Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Managed Redis wird auf dem Redis Enterprise-Stapel ausgeführt, der gegenüber der Community-Edition von Redis erhebliche Vorteile bietet. Im Folgenden finden Sie ausführlichere Informationen zur Architektur von Azure Managed Redis, die auch für Power-Benutzer nützlich sein können.
Vergleich mit Azure Cache for Redis
Die Stufen "Basic", "Standard" und "Premium" von Azure Cache für Redis werden auf der Community-Edition von Redis ausgeführt. Diese Communityversion von Redis hat mehrere erhebliche Einschränkungen, u. a. das Singlethread-Design. Diese Einschränkung reduziert die Leistung erheblich und macht die Skalierung weniger effizient, da der Dienst nicht vollständig mehr vCPUs nutzt. Eine typische Azure Cache for Redis-Instanz verwendet eine Architektur wie die folgende:
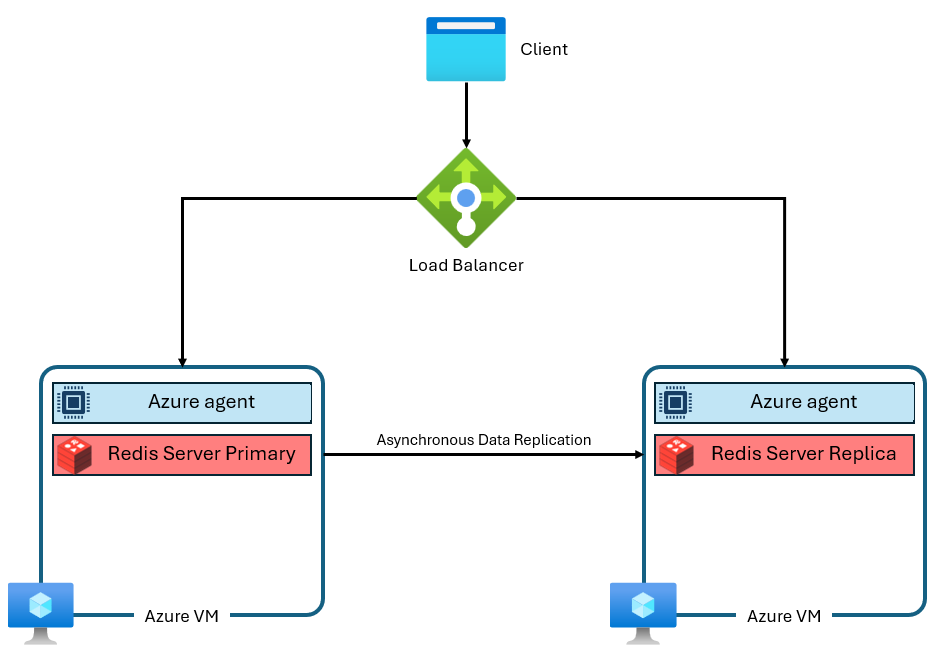
Beachten Sie, dass zwei virtuelle Computer verwendet werden – ein primäres und ein Replikat. Diese virtuellen Computer werden auch als Knoten bezeichnet. Der primäre Knoten enthält den Redis-Hauptprozess und akzeptiert alle Schreibvorgänge. Die Replikation wird asynchron auf den Replikatknoten durchgeführt, um während Wartung, Skalierung oder unerwarteten Ausfällen eine Sicherungskopie bereitzustellen. Jeder Knoten kann aufgrund des Singlethread-Designs von Community Redis nur einen einzelnen Redis-Serverprozess ausführen.
