftrags-ID als Parameter gesendet.
- Die ML-Pipeline kann dann einen Azure Machine Learning-Datenspeicher und ein Dataset mit dem Speicherort der Daten erstellen. Weitere Informationen finden Sie unter Ausführen von Azure Machine Learning-Pipelines in Azure Data Factory-Pipelines.
Tipp
Datasets unterstützen die Versionsverwaltung, sodass die ML-Pipeline eine neue Version des Datasets registrieren kann, die auf die neuesten Daten aus der ADF-Pipeline verweist.
Sobald die Daten über einen Datenspeicher oder ein Dataset zugänglich sind, können Sie sie zum Trainieren eines Machine Learning-Modells verwenden. Der Trainingsprozess könnte Teil derselben ML-Pipeline sein, die von ADF aufgerufen wird. Oder es könnte ein separater Prozess sein, z. B. ein Experiment in einem Jupyter Notebook.
Da Datasets die Versionsverwaltung unterstützen und jeder Auftrag der Pipeline eine neue Version erzeugt, ist es leicht zu erkennen, welche Version der Daten zum Trainieren eines Modells verwendet wurde.
Direktes Lesen von Daten aus dem Speicher
Wenn Sie keine ML-Pipeline erstellen möchten, können Sie direkt über das Speicherkonto auf die Daten zugreifen, in dem Ihre vorbereiteten Daten mit einem Azure Machine Learning-Datenspeicher und -Dataset gespeichert sind.
Der folgende Python-Code veranschaulicht, wie Sie einen Datenspeicher erstellen, der über eine Verbindung mit Azure Data Lake Gen2-Speicher verfügt. Lesen Sie die Informationen zu Datenspeichern und zur Ermittlung der Berechtigungen für Dienstprinzipale.
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Erstellen Sie als Nächstes ein Dataset zum Verweisen auf die Dateien, die Sie in Ihrer Aufgabe für maschinelles Lernen verwenden möchten.
Mit dem folgenden Code wird ein TabularDataset-Element aus der CSV-Datei prepared-data.csv erstellt. Erfahren Sie mehr zu Datasettypen und akzeptierten Dateiformaten.
GILT FÜR:Python SDK azureml v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
Verwenden Sie ab jetzt prepared_dataset, um auf Ihre aufbereiteten Daten zu verweisen, z. B. in Ihren Trainingsskripts. Informieren Sie sich über das Trainieren von Modellen mit Datasets in Azure Machine Learning.