Datenflussprotokolle für Netzwerksicherheitsgruppen mit Network Watcher und Grafana verwalten und analysieren
Artikel
Wichtig
Am 30. September 2027 werden NSG-Datenflussprotokolle (Netzwerksicherheitsgruppe) eingestellt. Aufgrund dieser Einstellung können Sie ab dem 30. Juni 2025 keine neuen NSG-Datenflussprotokolle mehr erstellen. Es wird empfohlen, zu Datenflussprotokollen für virtuelle Netzwerke zu migrieren, bei denen die Einschränkungen von NSG-Datenflussprotokollen nicht gelten. Nach dem Einstellungsdatum wird die Aktivierung der Datenverkehrsanalyse mit NSG-Datenflussprotokollen nicht mehr unterstützt, und vorhandene Ressourcen für NSG-Datenflussprotokolle in Ihren Abonnements werden gelöscht. NSG-Datenflussprotokolle werden jedoch nicht gelöscht, und es gelten weiterhin die jeweiligen Aufbewahrungsrichtlinien. Weitere Informationen finden Sie in der offiziellen Ankündigung.
Datenflussprotokolle von Netzwerksicherheitsgruppen (NSG) enthalten Informationen zum besseren Verstehen von ein- und ausgehendem IP-Datenverkehr an Netzwerkschnittstellen. Diese Datenflussprotokolle zeigen aus- und eingehende Datenflüsse pro NSG-Regel, die NIC, auf die sich der Datenfluss bezieht, fünf Informationen zum Datenfluss (Quell-/Ziel-IP-Adresse, Quell-/Zielport, Protokoll) und Informationen dazu, ob der Datenverkehr zugelassen oder verweigert wurde.
Für viele NSGs in Ihrem Netzwerk kann die Datenflussprotokollierung aktiviert sein. Diese Menge an Protokolldaten macht es allerdings umständlich, Ihre Protokolle zu analysieren, um Einblicke zu gewinnen. Dieser Artikel bietet eine Lösung zur zentralen Verwaltung dieser NSG-Datenflussprotokolle mit Grafana, einem Open-Source-Visualisierungstool, Elasticsearch, einer verteilten Engine für Suche und Analyse, und Logstash, einer serverseitigen Open-Source-Datenverarbeitungspipeline.
Szenario
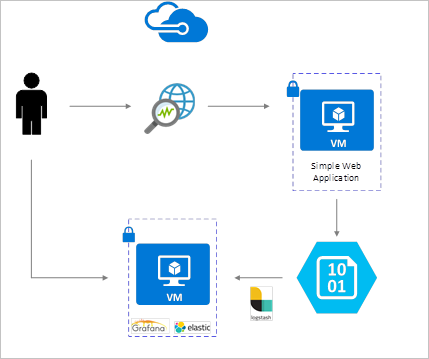
NSG-Datenflussprotokolle werden mithilfe von Network Watcher aktiviert und in Azure Blob Storage abgelegt. Ein Logstash-Plug-In wird verwendet, um eine Verbindung mit Datenflussprotokollen im Blob-Speicher herzustellen und diese zu verarbeiten und an Elasticsearch zu senden. Sobald die Datenflussprotokolle in Elasticsearch gespeichert sind, können sie analysiert und in benutzerdefinierten Dashboards in Grafana visualisiert werden.
Installationsschritte
Aktivieren der Datenflussprotokollierung für Netzwerksicherheitsgruppen
Bei diesem Beispiel sind Grafana, Elasticsearch und Logstash auf einem in Azure bereitgestellten Ubuntu LTS-Server konfiguriert. Dieses minimale Setup wird für die Ausführung aller drei Komponenten verwendet, die alle auf derselben VM ausgeführt werden. Dieses Setup sollte allerdings nur für Test- und unkritische Workloads verwendet werden. Logstash, Elasticsearch und Grafana können so gestaltet werden, dass eine unabhängige Skalierung auf zahlreiche Instanzen möglich ist. Weitere Informationen finden Sie in der Dokumentation zu den einzelnen Komponenten.
Installieren von Logstash
Mithilfe von Logstash können Sie die JSON-formatierten Datenflussprotokolle auf Flusstupelebene vereinfachen.
