Verwenden von Apache Spark (unterstützt von Azure Synapse Analytics) in Ihrer Machine Learning-Pipeline (veraltet)
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
Warnung
Die im Python SDK v1 verfügbare Azure Synapse Analytics-Integration mit Azure Machine Learning ist veraltet. Benutzer können weiterhin den Synapse-Arbeitsbereich, der bei Azure Machine Learning registriert ist, als verknüpften Dienst verwenden. Ein neuer Synapse-Arbeitsbereich kann jedoch nicht mehr bei Azure Machine Learning als verknüpfter Dienst registriert werden. Es wird empfohlen, verwaltete (automatische) Synapse-Computeressourcen und angefügte Synapse Spark-Pools zu verwenden, die in CLI v2 und Python SDK v2 verfügbar sind. Ausführliche Informationen finden Sie unter https://aka.ms/aml-spark.
In diesem Artikel erfahren Sie, wie Sie Apache Spark-Pools, die von Azure Synapse Analytics unterstützt werden, als Computeziel für einen Datenaufbereitungsschritt in einer Azure Machine Learning-Pipeline verwenden. Sie erfahren, wie eine einzelne Pipeline Computeressourcen verwenden kann, die für einen bestimmten Schritt geeignet sind, z. B. Datenvorbereitung oder Training. Sie sehen, wie die Daten für den Spark-Schritt vorbereitet und an den nächsten Schritt weitergeleitet werden.
Voraussetzungen
Erstellen Sie einen Azure Machine Learning-Arbeitsbereich, um Ihre gesamten Pipelineressourcen aufzunehmen.
Konfigurieren Sie Ihre Entwicklungsumgebung für die Installation des Azure Machine Learning SDK, oder verwenden Sie eine Azure Machine Learning-Computeinstanz mit bereits installiertem SDK.
Erstellen Sie einen Azure Synapse Analytics-Arbeitsbereich und einen Apache Spark-Pool (siehe Schnellstart: Erstellen eines serverlosen Apache Spark-Pools mithilfe von Synapse Studio).
Verknüpfen des Azure Machine Learning-Arbeitsbereichs und des Azure Synapse Analytics-Arbeitsbereichs
Sie erstellen und verwalten Ihre Apache Spark-Pools in einem Azure Synapse Analytics-Arbeitsbereich. Wenn Sie einen Apache Spark-Pool mit einem Azure Machine Learning-Arbeitsbereich integrieren möchten, müssen Sie eine Verknüpfung mit dem Azure Synapse Analytics-Arbeitsbereich herstellen.
Sobald Ihr Azure Machine Learning-Arbeitsbereich und Ihre Azure Synapse Analytics-Arbeitsbereiche verknüpft sind, können Sie einen Apache Spark-Pool anfügen über
Python SDK (wie unten beschrieben)
Azure Resource Manager-Vorlage (ARM) (siehe ARM-Beispielvorlage).
- Sie können die Befehlszeile verwenden, um die ARM-Vorlage zu befolgen, den verknüpften Dienst hinzuzufügen und den Apache Spark-Pool mit folgendem Code anzufügen:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Wichtig
Um erfolgreich eine Verknüpfung mit dem Azure Synapse Analytics-Arbeitsbereich herzustellen, benötigen Sie die Rolle „Besitzer“ in der Azure Synapse Analytics-Arbeitsbereichsressource. Überprüfen Sie Ihren Zugriff im Azure-Portal.
Der verknüpfte Dienst erhält eine systemseitig zugewiesene verwaltete Identität (SAI), wenn Sie ihn erstellen. Sie müssen dieser vom System zugewiesenen Identität des Linkdiensts die Rolle „Synapse Apache Spark-Administrator“ von Synapse Studio zuweisen, damit sie den Spark-Auftrag übermitteln kann (weitere Informationen finden Sie unter Verwalten von Synapse RBAC-Rollenzuweisungen in Synapse Studio).
Außerdem müssen Sie dem Benutzer des Azure Machine Learning-Arbeitsbereichs die Rolle „Mitwirkender“ im Azure-Portal der Ressourcenverwaltung erteilen.
