Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie die Grundursache für langsam ausgeführte Abfragen identifizieren und diagnostizieren.
In diesem Artikel lernen Sie Folgendes:
- Identifizieren langsam ausgeführter Abfragen.
- Identifizieren einer in diesem Zusammenhang langsam ausgeführten Prozedur. eine langsame Abfrage innerhalb einer Liste von Abfragen identifizieren, die zur gleichen langsam ausgeführten gespeicherten Prozedur gehören.
Voraussetzungen
Aktivieren Sie Anleitungen zur Problembehandlung, indem Sie die unter Verwendung der Leitfäden zur Problembehandlung beschriebenen Schritte ausführen.
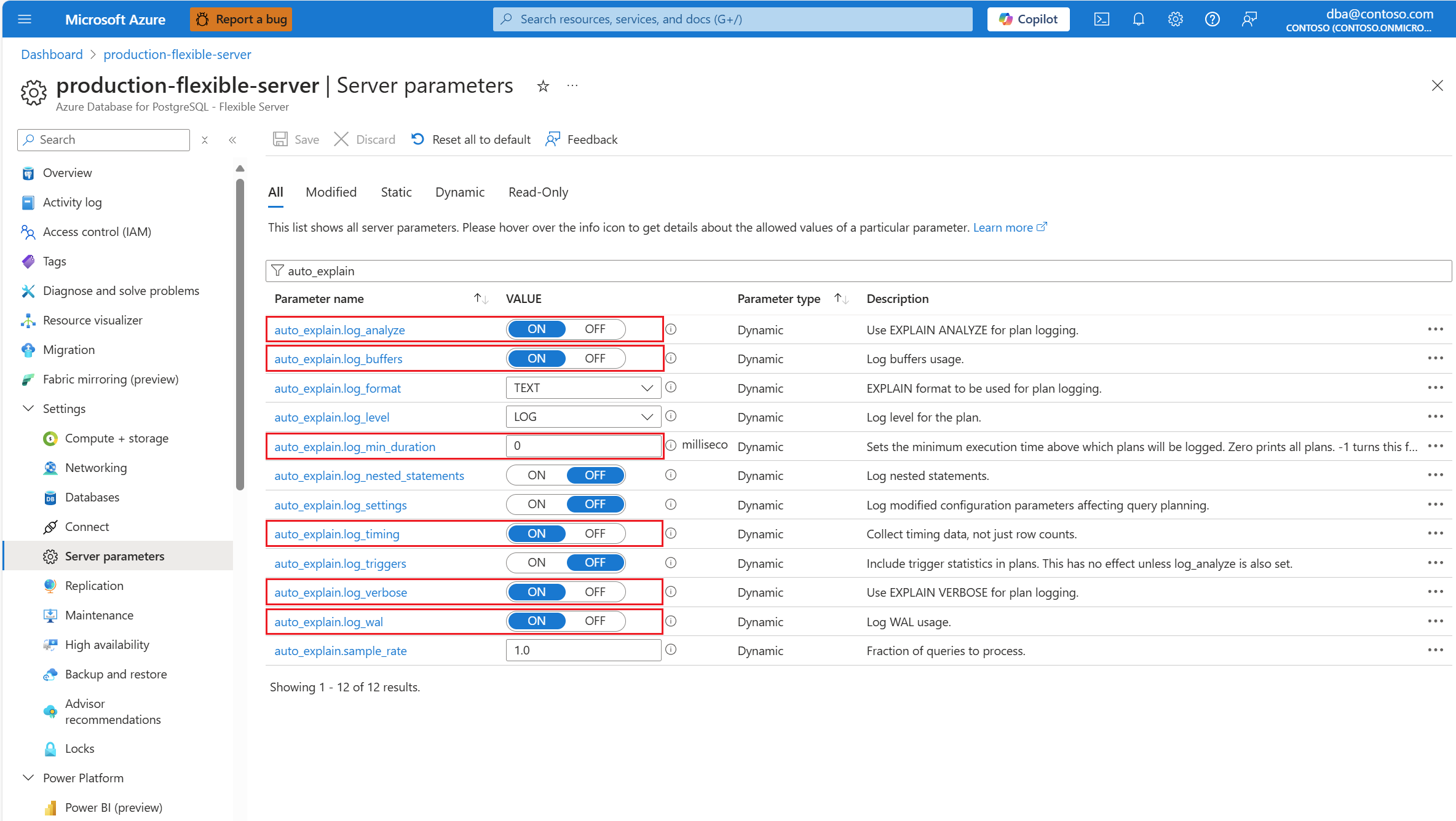
Konfigurieren Sie die
auto_explain-Erweiterung, indem Sie die Erweiterung der Positivliste hinzufügen und laden.Ändern Sie nach der Konfiguration der
auto_explain-Erweiterung die folgenden Serverparameter, die das Verhalten der Erweiterung steuern:-
auto_explain.log_analyzeinON. -
auto_explain.log_buffersinON. -
auto_explain.log_min_durationentsprechend den in Ihrem Szenario sinnvollen Werten. -
auto_explain.log_timinginON. -
auto_explain.log_verboseinON.
