Tutorial: Designer – Trainieren eines Regressionsmodells ohne Code
Trainieren Sie ein lineares Regressionsmodell, das die Autopreise mithilfe des Azure Machine Learning Designers vorhersagt. Dieses Tutorial ist der erste Teil einer zweiteiligen Reihe.
In diesem Tutorial wird der Azure Machine Learning-Designer verwendet. Weitere Informationen dazu finden Sie unter Was ist der Azure Machine Learning-Designer?.
Hinweis
Der Designer unterstützt zwei Komponententypen: klassisch vorkonfigurierte Komponenten (v1) und benutzerdefinierte Komponenten (v2). Diese beiden Komponententypen sind NICHT kompatibel.
Klassische vorkonfigurierte Komponenten bieten vordefinierte Komponenten, die vor allem für die Datenverarbeitung und für herkömmliche Machine Learning-Aufgaben wie Regression und Klassifizierung genutzt werden. Dieser Komponententyp wird weiterhin unterstützt, aber es werden keine neuen Komponenten hinzugefügt.
Benutzerdefinierte Komponenten ermöglichen es Ihnen, Ihren eigenen Code als Komponente bereitzustellen. Sie unterstützen die arbeitsbereichübergreifende Freigabe und die reibungslose Erstellung über Studio-, CLI (v2)- und SDK (v2)-Schnittstellen.
Für neue Projekte wird dringend empfohlen, eine benutzerdefinierte Komponente zu verwenden, die mit AzureML V2 kompatibel ist und weiterhin neue Updates erhält.
Dieser Artikel gilt für klassische vordefinierte Komponenten und ist nicht mit CLI v2 und SDK v2 kompatibel.
In dem ersten Teil des Tutorials lernen Sie Folgendes:
- Erstellen einer neuen Pipeline
- Importieren von Daten
- Aufbereiten von Daten
- Trainieren eines Machine Learning-Modells
- Auswerten eines Machine Learning-Modells
In dem zweiten Teil des Tutorials stellen Sie Ihr Modell als Echtzeit-Rückschlussendpunkt bereit. Damit können Sie den Preis eines beliebigen Autos basierend auf den von Ihnen eingesendeten technischen Spezifikationen zu prognostizieren.
Hinweis
Eine fertige Version dieses Tutorials ist als Beispielpipeline verfügbar.
Diese finden Sie im Designer in Ihrem Arbeitsbereich. Wählen Sie im Abschnitt Neue Pipeline die Option Sample 1 - Regression: Automobile Price Prediction(Basic) (Beispiel 1: Regression: Automobilpreisvorhersage (Standard)) aus.
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
Erstellen einer neuen Pipeline
Azure Machine Learning-Pipelines fassen mehrere Machine Learning- und Datenverarbeitungsschritte in einer einzelnen Ressource zusammen. Pipelines ermöglichen die Strukturierung, Verwaltung und Wiederverwendung komplexer Machine Learning-Workflows für verschiedene Projekte und Benutzer.
Für die Erstellung einer Azure Machine Learning-Pipeline benötigen Sie einen Azure Machine Learning-Arbeitsbereich. In diesem Abschnitt erfahren Sie, wie Sie diese beiden Ressourcen erstellen.
Erstellen eines neuen Arbeitsbereichs
Sie benötigen einen Azure Machine Learning-Arbeitsbereich, um den Designer verwenden zu können. Der Arbeitsbereich ist die Ressource der obersten Ebene für Azure Machine Learning und bietet einen zentralen Ort für die Arbeit mit allen Artefakten, die Sie in Azure Machine Learning erstellen. Anweisungen zum Erstellen eines Arbeitsbereichs finden Sie unter Erstellen von Arbeitsbereichsressourcen.
Hinweis
Wenn für Ihren Arbeitsbereich ein virtuelles Netzwerk verwendet wird, müssen Sie zusätzliche Konfigurationsschritte ausführen, um den Designer verwenden zu können. Weitere Informationen finden Sie unter Verwenden von Azure Machine Learning Studio in einem virtuellen Azure-Netzwerk.
Erstellen der Pipeline
Hinweis
Designer unterstützt zwei Arten von Komponenten, die klassischen vordefinierten Komponenten und die benutzerdefinierten Komponenten. Diese beiden Arten von Komponenten sind nicht kompatibel.
Klassische vordefinierte Komponenten bieten vordefinierte Komponenten vor allem für die Datenverarbeitung und traditionelle Machine Learning-Aufgaben wie Regression und Klassifizierung. Dieser Komponententyp wird weiterhin unterstützt, aber es werden keine neuen Komponenten hinzugefügt.
Benutzerdefinierte Komponenten ermöglichen es Ihnen, Ihren eigenen Code als Komponente bereitzustellen. Sie unterstützen die arbeitsbereichsübergreifende Freigabe und die reibungslose Erstellung über Studio-, CLI- und SDK-Schnittstellen.
Dieser Artikel bezieht sich auf klassische vordefinierte Komponenten.
Melden Sie sich bei ml.azure.com an, und wählen Sie den gewünschten Arbeitsbereich aus.
Wählen Sie Designer –>Klassisch vorkonfiguriert aus.
