Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Managed Instance for Apache Cassandra verfügt über automatisierte Bereitstellungs- und Skalierungsvorgänge für verwaltete Open-Source-basierte Apache Cassandra-Rechenzentren. Dieses Feature beschleunigt Hybridszenarien und trägt dazu bei, die fortlaufende Wartung zu reduzieren.
In dieser Schnellstartanleitung wird veranschaulicht, wie Sie das Azure-Portal verwenden, um einen vollständig verwalteten Apache Spark-Cluster innerhalb des virtuellen Azure-Netzwerks Ihrer azure Managed Instance für Apache Cassandra-Cluster zu erstellen. Der Spark-Cluster wird in Azure Databricks erstellt. Später können Sie Notebooks erstellen oder an den Cluster anfügen, Daten aus verschiedenen Datenquellen lesen und Erkenntnisse analysieren.
Weitere Informationen sowie eine ausführliche Anleitung finden Sie unter Bereitstellen von Azure Databricks in Ihrem virtuellen Azure-Netzwerk (VNET-Einschleusung)..
Voraussetzungen
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Erstellen eines Azure Databricks-Clusters
Führen Sie die folgenden Schritte aus, um einen Azure Databricks-Cluster in einem virtuellen Netzwerk zu erstellen, das über die azure Managed Instance für Apache Cassandra verfügt:
Melden Sie sich beim Azure-Portal an.
Suchen Sie im linken Bereich nach Ressourcengruppen. Wechseln Sie zu Ihrer Ressourcengruppe, die das virtuelle Netzwerk enthält, in dem Ihre verwaltete Instanz bereitgestellt wird.
Öffnen Sie die Virtuelle Netzwerkressource , und notieren Sie sich den Adressraum.
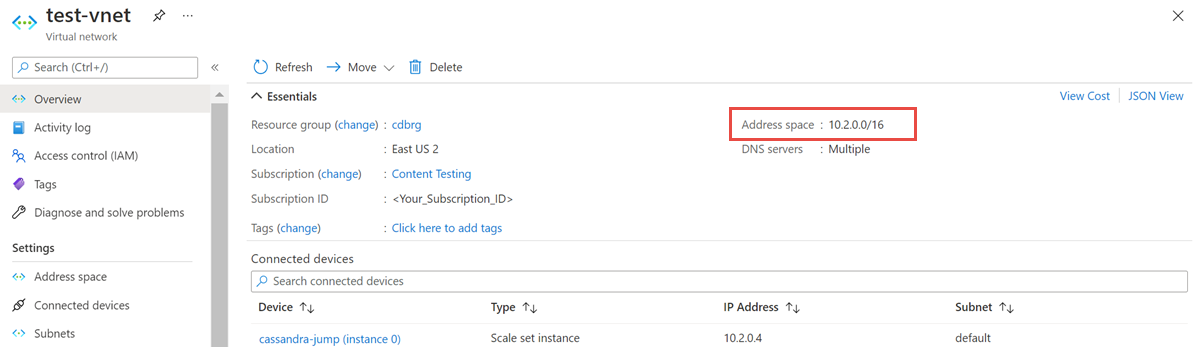
Wählen Sie in der Ressourcengruppe "Hinzufügen" aus, und suchen Sie im Suchfeld nach Azure Databricks .
Wählen Sie "Erstellen" aus, um ein Azure Databricks-Konto zu erstellen.