Abrufen des Links zwischen Ihrem Azure Synapse Analytics-Arbeitsbereich und Ihrem Azure Machine Learning-Arbeitsbereich
Sie können verknüpfte Dienste in Ihrem Arbeitsbereich mit Code wie dem folgenden abrufen:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Zuerst greift Workspace.from_config() mithilfe der Konfiguration in config.json auf Ihren Azure Machine Learning-Arbeitsbereich zu (weitere Informationen finden Sie unter Erstellen einer Konfigurationsdatei für den Arbeitsbereich). Anschließend gibt der Code alle verknüpften Dienste aus, die im Arbeitsbereich verfügbar sind. Schließlich ruft LinkedService.get() einen verknüpften Dienst namens 'synapselink1' ab.
Anfügen Ihres Apache Spark-Pools als Computeziel für Azure Machine Learning
Wenn Sie Ihren Apache Spark-Pool verwenden möchten, um einen Schritt in Ihrer Machine Learning-Pipeline zu nutzen, müssen Sie ihn als ComputeTarget für den Pipelineschritt anfügen, wie im folgenden Code gezeigt:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
Der erste Schritt ist die Konfiguration von SynapseCompute. Das Argument linked_service ist das LinkedService-Objekt, das Sie im vorherigen Schritt erstellt oder abgerufen haben. Das Argument type muss SynapseSpark sein. Das Argument pool_name in SynapseCompute.attach_configuration() muss mit einem vorhandenen Pool in Ihrem Azure Synapse Analytics-Arbeitsbereich übereinstimmen. Weitere Informationen zum Erstellen eines Apache Spark-Pools im Azure Synapse Analytics-Arbeitsbereich finden Sie unter Schnellstart: Erstellen eines serverlosen Apache Spark-Pools mithilfe von Synapse Studio. Der Typ von attach_config lautet ComputeTargetAttachConfiguration.
Nachdem die Konfiguration erstellt wurde, erstellen Sie ein Machine Learning-ComputeTarget indem Sie Workspace, ComputeTargetAttachConfiguration und den Namen übergeben, über den Sie auf die Compute-Instanz im Machine Learning-Arbeitsbereich verweisen möchten. Der Aufruf von ComputeTarget.attach() ist asynchron, sodass das Beispiel blockiert wird, bis der Aufruf abgeschlossen ist.
Erstellen eines SynapseSparkStep-Elements, das den verknüpften Apache Spark-Pool verwendet
Das Beispielnotebook Spark-Auftrag im Apache Spark-Pool definiert eine einfache Machine Learning-Pipeline. Zuerst definiert das Notebook einen Datenaufbereitungsschritt, der durch synapse_compute unterstützt wird, das im vorherigen Schritt definiert wurde. Anschließend definiert das Notebook einen Trainingsschritt, der von einem Computeziel unterstützt wird, das besser für das Training geeignet ist. Das Beispielnotebook verwendet die Datenbank „Titanic Survival“, um die Dateneingabe und -ausgabe zu veranschaulichen. Es bereinigt nicht wirklich die Daten oder erstellt ein Vorhersagemodell. Da in diesem Beispiel kein echtes Training erfolgt, verwendet der Trainingsschritt eine kostengünstige, CPU-basierte Computeressource.
Daten fließen in eine Machine Learning-Pipeline über DatasetConsumptionConfig-Objekte ein, die Tabellendaten oder eine Reihe von Dateien enthalten können. Die Daten stammen häufig aus Dateien im Blobspeicher im Datenspeicher eines Arbeitsbereichs. Der folgende Code stellt einen typischen Code zum Erstellen von Eingaben für eine Machine Learning-Pipeline dar:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
Der obige Code geht davon aus, dass sich die Datei Titanic.csv im Blobspeicher befindet. Der Code zeigt, wie die Datei als TabularDataset und als FileDataset gelesen wird. Dieser Code dient nur zu Demonstrationszwecken, da es verwirrend wäre, Eingaben zu duplizieren oder eine einzelne Datenquelle sowohl als Ressource mit Tabellendaten als auch nur als Datei zu interpretieren.
Wichtig
Damit ein FileDataset als Eingabe verwendet werden kann, muss Ihre azureml-core-Version mindestens 1.20.0 entsprechen. Wie Sie dies mithilfe der Environment-Klasse angeben, wird im Folgenden erläutert.
Wenn ein Schritt abgeschlossen ist, können Sie die Ausgabedaten mithilfe von Code speichern, der etwa wie folgt aussieht:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
In diesem Fall werden die Daten im datastore in einer Datei namens test gespeichert und würden im Machine Learning-Arbeitsbereich als Dataset namens registered_dataset zur Verfügung stehen.