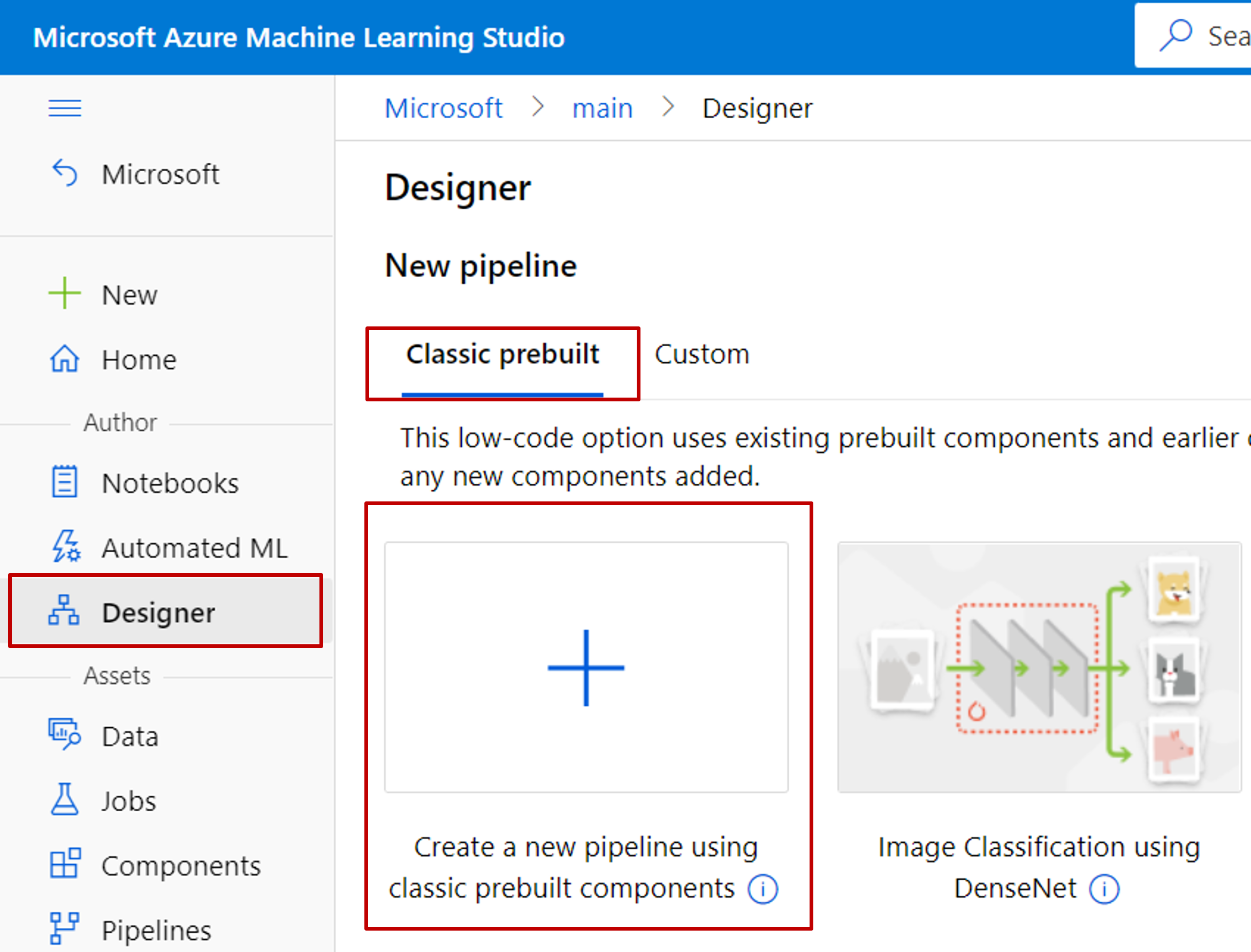
Wählen Sie Erstellen einer neuen Pipeline mithilfe von klassischen vordefinierten Komponenten aus.
Klicken Sie auf das Bleistiftsymbol neben dem automatisch generierten Namen des Pipelineentwurfs, und benennen Sie ihn in Automobilpreisvorhersage um. Der Name muss nicht eindeutig sein.
Festlegen des Standardcomputeziels
Ein Pipelineauftrag auf einem Computeziel. Dabei handelt es sich um eine an Ihren Arbeitsbereich angefügte Computeressource. Nachdem Sie ein Computeziel erstellt haben, können Sie es für künftige Aufträge wiederverwenden.
Wichtig
Angefügte Computeressourcen werden nicht unterstützt. Verwenden Sie stattdessen Compute-Instanzen oder -cluster.
Sie können ein Standardcomputeziel für die gesamte Pipeline festlegen, wodurch jede Komponente standardmäßig das gleiche Computeziel verwendet. Sie können aber auch modulspezifische Computeziele angeben.
Wählen Sie
 Einstellungen rechts von der Canvas aus, um den Bereich Einstellungen zu öffnen.
Einstellungen rechts von der Canvas aus, um den Bereich Einstellungen zu öffnen.Wählen Sie Azure Machine Learning-Compute-Instanz erstellen aus.
Wenn Sie bereits über ein verfügbares Computeziel verfügen, können Sie es aus der Dropdownliste Azure Machine Learning-Compute-Instanz auswählen auswählen, um diese Pipeline auszuführen.
Wählen Sie alternativ „Serverlos“ aus, um serverloses Computing (Vorschau) zu verwenden.
Geben Sie einen Namen für die Computeressource ein.
Klicken Sie auf Erstellen.
