Failover für Business Continuity & Disaster Recovery
Planen Sie zum Maximieren der Betriebszeit voraus, um die Geschäftskontinuität aufrechtzuerhalten und die Notfallwiederherstellung mit Azure Machine Learning vorzubereiten.
Microsoft möcht sicherstellen, dass Azure-Dienste immer verfügbar sind. Es kann jedoch zu ungeplanten Dienstausfällen kommen. Es wird empfohlen, einen Notfallwiederherstellungsplan für die Behandlung regionaler Dienstausfälle zu erstellen. In diesem Artikel lernen Sie Folgendes:
- Planen Sie eine sich auf mehrere Regionen erstreckende Bereitstellung von Azure Machine Learning und zugehörigen Ressourcen.
- Maximieren Sie die Chancen, Protokolle, Notebooks, Docker-Images und andere Metadaten wiederherzustellen.
- Erstellen Sie einen Entwurf für die Hochverfügbarkeit Ihrer Lösung.
- Initiieren Sie ein Failover in eine andere Region.
Wichtig
Azure Machine Learning selbst bietet kein automatisches Failover bzw. keine automatische Notfallwiederherstellung. Sicherung und Wiederherstellung von Metadaten des Arbeitsbereichs, z. B. des Ausführungsverlaufs, sind nicht verfügbar.
Falls Sie Ihren Arbeitsbereich oder die entsprechenden Komponenten versehentlich gelöscht haben, enthält dieser Artikel auch die derzeit unterstützten Wiederherstellungsoptionen.
Grundlegendes zu Azure-Diensten für Azure Machine Learning
Azure Machine Learning ist von mehreren Azure-Diensten abhängig. Einige dieser Dienste werden in Ihrem Abonnement bereitgestellt. Sie sind für die Hochverfügbarkeitskonfiguration dieser Dienste verantwortlich. Andere Dienste werden in einem Microsoft-Abonnement erstellt und von Microsoft verwaltet.
Die Azure-Dienste umfassen Folgendes:
Azure Machine Learning-Infrastruktur: Eine von Microsoft verwaltete Umgebung für den Azure Machine Learning-Arbeitsbereich.
Zugeordnete Ressourcen: Ressourcen, die während der Erstellung des Azure Machine Learning-Arbeitsbereichs in Ihrem Abonnement bereitgestellt werden. Zu diesen Ressourcen zählen Azure Storage, Azure Key Vault, Azure Container Registry (ACR) und Application Insights.
- Standardspeicher enthält Daten wie etwa Modelle, Trainingsprotokolldaten und Datasets.
- Key Vault enthält Anmeldeinformationen für Azure Storage, Container Registry und Datenspeicher.
- Container Registry enthält ein Docker-Image für die Trainings- und Rückschlussumgebungen.
- Application Insights dient zum Überwachen von Azure Machine Learning.
Computeressourcen: Ressourcen, die Sie nach der Bereitstellung des Arbeitsbereichs erstellen. Beispielsweise können Sie eine Compute-Instanz oder einen Computecluster erstellen, um ein Machine Learning-Modell zu trainieren.
- Compute-Instanz und Computecluster: Von Microsoft verwaltete Umgebungen für die Modellentwicklung.
- Weitere Ressourcen: Microsoft Computeressourcen, die an Azure Machine Learning angefügt werden können, z. B. Azure Kubernetes Service (AKS), Azure Databricks, Azure Container Instances und Azure HDInsight. Sie sind für das Konfigurieren von Hochverfügbarkeitseinstellungen für diese Ressourcen verantwortlich.
Weitere Datenspeicher: Azure Machine Learning kann für Trainingsdaten weitere Datenspeicher einbinden, z. B. Azure Storage, Azure Data Lake Storage und Azure SQL-Datenbank. Diese Datenspeicher werden in Ihrem Abonnement bereitgestellt. Sie sind für das Konfigurieren ihrer Hochverfügbarkeitseinstellungen verantwortlich.