Zusätzlich zu den Daten kann eine Pipeline Python-Abhängigkeiten pro Schritt aufweisen. Einzelne SynapseSparkStep-Objekte können auch ihre exakte Azure Synapse Apache Spark-Konfiguration angeben. Dies wird im folgenden Code gezeigt, der angibt, dass die azureml-core-Paketversion mindestens 1.20.0 lauten muss. (Wie bereits erwähnt, ist diese Anforderung für azureml-core erforderlich, um ein FileDataset als Eingabe zu verwenden.)
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Der obige Code gibt einen einzelnen Schritt in der Azure Machine Learning-Pipeline an. Die environment dieses Schritts gibt eine bestimmte azureml-core-Version an und kann bei Bedarf andere Conda- oder Pip-Abhängigkeiten hinzufügen.
Der SynapseSparkStep zippt das Unterverzeichnis ./code vom lokalen Computer und lädt es hoch. Dieses Verzeichnis wird auf dem Computeserver neu erstellt und der Schritt führt die Datei dataprep.py aus diesem Verzeichnis aus. Die inputs und outputs dieses Schritts sind die step1_input1-, step1_input2- und step1_output-Objekte, die zuvor erläutert wurden. Die einfachste Möglichkeit, auf diese Werte innerhalb des dataprep.py-Skripts zuzugreifen, besteht darin, ihnen benannte arguments zuzuordnen.
Der nächste Satz von Argumenten für den SynapseSparkStep-Konstruktor steuert Apache Spark. Das compute_target ist 'link1-spark01', das wir zuvor als Computeziel angefügt haben. Mit den anderen Parametern werden der Arbeitsspeicher und die Kerne angegeben, die wir verwenden möchten.
Das Beispielnotebook verwendet den folgenden Code für dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
Dieses Skript zur „Datenaufbereitung“ führt keine echte Datentransformation durch, sondern veranschaulicht, wie Daten abgerufen, in einen Spark-Datenrahmen konvertiert und einige grundlegende Apache Spark-Bearbeitungen vorgenommen werden. Sie können die Ausgabe in Azure Machine Learning Studio finden, indem Sie den untergeordneten Auftrag öffnen, die Registerkarte Ausgaben und Protokolle auswählen und die Datei logs/azureml/driver/stdout öffnen, wie in der folgenden Abbildung dargestellt.
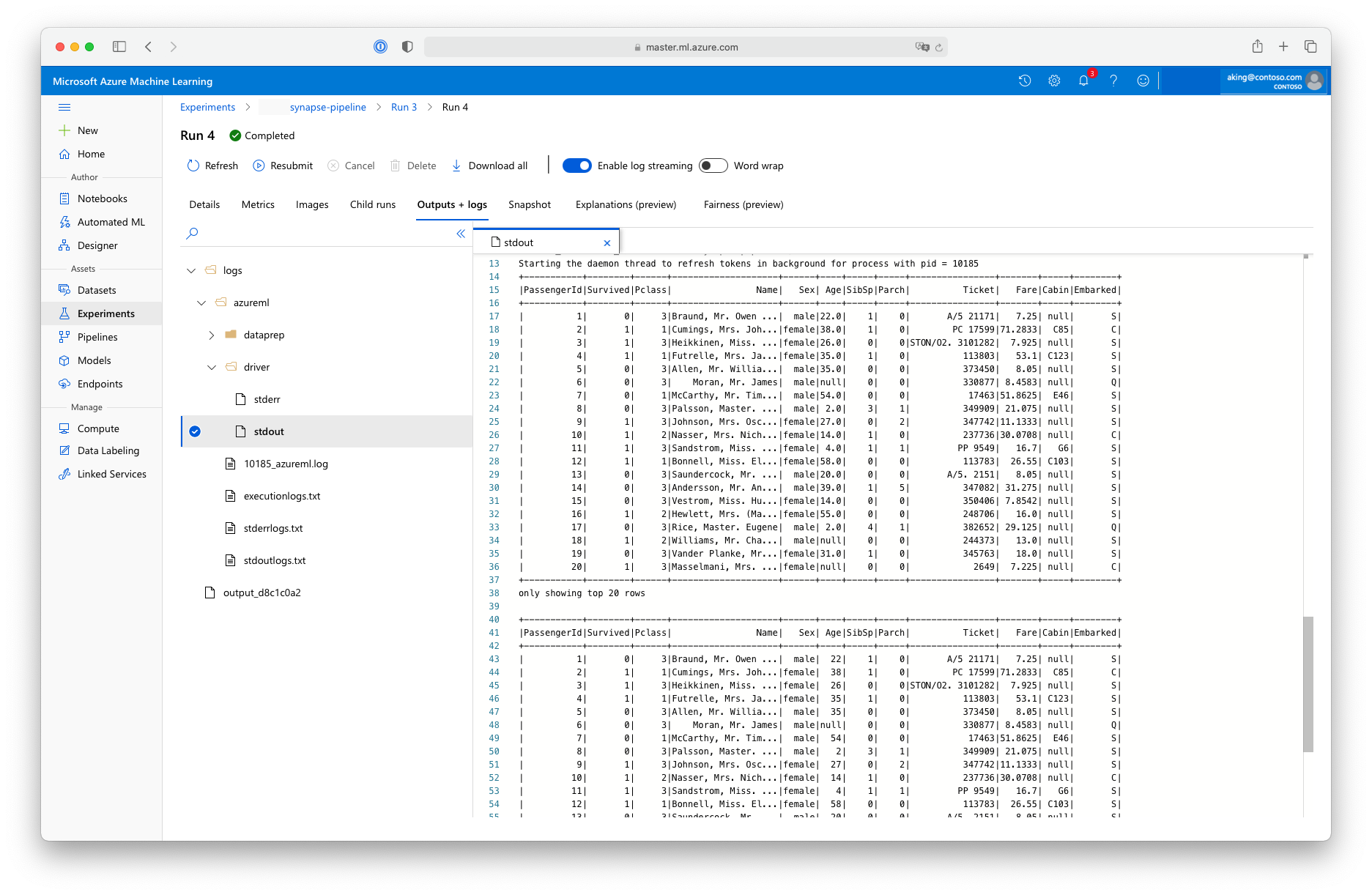
Verwenden von SynapseSparkStep in einer Pipeline