Hinweis
Die Erstellung einer Computeressource dauert etwa fünf Minuten. Nach der Erstellung der Ressource können Sie sie wiederverwenden und diese Wartezeit in künftigen Aufträgen vermeiden.
Eine im Leerlauf befindliche Computeressource wird automatisch auf 0 Knoten skaliert, um Kosten zu sparen. Wenn Sie sie nach einer Verzögerung erneut verwenden, müssen Sie unter Umständen etwa fünf Minuten warten, bis sie wieder hochskaliert wurde.
Daten importieren
Im Designer stehen mehrere Beispieldatasets zur Verfügung, mit denen Sie experimentieren können. Verwenden Sie für dieses Tutorial Automobile Price Data (Raw) (Automobilpreisdaten (Rohdaten)).
Links neben der Pipelinecanvas befindet sich eine Palette mit Datasets und Komponenten. Wählen Sie Komponente –>Beispieldaten aus.
Wählen Sie das Dataset Automobile Price Data (Raw) (Automobilpreisdaten (Rohdaten)) aus, und ziehen Sie es auf die Canvas.
Visualisieren der Daten
Sie können die Daten visualisieren, um sich mit dem zu verwendenden Dataset vertraut zu machen.
Klicken Sie mit der rechten Maustaste auf Automobile Price Data (Raw) (Automobilpreisdaten (Rohdaten)), und wählen Sie Datenvorschau anzeigen aus.
Wählen Sie die verschiedenen Spalten im Datenfenster aus, um Informationen zur jeweiligen Spalte zu erhalten.
Jede Zeile steht für ein Fahrzeug, und die Variablen, die den einzelnen Fahrzeugen zugeordnet sind, werden als Spalten angezeigt. Es gibt 205 Zeilen und 26 Spalten in diesem Dataset.
Vorbereiten von Daten
Für Datasets ist vor der Analyse in der Regel eine Vorverarbeitung erforderlich. Bei der Untersuchung des Datasets sind Ihnen unter Umständen einige fehlende Werte aufgefallen. Damit das Modell die Daten korrekt analysieren kann, müssen diese fehlenden Werte bereinigt werden.
Entfernen einer Spalte
Wenn Sie ein Modell trainieren, müssen Sie etwas gegen fehlende Daten tun. In diesem Dataset fehlen in der Spalte normalized-losses zahlreiche Werte. Daher schließen wir diese Spalte ganz aus dem Modell aus.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Spalten im Dataset auswählen.
Ziehen Sie die Komponente Spalten im Dataset auswählen auf die Canvas. Legen Sie die Komponente unterhalb der Datasetkomponente ab.
Verbinden Sie das Dataset Automobile price data (Raw) (Automobilpreisdaten (Rohdaten)) mit der Komponente Spalten im Dataset auswählen. Ziehen Sie eine Linie vom Ausgabeport des Datasets zum Eingabeport von Spalten im Dataset auswählen – also von dem kleinen Kreis am unteren Rand des Datasets auf der Canvas zu dem kleinen Kreis am oberen Rand der Komponente.
Tipp
Um einen Datenfluss für Ihre Pipeline zu erstellen, verbinden Sie den Ausgabeport einer Komponente mit dem Eingabeport einer anderen Komponente.
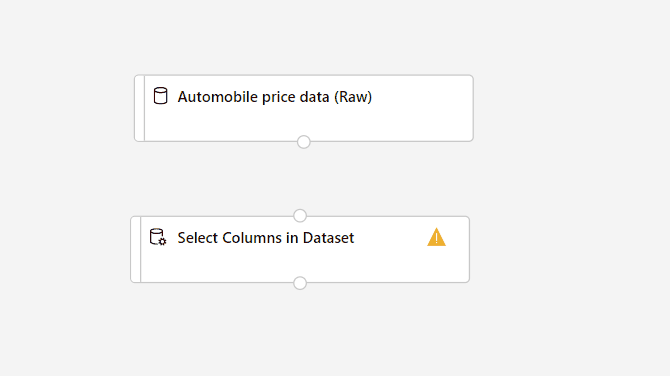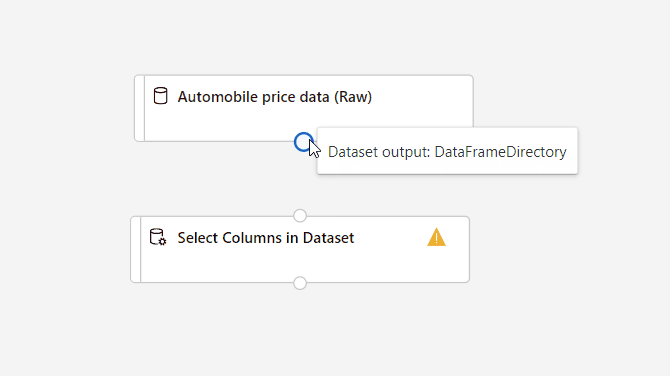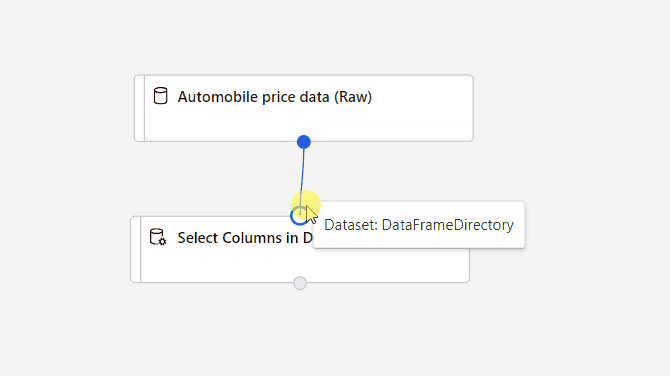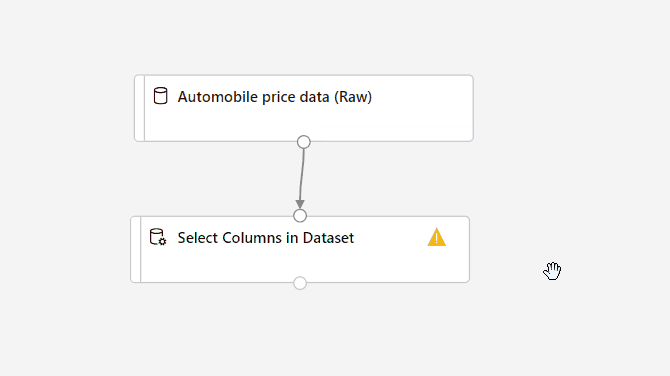
Wählen Sie die Komponente Spalten im Dataset auswählen aus.
