Scans und Erfassung in Microsoft Purview
Dieser Artikel bietet eine Übersicht über die Scan- und Erfassungsfeatures in Microsoft Purview. Diese Features verbinden Ihr Microsoft Purview-Konto mit Ihren Quellen, um die Datenzuordnung und die Unified Catalog aufzufüllen, sodass Sie mit der Untersuchung und Verwaltung Ihrer Daten über Microsoft Purview beginnen können.
- Bei der Überprüfung werden Metadaten aus Datenquellen erfasst und in Microsoft Purview bereitgestellt.
-
Die Erfassung verarbeitet Metadaten und speichert sie in Unified Catalog aus beiden:
- Datenquellenscans: Gescannte Metadaten werden dem Microsoft Purview Data Map hinzugefügt.
- Herkunftsverbindungen: Transformationsressourcen fügen Metadaten zu ihren Quellen, Ausgaben und Aktivitäten zum Microsoft Purview Data Map hinzu.
Analyse
Nachdem Datenquellen in Ihrem Microsoft Purview-Konto registriert wurden, besteht der nächste Schritt darin, die Datenquellen zu überprüfen. Der Überprüfungsprozess stellt eine Verbindung mit der Datenquelle her und erfasst technische Metadaten wie Namen, Dateigröße, Spalten usw. Außerdem werden Schemas für strukturierte Datenquellen extrahiert, Klassifizierungen auf Schemas angewendet und Vertraulichkeitsbezeichnungen angewendet, wenn Ihr Microsoft Purview Data Map mit einem Microsoft Purview-Complianceportal verbunden ist. Der Überprüfungsprozess kann so ausgelöst werden, dass er sofort ausgeführt wird oder regelmäßig ausgeführt werden kann, um Ihr Microsoft Purview-Konto auf dem neuesten Stand zu halten.
Für jede Überprüfung gibt es Anpassungen, die Sie anwenden können, sodass Sie nur die benötigten Informationen und nicht die gesamte Quelle überprüfen.
Auswählen einer Authentifizierungsmethode für Ihre Überprüfungen
Microsoft Purview ist standardmäßig sicher. Kennwörter oder Geheimnisse werden nicht direkt in Microsoft Purview gespeichert, sodass Sie eine Authentifizierungsmethode für Ihre Quellen auswählen müssen. Es gibt mehrere Möglichkeiten zum Authentifizieren Ihres Microsoft Purview-Kontos, aber nicht alle Methoden werden für jede Datenquelle unterstützt.
- Verwaltete Identität
- Dienstprinzipal
- SQL-Authentifizierung
- Windows-Authentifizierung
- Rollen-ARN
- Delegierte Authentifizierung
- Consumerschlüssel
- Kontoschlüssel oder Standardauthentifizierung
Nach Möglichkeit ist eine verwaltete Identität die bevorzugte Authentifizierungsmethode, da dadurch das Speichern und Verwalten von Anmeldeinformationen für einzelne Datenquellen entfällt. Dies kann die Zeit, die Sie und Ihr Team für die Einrichtung und Problembehandlung der Authentifizierung für Überprüfungen aufwenden, erheblich reduzieren. Wenn Sie eine verwaltete Identität für Ihr Microsoft Purview-Konto aktivieren, wird eine Identität in Microsoft Entra ID erstellt und an den Lebenszyklus Ihres Kontos gebunden.
Festlegen des Scanbereichs
Beim Scannen einer Quelle können Sie die gesamte Datenquelle überprüfen oder nur bestimmte Entitäten (Ordner/Tabellen) zum Scannen auswählen. Die verfügbaren Optionen hängen von der Quelle ab, die Sie überprüfen, und sie können sowohl für einmalige als auch für geplante Überprüfungen definiert werden.
Wenn Sie beispielsweise eine Überprüfung für eine Azure SQL Datenbank erstellen und ausführen, können Sie auswählen, welche Tabellen überprüft werden sollen, oder die gesamte Datenbank auswählen.
Für jede Entität (Ordner/Tabelle) gibt es drei Auswahlzustände: vollständig ausgewählt, teilweise ausgewählt und nicht ausgewählt. Wenn Sie im folgenden Beispiel in der Ordnerhierarchie "Abteilung 1" auswählen, gilt "Abteilung 1" als vollständig ausgewählt. Die übergeordneten Entitäten für "Abteilung 1" wie "Unternehmen" und "Beispiel" werden als teilweise ausgewählt betrachtet, da andere Entitäten unter demselben übergeordneten Element nicht ausgewählt wurden, z. B. "Abteilung 2". Verschiedene Symbole werden auf der Benutzeroberfläche für Entitäten mit unterschiedlichen Auswahlzuständen verwendet.