-

Hinweis
Wenn Sie auto_explain.log_min_duration auf 0 festlegen, beginnt die Erweiterung mit der Protokollierung aller Abfragen, die auf dem Server ausgeführt werden. Dies kann sich auf die Leistung der Datenbank auswirken. Sie müssen eine ordnungsgemäße Due Diligence durchführen, um zu einem Wert zu gelangen, der auf dem Server als langsam betrachtet werden kann. Wenn beispielsweise alle Abfragen in weniger als 30 Sekunden abgeschlossen werden und dies für Ihre Anwendung akzeptabel ist, wird empfohlen, den Parameter auf 30.000 Millisekunden zu aktualisieren. Dies würde dann jede Abfrage protokollieren, die länger als 30 Sekunden dauert, bis sie abgeschlossen ist.
Identifizieren langsamer Abfragen
Da Ihnen nun die Anleitungen zur Problembehandlung und die auto_explain-Erweiterung zur Verfügung stehen, kann das Szenario mithilfe eines Beispiels erläutert werden.
Wir haben ein Szenario, in dem die CPU-Auslastung auf 90 % steigt, und möchten die Ursache der Spitze ermitteln. Führen Sie die folgenden Schritte aus, um das Szenario zu debuggen:
Sobald Sie von einem CPU-Szenario benachrichtigt werden, wählen Sie im Ressourcenmenü der betroffenen Instanz von Azure Database for PostgreSQL flexiblen Server im Abschnitt "Überwachung " Die Anleitungen zur Problembehandlung aus.
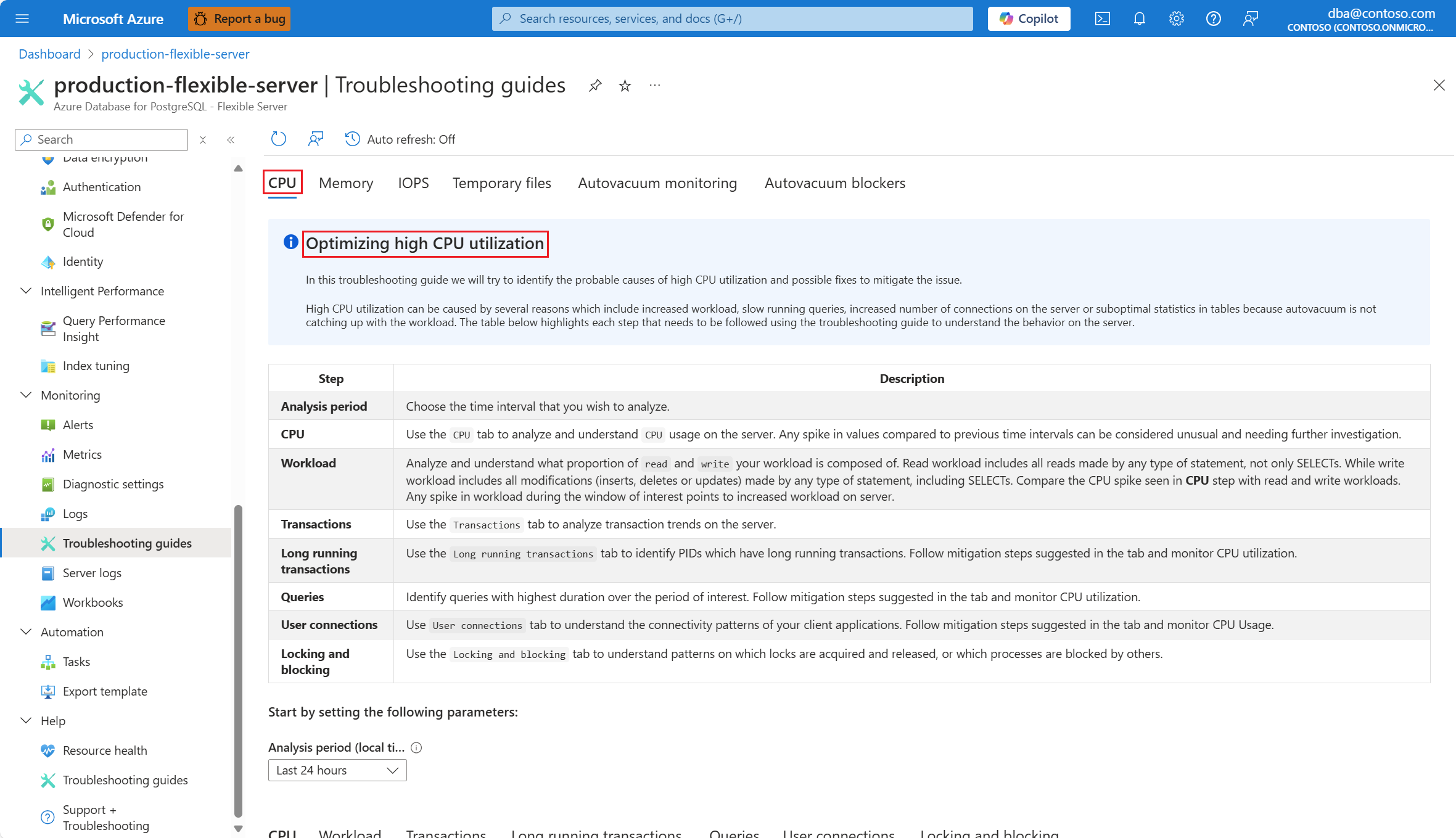
Wählen Sie die Registerkarte CPU aus. Die Anleitung zur Problembehandlung Optimieren einer hohen CPU-Auslastung öffnet sich.
Wählen Sie in der Dropdownliste "Analysezeitraum " (Ortszeit) den Zeitraum aus, auf den Sie die Analyse konzentrieren möchten.
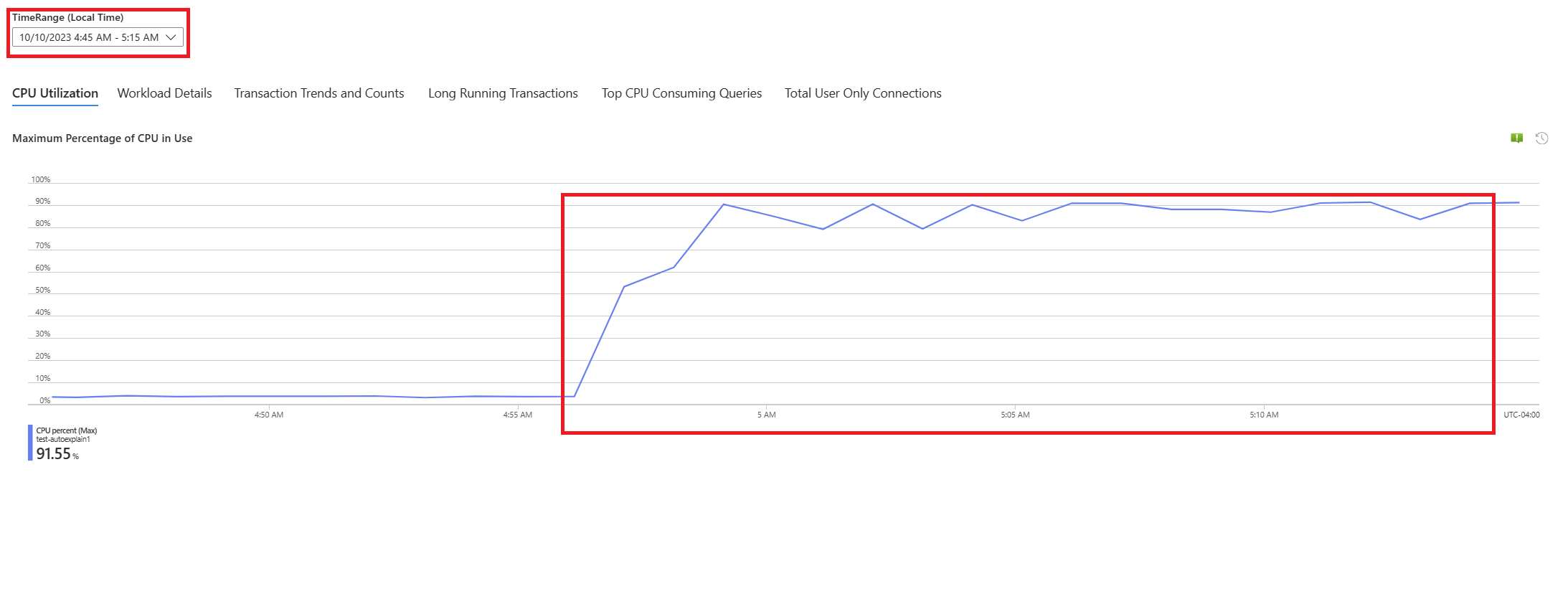
Wählen Sie die Registerkarte Abfragen aus. Hier werden die Details zu allen Abfragen angezeigt, die in dem Intervall ausgeführt wurden, in dem CPU-Auslastungsspitzen von 90 % vorlagen. Die Momentaufnahme lässt darauf schließen, dass die Abfrage mit der langsamsten durchschnittlichen Ausführungszeit während des Zeitintervalls ca. 2,6 Minuten benötigte und während des Intervalls 22 Mal ausgeführt wurde. Diese Abfrage ist höchstwahrscheinlich die Ursache der CPU-Auslastungsspitzen.
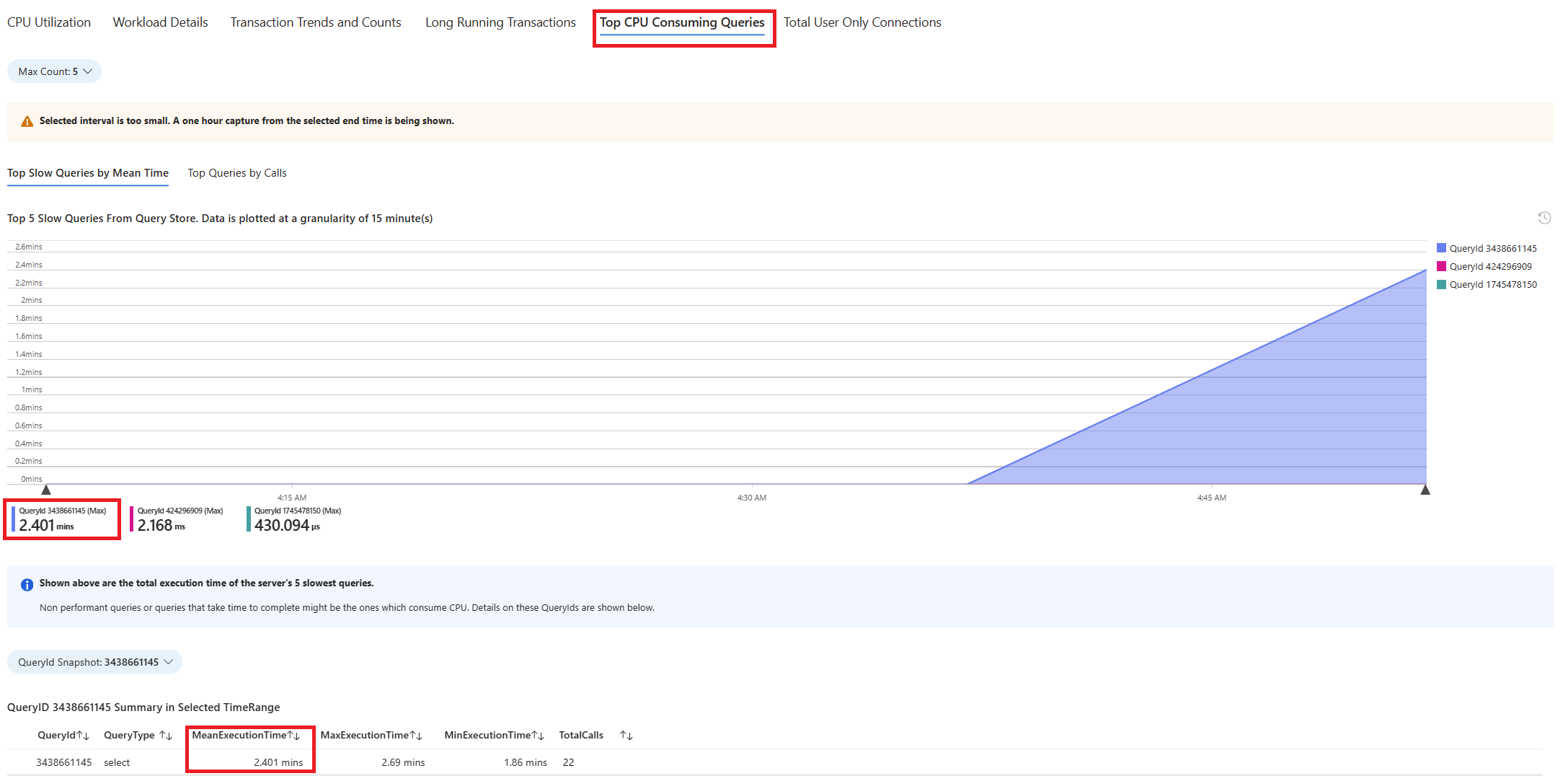
Stellen Sie eine Verbindung mit der