Die folgende Tabelle zeigt, welche Azure-Dienste von Microsoft und welche von Ihnen verwaltet werden. Außerdem werden die Dienste angegeben, die standardmäßig hoch verfügbar sind.
| Dienst | Verwaltet von | Hochverfügbarkeit standardmäßig |
|---|---|---|
| Azure Machine Learning-Infrastruktur | Microsoft | |
| Zugeordnete Ressourcen | ||
| Azure Storage | Sie | |
| Key Vault | Sie | ✓ |
| Container Registry | Sie | |
| Application Insights | Sie | Nicht verfügbar |
| Computeressourcen | ||
| Compute-Instanz | Microsoft | |
| Computecluster | Microsoft | |
| Andere Computeressourcen, z. B. AKS, Azure Databricks, Container Instances, HDInsight |
Sie | |
| Andere Datenspeicher wie Azure Storage, SQL-Datenbank, Azure Database for PostgreSQL und Azure Database for MySQL und Azure Databricks File System |
Sie |
Im weiteren Verlauf dieses Artikels werden die Aktionen beschrieben, die Sie durchführen müssen, damit die einzelnen Dienste hochverfügbar werden.
Planen der Bereitstellung in mehreren Regionen
Eine Bereitstellung in mehreren Regionen basiert auf der Erstellung von Azure Machine Learning-Ressourcen und anderen Ressourcen (Infrastruktur) in zwei Azure-Regionen. Wenn ein regionaler Ausfall auftritt, können Sie zur anderen Region wechseln. Beachten Sie bei der Planung des Bereitstellungsorts für Ihre Ressourcen Folgendes:
Regionale Verfügbarkeit: Verwenden Sie Regionen, die sich in der Nähe der Benutzer befinden. Informationen zur regionalen Verfügbarkeit für Azure Machine Learning finden Sie unter Azure-Produkte nach Region.
Azure-Regionspaare: Regionspaare koordinieren Plattformupdates und priorisieren bei Bedarf Wiederherstellungsvorgänge. Weitere Informationen finden Sie unter Azure-Regionspaare.
Dienstverfügbarkeit: Entscheiden Sie, ob die von Ihrer Lösung verwendeten Ressourcen Zugriffsebenen der Varianten heiß/heiß, heiß/warm oder heiß/kalt aufweisen sollen.
- Heiß/heiß: Beide Regionen sind gleichzeitig aktiv, und in einer Region kann die Verwendung sofort beginnen.
- Heiß/warm: Die primäre Region ist aktiv, die sekundäre Region verfügt über wichtige Ressourcen (z. B. bereitgestellte Modelle), die startbereit sind. Weniger wichtige Ressourcen müssten manuell in der sekundären Region bereitgestellt werden.
- Heiß/kalt: Die primäre Region ist aktiv, in der sekundären Region sind Azure Machine Learning-Ressourcen und andere Ressourcen sowie die erforderlichen Daten bereitgestellt. Ressourcen wie Modelle, Modellimplementierungen oder Pipelines müssten manuell bereitgestellt werden.
Tipp
Abhängig von Ihren Geschäftsanforderungen können Sie verschiedene Azure Machine Learning-Ressourcen jeweils unterschiedlich behandeln. Beispielsweise empfiehlt es sich gegebenenfalls, die Zugriffsebenenvariante heiß/heiß für bereitgestellte Modelle (Rückschluss) und die Variante heiß/kalt für Experimente (Training) zu verwenden.