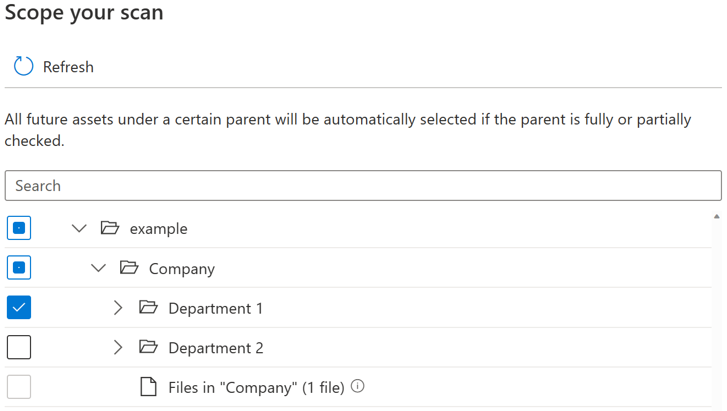
Nachdem Sie die Überprüfung ausgeführt haben, werden dem Quellsystem wahrscheinlich neue Ressourcen hinzugefügt. Standardmäßig werden die zukünftigen Ressourcen unter einem bestimmten übergeordneten Element automatisch ausgewählt, wenn das übergeordnete Element vollständig oder teilweise ausgewählt ist, wenn Sie die Überprüfung erneut ausführen. Nachdem Sie im obigen Beispiel "Abteilung 1" ausgewählt und die Überprüfung ausgeführt haben, werden alle neuen Ressourcen im Ordner "Abteilung 1" oder unter "Unternehmen" und "Beispiel" eingeschlossen, wenn Sie die Überprüfung erneut ausführen.
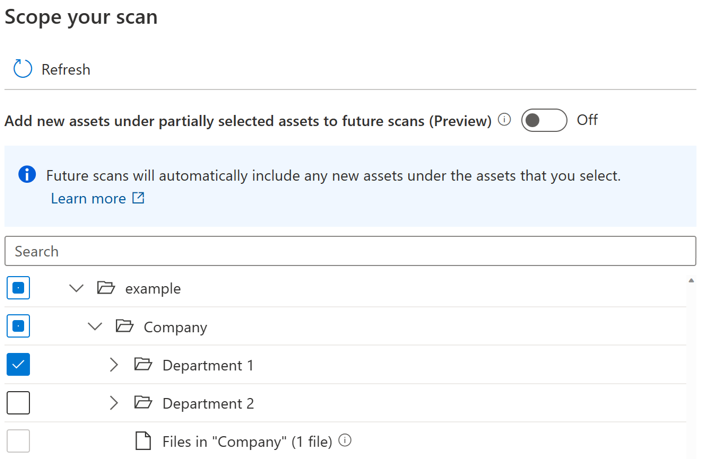
Es wird eine Umschaltfläche für Benutzer eingeführt, um die automatische Aufnahme für neue Ressourcen unter teilweise ausgewähltem übergeordnetem Element zu steuern. Standardmäßig wird der Umschalter deaktiviert, und das automatische Einschlussverhalten für teilweise ausgewählte übergeordnete Elemente ist deaktiviert. Im selben Beispiel, in dem die Umschaltfläche deaktiviert ist, werden alle neuen Ressourcen unter teilweise ausgewählten übergeordneten Elementen wie "Unternehmen" und "Beispiel" nicht einbezogen, wenn Sie die Überprüfung erneut ausführen. In der zukünftigen Überprüfung werden nur neue Ressourcen unter "Abteilung 1" einbezogen.
