Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Queue Storage ist ein Dienst zum Speichern und Verteilen großer Anzahl von Nachrichten. Queue Storage wird häufig verwendet, um ein Arbeits-Backlog zur asynchronen Verarbeitung zu erstellen. Es bietet eine zuverlässige Nachrichtenübermittlung für lose gekoppelte Anwendungsarchitekturen. Eine Warteschlangennachricht kann bis zu 64 KB groß sein, und eine Warteschlange kann Millionen von Nachrichten enthalten. Deren Anzahl ist nur durch die Kapazität des Speicherkontos begrenzt.
Wenn Sie Azure verwenden, ist Zuverlässigkeit eine gemeinsame Verantwortung. Microsoft bietet eine Reihe von Funktionen zur Unterstützung von Resilienz und Wiederherstellung. Sie sind dafür verantwortlich, zu verstehen, wie diese Funktionen in allen von Ihnen verwendeten Diensten funktionieren, und die Funktionen auswählen, die Sie benötigen, um Ihre Geschäftsziele und Uptime-Ziele zu erfüllen.
In diesem Artikel wird beschrieben, wie Sie den Warteschlangenspeicher für eine Vielzahl potenzieller Ausfälle und Probleme widerstandsfähig machen, einschließlich vorübergehender Fehler, Ausfall der Verfügbarkeitszone und Regionsausfälle. Darüber hinaus wird beschrieben, wie Sie Sicherungen verwenden können, um aus anderen Arten von Problemen wiederherzustellen, und hebt einige wichtige Informationen zum Sla (Queue Storage Service Level Agreement) hervor.
Hinweis
Queue Storage ist Teil der Azure Storage-Plattform. Einige der Funktionen des Warteschlangenspeichers sind in vielen Azure Storage-Diensten üblich.
Empfehlungen für die Produktionsimplementierung für Zuverlässigkeit
Für Produktionsumgebungen:
Aktivieren Sie den zonenredundanten Speicher (ZRS) für die Speicherkonten, die Warteschlangenressourcen enthalten. ZRS bietet eine höhere Verfügbarkeit, indem Sie Ihre Daten synchron über mehrere Verfügbarkeitszonen in der primären Region replizieren. Eine höhere Verfügbarkeit schützt Ihre Speicherkonten vor Verfügbarkeitszonenfehlern.
Wenn Sie Ausfallsicherheit für Regionsausfälle benötigen und die primäre Region Ihres Speicherkontos gekoppelt ist, sollten Sie den georedundanten Speicher (GRS) aktivieren. GRS repliziert Daten asynchron in den gekoppelten Bereich. In unterstützten Regionen können Sie Georedundanz mit Zonenredundanz kombinieren, indem Sie geozonenredundanten Speicher (GZRS) verwenden.
Berücksichtigen Sie bei erweiterten Messaginganforderungen die Verwendung von Azure Service Bus. Informationen zu den Unterschieden zwischen Queue Storage und Service Bus finden Sie unter Vergleichen von Azure Storage-Warteschlangen und Service Bus-Warteschlangen.
Übersicht über die Zuverlässigkeitsarchitektur
Queue Storage fungiert als verteilter Messagingdienst innerhalb der Azure Storage-Plattforminfrastruktur. Der Dienst bietet Redundanz durch mehrere Kopien Ihrer Warteschlangen- und Nachrichtendaten. Das spezifische Redundanzmodell hängt von der Konfiguration Ihres Speicherkontos ab.
Lokal redundanter Speicher (LRS) repliziert die Daten in Ihren Speicherkonten in eine oder mehrere Azure-Verfügbarkeitszonen, die sich in der primären Region Ihrer Wahl befinden. Obwohl es keine Option gibt, Ihre bevorzugte Verfügbarkeitszone auszuwählen, kann Azure LRS-Konten über Zonen hinweg verschieben oder erweitern, um den Lastenausgleich zu verbessern. Es gibt keine Garantie dafür, dass Ihre Daten über Zonen verteilt werden. Weitere Informationen zu Verfügbarkeitszonen finden Sie unter Was sind Verfügbarkeitszonen?.