Azure Machine Learning baut auf weiteren Diensten auf. Einige Dienste können für die Replikation in andere Regionen konfiguriert werden. Andere müssen Sie manuell in mehreren Regionen erstellen. Die folgende Tabelle enthält eine Liste der Dienste, den jeweiligen Replikationsverantwortlichen sowie eine Übersicht über die jeweilige Konfiguration:
| Azure-Dienst | Georeplikation durch | Konfiguration |
|---|---|---|
| Machine Learning-Arbeitsbereich | Sie | Erstellen Sie einen Arbeitsbereich in den ausgewählten Regionen. |
| Machine Learning Compute | Sie | Erstellen Sie die Computeressourcen in den ausgewählten Regionen. Stellen Sie für Computeressourcen, die dynamisch skaliert werden können, sicher, dass beide Regionen ein ausreichendes Computekontingent für Ihre Anforderungen bereitstellen. |
| Key Vault | Microsoft | Verwenden Sie dieselbe Key Vault-Instanz mit dem Azure Machine Learning-Arbeitsbereich und den Ressourcen in beiden Regionen. Von Key Vault wird ein automatisches Failover in eine sekundäre Region ausgeführt. Weitere Informationen finden Sie unter Azure Key Vault: Verfügbarkeit und Redundanz. |
| Container Registry | Microsoft | Konfigurieren Sie die Container Registry-Instanz für die Georeplikation von Registrierungen in die jeweilige Region des Regionspaars für Azure Machine Learning. Verwenden Sie dieselbe Instanz für beide Arbeitsbereichsinstanzen. Weitere Informationen finden Sie unter Georeplikation in Azure Container Registry. |
| Speicherkonto | Sie | Azure Machine Learning unterstützt kein Failover des Standardspeicherkontos mit georedundantem Speicher (GRS), geozonenredundantem Speicher (GZRS), georedundantem Speicher mit Lesezugriff (RA-GRS) oder geozonenredundantem Speicher mit Lesezugriff (RA-GZRS). Erstellen Sie ein separates Speicherkonto für den Standardspeicher jedes Arbeitsbereichs. Erstellen Sie separate Speicherkonten oder Dienste für andere Datenspeicher. Weitere Informationen finden Sie unter Azure Storage-Redundanz. |
| Application Insights | Sie | Erstellen Sie Application Insights für den Arbeitsbereich in beiden Regionen. Wenn Sie den Aufbewahrungszeitraum der Daten und Details anpassen möchten, lesen Sie Datenerfassung, -aufbewahrung und -speicherung in Application Insights. |
Damit eine schnelle Wiederherstellung und ein Neustart in der sekundären Region möglich sind, empfehlen sich die folgenden Entwicklungsmethoden:
- Verwenden Sie Azure Resource Manager-Vorlagen. Vorlagen sind „Infrastructure-as-Code“ und ermöglichen Ihnen die schnelle Bereitstellung von Diensten in beiden Regionen.
- Aktualisieren Sie die Continuous Integration- und Bereitstellungspipelines für die Bereitstellung in beiden Regionen, um Drift zwischen den beiden Regionen zu vermeiden.
- Beziehen Sie beim Automatisieren von Bereitstellungen die Konfiguration der an den Arbeitsbereich angeschlossenen Computeressourcen ein, z. B. Azure Kubernetes Service.
- Erstellen Sie Rollenzuweisungen für Benutzer in beiden Regionen.
- Erstellen Sie Netzwerkressourcen wie Azure Virtual Networks und private Endpunkte für beide Regionen. Stellen Sie sicher, dass Benutzer Zugriff auf beide Netzwerkumgebungen haben. Beispielsweise VPN- und DNS-Konfigurationen für beide virtuellen Netzwerke.
Compute- und Datendienste
Je nach Ihren Anforderungen verfügen Sie möglicherweise über mehrere Compute- oder Datendienste, die von Azure Machine Learning verwendet werden. Beispielsweise könnten Sie Azure Kubernetes Services oder die Azure SQL-Datenbank verwenden. Verwenden Sie die folgenden Informationen, um zu erfahren, wie Sie diese Dienste für Hochverfügbarkeit konfigurieren.
Computeressourcen
- Azure Kubernetes Service: Siehe Best Practices für Geschäftskontinuität und Notfallwiederherstellung in Azure Kubernetes Service (AKS) und Erstellen eines Azure Kubernetes Service-Clusters (AKS), der Verfügbarkeitszonen verwendet. Wenn der AKS-Cluster mit Azure Machine Learning Studio, dem SDK oder der CLI erstellt wurde, wird regionsübergreifende Hochverfügbarkeit nicht unterstützt.