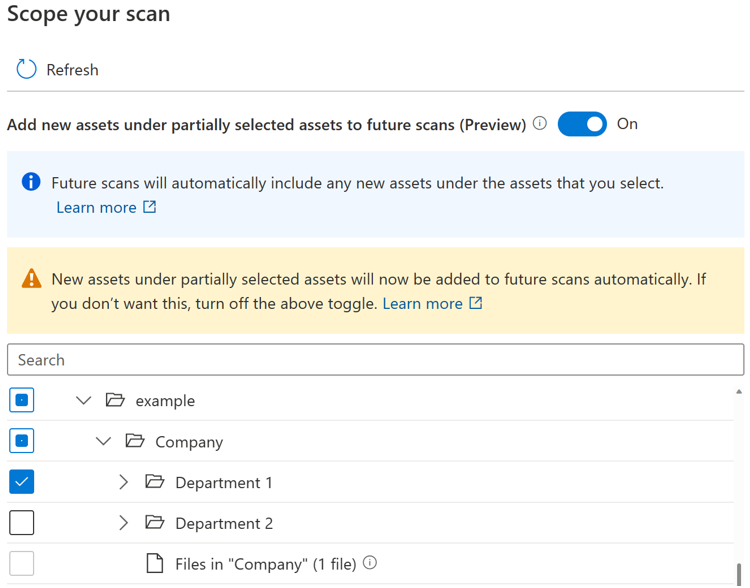
Wenn die Umschaltfläche aktiviert ist, werden die neuen Ressourcen unter einem bestimmten übergeordneten Element automatisch ausgewählt, wenn das übergeordnete Element vollständig oder teilweise ausgewählt ist, wenn Sie die Überprüfung erneut ausführen. Das Einschlussverhalten ist dasselbe wie vor der Einführung der Umschaltfläche.
Hinweis
- Die Verfügbarkeit der Umschaltfläche hängt vom Datenquellentyp ab. Derzeit ist es in der öffentlichen Vorschau für Quellen verfügbar, einschließlich Azure Blob Storage, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, Azure Files und Azure Dedicated SQL-Pool (früher SQL DW).
- Für alle Überprüfungen, die vor der Einführung der Umschaltfläche erstellt oder geplant wurden, wird der Umschaltzustand auf On festgelegt und kann nicht geändert werden. Bei überprüfungen, die erstellt oder geplant wurden, nachdem die Umschaltfläche eingeführt wurde, kann der Umschaltzustand nach dem Speichern der Überprüfung nicht geändert werden. Sie müssen eine neue Überprüfung erstellen, um den Umschaltzustand zu ändern.
- Wenn die Umschaltfläche deaktiviert ist, kann es für Quellen mit Speichertyp wie Azure Data Lake Storage Gen 2 bis zu 4 Stunden dauern, bis das Durchsuchen nach Quelltyp nach Abschluss des Scanauftrags vollständig verfügbar ist.
Bekannte Einschränkungen
Wenn die Umschaltfläche deaktiviert ist:
- Die Dateientitäten unter einem teilweise ausgewählten übergeordneten Element werden nicht überprüft.
- Wenn alle vorhandenen Entitäten unter einem übergeordneten Element explizit ausgewählt sind, gilt das übergeordnete Element als vollständig ausgewählt, und alle neuen Ressourcen unter dem übergeordneten Element werden einbezogen, wenn Sie die Überprüfung erneut ausführen.
Anpassen der Scanebene
In Microsoft Purview Data Map Terminologie gibt es basierend auf dem Metadatenbereich und den Funktionen drei verschiedene Scanebenen:
- L1-Scan: Extrahiert grundlegende Informationen und Metadaten wie Dateiname, Größe und vollqualifizierter Name
- L2-Überprüfung: Extrahiert das Schema für strukturierte Dateitypen und Datenbanktabellen.
- L3-Überprüfung: Extrahiert ggf. das Schema und unterzieht die Stichprobendatei dem System und benutzerdefinierten Klassifizierungsregeln.
Wenn Sie eine neue Überprüfung einrichten oder eine vorhandene Überprüfung bearbeiten, können Sie die Überprüfungsebene für die Überprüfung von Datenquellen anpassen, die die Konfiguration der Scanebene bereits unterstützt haben.

Standardmäßig wird "Automatische Erkennung" ausgewählt, was bedeutet, dass Microsoft Purview die höchste für diese Datenquelle verfügbare Überprüfungsstufe anwendet. Nehmen wir Azure SQL Datenbank als Beispiel: Die automatische Erkennung wird als "Level-3" aufgelöst, wenn die Überprüfung ausgeführt wird, da die Datenquelle bereits die Klassifizierung in Microsoft Purview unterstützt hat. Die Überprüfungsebene in den Details zur Überprüfungsausführung zeigt die tatsächlich angewendete Ebene an.