Klicken Sie unter „Einstellungen“ rechts neben der Canvas auf das Pfeilsymbol, um den Komponentendetailbereich zu öffnen. Alternativ können Sie auf die Komponente Spalten im Dataset auswählen doppelklicken, um den Detailbereich zu öffnen.
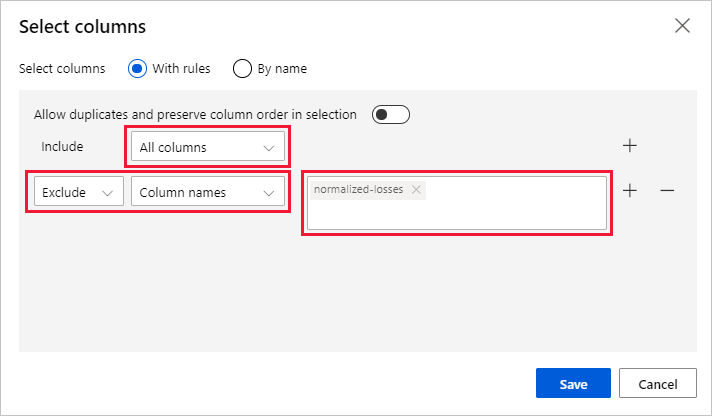
Wählen Sie rechts neben dem Bereich Spalte bearbeiten aus.
Erweitern Sie neben Einschließen die Dropdownliste Spaltennamen, und wählen Sie Alle Spalten aus.
Wählen Sie + aus, um eine neue Regel hinzuzufügen.
Wählen Sie in den Dropdownmenüs die Optionen Ausschließen und Spaltennamen aus.
Geben Sie normalized-losses in das Textfeld ein.
Wählen Sie rechts unten Speichern aus, um die Spaltenauswahl zu schließen.
Erweitern Sie im Detailbereich der Komponente Spalten im Dataset auswählen den Abschnitt Knoteninformationen.
Wählen Sie das Textfeld Kommentar aus, und geben Sie Exclude normalized losses (Normalisierte Verluste ausschließen) ein.
Kommentare werden im Diagramm angezeigt, um Sie bei der Strukturierung Ihrer Pipeline zu unterstützen.
Fehlende Daten bereinigen
Auch nach dem Entfernen der Spalte normalized-losses weist Ihr Dataset noch fehlende Werte auf. Die restlichen fehlenden Daten können mithilfe der Komponente Clean Missing Data (Fehlende Daten bereinigen) entfernt werden.
Tipp
Die Bereinigung fehlender Werte in den Eingabedaten wird bei den meisten Komponenten im Designer vorausgesetzt.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Fehlende Daten bereinigen.
Ziehen Sie die Komponente Clean Missing Data (Fehlende Daten bereinigen) auf die Pipelinecanvas. Verbinden Sie sie mit der Komponente Spalten im Dataset auswählen.
Wählen Sie die Komponente Clean Missing Data (Fehlende Daten bereinigen) aus.
Klicken Sie unter „Einstellungen“ rechts neben der Canvas auf das Pfeilsymbol, um den Komponentendetailbereich zu öffnen. Alternativ können Sie auf die Komponente Fehlende Daten bereinigen doppelklicken, um den Detailbereich zu öffnen.
Wählen Sie rechts neben dem Bereich Spalte bearbeiten aus.
Erweitern Sie im angezeigten Fenster Columns to be cleaned (Zu bereinigende Spalten) das Dropdownmenü neben Einschließen. Wählen Sie Alle Spalten aus.
Wählen Sie Speichern aus.
Wählen Sie im Detailbereich der Komponente Fehlende Daten bereinigen unter Bereinigungsmodus die Option Gesamte Zeile entfernen aus.
Erweitern Sie im Detailbereich der Komponente Fehlende Daten bereinigen den Abschnitt Knoteninformationen.
Wählen Sie das Textfeld Kommentar aus, und geben Sie Fehlende Wertzeilen entfernen ein.