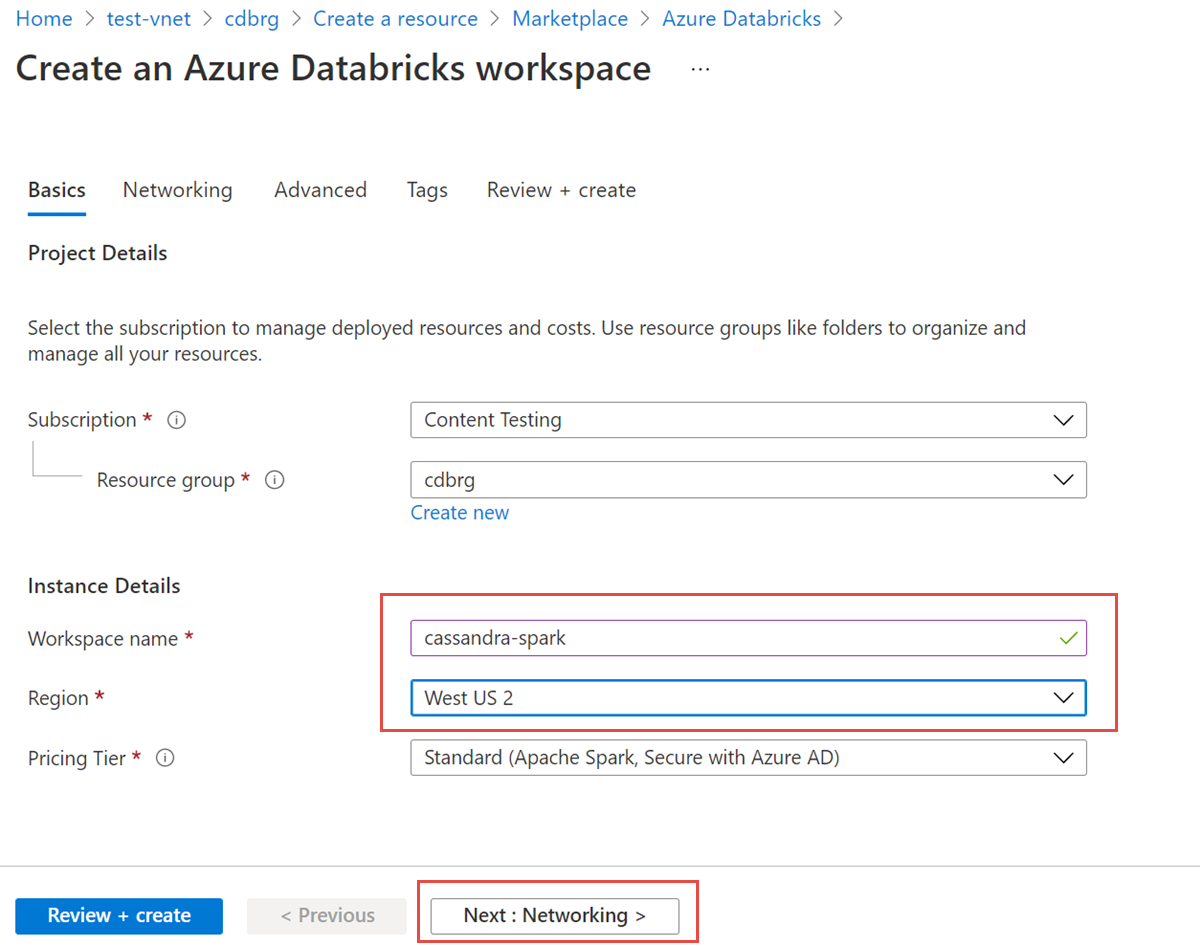
Geben Sie die folgenden Werte ein:
- Arbeitsbereichsname: Geben Sie einen Namen für Ihren Azure Databricks-Arbeitsbereich an.
- Region: Stellen Sie sicher, dass Sie dieselbe Region wie Ihr virtuelles Netzwerk auswählen.
- Preisstufe: Wählen Sie "Standard", "Premium" oder "Testversion" aus. Weitere Informationen zu diesen Stufen finden Sie auf der Azure Databricks-Preisseite.
Wählen Sie die Registerkarte "Netzwerk " aus, und geben Sie die folgenden Details ein:
- Bereitstellen des Azure Databricks-Arbeitsbereichs in Ihrem virtuellen Netzwerk (VNet): Wählen Sie "Ja" aus.
- Virtuelles Netzwerk: Wählen Sie in der Dropdownliste das virtuelle Netzwerk aus, in dem Ihre verwaltete Instanz vorhanden ist.
- Öffentlicher Subnetzname: Geben Sie einen Namen für das öffentliche Subnetz ein.
- Öffentlicher Subnetz-CIDR-Bereich: Geben Sie einen IP-Bereich für das öffentliche Subnetz ein.
- Name des privaten Subnetzs: Geben Sie einen Namen für das private Subnetz ein.