Architekturverbesserungen von Azure Managed Redis
Azure Managed Redis verwendet eine komplexere Architektur, die ungefähr wie folgt aussieht:
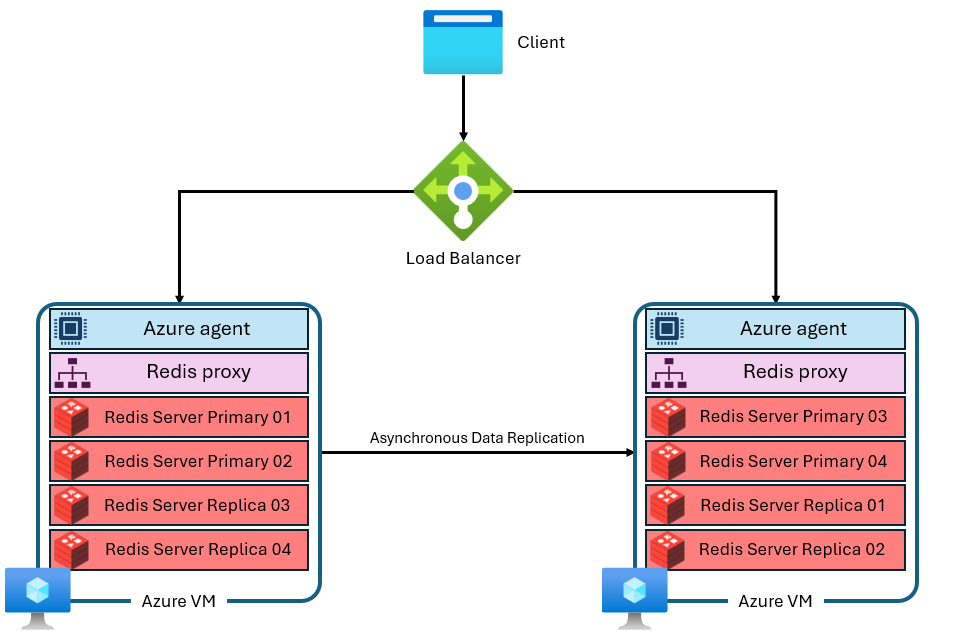
Es gibt mehrere Unterschiede:
- Jeder virtuelle Computer (oder Knoten) führt mehrere Redis-Serverprozesse (als Shards bezeichnet) parallel aus. Mehrere Shards ermöglichen eine effizientere Nutzung von vCPUs auf jedem virtuellen Computer und eine höhere Leistung.
- Nicht alle primären Redis-Shards befinden sich auf demselben virtuellen Computer/Knoten. Stattdessen werden primäre und Replikatshards über beide Knoten verteilt. Da primäre Shards mehr CPU-Ressourcen als Replikatshards verwenden, ermöglicht dieser Ansatz die parallele Ausführung von primären Shards.
- Jeder Knoten verfügt über einen leistungsstarken Proxy-Prozess, um die Shards zu verwalten, die Verbindungsverwaltung auszuführen und Self-healing auszulösen.
Diese Architektur ermöglicht sowohl höhere Leistung als auch erweiterte Features wie die aktive Georeplikation.
Clusterbildung
Jede azure Managed Redis-Instanz ist intern für die Verwendung von Clustern auf allen Ebenen und SKUs konfiguriert. Azure Managed Redis basiert auf Redis Enterprise, das mehrere Shards pro Knoten verwenden kann. Diese Funktion enthält kleinere Instanzen, die nur für die Verwendung eines einzelnen Shards eingerichtet sind. Clustering ist eine Möglichkeit, die Daten in der Redis-Instanz über mehrere Redis-Prozesse aufzuteilen, auch als Sharding bezeichnet. Azure Managed Redis bietet drei Clusterrichtlinien , die bestimmen, welches Protokoll für Redis-Clients für die Verbindung mit der Cacheinstanz verfügbar ist.
Clusterrichtlinien
Azure Managed Redis bietet drei Clusteringrichtlinien: OSS, Unternehmen und nicht geclustert. Die OSS-Clusterrichtlinie eignet sich für die meisten Anwendungen, da sie einen höheren maximalen Durchsatz unterstützt, aber jede Version hat ihre eigenen Vor- und Nachteile.