Zonenredundanter Speicher (ZRS), georedundanter Speicher (GRS) und geozonenredundanter Speicher (GZRS) bieten zusätzlichen Schutz. In diesem Artikel werden diese Optionen ausführlich beschrieben.
Resilienz für vorübergehende Fehler
Vorübergehende Fehler sind kurze, zeitweilige Fehler in Komponenten. Sie treten häufig in einer verteilten Umgebung wie der Cloud auf und sind ein normaler Bestandteil von Vorgängen. Vorübergehende Fehler korrigieren sich nach kurzer Zeit. Es ist wichtig, dass Ihre Anwendungen vorübergehende Fehler behandeln können, in der Regel durch Wiederholen betroffener Anforderungen.
Alle in der Cloud gehosteten Anwendungen sollten die Anleitung zur vorübergehenden Fehlerbehandlung von Azure befolgen, wenn sie mit cloudgehosteten APIs, Datenbanken und anderen Komponenten kommunizieren. Weitere Informationen finden Sie unter Empfehlungen zur Behandlung vorübergehender Fehler.
Queue Storage wird häufig in Anwendungen verwendet, um vorübergehende Fehler in anderen Komponenten zu behandeln. Mithilfe von asynchronem Messaging mit einem Dienst wie Queue Storage können Anwendungen vorübergehende Fehler wiederherstellen, indem Nachrichten zu einem späteren Zeitpunkt erneut verarbeitet werden. Weitere Informationen finden Sie unter "Asynchronous Messaging Primer".
Innerhalb des Diensts selbst verarbeitet Queue Storage vorübergehende Fehler automatisch mithilfe mehrerer Mechanismen, die die Azure Storage-Plattform und Clientbibliotheken bereitstellen. Der Dienst wurde entwickelt, um ausfallsichere Nachrichtenwarteschlangenfunktionen auch bei temporären Infrastrukturproblemen bereitzustellen.
Queue Storage-Clientbibliotheken umfassen integrierte Wiederholungsrichtlinien, die häufige vorübergehende Fehler wie Netzwerktimeouts, temporäre Dienstverfügbarkeit (HTTP 503) und Drosselungsreaktionen (HTTP 429) automatisch behandeln. Wenn Ihre Anwendung auf diese vorübergehenden Bedingungen trifft, versuchen die Clientbibliotheken Vorgänge automatisch mithilfe von Strategien für exponentielles Backoff erneut.
Um vorübergehende Fehler effektiv mithilfe von Queue Storage zu verwalten, können Sie die folgenden Aktionen ausführen:
Konfigurieren Sie geeignete Timeouts in Ihrem Queue Storage-Client, um die Reaktionsfähigkeit mit Resilienz gegenüber temporären Verlangsamungen auszugleichen. Die Standardtimeouts in Azure Storage-Clientbibliotheken eignen sich in der Regel für die meisten Szenarien.
Implementieren Sie Schaltkreistrennmuster in Ihrer Anwendung, wenn sie Nachrichten aus Warteschlangen verarbeitet. Schaltkreisbrechermuster verhindern Kaskadierende Fehler, wenn nachgeschaltete Dienste Probleme haben.
Verwenden Sie Sichtbarkeitstimeouts entsprechend, wenn Ihre Anwendung Nachrichten empfängt. Sichtbarkeitstimeouts stellen sicher, dass Nachrichten zur Wiederholung verfügbar werden, wenn bei der Verarbeitung Fehler auftreten.
Weitere Informationen zur Azure Table Storage-Architektur und zum Entwerfen robuster und umfangreicher Anwendungen finden Sie in der Checkliste für Leistung und Skalierbarkeit für Warteschlangenspeicher.
Ausfallsicherheit bei Ausfällen von Verfügbarkeitszonen
Verfügbarkeitszonen sind physisch getrennte Gruppen von Rechenzentren innerhalb einer Azure-Region. Wenn eine Zone ausfällt, erfolgt ein Failover der Dienste zu einer der verbleibenden Zonen.