azure_sys-Datenbank her, und führen Sie die folgende Abfrage aus, um den tatsächlichen Abfragetext abzurufen.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- In diesem Beispiel war die als langsam identifizierte Abfrage die folgende:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Verwenden Sie Protokolle von Azure Database für PostgreSQL, um zu verstehen, welche genauen Ausführungspläne generiert wurden. Jedes Mal, wenn die Abfrage während dieses Zeitfensters ausgeführt wurde, sollte die
auto_explain-Erweiterung einen Eintrag in die Protokolle schreiben. Wählen Sie im Ressourcenmenü im Abschnitt Überwachung die Option Protokolle aus.
Wählen Sie den Zeitbereich aus, in dem eine CPU-Auslastung von 90 % gefunden wurde.
Führen Sie die folgende Abfrage aus, um die Ausgabe von EXPLAIN ANALYZE der identifizierten Abfrage zu erhalten.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
In der Nachrichtenspalte wird der Ausführungsplan wie in der folgenden Ausgabe dargestellt gespeichert:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Die Abfrage wurde ca. 2,5 Minuten lang ausgeführt, wie in der Anleitung zur Problembehandlung gezeigt. Der duration-Wert 150.692,864 ms aus der abgerufenen Ausführungsplanausgabe bestätigt dies. Verwenden Sie die Ausgabe von EXPLAIN ANALYZE, um die Problembehandlung fortzusetzen und die Abfrage zu optimieren.