- Privater Subnetz-CIDR-Bereich: Geben Sie einen IP-Bereich für das private Subnetz ein.
Wählen Sie höhere Bereiche aus, um Bereichskonflikte zu vermeiden. Verwenden Sie bei Bedarf einen visuellen Subnetzrechner , um die Bereiche zu dividieren.
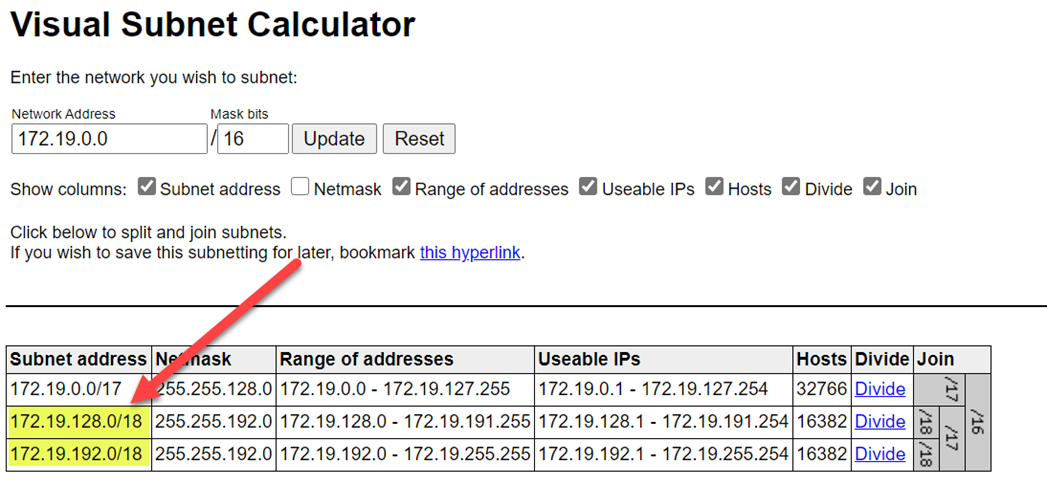
Der folgende Screenshot zeigt Beispieldetails im Netzwerkbereich.
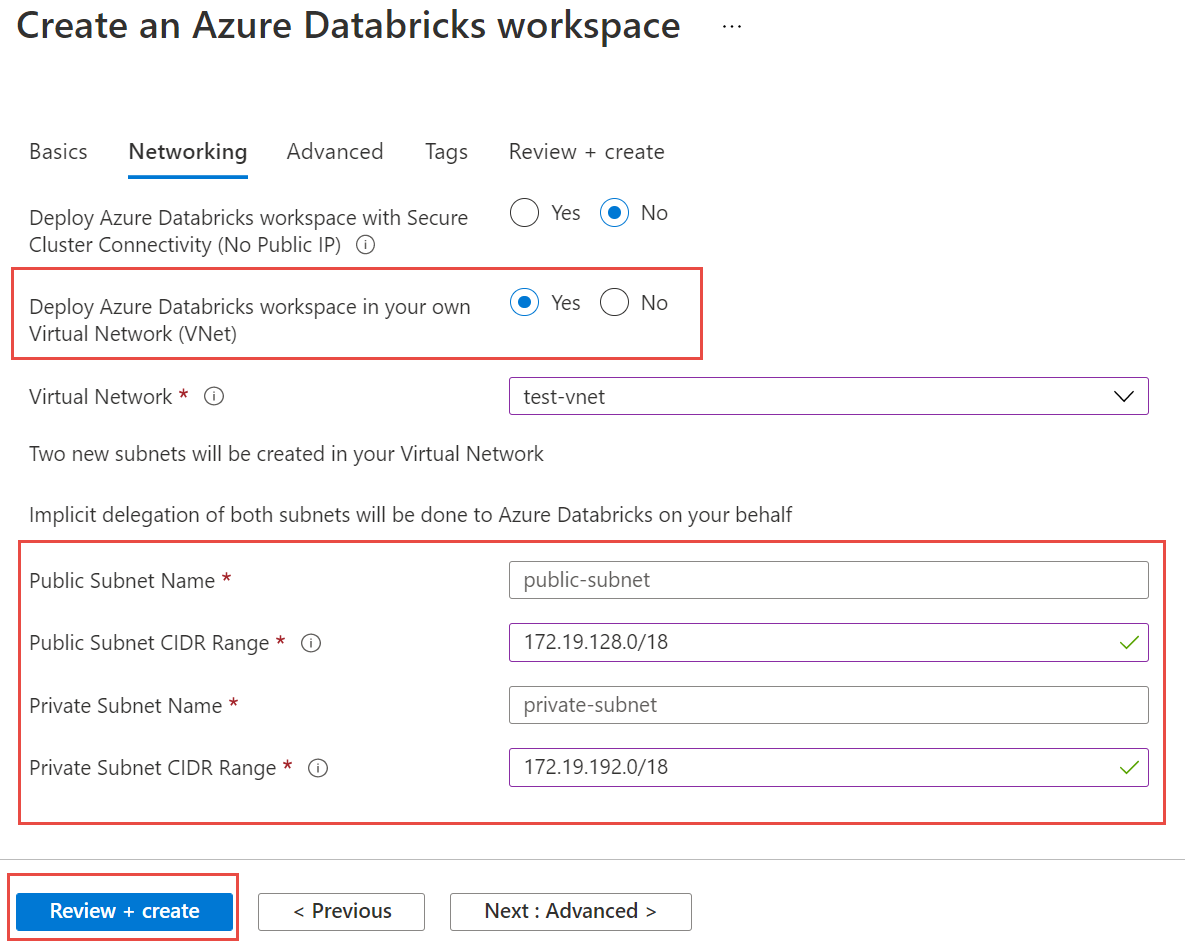
Wählen Sie "Überprüfen + Erstellen" aus und dann "Erstellen", um den Arbeitsbereich bereitzustellen.
Öffnen Sie den Arbeitsbereich, nachdem der Arbeitsbereich erstellt wurde.
Sie werden zum Azure Databricks-Portal weitergeleitet. Wählen Sie im Portal Neuer Cluster aus.
Übernehmen Sie im Bereich "Neuer Cluster" Standardwerte für alle Anderen Felder als die folgenden Felder:
- Clustername: Geben Sie einen Namen für den Cluster ein.
- Databricks-Runtime-Version: Es wird empfohlen, azure Databricks-Laufzeitversion 7.5 oder höher für spark 3.x-Unterstützung auszuwählen.

Erweitern Sie erweiterte Optionen, und fügen Sie die folgende Konfiguration hinzu. Stellen Sie sicher, dass Sie die Knoten-IPs und Anmeldeinformationen ersetzen.