Azure Queue Storage ist zonenredundant, wenn es mit der ZRS-Konfiguration bereitgestellt wird. Im Gegensatz zu LRS garantiert ZRS, dass Azure Ihre Warteschlangendaten synchron über mehrere Verfügbarkeitszonen repliziert. ZRS stellt sicher, dass Ihre Daten auch dann zugänglich bleiben, wenn eine Zone einen Ausfall erlebt. ZRS stellt sicher, dass Ihre Warteschlangen auch dann zugänglich bleiben, wenn eine gesamte Verfügbarkeitszone nicht verfügbar ist. Alle Schreibvorgänge müssen über mehrere Zonen hinweg anerkannt werden, bevor sie abgeschlossen werden, was eine starke Konsistenzgarantie bietet.
Zonenredundanz wird auf Speicherkontoebene aktiviert und gilt für alle Ressourcen des Warteschlangenspeichers innerhalb dieses Kontos. Sie können einzelne Warteschlangen nicht für unterschiedliche Redundanzebenen konfigurieren. Die Einstellung gilt für das gesamte Speicherkonto. Wenn eine Verfügbarkeitszone einen Ausfall erlebt, leitet Azure Storage Anforderungen automatisch an fehlerfreie Zonen weiter, ohne dass eine Intervention ihrer Anwendung erforderlich ist.

Anforderungen
- Regionsunterstützung: Sie können zonenredundante Azure Storage-Konten in jeder Region bereitstellen, die Verfügbarkeitszonen unterstützt.
- Speicherkontotypen: Sie müssen ein Standard-Allzweck-Speicherkonto v2 verwenden, um ZRS für Warteschlangenspeicherung zu aktivieren. Premium-Speicherkonten unterstützen Queue Storage nicht.
Kosten
Wenn Sie den zonenredundanten Speicher (ZRS) aktivieren, werden Sie aufgrund des zusätzlichen Replikations- und Speicheraufwands mit einer anderen Rate als lokal beim redundantem Speicher (LRS) belastet.
Ausführliche Preisinformationen finden Sie unter Preise für Queue Storage.
Konfigurieren der Unterstützung von Verfügbarkeitszonen
Erstellen Sie ein zonenredundantes Speicherkonto und eine Warteschlange, indem Sie die folgenden Schritte ausführen.
Erstellen Sie ein Speicherkonto, und wählen Sie ZRS, GZRS oder geozonenredundanter Speicher mit Lesezugriff (RA-GZRS) als Redundanzoption während der Kontoerstellung aus.
Ändern Sie den Replikationstyp. Informationen zum Ändern eines vorhandenen Speicherkontos in zonenredundanten Speicher (ZRS) und zu Konfigurationsoptionen und Anforderungen finden Sie unter Ändern der Replikation eines Speicherkontos.
Zonenredundanz deaktivieren. Konvertieren Sie ZRS-Konten wieder in eine nicht-zonale Konfiguration, z. B. lokal redundanten Speicher (LRS), mithilfe desselben Redundanzkonfigurations-Änderungsprozesses.
Verhalten, wenn alle Zonen fehlerfrei sind
In diesem Abschnitt wird beschrieben, was Sie erwarten müssen, wenn ein Warteschlangenspeicherkonto für Zonenredundanz konfiguriert ist und alle Verfügbarkeitszonen betriebsbereit sind.
Datenverkehrsrouting zwischen Zonen: Azure Storage mit zonenredundanten Speicher (ZRS) verteilt Anforderungen automatisch über Speichercluster in mehreren Verfügbarkeitszonen. Die Datenverkehrsverteilung ist für Anwendungen transparent und erfordert keine clientseitige Konfiguration.
Datenreplikation zwischen Zonen: Alle Schreibvorgänge im ZRS werden synchron in allen Verfügbarkeitszonen innerhalb der Region repliziert. Wenn Sie Daten hochladen oder ändern, wird der Vorgang erst als abgeschlossen betrachtet, wenn die Daten in allen Verfügbarkeitszonen erfolgreich repliziert wurden. Diese synchrone Replikation stellt eine starke Konsistenz und keinen Datenverlust bei Zonenfehlern sicher.