Hinweis
Beachten Sie, dass die Abfrage 22 Mal während des Intervalls ausgeführt wurde, und die angezeigten Protokolle enthalten solche Einträge, die während des Intervalls erfasst wurden.
Identifizieren langsam ausgeführte Abfragen in einer gespeicherten Prozedur
Da Ihnen nun die Anleitungen zur Problembehandlung und die auto_explain-Erweiterung zur Verfügung stehen, kann das Szenario mithilfe eines Beispiels erläutert werden.
Wir haben ein Szenario, in dem die CPU-Auslastung auf 90 % steigt, und möchten die Ursache der Spitze ermitteln. Führen Sie die folgenden Schritte aus, um das Szenario zu debuggen:
Sobald Sie von einem CPU-Szenario benachrichtigt werden, wählen Sie im Ressourcenmenü der betroffenen Instanz von Azure Database for PostgreSQL flexiblen Server im Abschnitt "Überwachung " Die Anleitungen zur Problembehandlung aus.
Wählen Sie die Registerkarte CPU aus. Die Anleitung zur Problembehandlung Optimieren einer hohen CPU-Auslastung öffnet sich.
Wählen Sie in der Dropdownliste "Analysezeitraum " (Ortszeit) den Zeitraum aus, auf den Sie die Analyse konzentrieren möchten.