- Azure Databricks: Siehe Regionale Notfallwiederherstellung für Azure Databricks-Cluster.
- Container Instances: Ein ACI-Orchestrator ist für Failover verantwortlich. Siehe Azure Container Instances und Containerorchestratoren.
- HDInsight: Siehe Von Azure HDInsight unterstützte Hochverfügbarkeitsdienste.
Datendienste:
- Azure-Blobcontainer/Azure Files/Data Lake Storage Gen2: Siehe Azure Storage-Redundanz.
- Data Lake Storage Gen1: Weitere Informationen finden Sie im Leitfaden zu Hochverfügbarkeit und Notfallwiederherstellung für Data Lake Storage Gen1.
- SQL-Datenbank: Weitere Informationen finden Sie unterHochverfügbarkeit für Azure SQL-Datenbank und SQL Managed Instance.
- Azure Database for PostgreSQL: Siehe Hochverfügbarkeitskonzepte von Azure Database for PostgreSQL – Einzelserver.
- Azure Database for MySQL: Siehe Informationen zur Geschäftskontinuität in Azure Database for MySQL.
- Azure Databricks File System: Siehe Regionale Notfallwiederherstellung für Azure Databricks-Cluster.
Tipp
Wenn Sie Ihren eigenen kundenseitig verwalteten Schlüssel zum Bereitstellen des Azure Machine Learning-Arbeitsbereichs angeben, wird Azure Cosmos DB ebenfalls in Ihrem Abonnement bereitgestellt. In diesem Fall sind Sie für das Konfigurieren der Hochverfügbarkeitseinstellungen verantwortlich. Siehe Hochverfügbarkeit mit Azure Cosmos DB.
Entwurf für Hochverfügbarkeit
Bereitstellen wichtiger Komponenten in mehreren Regionen
Bestimmen Sie den Grad an Geschäftskontinuität, den Sie erreichen möchten. Der Grad kann sich zwischen den Komponenten Ihrer Lösung unterscheiden. Beispielsweise könnten Sie sich für eine Zugriffsebenenkonfiguration vom Typ „heiß/heiß“ für Produktionspipelines oder Modellimplementierungen und eine Zugriffsebenenkonfiguration vom Typ „heiß/kalt“ für Experimente entscheiden.
Verwalten von Trainingsdaten im isolierten Speicher
Indem Sie den Datenspeicher von dem Standardspeicher trennen, der vom Arbeitsbereich für Protokolle verwendet wird, können Sie:
- Dieselben Speicherinstanzen als Datenspeicher an den primären und den sekundären Arbeitsbereich anschließen
- Georeplikation für Datenspeicherkonten nutzen und die Betriebszeit maximieren
Verwalten von Machine Learning-Ressourcen als Code
Hinweis
Sicherung und Wiederherstellung von Arbeitsbereichsmetadaten wie Ausführungsverlauf, Modellen und Umgebungen ist nicht verfügbar. Die Angabe von Ressourcen und Konfigurationen als Code mithilfe von YAML-Spezifikationen hilft Ihnen, Ressourcen in verschiedenen Arbeitsbereichen im Falle eines Notfalls neu zu erstellen.
Aufträge in Azure Machine Learning werden durch eine Auftragsspezifikation definiert. Diese Spezifikation umfasst Abhängigkeiten von Eingabeartefakten, die auf Arbeitsbereichsinstanzebene verwaltet werden, einschließlich Umgebungen, Datasets und Compute. Für die Übermittlung und Bereitstellung von Aufträgen in mehreren Regionen empfehlen sich die folgenden Methoden:
Verwalten Sie die Codebasis lokal, unterstützt durch ein Git-Repository.
Exportieren Sie wichtige Notebooks aus Azure Machine Learning Studio.