Verhalten bei einem Zoneausfall
Wenn eine Verfügbarkeitszone nicht verfügbar ist, verarbeitet Queue Storage den Failovervorgang automatisch, indem die folgenden Aktionen ausgeführt werden.
- Erkennung und Reaktion: Microsoft erkennt Zonenfehler automatisch und initiiert Wiederherstellungsprozesse. Für Zonenredundanzspeicherkonten (ZRS) ist keine Kundenaktion erforderlich. Wenn eine Zone nicht verfügbar ist, übernimmt Azure Netzwerkupdates wie die Neuausrichtung des Domain Name Systems (DNS).
- Benachrichtigung: Microsoft benachrichtigt Sie nicht automatisch, wenn eine Zone deaktiviert ist. Sie können jedoch Azure Resource Health verwenden, um den Status einer einzelnen Ressource zu überwachen, und Sie können Ressourcenintegritätswarnungen einrichten, um Sie über Probleme zu informieren. Sie können auch Azure Service Health verwenden, um die allgemeine Integrität des Diensts zu verstehen, einschließlich jeglicher Zonenfehler, und Sie können Dienststatuswarnungen einrichten, um Sie über Probleme zu informieren.
Aktive Anforderungen: In-Flight-Anforderungen werden möglicherweise während des Wiederherstellungsvorgangs verworfen und sollten erneut überprüft werden. Anwendungen sollten Wiederholungslogik implementieren , um diese temporären Unterbrechungen zu behandeln.
Erwarteter Datenverlust: Während Zonenfehlern tritt kein Datenverlust auf, da Daten synchron über mehrere Zonen repliziert werden, bevor Schreibvorgänge abgeschlossen sind.
Erwartete Downtime: Ein wenig Downtime, in der Regel einige Sekunden, kann während der automatischen Wiederherstellung auftreten, da der Datenverkehr zu fehlerfreien Zonen umgeleitet wird. Halten Sie beim Entwerfen von Anwendungen für ZRS die Vorgehensweisen für vorübergehende Fehler ein. Dazu gehört u. a. die Implementierung von Wiederholungsrichtlinien mit exponentiellem Backoff.
- Datenverkehrsumleitung. Wenn eine Zone nicht verfügbar ist, führt Azure Netzwerkupdates wie die Umleitung des Domain Name Systems (DNS) durch, sodass Anforderungen an die verbleibenden fehlerfreien Verfügbarkeitszonen weitergeleitet werden. Der Dienst verwaltet die volle Funktionalität mithilfe der überlebenden Zonen, ohne dass ein Kundeneingriff erforderlich ist.
Zonenwiederherstellung
Wenn die fehlgeschlagene Verfügbarkeitszone wiederhergestellt wird, stellt Azure Storage automatisch normale Vorgänge in allen Verfügbarkeitszonen wieder her. Der Dienst stellt automatisch die Datenkonsistenz sicher, indem alle Vorgänge synchronisiert werden, die während des Ausfallzeitraums aufgetreten sind.
Test auf Zonenfehler
Wenn Sie zonenredundanten Speicher (ZRS) verwenden, verwaltet Azure Storage automatisch Replikations-, Datenverkehrsrouting- und Zonendownantworten. Da dieses Feature vollständig verwaltet ist, müssen Sie die Ausfallprozesse für Verfügbarkeitszonen weder einleiten noch überprüfen.
Widerstandsfähigkeit bei regionalen Ausfällen
Azure Storage, einschließlich Azure Blob Storage, Azure Files, Azure Table Storage und Azure Queue Storage, bietet eine Reihe von Georedundanz- und Failoverfunktionen für unterschiedliche Anforderungen.
Von Bedeutung
Georedundanter Speicher (GRS) funktioniert nur innerhalb von Azure-gekoppelten Regionen. Wenn die Region Ihres Speicherkontos nicht gekoppelt ist, sollten Sie die benutzerdefinierten Multi-Region-Lösungen zur Resilienz verwenden.