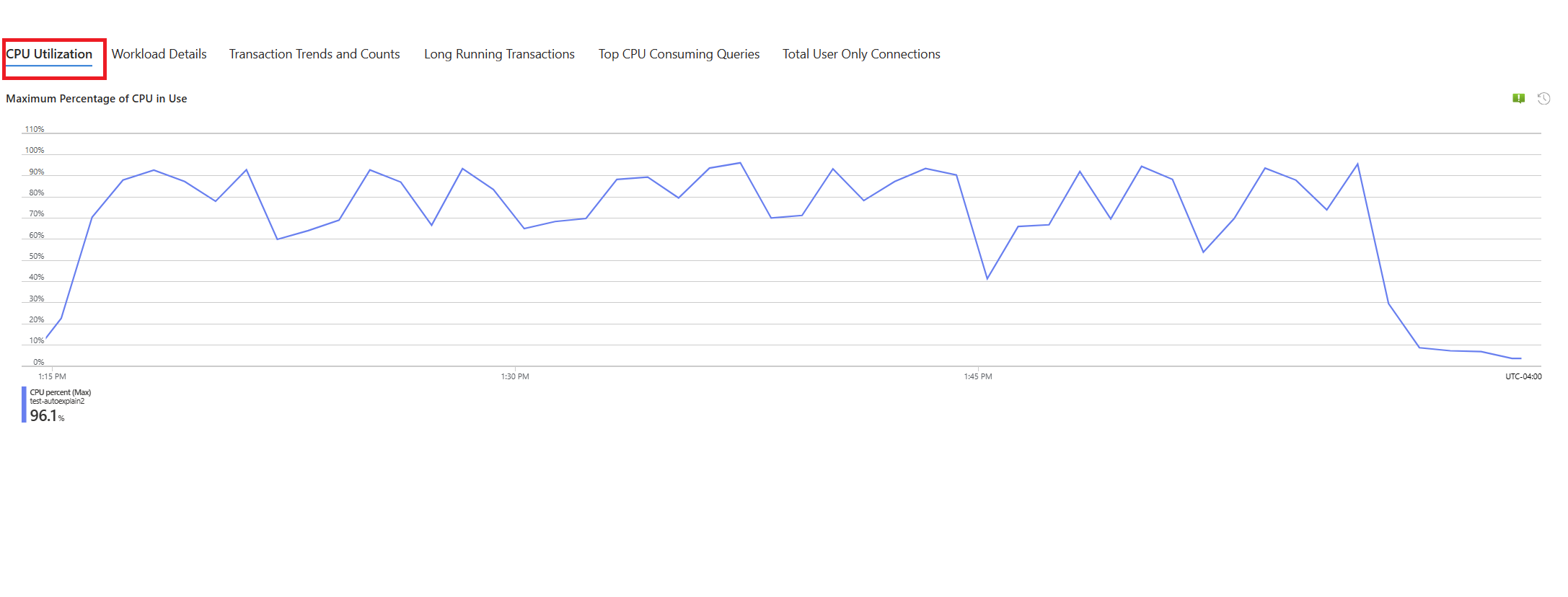
Wählen Sie die Registerkarte Abfragen aus. Hier werden die Details zu allen Abfragen angezeigt, die in dem Intervall ausgeführt wurden, in dem CPU-Auslastungsspitzen von 90 % vorlagen. Die Momentaufnahme lässt darauf schließen, dass die Abfrage mit der langsamsten durchschnittlichen Ausführungszeit während des Zeitintervalls ca. 2,6 Minuten benötigte und während des Intervalls 22 Mal ausgeführt wurde. Diese Abfrage ist höchstwahrscheinlich die Ursache der CPU-Auslastungsspitzen.
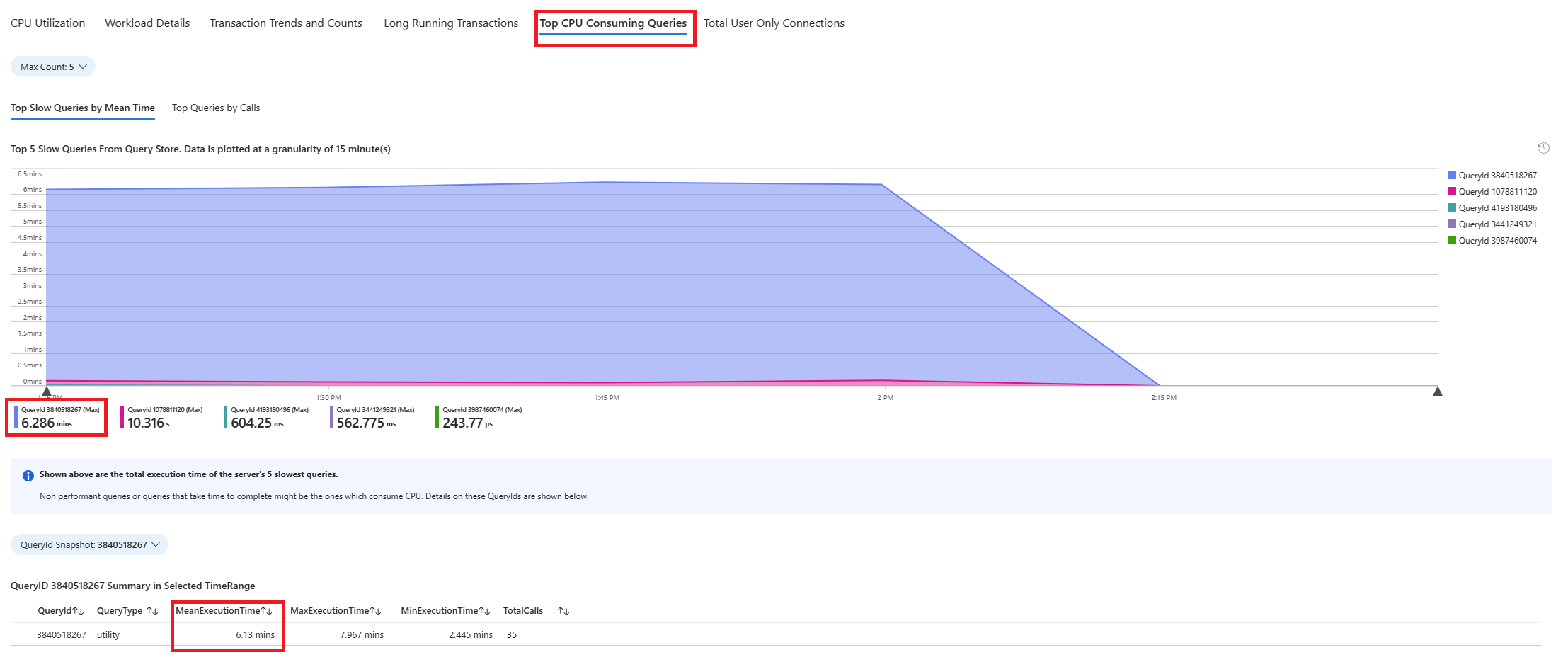
Stellen Sie eine Verbindung mit der azure_sys-Datenbank her, und verwenden Sie das folgende Skript, um den tatsächlichen Abfragetext abzurufen.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- Im Beispiel war die als langsam identifizierte Abfrage eine gespeicherte Prozedur:
call autoexplain_test ();
- Verwenden Sie Protokolle von Azure Database für PostgreSQL, um zu verstehen, welche genauen Ausführungspläne generiert wurden. Jedes Mal, wenn die Abfrage während dieses Zeitfensters ausgeführt wurde, sollte die
auto_explain-Erweiterung einen Eintrag in die Protokolle schreiben. Wählen Sie im Ressourcenmenü im Abschnitt Überwachung die Option Protokolle aus. Wählen Sie dann unter Zeitbereich: das Zeitfenster aus, auf das Sie die Analyse konzentrieren möchten.