Ihre Pipeline sollte nun in etwa wie folgt aussehen:
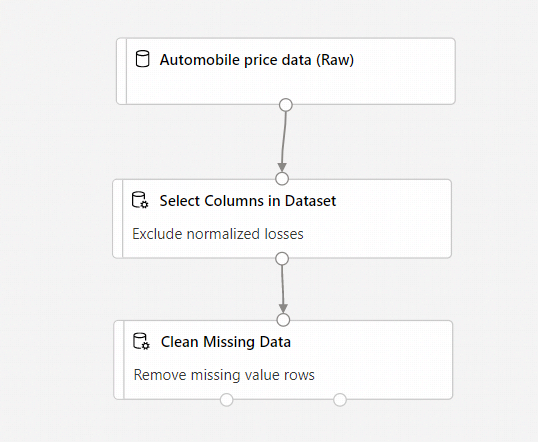
Trainieren eines Machine Learning-Modells
Nachdem Sie nun über die Komponenten für die Datenverarbeitung verfügen, können Sie die Trainingskomponenten einrichten.
Da Sie einen Preis (also eine Zahl) vorhersagen möchten, können Sie einen Regressionsalgorithmus verwenden. In diesem Beispiel verwenden Sie ein lineares Regressionsmodell.
Teilen der Daten
Das Aufteilen von Daten ist eine gängige Aufgabe beim maschinellen Lernen. Ihre Daten werden in zwei separate Datasets aufgeteilt. eins zum Trainieren des Modells und eins zum Testen der Ergebnisqualität des Modells.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Daten aufteilen.
Ziehen Sie die Komponente Split Data (Daten aufteilen) auf die Pipelinecanvas.
Verbinden Sie den linken Port der Komponente Clean Missing Data (Fehlende Daten bereinigen) mit der Komponente Split Data (Daten aufteilen).
Wichtig
Achten Sie darauf, dass der linke Ausgabeport von Fehlende Daten bereinigen mit Daten aufteilen verbunden ist. Der linke Port enthält die bereinigten Daten. Der rechte Port enthält die verworfenen Daten.
Wählen Sie die Komponente Daten aufteilen aus.
Klicken Sie unter „Einstellungen“ rechts neben der Canvas auf das Pfeilsymbol, um den Komponentendetailbereich zu öffnen. Alternativ können Sie auf die Komponente Daten aufteilen doppelklicken, um den Detailbereich zu öffnen.
Legen Sie im Detailbereich für Daten aufteilen die Option Anteil der Zeilen im ersten Ausgabedataset auf „0,7“ fest.
Mit dieser Option werden 70 Prozent der Daten zum Trainieren des Modells und 30 Prozent zum Testen verwendet. Auf das Dataset mit den 70 Prozent kann über den linken Ausgabeport zugegriffen werden. Die restlichen Daten sind über den rechten Ausgabeport verfügbar.
Erweitern Sie im Bereich Daten aufteilen den Abschnitt Knoteninformationen.
Wählen Sie das Textfeld Kommentar aus, und geben Sie Dataset in Trainingssatz (0,7) und Testsatz (0,3) unterteilen ein.
Trainieren des Modells
Trainieren Sie das Modell, indem Sie ein Dataset mit Preis bereitstellen. Durch den Algorithmus wird ein Modell erstellt, das die Beziehung zwischen den Features und dem Preis aus den Trainingsdaten erklärt.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Lineare Regression.
Ziehen Sie die Komponente Lineare Regression auf die Pipelinecanvas.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Modell trainieren.
Ziehen Sie die Komponente Modell trainieren auf die Pipelinecanvas.
Verbinden Sie die Ausgabe der Komponente Linear Regression (Lineare Regression) mit der linken Eingabe der Komponente Train Model (Modell trainieren).
Verbinden Sie die Trainingsdatenausgabe (linker Port) der Komponente Split Data (Daten aufteilen) mit der rechten Eingabe der Komponente Train Model (Modell trainieren).
Wichtig
Achten Sie darauf, dass der linke Ausgabeport von Daten aufteilen mit Modell trainieren verbunden ist. Der linke Port enthält den Trainingssatz. Der rechte Port enthält den Testsatz.
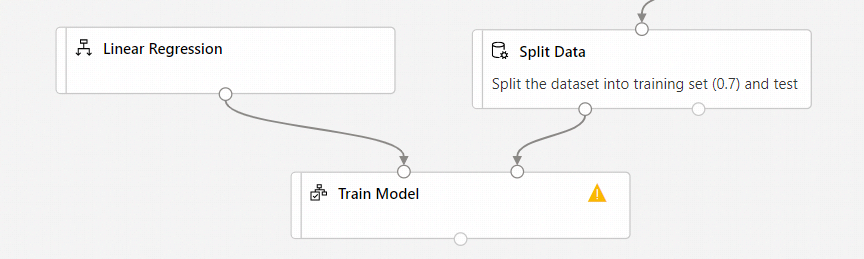
Wählen Sie die Komponente Trainingsmodell.
Klicken Sie unter „Einstellungen“ rechts neben der Canvas auf das Pfeilsymbol, um den Komponentendetailbereich zu öffnen. Alternativ können Sie auf die Komponente Modell trainieren doppelklicken, um den Detailbereich zu öffnen.
Wählen Sie rechts neben dem Bereich Spalte bearbeiten aus.
Erweitern Sie im angezeigten Fenster Bezeichnungsspalte das Dropdownmenü, und wählen Sie Spaltennamen aus.
Geben Sie price (Preis) in das Textfeld ein, um den Wert anzugeben, der von Ihrem Modell prognostiziert wird.