Exportieren Sie Pipelines, die in Studio als Code erstellt wurden.
Hinweis
Pipelines, die im Studio-Designer erstellt wurden, können derzeit nicht als Code exportiert werden.
Verwalten Sie Konfigurationen als Code.
- Vermeiden Sie hartcodierte Verweise auf den Arbeitsbereich. Konfigurieren Sie stattdessen mithilfe einer Konfigurationsdatei einen Verweis auf die Arbeitsbereichsinstanz, und verwenden Sie Workspace.from_config(), um den Arbeitsbereich zu initialisieren. Verwenden Sie zum Automatisieren des Prozesses den Befehl az ml folder attach der Azure CLI-Erweiterung für Azure Machine Learning.
- Verwenden Sie Hilfsprogramme für die Auftragsübermittlung, z. B. ScriptRunConfig und Pipeline.
- Verwenden Sie Environments.save_to_directory(), um die Umgebungsdefinitionen zu speichern.
- Verwenden Sie ein Dockerfile, wenn Sie benutzerdefinierte Docker-Images verwenden.
- Verwenden Sie die Datasetklasse, um die Sammlung von Datenpfaden zu definieren, die von der Lösung verwendet werden.
- Verwenden Sie die Inferenceconfig-Klasse, um Modelle als Rückschlussendpunkte bereitzustellen.
Initiieren eines Failovers
Fortsetzen der Arbeit im Failoverarbeitsbereich
Wenn der primäre Arbeitsbereich nicht mehr verfügbar ist, können Sie zum sekundären Arbeitsbereich wechseln, um mit dem Experimentieren und der Entwicklung fortzufahren. Aufträge werden von Azure Machine Learning nicht automatisch an den sekundären Arbeitsbereich gesendet, wenn ein Ausfall vorliegt. Aktualisieren Sie die Codekonfiguration so, dass sie auf die neue Arbeitsbereichsressource verweist. Es wird empfohlen, die Hartcodierung von Arbeitsbereichsverweisen zu vermeiden. Verwenden Sie stattdessen eine Arbeitsbereichskonfigurationsdatei, um manuelle Benutzerschritte beim Ändern von Arbeitsbereichen zu minimieren. Stellen Sie außerdem sicher, dass Sie alle Automatisierungen aktualisieren, z. B. Continuous Integration- und Bereitstellungspipelines zum neuen Arbeitsbereich.
Artefakte oder Metadaten können von Azure Machine Learning nicht zwischen Arbeitsbereichsinstanzen synchronisiert oder wiederhergestellt werden. Abhängig von Ihrer Strategie für die Anwendungsbereitstellung müssen Sie möglicherweise Artefakte verschieben oder Eingaben zum Experimentieren, z. B. Datasetobjekte, im Failoverarbeitsbereich neu erstellen, um die Auftragsübermittlung fortzusetzen. Falls Sie die Ressourcen des primären und des sekundären Arbeitsbereichs so konfiguriert haben, dass zugeordnete Ressourcen mit aktivierter Georeplikation freigegeben werden, sind einige Objekte möglicherweise direkt für den Failoverarbeitsbereich verfügbar. Dies gilt beispielsweise, wenn in beiden Arbeitsbereichen dieselben Docker-Images, konfigurierten Datenspeicher und Azure Key Vault-Ressourcen gemeinsam genutzt werden. Die folgende Abbildung zeigt eine Konfiguration, bei der in zwei Arbeitsbereichen dieselben Images (1), Datenspeicher (2) und derselbe Key Vault (3) gemeinsam genutzt werden.