- Wenn Sie aus einer nicht gruppierten Standard- oder Premium-Topologie wechseln, sollten Sie die Verwendung von OSS-Clustering in Betracht ziehen, um die Leistung zu verbessern. Verwenden Sie nicht gruppierte Konfigurationen nur, wenn Ihre Anwendung osS- oder Enterprise-Topologien nicht unterstützen kann. Die OSS-Clustering-Richtlinie implementiert dieselbe API wie Open-Source-Software von Redis. Die Redis-Cluster-API ermöglicht dem Redis-Client, eine direkte Verbindung mit Shards auf jedem Redis-Knoten herzustellen, die Latenz zu minimieren und den Netzwerkdurchsatz zu optimieren. Der Durchsatz skaliert nahezu linear, da die Anzahl der Shards und vCPUs zunimmt. Die OSS-Clusteringrichtlinie bietet in der Regel die niedrigste Latenz und beste Durchsatzleistung. Die OSS-Clusterrichtlinie erfordert jedoch, dass Ihre Clientbibliothek die Redis-Cluster-API unterstützt. Heute unterstützen fast alle Redis-Clients die Redis Cluster-API, aber die Kompatibilität kann ein Problem für ältere Clientversionen oder spezielle Bibliotheken sein.
Sie können die OSS-Clusteringrichtlinie nicht mit dem RediSearch-Modul verwenden.
Das OSS-Clusteringprotokoll erfordert, dass der Client die richtigen Shardverbindungen herstellen kann. Die erste Verbindung erfolgt über Port 10000. Beim Herstellen einer Verbindung mit einzelnen Knoten werden Ports im 85XX-Bereich verwendet. Die 85xx-Ports können sich im Laufe der Zeit ändern, und Sie sollten sie nicht in Ihre Anwendung hartcodieren. Redis-Clients, die das Clustering unterstützen, verwenden den BEFEHL CLUSTERKNOTEN , um die genauen Ports zu ermitteln, die für die primären und Replikatshards verwendet werden, und machen die Shardverbindungen für Sie.
Die Enterprise-Clustering-Richtlinie ist eine einfachere Konfiguration, die einen einzelnen Endpunkt für alle Clientverbindungen verwendet. Wenn Sie die Enterprise-Clustering-Richtlinie verwenden, leitet sie alle Anforderungen an einen einzelnen Redis-Knoten weiter, der als Proxy fungiert. Dieser Knoten leitet Intern Anforderungen an den richtigen Knoten im Cluster weiter. Der Vorteil dieses Ansatzes besteht darin, dass Azure Managed Redis für Benutzer nicht gruppiert aussieht. Dies bedeutet, dass Redis-Clientbibliotheken Redis Clustering nicht unterstützen müssen, um einige der Leistungsvorteile von Redis Enterprise zu erzielen. Die Verwendung eines einzelnen Endpunkts erhöht die Abwärtskompatibilität und vereinfacht die Verbindung. Der Nachteil besteht darin, dass ein einzelner Knoten-Proxy ein Engpass bei der Rechenauslastung oder beim Netzwerkdurchsatz sein kann.
Die Enterprise-Clustering-Richtlinie ist die einzige, die Sie mit dem RediSearch-Modul verwenden können. Während die Enterprise-Clusterrichtlinie eine Azure Managed Redis-Instanz für Benutzer als nicht gruppiert erscheinen lässt, hat sie dennoch einige Einschränkungen bei Befehlen mit mehreren Tasten.
Die Clusteringrichtlinie für nicht geclustert speichert Daten auf jedem Knoten ohne Sharding. Sie gilt nur für Caches mit einer Größe von 25 GB und kleiner. Zu den Szenarien für die Verwendung der nicht gruppierten Clusterringrichtlinie gehören:
- Bei der Migration von einer Redis-Umgebung, die nicht fragmentiert ist. Beispielsweise die nicht geshardeten Topologien von Basic-, Standard- und Premium-SKUs von Azure Cache für Redis.
- Wenn Sie viele Cross Slot-Befehle ausführen und Daten in Shards aufteilen, führt das zu Fehlern. Beispielsweise die MULTI-Befehle.
- Wenn Sie Redis als Nachrichtenbroker verwenden und keine Sharding benötigen.