Wichtig
Achten Sie darauf, dass Sie den Spaltennamen genau eingeben. Schreiben Sie price nicht groß.
Ihre Pipeline sollte wie folgt aussehen:
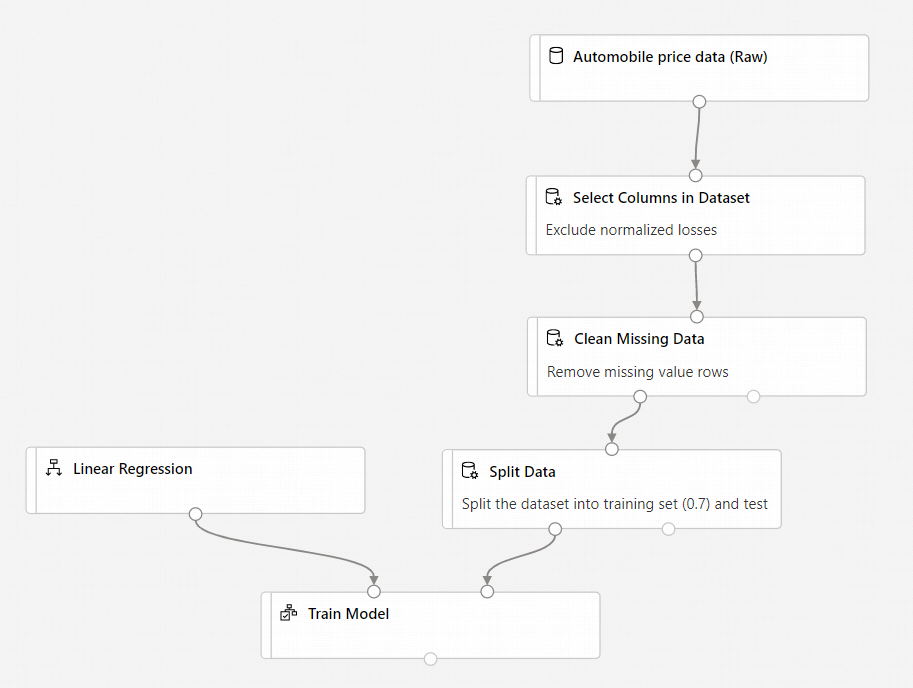
Hinzufügen der Komponente „Score Model“ (Modell bewerten)
Nachdem Sie das Modell mit 70 Prozent der Daten trainiert haben, können Sie unter Verwendung der restlichen 30 Prozent bewerten, wie gut das Modell funktioniert.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Modell bewerten.
Ziehen Sie die Komponente Modell bewerten auf die Pipelinecanvas.
Verbinden Sie die Ausgabe der Komponente Train Model (Model trainieren) mit dem linken Eingabeport von Score Model (Modell bewerten). Verbinden Sie die Testdatenausgabe (den rechten Port) der Komponente Split Data (Daten teilen) mit dem rechten Eingabeport von Score Model (Modell bewerten).
Hinzufügen der Komponente „Evaluate Model“ (Modell auswerten)
Verwenden Sie die Komponente Evaluate Model (Modell auswerten), um auszuwerten, wie gut das Testdataset von Ihrem Modell bewertet wurde.
Klicken Sie in den Datasets und der Komponentenpalette links neben der Canvas auf Komponente, und suchen Sie nach der Komponente Modell auswerten.
Ziehen Sie die Komponente Modell auswerten auf die Pipelinecanvas.
Verbinden Sie die Ausgabe der Komponente Score Model (Modell bewerten) mit der linken Eingabe von Evaluate Model (Modell auswerten).
Die fertige Pipeline sollte in etwa wie folgt aussehen:
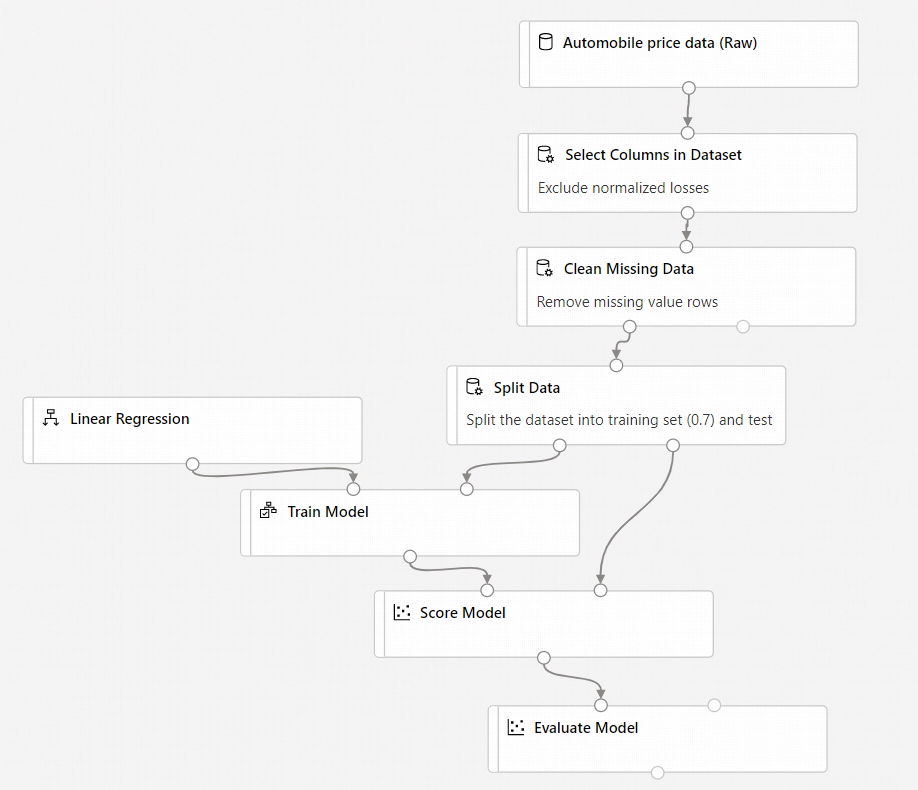
Übermitteln der Pipeline
Nachdem die Einrichtung Ihrer Pipeline jetzt abgeschlossen ist, können Sie einen Pipelineauftrag übermitteln, um Ihr Machine Learning-Modell zu trainieren. Sie können jederzeit einen gültigen Pipelineauftrag übermitteln, mit der während der Entwicklung Änderungen an ihrer Pipeline überprüft werden können.