Für alle Scanausführungen im Scanverlauf, die abgeschlossen wurden, bevor die Überprüfungsebene als neues Feature eingeführt wurde, wird die Scanebene standardmäßig festgelegt und als "Automatische Erkennung" angezeigt.

- Wenn eine höhere Scanebene für eine Datenquelle verfügbar wird, wenden die gespeicherten oder geplanten Überprüfungen, für die die Überprüfungsebene auf "Automatisch erkennen" festgelegt ist, automatisch die neue Scanebene an. Wenn z. B. die Klassifizierung als neues Feature für eine bestimmte Datenquelle aktiviert ist, wenden alle vorhandenen Überprüfungen für diese Datenquelle automatisch die Klassifizierung an.
- Die Einstellung der Scanebene wird in der Scanüberwachungsschnittstelle für jeden Scanlauf angezeigt.
- Wenn "Level-1" ausgewählt ist, gibt die Überprüfung nur grundlegende technische Metadaten wie Ressourcenname, Ressourcengröße, geänderter Zeitstempel usw. basierend auf der vorhandenen Metadatenverfügbarkeit einer bestimmten Datenquelle zurück. Für Azure SQL-Datenbank werden Ressourcenentitäten wie Tabellen in Microsoft Purview Data Map ohne Tabellenschemaextraktion erstellt. (Hinweis: Benutzer können das Tabellenschema weiterhin über die Liveansicht anzeigen, wenn sie über die erforderlichen Berechtigungen im Quellsystem verfügen.)
- Wenn "Level-2" ausgewählt ist, gibt die Überprüfung Tabellenschemas und grundlegende technische Metadaten zurück, aber die Datenstichproben und -klassifizierungen werden nicht durchgeführt. Für Azure SQL-Datenbank verfügen Entitäten von Tabellenobjekten über ein Tabellenschema, das ohne Klassifizierungsinformationen erfasst wurde.)
- Wenn "Level-3" ausgewählt ist, führt die Überprüfung die Stichprobenentnahme und Klassifizierung der Daten durch. Dies ist eine Standardkonfiguration für Azure SQL Datenbanküberprüfung, bevor die Überprüfungsebene als neues Feature eingeführt wird.
- Wenn eine geplante Überprüfung auf eine niedrigere Überprüfungsstufe festgelegt und später auf eine höhere Überprüfungsebene geändert wird, führt die nächste Überprüfungsausführung automatisch eine vollständige Überprüfung durch, und alle vorhandenen Datenressourcen aus der Datenquelle werden mit Metadaten aktualisiert, die durch eine höhere Einstellung der Überprüfungsebene eingeführt werden. Wenn beispielsweise ein geplanter Scansatz mit "Level-2" für eine Azure SQL-Datenbank in "Level-3" geändert wird, ist die nächste Überprüfungsausführung eine vollständige Überprüfung, und alle vorhandenen Azure SQL Datenbanktabellen-/Ansichtsressourcen werden mit Klassifizierungsinformationen aktualisiert, und alle überprüfungen danach werden als inkrementelle Überprüfungen fortgesetzt, die mit "Level-3" festgelegt sind.
- Wenn eine geplante Überprüfung auf eine höhere Überprüfungsebene festgelegt und später auf eine niedrigere Überprüfungsebene geändert wird, wird bei der nächsten Überprüfungsausführung weiterhin eine inkrementelle Überprüfung durchgeführt, und alle neuen Datenressourcen aus der Datenquelle verfügen nur über Metadaten, die durch eine niedrigere Einstellung der Überprüfungsebene eingeführt werden. Wenn beispielsweise ein geplanter Scansatz mit "Level-3" für eine Azure SQL Datenbank in "Level-2" geändert wird, ist die nächste Überprüfungsausführung eine inkrementelle Überprüfung, und alle neuen Azure SQL Datenbanktabellen-/Sichtressourcen, die in Microsoft Purview Data Map hinzugefügt wurden, enthalten keine Klassifizierungsinformationen. Alle vorhandenen Datenressourcen behalten weiterhin die Klassifizierungsinformationen bei, die aus dem vorherigen Scansatz mit "Level-3" generiert wurden.