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueFügen Sie dem Cluster die Apache Spark-Cassandra-Connectorbibliothek hinzu, um eine Verbindung mit nativen Endpunkten sowie mit Azure Cosmos DB-Cassandra-Endpunkten herzustellen. Wählen Sie in Ihrem Cluster Libraries>Install New>Maven aus und fügen Sie dann im Feld
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0"Maven Coordinates" hinzu.
Wählen Sie Installieren aus.
Bereinigen von Ressourcen
Wenn Sie diesen verwalteten Instanzcluster nicht weiterhin verwenden werden, führen Sie die folgenden Schritte aus, um ihn zu löschen:
- Wählen Sie im Azure-Portal im Menü auf der linken Seite die Option Ressourcengruppen aus.
- Wählen Sie in der Liste die Ressourcengruppe aus, die Sie für diese Schnellstartanleitung erstellt haben.
- Wählen Sie im Ressourcengruppenbereich Übersicht die Option Ressourcengruppe löschen aus.
- Geben Sie im nächsten Bereich den Namen der zu löschenden Ressourcengruppe ein, und wählen Sie dann "Löschen" aus.
Nächster Schritt
In dieser Schnellstartanleitung haben Sie erfahren, wie Sie einen vollständig verwalteten Apache Spark-Cluster innerhalb des virtuellen Netzwerks Ihrer azure Managed Instance für Apache Cassandra-Cluster erstellen. Erfahren Sie als Nächstes, wie Sie die Cluster- und Rechenzentrumsressourcen verwalten.