Wählen Sie im oberen Bereich der Canvas die Option Senden aus.
Wählen Sie im Dialogfeld Pipelineauftrag einrichten die Option Neu erstellen aus.
Hinweis
Experimente fassen ähnliche Pipelineaufträge in einer Gruppe zusammen. Wenn Sie eine Pipeline mehrmals ausführen, können Sie für aufeinanderfolgende Aufträge das gleiche Experiment auswählen.
Geben Sie für Name des neuen Experiments die Zeichenfolge Tutorial-CarPrices ein.
Klicken Sie auf Submit (Senden).
Im linken Bereich des Canvas wird eine Übermittlungsliste angezeigt, und eine Benachrichtigung wird in der oberen rechten Ecke der Seite angezeigt. Sie können den Link Auftragsdetails auswählen, um zum Debuggen zur Seite mit den Auftragsdetails zu wechseln.
Falls dies der erste Auftrag ist, kann es bis zu 20 Minuten dauern, bis die Ausführung der Pipeline vollständig abgeschlossen ist. In den Standardcomputeeinstellungen ist eine minimale Knotengröße von 0 festgelegt. Das bedeutet, dass der Designer Ressourcen nach dem Leerlauf zuordnen muss. Wiederholte Pipeline-Aufträge nehmen weniger Zeit in Anspruch, da die Rechenressourcen bereits zugewiesen sind. Außerdem verwendet der Designer für jede Komponente zwischengespeicherte Ergebnisse, um die Effizienz weiter zu steigern.
Anzeigen bewerteter Bezeichnungen
Auf der Detailseite des Auftrags können Sie den Status, die Ergebnisse und die Protokolle des Pipelineauftrags überprüfen.
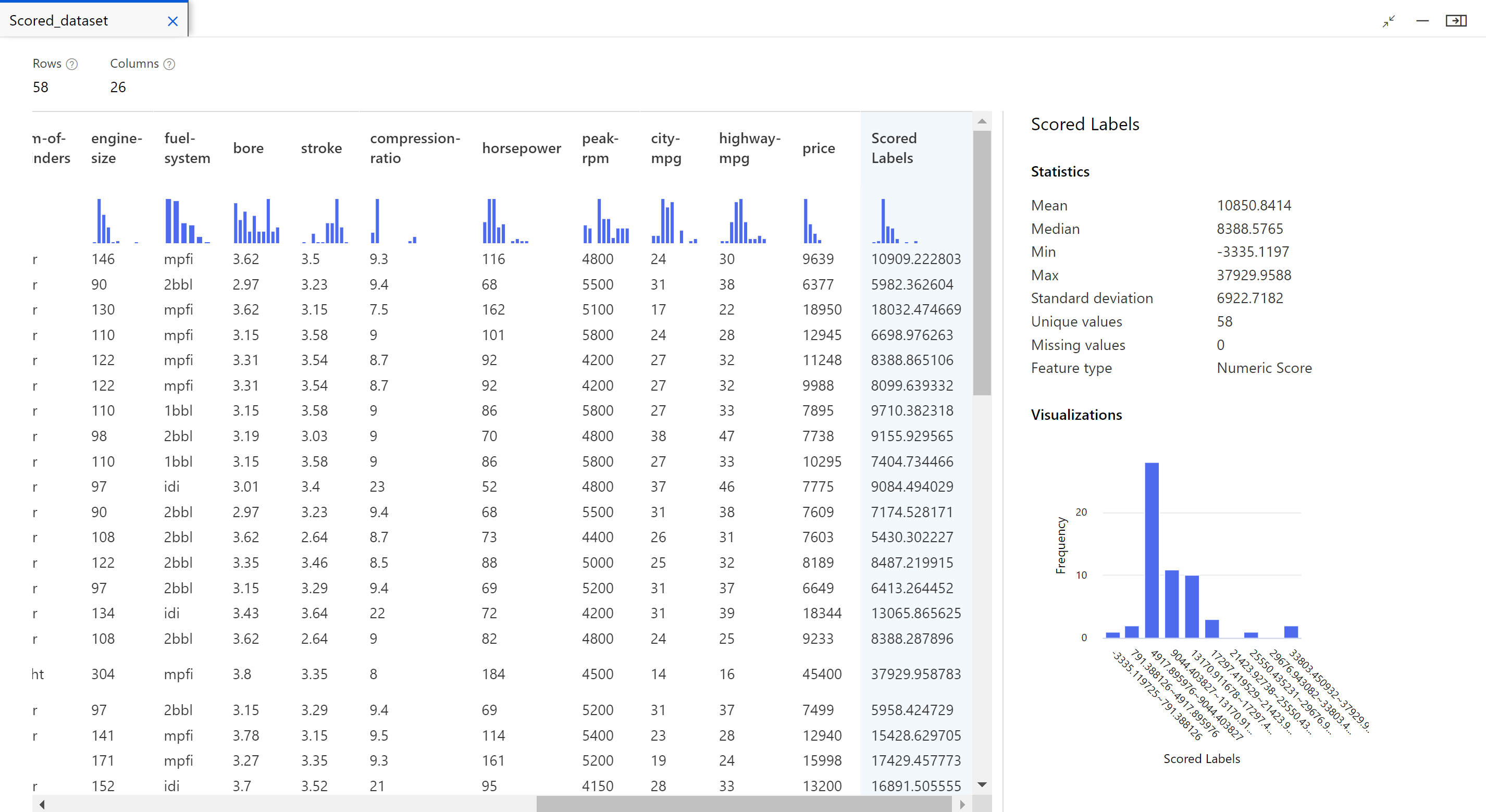
Nach Abschluss des Auftrags können Sie sich die Ergebnisse ansehen. Sehen Sie sich zuerst die vom Regressionsmodell generierten Vorhersagen an.