Die folgenden Anweisungen dienen zur Installation von Logstash unter Ubuntu. Anweisungen zum Installieren dieses Pakets unter Red Hat Enterprise Linux finden Sie unter Installieren aus Paketrepositorys: yum.
Führen Sie die folgenden Befehle zum Installieren von Logstash aus:
Die bereitgestellte Konfigurationsdatei von Logstash besteht aus drei Teilen: Eingabe, Filter und Ausgabe.
Der Eingabebereich bezeichnet die Eingabequelle der Protokolle, die Logstash verarbeitet. In diesem Fall verwenden wir ein „azureblob“-Eingabe-Plug-In (das in den nächsten Schritten installiert wird). Es erlaubt uns, auf die JSON-Dateien des NSG-Datenflussprotokolls zuzugreifen, die in Blob Storage gespeichert sind.
Der Filterabschnitt vereinfacht dann jede Datenfluss-Protokolldatei so, dass jedes einzelnen Flusstupel und die ihm zugeordneten Eigenschaften zu einem gesonderten Logstash-Ereignis werden.
Schließlich leitet der Ausgabeabschnitt jedes Logstash-Ereignis an den Elasticsearch-Server weiter. Sie können die CONF-Datei von Logstash nach Wunsch an Ihre spezifischen Anforderungen anpassen.
Installieren des Logstash-Eingabe-Plug-Ins für Azure Blob Storage
Mithilfe dieses Logstash-Plug-Ins können Sie direkt auf die Datenflussprotokolle im jeweiligen Blob Storage-Konto zugreifen. Sie installieren dieses Plug-In, indem Sie über das Logstash-Standardinstallationsverzeichnis (in diesem Fall /usr/share/logstash/bin) folgenden Befehl ausführen:
Sie können das folgende Skript verwenden, um Elasticsearch zu installieren. Informationen zum Installieren von Elasticsearch finden Sie unter Elastic Stack.
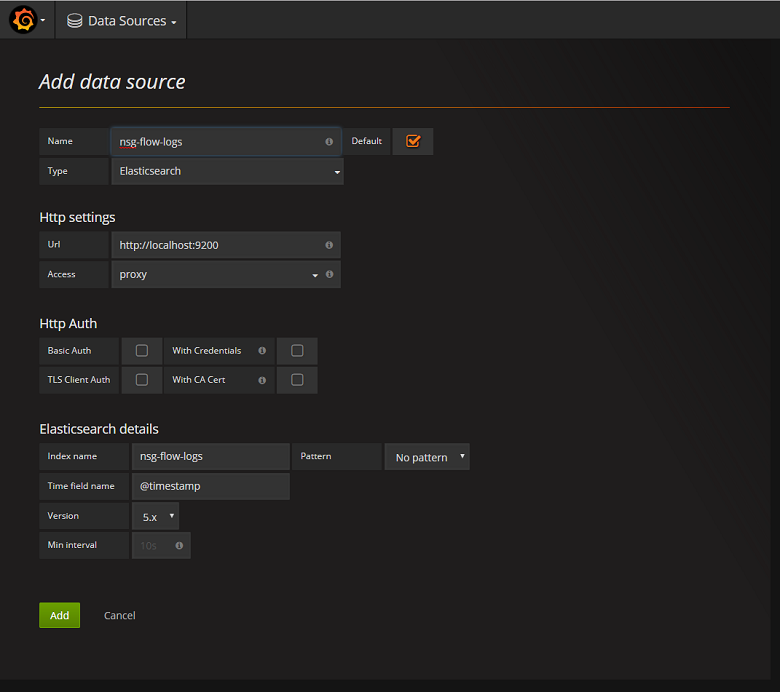
Hinzufügen des Elasticsearch-Servers als Datenquelle
Als Nächstes müssen Sie den Elasticsearch-Index mit den Datenflussprotokollen als Datenquelle hinzufügen. Sie können eine Datenquelle hinzufügen, indem Sie Add data source auswählen und das Formular mit den entsprechenden Informationen ausfüllen. Ein Beispiel dieser Konfiguration finden Sie im folgenden Screenshot:
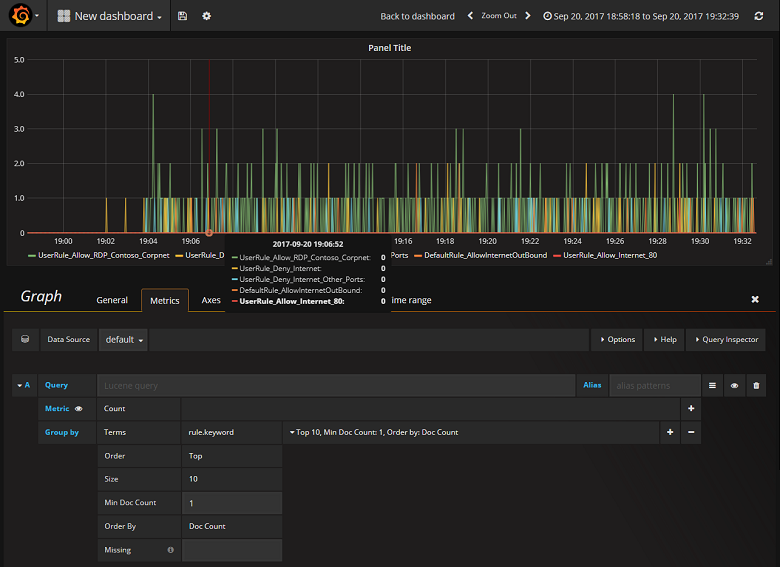
Erstellen eines Dashboards
Nachdem Sie Grafana nun erfolgreich so konfiguriert haben, dass Daten aus dem Elasticsearch-Index mit den NSG-Datenflussprotokolle gelesen werden, können Sie Dashboards erstellen und personalisieren. Wählen Sie zum Erstellen eines neuen Dashboards Create your first dashboard aus. Die folgende Beispielkonfiguration eines Graphen zeigt nach NSG-Regel segmentierte Datenflüsse:
Zusammenfassung
Durch die Integration von Network Watcher mit Elasticsearch und Grafana haben Sie jetzt eine einfache und zentrale Möglichkeit zum Verwalten und Visualisieren von NSG-Datenflussprotokollen wie auch anderer Daten. Grafana verfügt über eine Reihe weiterer leistungsfähiger Grafikfunktionen, die auch zur weiteren Verwaltung von Datenflussprotokollen und zum besseren Verständnis des Netzwerkdatenverkehrs genutzt werden können. Nachdem Sie eine Grafana-Instanz eingerichtet und mit Azure verbunden haben, können Sie die anderen gebotenen Funktionen weiter erkunden.
In diesem Modul erfahren Sie, wie Sie die folgenden Azure Network Watcher-Funktionen verwenden, um Azure-Netzwerke zu überwachen und zu diagnostizieren: Azure Network Watcher-Topologie. Verbindungsmonitor. IP-Datenflussüberprüfung und NSG-Diagnose. Paketerfassung.
Zeigen Sie Ihre Kenntnisse zu Entwurf, Implementierung und Wartung der Azure-Netzwerkinfrastruktur, zum Lastenausgleich für Datenverkehr, zum Netzwerkrouting u. v. m.
Erfahren Sie, wie Sie mit Power BI Datenflussprotokolle für Netzwerksicherheitsgruppen visualisieren, um Informationen zum IP-Datenverkehr anzeigen zu können.
Erfahren Sie, wie Sie mit einem PowerShell-Skript Datenflussprotokolle analysieren, die stündlich erstellt und alle paar Minuten in Azure Network Watcher aktualisiert werden.
Weitere Informationen zu NSG-Datenflussprotokolle – ein Feature von Azure Network Watcher, mit dem Sie Informationen zu IP-Datenverkehr protokollieren können, der eine Netzwerksicherheitsgruppe (NSG) durchläuft.
Erfahren Sie, wie Sie Azure Network Watcher -Datenflussprotokolle für virtuelle Netzwerke mithilfe des Azure-Portals erstellen, ändern, aktivieren, deaktivieren oder löschen.
Erfahren Sie, wie Sie Azure Policy integrierten Richtlinien verwenden, um Azure Network Watcher NSG-Flussprotokolle zu überwachen und die Bereitstellung von Datenverkehrsanalysen zu verwalten.
In diesem Artikel wird erläutert, wie Sie die Speicherblobs für Flowprotokolle für Netzwerksicherheitsgruppen, die sich nicht mehr innerhalb Aufbewahrungsrichtlinie befinden, in Azure Network Watcher löschen.