Georedundanter Speicher für gekoppelte Regionen
Azure Storage bietet mehrere Arten von GRS in gekoppelten Regionen. Unabhängig davon, welche Art von GRS Sie verwenden, werden Daten in der sekundären Region immer mithilfe von lokal redundantem Speicher (LRS) repliziert. Dieser Ansatz bietet Schutz vor Hardwarefehlern innerhalb der sekundären Region.
GRS bietet Unterstützung für geplante und ungeplante Failovers in die gekoppelte Azure-Region, wenn ein Ausfall in der primären Region vorhanden ist. GRS repliziert asynchron Daten aus der primären Region in den gekoppelten Bereich.
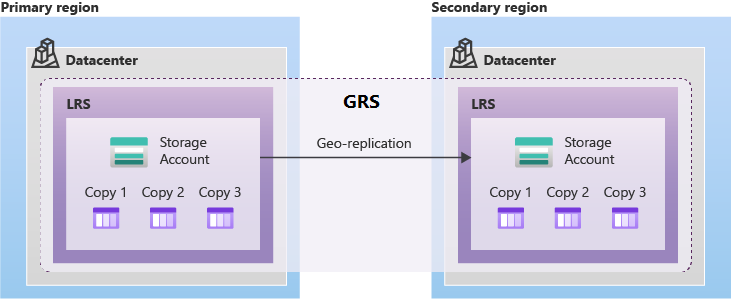
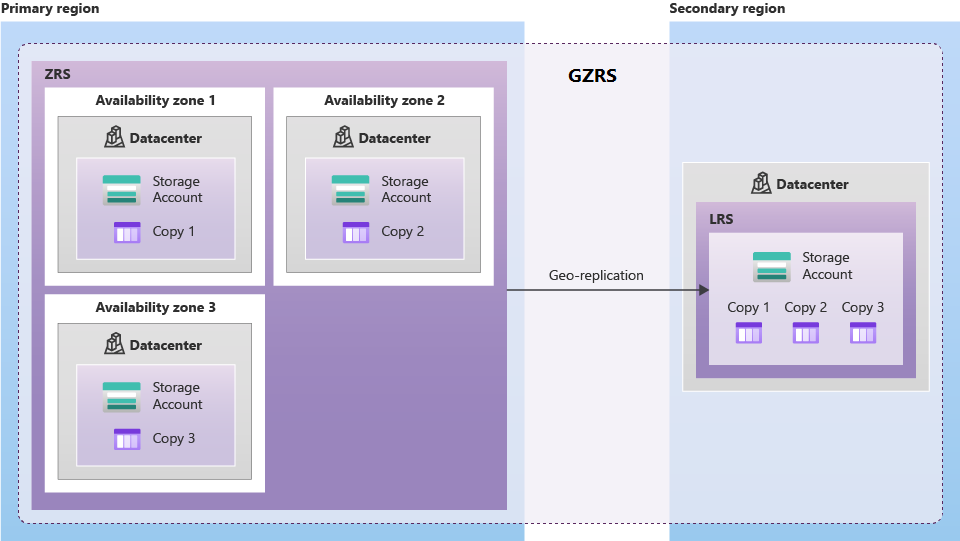
Geozonenredundanter Speicher (GZRS) repliziert Daten in mehreren Verfügbarkeitszonen in der primären Region und in die gekoppelte Region.


- Georedundanter Speicher mit Lesezugriff (RA-GRS) und geozonenredundanter Speicher mit Lesezugriff (RA-GZRS) erweitert georedundanten Speicher (GRS) und geozonenredundanten Speicher (GZRS) um den zusätzlichen Vorteil des Lesezugriffs auf den sekundären Endpunkt. Diese Optionen sind ideal für Anwendungen, die für hochverfügbare, geschäftskritische Anwendungen konzipiert sind. Im unwahrscheinlichen Fall, dass der primäre Endpunkt einen Ausfall erlebt, können Anwendungen, die für den Lesezugriff auf die sekundäre Region konfiguriert sind, weiterhin ausgeführt werden.