Klicken Sie mit der rechten Maustaste auf die Komponente Score Model (Modell bewerten), und wählen Sie Datenvorschau anzeigen>Bewertetes Dataset aus, um seine Ausgabe anzuzeigen.
Hier sehen Sie die vorhergesagten Preise und die tatsächlichen Preise aus den Testdaten.
Auswerten von Modellen
Verwenden Sie das Modul Evaluate Model (Modell auswerten), um zu prüfen, wie gut das trainierte Modell beim Testdataset abgeschnitten hat.
- Klicken Sie mit der rechten Maustaste auf die Komponente Evaluate Model (Modell auswerten), und wählen Sie Vorschaudaten anzeigen>Auswertungsergebnisse aus, um seine Ausgabe anzuzeigen.
Die folgenden Statistiken werden für Ihr Modell angezeigt:
- Mean Absolute Error (MAE) (Mittlerer absoluter Fehler): Der Mittelwert der absoluten Fehler. Ein Fehler ist die Differenz zwischen dem prognostizierten und dem tatsächlichen Wert.
- Root Mean Squared Error (RMSE) (Wurzel des mittleren quadratischen Fehlers): Die Quadratwurzel des Durchschnitts des Quadrats der Prognosefehler für das Testdataset.
- Relative Absolute Error: Der Mittelwert der absoluten Fehler relativ zur absoluten Differenz zwischen tatsächlichen Werten und dem Durchschnitt aller tatsächlichen Werte.
- Relative Squared Error: Der Durchschnitt der quadrierten Fehler relativ zur quadrierten Differenz zwischen tatsächlichen Werten und dem Durchschnitt aller tatsächlichen Werte.
- Coefficient of Determination: Dieser auch als „R-Quadrat“ bezeichnete Wert ist eine statistische Kenngröße, die angibt, wie gut ein Modell zu den Daten passt.
Für jede Fehlerstatistik sind kleinere Werte besser. Ein kleinerer Wert gibt an, dass die Vorhersagen näher bei den tatsächlichen Werten liegen. Für den Bestimmungskoeffizienten gilt Folgendes: Je näher der Bestimmungskoeffizient am Wert eins (1,0) liegt, desto besser die Vorhersage.
Bereinigen von Ressourcen
Überspringen Sie diesen Abschnitt, wenn Sie mit dem zweiten Teil des Tutorials (Bereitstellen eines Machine Learning-Modells mit dem Designer) fortfahren möchten.
Wichtig
Sie können die von Ihnen bei der Vorbereitung erstellten Ressourcen auch in anderen Tutorials und Anleitungen für Azure Machine Learning verwenden.
Alles löschen
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie die gesamte Ressourcengruppe, damit Ihnen keine Kosten entstehen.
Wählen Sie im Azure-Portal links im Fenster Ressourcengruppen aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Klicken Sie auf Ressourcengruppe löschen.
Durch das Löschen einer Ressourcengruppe werden auch alle im Designer erstellten Ressourcen gelöscht.
Löschen einzelner Objekte
In dem Designer, in dem Sie Ihr Experiment erstellt haben, können Sie einzelne Ressourcen löschen, indem Sie erst die gewünschten Ressourcen und dann die Schaltfläche Löschen auswählen.
Das hier erstellte Computeziel wird automatisch auf null Knoten skaliert, wenn es nicht verwendet wird. Diese Aktion wird durchgeführt, um Gebühren zu minimieren. Wenn Sie das Computeziel löschen möchten, führen Sie die folgenden Schritte aus:
Die Registrierung von Datasets im Arbeitsbereich kann aufgehoben werden, indem Sie die einzelnen Datasets und anschließend Registrierung aufheben auswählen.
Zum Löschen eines Datasets wechseln Sie im Azure-Portal oder Azure Storage-Explorer zum Speicherkonto, und löschen Sie diese Ressourcen manuell.
Nächste Schritte
Im zweiten Teil erfahren Sie, wie Sie Ihr Modell als Echtzeitendpunkt bereitstellen.