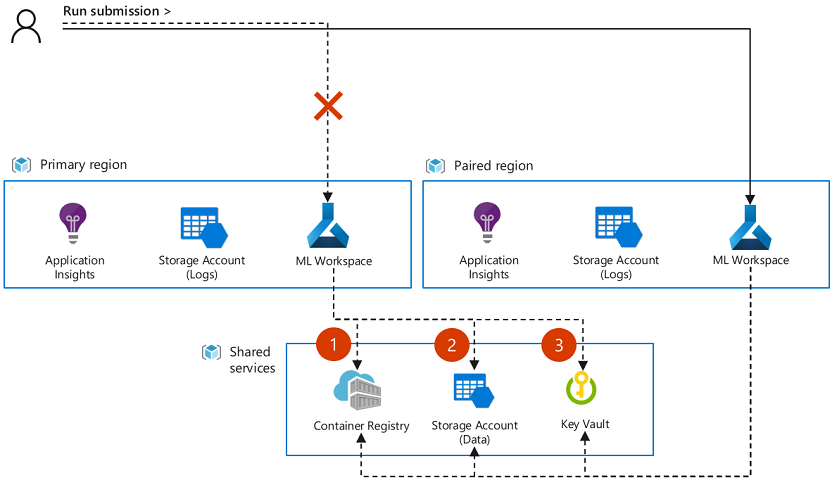
Hinweis
Aufträge, die ausgeführt werden, wenn ein Dienstausfall auftritt, werden nicht automatisch in den sekundären Arbeitsbereich überführt. Es ist auch unwahrscheinlich, dass die Aufträge im primären Arbeitsbereich fortgesetzt und erfolgreich abgeschlossen werden, sobald der Ausfall behoben wurde. Stattdessen müssen diese Aufträge erneut übermittelt werden, entweder im sekundären Arbeitsbereich oder im primären Arbeitsbereich (sobald der Ausfall behoben wurde).
Verschieben von Artefakten zwischen Arbeitsbereichen
Abhängig von Ihrem Wiederherstellungsansatz müssen Sie möglicherweise Artefakte wie Dataset- und Modellobjekte zwischen den Arbeitsbereichen kopieren, um die Arbeit fortzusetzen. Derzeit ist die Portabilität von Artefakten zwischen Arbeitsbereichen eingeschränkt. Es wird empfohlen, Artefakte nach Möglichkeit als Code zu verwalten, damit sie in der Failoverinstanz neu erstellt werden können.
Die folgenden Artefakte können mithilfe der Azure CLI-Erweiterung für Azure Machine Learning zwischen Arbeitsbereichen exportiert und importiert werden:
| Artefakt | Exportieren | Importieren |
|---|---|---|
| Modelle | az ml model download --model-id {ID} --target-dir {PATH} | az ml model register –name {NAME} --path {PATH} |
| Umgebungen | az ml environment download -n {NAME} -d {PATH} | az ml environment register -d {PATH} |
| Azure Machine Learning-Pipelines (mit Code generiert) | az ml pipeline get --path {PATH} | az ml pipeline create --name {NAME} -y {PATH} |
Tipp
- Registrierte Datasets können nicht heruntergeladen oder verschoben werden. Dies schließt von Azure Machine Learning generierte Datasets ein, z. B. Zwischen-Pipelinedatasets. Datasets, die auf einen freigegebenen Dateispeicherort verweisen, auf den beide Arbeitsbereiche zugreifen können, oder bei dem der zugrunde liegende Datenspeicher repliziert wird, können jedoch in beiden Arbeitsbereichen registriert werden. Verwenden Sie az ml dataset register, um ein Dataset zu registrieren.
- Auftragsausgaben werden im Standardspeicherkonto gespeichert, das einem Arbeitsbereich zugeordnet ist. Während bei einem Dienstausfall möglicherweise nicht mehr über die Studio-Benutzeroberfläche auf Auftragsausgaben zugegriffen werden kann, können Sie direkt über das Speicherkonto auf die Daten zugreifen. Weitere Informationen zum Arbeiten mit in Blobs gespeicherten Daten finden Sie unter Erstellen, Herunterladen und Auflisten von Blobs mit der Azure-Befehlszeilenschnittstelle.