Failovertypen
Azure Storage unterstützt drei Arten von Failover für verschiedene Szenarien.
Kundenseitig verwaltetes nicht geplantes Failover: Sie sind für das Initiieren der Wiederherstellung verantwortlich, wenn in Ihrer primären Region ein regionsweiter Speicherfehler auftritt.
Vom Kunden verwaltetes geplantes Failover: Sie sind für das Initiieren der Wiederherstellung verantwortlich, wenn ein anderer Teil Ihrer Lösung einen Fehler in Ihrer primären Region aufweist und Sie die gesamte Lösung in eine sekundäre Region umstellen müssen. Verwenden Sie ein geplantes Failover, wenn der Speicher in der primären Region betriebsbereit bleibt, Sie aber Ihre gesamte Lösung in eine sekundäre Region umschalten müssen, z. B. für Notfallwiederherstellungsübungen, um die Einhaltung von Compliance- und Audit-Anforderungen sicherzustellen.
Von Microsoft verwaltetes Failover: Unter außergewöhnlichen Umständen kann Microsoft ein Failover für alle georedundanten Speicherkonten (GRS) in einer Region initiieren. Das von Microsoft verwaltete Failover ist jedoch ein letztes Mittel und wird erwartet, dass es nur nach einem längeren Zeitraum des Ausfalls ausgeführt wird. Sie sollten sich nicht auf das von Microsoft verwaltete Failover verlassen.
GRS-Konten können jeden dieser Failovertypen verwenden. Sie müssen kein Speicherkonto vorkonfigurieren, um einen der Failovertypen vorab zu verwenden.
Anforderungen
Regionsunterstützung: Georedundante Azure Storage-Konfigurationen verwenden azure-gekoppelte Regionen für die sekundäre Regionsreplikation. Die sekundäre Region wird basierend auf ihrer primären Regionsauswahl automatisch bestimmt und kann nicht angepasst werden. Eine vollständige Liste der gekoppelten Azure-Regionen finden Sie in der Azure-Regionsliste.
Wenn die Region Ihres Speicherkontos nicht gekoppelt ist, sollten Sie die benutzerdefinierten Multi-Region-Lösungen zur Resilienz verwenden.
- Speicherkontotypen: Georedundanter Speicher (GRS) und vom Kunden initiiertes Failover und Failback sind in allen gekoppelten Azure-Regionen verfügbar, die allgemeine v2 Azure Storage-Konten unterstützen.
Überlegungen
Berücksichtigen Sie beim Implementieren von Queue Storage mit mehreren Regionen die folgenden wichtigen Faktoren.
Asynchrone Replikationswartezeit: Die Datenreplikation in die sekundäre Region ist asynchron. Dies bedeutet, dass zwischen dem Schreiben von Daten in die primäre Region und deren Verfügbarkeit in der sekundären Region ein Verzögerung besteht. Diese Verzögerung kann zu einem potenziellen Datenverlust führen, wenn ein Primärregionsfehler auftritt, bevor die letzten Daten repliziert werden. Der Datenverlust wird durch Recovery Point Objective (RPO) gemessen. Sie können davon ausgehen, dass die Replikationsverzögerung weniger als 15 Minuten beträgt, aber diese Zeit ist eine Schätzung und nicht garantiert.
Sie können die Eigenschaft Letzte Synchronisierungszeit überprüfen, um zu verstehen, wie viele Daten verloren gehen können, wenn bei Ihrem Speicherkonto ein ungeplantes Failover auftritt.
Zugriff auf sekundäre Regionen: Mit georedundanten Speicherkonfigurationen (GRS) und geozonenredundanter Speicherkonfigurationen (GZRS) ist die sekundäre Region erst für Lesevorgänge zugänglich, wenn ein Failover auftritt.