- Führen Sie die folgende Abfrage aus, um die „explain analyze“-Ausgabe der identifizierten Abfrage zu erhalten.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Die Prozedur enthält mehrere Abfragen, die unten hervorgehoben sind. Die „Analyse erläutern“-Ausgabe jeder Abfrage, die in der gespeicherten Prozedur verwendet wird, wird protokolliert, um weitere Analysen und Problembehandlungen zu ermöglichen. Die Ausführungszeit der protokollierten Abfragen kann verwendet werden, um die langsamsten Abfragen zu identifizieren, die Teil der gespeicherten Prozedur sind.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Hinweis
Zu Demonstrationszwecken wird lediglich die EXPLAIN ANALYZE-Ausgaben von einigen in der Prozedur verwendeten Abfragen gezeigt. Die Idee dahinter ist, dass Sie die EXPLAIN ANALYZE-Ausgabe aller Abfragen aus den Protokollen sammeln, die langsamsten identifizieren und dann versuchen können, sie zu optimieren.
Verwandte Inhalte
- Problembehandlung bei hoher CPU-Auslastung in Azure-Datenbank für PostgreSQL.
- Problembehandlung bei hoher IOPS-Auslastung in Azure Database for PostgreSQL.
- Behandeln von Problemen mit hoher Speicherauslastung in Azure Database for PostgreSQL.
- Serverparameter in Azure-Datenbank für PostgreSQL.
- Autovacuum-Optimierung in Azure Database für PostgreSQL.