Hinweis
- Das Anpassen der Überprüfungsebene ist derzeit für die folgenden Datenquellen verfügbar: Azure SQL Database, Azure SQL Managed Instance, Azure Cosmos DB for NoSQL, Azure Database for PostgreSQL, Azure Database for MySQL, Azure Data Lake Storage Gen2, Azure Blob Storage, Azure Files, Azure Synapse Analytics, Azure Dedicated SQL-Pool (früher SQL DW), Azure Data Explorer, Dataverse, Azure Multiple (Azure-Abonnement), Azure Multiple (Azure-Ressourcengruppe), Snowflake, Azure Databricks Unity Catalog
- Derzeit ist das Feature nur in Azure IR und Managed VNet IR v2 verfügbar.
Regelsatz überprüfen
Ein Überprüfungsregelsatz bestimmt die Arten von Informationen, nach denen eine Überprüfung sucht, wenn sie für eine Ihrer Quellen ausgeführt wird. Die verfügbaren Regeln hängen von der Art der Quelle ab, die Sie überprüfen, enthalten jedoch Elemente wie die Dateitypen , die Sie überprüfen sollten, und die Arten von Klassifizierungen , die Sie benötigen.
Es gibt bereits Systemscanregelsätze für viele Datenquellentypen, aber Sie können auch eigene Scanregelsätze erstellen, um Ihre Überprüfungen an Ihre organization anzupassen.
Planen der Überprüfung
Microsoft Purview bietet Ihnen die Wahl zwischen täglichen, wöchentlichen oder monatlichen Überprüfungen zu einem von Ihnen gewählten Zeitpunkt. Erfahren Sie mehr über die unterstützten Zeitplanoptionen. Tägliche oder wöchentliche Überprüfungen können für Datenquellen mit Strukturen geeignet sein, die sich aktiv in der Entwicklung befinden oder sich häufig ändern. Die monatliche Überprüfung eignet sich besser für Datenquellen, die sich selten ändern. Die bewährte Methode besteht darin, mit dem Administrator der Quelle zusammenzuarbeiten, die Sie überprüfen möchten, um einen Zeitpunkt zu identifizieren, zu dem die Computeanforderungen für die Quelle gering sind.
So erkennen Überprüfungen gelöschte Ressourcen
Ein Microsoft Purview-Katalog erkennt den Zustand eines Datenspeichers nur, wenn er eine Überprüfung ausführt. Damit der Katalog weiß, ob eine Datei, Tabelle oder ein Container gelöscht wurde, vergleicht er die letzte Scanausgabe mit der aktuellen Scanausgabe. Angenommen, beim letzten Scannen eines Azure Data Lake Storage Gen2 Kontos wurde ein Ordner namens folder1 enthalten. Wenn dasselbe Konto erneut gescannt wird, fehlt folder1 . Daher geht der Katalog davon aus, dass der Ordner gelöscht wurde.
Tipp
Aufgrund der Art, wie gelöschte Dateien erkannt werden, sind möglicherweise mehrere erfolgreiche Überprüfungen erforderlich, um gelöschte Ressourcen zu erkennen und aufzulösen. Wenn Unified Catalog keine Löschungen für eine bereichsbezogene Überprüfung registriert, versuchen Sie es mit mehreren vollständigen Überprüfungen, um das Problem zu beheben.
Erkennen gelöschter Dateien
Die Logik zum Erkennen fehlender Dateien funktioniert für mehrere Überprüfungen durch denselben Benutzer und durch verschiedene Benutzer. Angenommen, ein Benutzer führt eine einmalige Überprüfung für einen Data Lake Storage Gen2 Datenspeicher in den Ordnern A, B und C aus. Später führt ein anderer Benutzer im selben Konto eine andere einmalige Überprüfung für die Ordner C, D und E desselben Datenspeichers aus. Da Ordner C zweimal überprüft wurde, überprüft der Katalog ihn auf mögliche Löschungen. Die Ordner A, B, D und E wurden jedoch nur einmal überprüft, und der Katalog überprüft sie nicht auf gelöschte Ressourcen.
Um gelöschte Dateien aus Ihrem Katalog zu entfernen, ist es wichtig, regelmäßige Überprüfungen durchzuführen. Das Überprüfungsintervall ist wichtig, da der Katalog gelöschte Ressourcen erst erkennen kann, wenn eine andere Überprüfung ausgeführt wird. Wenn Sie also einmal pro Monat Überprüfungen für einen bestimmten Speicher ausführen, kann der Katalog keine gelöschten Datenressourcen in diesem Speicher erkennen, bis Sie die nächste Überprüfung einen Monat später ausführen.