Die Überlegungen zur Verwendung einer nicht gruppierten Richtlinie sind:
- Diese Richtlinie gilt nur für Azure Managed Redis-Ebenen, die kleiner oder gleich 25 GB sind.
- Es ist nicht so leistungsfähig wie andere Clusteringrichtlinien, da CPUs nur Multithread mit Redis Enterprise-Software verwenden können, wenn der Cache abgeshardet wird.
- Wenn Sie Ihren Azure Managed Redis-Cache skalieren möchten, müssen Sie zuerst die Clusterrichtlinie ändern.
- Wenn Sie aus einer nicht gruppierten Standard- oder Premium-Topologie wechseln, sollten Sie die Verwendung von OSS-Clustern in Betracht ziehen, um die Leistung zu verbessern. Verwenden Sie nicht gruppierte Konfigurationen nur, wenn Ihre Anwendung osS- oder Enterprise-Topologien nicht unterstützen kann.
Aufskalieren oder Hinzufügen von Knoten
Die Redis Enterprise-Kernsoftware nimmt mithilfe größerer VMs eine vertikale Skalierung oder durch das Hinzufügen weiterer Knoten oder VMs eine horizontale Skalierung vor. Beide Skalierungsoptionen fügen mehr Arbeitsspeicher, mehr vCPUs und mehr Shards hinzu. Aufgrund dieser Redundanz bietet Azure Managed Redis nicht die Möglichkeit, die spezifische Anzahl der in jeder Konfiguration verwendeten Knoten zu steuern. Dieses Implementierungsdetail wird abstrahiert, um Verwirrung, Komplexität und suboptimale Konfigurationen zu vermeiden. Stattdessen wird jede SKU mit einer Knotenkonfiguration entworfen, die vCPUs und Arbeitsspeicher maximiert. Einige SKUs von Azure Managed Redis verwenden zwei Knoten, während andere mehr verwenden.
Befehle mit mehreren Schlüsseln
Da Azure Managed Redis-Instanzen eine gruppierte Konfiguration verwenden, können möglicherweise CROSSSLOT Ausnahmen bei Befehlen auftreten, die auf mehrere Schlüssel ausgeführt werden. Das Verhalten variiert je nach verwendeter Clusteringrichtlinie. Wenn Sie die OSS-Clustering-Richtlinie verwenden, müssen alle Schlüssel in mehrstufigen Befehlen demselben Hashplatz zugeordnet werden.
Bei Verwendung der Enterprise-Clusteringrichtlinie treten ggf. auch Fehler vom Typ CROSSSLOT auf. Nur die folgenden Multikeybefehle sind auf Slots mit Enterprise Clustering zugelassen: DEL, MSET, MGET, EXISTS, UNLINK und TOUCH.
In Active-Active Datenbanken können Mehrschlüssel-Schreibbefehle (DEL, MSET, UNLINK) nur auf Tasten ausgeführt werden, die sich im selben Steckplatz befinden. Die folgenden Mehrschlüsselbefehle sind jedoch in Active-Active-Datenbanken über die Slots hinweg zulässig: MGET, EXISTS, und TOUCH. Weitere Informationen finden Sie im Artikel zum Datenbankclustering unter Multi-key operations (Vorgänge mit mehreren Schlüsseln).
Shardingkonfiguration
Jede SKU von Azure Managed Redis führt parallel eine bestimmte Anzahl von Redis-Serverprozessen aus, die als Shards bezeichnet werden. Die Beziehung zwischen der Durchsatzleistung, der Anzahl der Shards und der Anzahl der für jede Instanz verfügbaren vCPUs ist komplex. Sie können die Anzahl der Shards nicht manuell ändern.
Bei einer bestimmten Arbeitsspeichergröße weist die version "Speicheroptimiert" die geringste Anzahl von vCPUs und Shards auf, während die computeoptimierte Version die höchste hat.
Das Erhöhen der Anzahl von Shards erhöht im Allgemeinen die Leistung, da Redis-Vorgänge parallel ausgeführt werden können. Wenn jedoch keine vCPUs zum Ausführen von Befehlen verfügbar sind, kann die Leistung fallen.