Konfigurationen mit georedundantem Speicher mit Lesezugriff (RA-GRS) und geozonenredundantem Speicher mit Lesezugriff (RA-GZRS) bieten Lesezugriff auf die sekundäre Region während normaler Vorgänge, aber aufgrund der asynchronen Replikationswartezeit geben sie möglicherweise leicht veraltete Daten zurück.
- Featurebeschränkungen: Einige Azure Storage-Features werden nicht unterstützt oder haben Einschränkungen, wenn Sie georedundanten Speicher (GRS) oder ein kundenseitig verwaltetes Failover verwenden. Überprüfen Sie die Featurekompatibilität, bevor Sie Georedundanz implementieren.
Kosten
Konfigurationen für Azure Storage-Konten mit mehreren Regionen verursachen zusätzliche Kosten für die regionsübergreifende Replikation und den Speicher in der sekundären Region. Die Datenübertragung zwischen Azure-Regionen wird basierend auf standardmäßigen Bandbreitenraten zwischen Regionen berechnet.
Ausführliche Preisinformationen finden Sie unter Preise für Queue Storage.
Konfigurieren der Unterstützung für mehrere Regionen
- Erstellen Sie ein neues Konto mit georedundantem Speicher (GRS). Informationen zum Erstellen eines GRS-Kontos finden Sie unter Erstellen eines Speicherkontos. Wählen Sie GRS, georedundanter Speicher mit Lesezugriff (RA-GRS), geozonenredundanter Speicher (GZRS) oder geozonenredundanter Speicher mit Lesezugriff (RA-GZRS) während der Kontoerstellung aus.
Aktivieren Sie Georedundanz für ein vorhandenes Speicherkonto. Informationen zum Konvertieren eines vorhandenen Speicherkontos in einen georedundanten Speicher (GRS) finden Sie unter Ändern der Replikation eines Speicherkontos.
Warnung
Nachdem Ihr Konto für Georedundanz neu konfiguriert wurde, kann es eine erhebliche Zeit dauern, bis vorhandene Daten in der neuen primären Region vollständig in die neue sekundäre Region kopiert werden.
Um einen großen Datenverlust zu vermeiden, überprüfen Sie den Wert der Eigenschaft Letzte Synchronisierungszeit, bevor Sie ein ungeplantes Failover initiieren. Um potenzielle Datenverluste auszuwerten, vergleichen Sie die letzte Synchronisierungszeit mit dem letzten Zeitpunkt, zu dem Daten in die neue primäre Region geschrieben wurden.
Georedundanz deaktivieren. Konvertieren Sie GRS-Konten mithilfe desselben Redundanzkonfigurationsprozesses in Konfigurationen mit einer Region wie lokal redundanten Speicher (LRS) oder zonenredundanten Speicher (ZRS).
Verhalten, wenn alle Regionen funktionsfähig sind
In diesem Abschnitt wird beschrieben, was Sie erwarten müssen, wenn ein Speicherkonto für Georedundanz konfiguriert ist und alle Regionen betriebsbereit sind.
Datenverkehrsrouting zwischen Regionen: Azure Storage verwendet einen aktiv-passiv Ansatz, bei dem alle Schreibvorgänge und die meisten Lesevorgänge an die primäre Region geleitet werden.
Bei Konfigurationen mit georedundantem Speicher mit Lesezugriff (RA-GRS) und geozonenredundantem Speicher mit Lesezugriff (RA-GZRS) können Anwendungen optional aus der sekundären Region lesen, indem Sie auf den sekundären Endpunkt zugreifen. Dieser Ansatz erfordert eine explizite Anwendungskonfiguration und ist nicht automatisch. Aufgrund der asynchronen Replikationsverzögerung können Daten in der sekundären Region möglicherweise etwas veraltet sein.
Datenreplikation zwischen Regionen: Schreibvorgänge werden zunächst mithilfe der folgenden konfigurierten Redundanztypen an die primäre Region gebunden:
- Lokal redundanter Speicher (LRS) für georedundanten Speicher (GRS) und RA-GRS
- Zonenredundanter Speicher (ZRS) für geozonenredundanten Speicher (GZRS) und RA-GZRS
Nach erfolgreichem Abschluss im primären Bereich werden die Daten asynchron in den sekundären Bereich repliziert, in dem sie mithilfe von LRS gespeichert werden.