Wenn Sie große Datenspeicher wie Data Lake Storage Gen2 auflisten, gibt es mehrere Möglichkeiten (einschließlich Enumerationsfehlern und verworfenen Ereignissen), Um Informationen zu verpassen. Bei einer bestimmten Überprüfung kann es vorkommen, dass eine Datei erstellt oder gelöscht wurde. Es sei denn, der Katalog ist sicher, dass eine Datei gelöscht wurde, wird sie nicht aus dem Katalog gelöscht. Diese Strategie bedeutet, dass Fehler auftreten können, wenn eine Datei, die nicht im gescannten Datenspeicher vorhanden ist, noch im Katalog vorhanden ist. In einigen Fällen muss ein Datenspeicher möglicherweise zwei- oder dreimal überprüft werden, bevor er bestimmte gelöschte Ressourcen abfängt.
Hinweis
- Objekte, die zum Löschen markiert sind, werden nach einer erfolgreichen Überprüfung gelöscht. Gelöschte Ressourcen sind möglicherweise noch einige Zeit in Ihrem Katalog sichtbar, bevor sie verarbeitet und entfernt werden.
- Die Löscherkennung wird nur für diese Quellen in Microsoft Purview unterstützt: Azure Synapse Analytics-Arbeitsbereiche, Azure Arc-fähige SQL Server, Azure Blob Storage, Azure Files, Azure Cosmos DB, Azure Data Explorer, Azure Database for MySQL, Azure Database for PostgreSQL, Azure Dedicated SQL-Pool, Azure Machine Learning, Azure SQL-Datenbank und Azure SQL Managed instance. Wenn für diese Quellen ein Medienobjekt aus der Datenquelle gelöscht wird, werden bei nachfolgenden Überprüfungen automatisch die entsprechenden Metadaten und die Herkunft in Microsoft Purview entfernt.
Ingestion
Die Erfassung ist der Prozess, der für das Auffüllen der Data Map mit Metadaten verantwortlich ist, die über die verschiedenen Prozesse gesammelt wurden.
Erfassung aus Überprüfungen
Die durch den Scanvorgang identifizierten technischen Metadaten oder Klassifizierungen werden dann an die Erfassung gesendet. Die Erfassung analysiert die Eingaben aus dem Scan, wendet Ressourcensatzmuster an, füllt verfügbare Herkunftsinformationen auf und lädt dann die Datenzuordnung automatisch. Objekte/Schemas können erst nach Abschluss der Erfassung ermittelt oder zusammengestellt werden. Wenn ihre Überprüfung abgeschlossen ist, Sie ihre Ressourcen jedoch nicht in der Data Map oder im Katalog gesehen haben, müssen Sie warten, bis der Erfassungsprozess abgeschlossen ist.
Erfassung aus Herkunftsverbindungen
Ressourcen wie Azure Data Factory und Azure Synapse können mit Microsoft Purview verbunden werden, um Datenquellen- und Herkunftsinformationen in Ihre Microsoft Purview Data Map. Wenn beispielsweise eine Kopierpipeline in einer Azure Data Factory ausgeführt wird, die mit Microsoft Purview verbunden wurde, werden Metadaten zu den Eingabequellen, der Aktivität und den Ausgabequellen in Microsoft Purview erfasst, und die Informationen werden der Data Map hinzugefügt.
Wenn der Data Map bereits über einen Scan eine Datenquelle hinzugefügt wurde, werden der vorhandenen Quelle Herkunftsinformationen zur Aktivität hinzugefügt. Wenn die Datenquelle der Datenzuordnung noch nicht hinzugefügt wurde, fügt der Datenherkunftserfassungsprozess sie der Stammauflistung mit ihren Herkunftsinformationen hinzu.
Weitere Informationen zu den verfügbaren Herkunftsverbindungen finden Sie im Benutzerhandbuch zur Herkunft.
Nächste Schritte
Weitere Informationen oder spezifische Anweisungen zum Überprüfen von Quellen finden Sie unter den folgenden Links.
- Informationen zu Ressourcensätzen finden Sie in unserem Artikel zu Ressourcensätzen.
- Steuern einer Azure SQL-Datenbank
- Herkunft in Microsoft Purview