Shards werden zugeordnet, um die Verwendung jeder vCPU zu optimieren, während vCPU-Zyklen für den Redis-Serverprozess, verwaltungs-Agent und Betriebssystemaufgaben reserviert werden, die sich auch auf die Leistung auswirken. Die clientanwendungen, die Sie erstellen, interagieren mit Azure Managed Redis so, als ob es sich um eine einzelne logische Datenbank handelt. Der Dienst verarbeitet das Routing über die vCPUs und Shards hinweg.
Verwenden Sie zum Erhöhen der Anzahl der Shards in einer SKU eine größere Ebene in dieser SKU. Sie können die SKUs auch so ändern, dass sie Ihren Leistungsanforderungen entsprechen.
Die folgende Tabelle zeigt das Verhältnis der vCPUs zu den primären Shards bei einer bestimmten Ebenengröße. Die Daten in den Spalten stellen keine Garantie dar, dass dies die Anzahl der vCPUs oder Shards ist. Die Tabellen dienen nur zur Veranschaulichung.
Hinweis
Azure Managed Redis optimiert die Leistung im Laufe der Zeit, indem die Anzahl der Shards und vCPUs geändert wird, die für jede SKU verwendet werden.
Speicheroptimierte, ausgewogene und computeoptimierte Versionen
Diese Tabelle zeigt ein allgemeines Beispiel für die Beziehung von Size zu vCPUs/primären Shards.
| Ebenen | Arbeitsspeicheroptimiert | Ausgeglichen | Für Compute optimiert |
|---|---|---|---|
| Größe (GB) | vCPUs/primäre Shards | vCPUs/primäre Shards | vCPUs/primäre Shards |
| 24 ¹ | 4/2 | 8. Juni | 16/12 |
| 60 ¹ | 8. Juni | 16/12 | 32/24 |
¹ Das Verhältnis von vCPUs zu primären Shards bei einer bestimmten Ebenengröße stellt keine Garantie für die SKU oder Ebene dar.
Flash-optimierte Version
Diese Tabelle zeigt ein allgemeines Beispiel für die Beziehung von Size zu vCPUs/primären Shards.
| Ebenen | Flash optimiert (Vorschau) |
|---|---|
| Größe (GB) | vCPUs/primäre Shards |
| 480 ¹ ² | 16/12 |
| 720 ¹ ² | 24/24 |
¹ Diese Ebenen befinden sich in der öffentlichen Vorschau.
² Das Verhältnis von vCPUs zu primären Shards bei einer bestimmten Ebenengröße stellt keine Garantie für die SKU oder Ebene dar.
Von Bedeutung
Alle In-Memory-Ebenen, die mehr als 350 GB Speicherplatz verwenden, befinden sich in der öffentlichen Vorschau, einschließlich speicheroptimierter M500 und höher; ausbalancierter B500 und höher; sowie rechenoptimierter X500 und höher. Alle diese Ebenen und höher befinden sich in der öffentlichen Vorschau.
Alle für Flash optimierten Ebenen befinden sich in der öffentlichen Vorschau.
Ausführung ohne aktivierten Hochverfügbarkeitsmodus
Sie können den Betrieb ohne aktivierten HA-Modus (High Availability) durchführen. Diese Konfiguration bedeutet, dass Ihre Redis-Instanz keine Replikation aktiviert hat und keinen Zugriff auf die Verfügbarkeits-SLA hat. Verwenden Sie den Nicht-HA-Modus nicht außerhalb von Entwicklungs- und Testszenarien. Sie können hohe Verfügbarkeit in einer bereits erstellten Instanz nicht deaktivieren. Sie können hohe Verfügbarkeit in einer Instanz aktivieren, die sie nicht hat. Da eine Instanz ohne hohe Verfügbarkeit weniger VMs und Knoten verwendet, werden vCPUs nicht so effizient verwendet, sodass die Leistung möglicherweise niedriger ist.