Im folgenden Beispiel wird die Ausgabe aus dem im vorherigen Abschnitt erstellten SynapseSparkStep verwendet. Andere Schritte in der Pipeline können ihre eigenen eindeutigen Umgebungen aufweisen und auf verschiedenen Computeressourcen ausgeführt werden, die für die jeweilige Aufgabe geeignet sind. Das Beispielnotebook führt den „Trainingsschritt“ auf einem kleinen CPU-Cluster aus:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
Der obige Code erstellt die neue Computeressource, falls erforderlich. Dann wird das step1_output-Ergebnis in eine Eingabe für den Trainingsschritt konvertiert. Die Option as_download() bedeutet, dass die Daten auf die Computeressource verschoben werden, was zu einem schnelleren Zugriff führt. Wenn die Daten so umfangreich sind, dass sie nicht auf die Festplatte der lokalen Compute-Instanz passen, würden Sie die Option as_mount() verwenden, um die Daten über das FUSE-Dateisystem zu streamen. Das compute_target dieses zweiten Schrittes ist 'cpucluster', nicht die 'link1-spark01'-Ressource, die Sie im Schritt der Datenaufbereitung verwendet haben. In diesem Schritt wird ein einfaches Programm (train.py) anstelle des im vorherigen Schritt verwendeten Programms dataprep.py verwendet. Die Details von train.py finden Sie im Beispielnotebook.
Nachdem Sie alle Schritte definiert haben, können Sie Ihre Pipeline erstellen und ausführen.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Der obige Code erstellt eine Pipeline, die aus dem von Azure Synapse Analytics unterstützten Datenaufbereitungsschritt (step_1) für Apache Spark-Pools und dem Trainingsschritt (step_2) besteht. Azure berechnet das Ausführungsdiagramm, indem die Datenabhängigkeiten zwischen den Schritten untersucht werden. In diesem Fall gibt es nur die einfache Abhängigkeit, dass für step2_input unbedingt step1_output erforderlich ist.
Der Aufruf von pipeline.submit erstellt bei Bedarf ein Experiment namens synapse-pipeline und startet darin asynchron einen Auftrag. Einzelne Schritte innerhalb der Pipeline werden als untergeordnete Aufträge dieses Hauptauftrags ausgeführt und können auf der Seite „Experimente“ von Studio überwacht und überprüft werden.