Wiederherstellungsoptionen
Löschen eines Arbeitsbereichs
Wenn Sie Ihren Arbeitsbereich versehentlich gelöscht haben, können Sie ihn möglicherweise wiederherstellen. Die Schritte zum Wiederherstellen finden Sie unter Wiederherstellen von Arbeitsbereichsdaten nach versehentlichem Löschen mit vorläufigem Löschen (Vorschau).
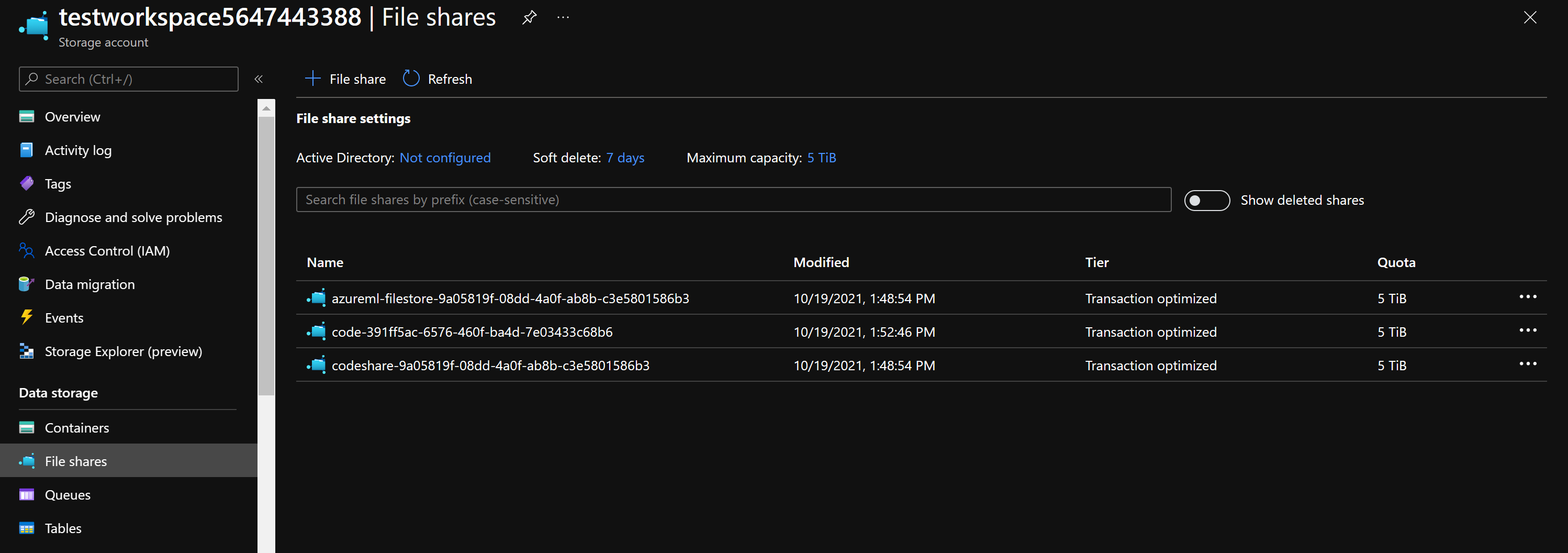
Auch wenn Ihr Arbeitsbereich nicht wiederhergestellt werden kann, können Sie Ihre Notebooks möglicherweise trotzdem aus der dem Arbeitsbereich zugeordneten Azure-Speicherressource abrufen, indem Sie die folgenden Schritte ausführen:
- Navigieren Sie im Azure-Portal zu dem Speicherkonto, das mit dem gelöschten Azure Machine Learning-Arbeitsbereich verknüpft war.
- Klicken Sie im Abschnitt „Datenspeicher“ auf der linken Seite auf Dateifreigaben.
- Ihre Notebooks befinden sich auf der Dateifreigabe mit dem Namen, der Ihre Arbeitsbereichs-ID enthält.
Nächste Schritte
Verwenden Sie eine Azure Resource Manager-Vorlage, um mehr über wiederholbare Infrastrukturbereitstellungen mit Azure Machine Learning zu erfahren.