Wenn Sie den HA-Modus aktivieren, wird Ihre Instanz mit primären und Replikashards bereitgestellt, die über mindestens zwei Knoten verteilt sind. Diese Konfiguration wird für alle Produktionsszenarien und für den Zugriff auf die Verfügbarkeits-SLA empfohlen. In Regionen, die Verfügbarkeitszonen unterstützen, verteilt Azure Managed Redis die Knoten standardmäßig über Zonen. Weitere Informationen finden Sie unter Zuverlässigkeit in Azure Managed Redis.
Reservierter Arbeitsspeicher
Bei jeder Azure Managed Redis-Instanz werden etwa 20 % des verfügbaren Speichers als Puffer für Nicht-Cachevorgänge reserviert, z. B. Replikation während des Failovers und Puffer für die aktive Georeplikation. Dieser Puffer trägt dazu bei, die Cacheleistung zu verbessern und einen Mangel an Arbeitsspeicher zu verhindern.
Herunterskalieren
Die Skalierung nach unten wird derzeit in Azure Managed Redis nicht unterstützt. Weitere Informationen finden Sie unter Einschränkungen der Skalierung von Azure Managed Redis.
Ebene „Flash-optimiert“
Die Ebene „Flash-optimiert“ verwendet sowohl NVMe-Flashspeicher als auch RAM. Da Flashspeicher kostengünstiger ist, können Sie mit der Dienstebene „Flash-optimiert“ einen Kompromiss zwischen Leistung und Preiseffizienz erzielen.
Bei Flash-optimierten Instanzen befinden sich 20 % des Cachespeichers im RAM, während für die anderen 80 % Flashspeicher verwendet wird. Alle Schlüssel werden im RAM gespeichert, während die Werte entweder im Flashspeicher oder im RAM gespeichert werden können. Die Redis-Software bestimmt den Speicherort der Werte auf intelligente Weise. Heiße Werte, auf die häufig zugegriffen wird, werden im RAM gespeichert, während kalte Werte, die weniger häufig verwendet werden, im Flashspeicher gespeichert werden. Bevor Daten gelesen oder geschrieben werden, müssen sie in den RAM verschoben werden, wodurch sie zu heißen Daten werden.
Redis optimiert die Speichernutzung, um die bestmögliche Leistung zu erzielen. Daher belegt die Instanz zuerst den verfügbaren RAM, bevor Elemente dem Flashspeicher hinzugefügt werden. Das anfängliche Auffüllen des RAM hat einige Auswirkungen auf die Leistung:
- Beim Testen mit geringer Speichernutzung können eine bessere Leistung und kürzere Wartezeiten auftreten. Tests mit einer vollständigen Cacheinstanz können zu einer geringeren Leistung führen, da nur RAM in der Testphase mit geringer Arbeitsspeicherauslastung verwendet wird.
- Wenn Sie mehr Daten in den Cache schreiben, verringert sich der Anteil der Daten im RAM im Vergleich zum Flashspeicher, was in der Regel zu einer Abnahme der Wartezeit- und Durchsatzleistung führt.
Für die Dienstebene „Flash-optimiert“ geeignete Workloads
Workloads, die gut auf der Stufe "Flash-Optimiert" ausgeführt werden, weisen häufig die folgenden Merkmale auf:
- Leseintensiv mit einem hohen Anteil von Lesebefehlen gegenüber Schreibbefehlen
- Access hat sich auf eine Teilmenge von Schlüsseln konzentriert, die Sie viel häufiger verwenden als der Rest des Datasets.
- Relativ große Werte im Vergleich zu den Schlüsselnamen (Da Schlüsselnamen immer im RAM gespeichert werden, können große Werte einen Engpass für die Arbeitsspeichervergrößerung verursachen.)
Für die Dienstebene „Flash-optimiert“ nicht geeignete Workloads
Einige Workloads verfügen über Zugriffseigenschaften, die für das Design der Flash-optimierten Ebene weniger gut geeignet sind:
- Schreibintensiv
- Zufällige oder einheitliche Datenzugriffsmuster im Großteil des Datasets.
- Lange Schlüsselnamen mit relativ kleinen Werten