Die asynchrone Art der regionsübergreifenden Replikation bedeutet, dass es in der Regel einen Zeitabstand zwischen dem Schreiben von Daten in die primäre Region und der Verfügbarkeit in der sekundären Region gibt. Sie können die Replikationszeit mithilfe der Eigenschaft Letzte Synchronisierungszeit überwachen.
Verhalten während eines Regionenausfalls
In diesem Abschnitt wird beschrieben, was Sie erwarten müssen, wenn ein Speicherkonto für Georedundanz konfiguriert ist und ein Ausfall in der primären Region vorhanden ist.
Kundenseitig verwaltetes Failover (ungeplant): Verwenden Sie ein ungeplantes Failover, wenn der Speicher in der primären Region nicht verfügbar ist.
Erkennung und Reaktion: Im unwahrscheinlichen Fall, dass Ihr Speicherkonto in Ihrer primären Region nicht verfügbar ist, können Sie erwägen, ein vom Kunden verwaltetes nicht geplantes Failover zu initiieren. Berücksichtigen Sie die folgenden Faktoren, um diese Entscheidung zu treffen:
Gibt an, ob Azure Resource Health Probleme beim Zugriff auf das Speicherkonto in Ihrer primären Region anzeigt.
Gibt an, ob Microsoft Ihnen empfiehlt, ein Failover in eine andere Region durchzuführen.
Warnung
Ein ungeplantes Failover kann zu Datenverlust führen. Bevor Sie ein kundenseitig verwaltetes Failover initiieren, entscheiden Sie, ob die Wiederherstellung des Diensts das Risiko eines Datenverlusts rechtfertigt.
Benachrichtigung: Microsoft benachrichtigt Sie nicht automatisch, wenn eine Region abfällt. Aber:
Sie können Azure Resource Health verwenden, um den Status einer einzelnen Ressource zu überwachen, und Sie können Ressourcenintegritätswarnungen einrichten, um Sie über Probleme zu informieren.
Sie können Azure Service Health verwenden, um die allgemeine Integrität des Diensts zu verstehen, einschließlich aller Regionsfehler, und Sie können Dienststatuswarnungen einrichten, um Sie über Probleme zu informieren.
Aktive Anforderungen: Während des Failoverprozesses werden sowohl die Endpunkte des primären als auch des sekundären Speicherkontos für Lese- und Schreibvorgänge vorübergehend nicht verfügbar. Möglicherweise werden alle aktiven Anforderungen gelöscht, und Clientanwendungen müssen nach Abschluss des Failovers erneut versuchen.
Erwarteter Datenverlust: Datenverlust tritt bei einem ungeplanten Failover aufgrund der asynchronen Replikationsverzögerung häufig auf. Dies bedeutet, dass zuletzt verwendete Schreibvorgänge möglicherweise nicht repliziert werden. Sie können die Eigenschaft Letzte Synchronisierungszeit überprüfen, um zu verstehen, wie viele Daten während eines ungeplanten Failovers verloren gehen könnten. Erwarteter Datenverlust wird häufig als Ziel des Wiederherstellungspunkts (Recovery Point Objective, RPO) bezeichnet. Sie können in der Regel davon ausgehen, dass das RPO weniger als 15 Minuten beträgt, aber diese Zeit ist nicht garantiert.
Erwartete Ausfallzeiten: Die Menge der erwarteten Ausfallzeiten wird häufig als Wiederherstellungszeitziel (RTO) bezeichnet. Das vom Kunden verwaltete Failover wird in der Regel innerhalb von 60 Minuten abgeschlossen, je nach Kontogröße und Komplexität.
Datenverkehrsumleitung: Nach Abschluss des Failovers aktualisiert Azure automatisch die Endpunkte des Speicherkontos, sodass Anwendungen nicht neu konfiguriert werden müssen. Wenn Ihre Anwendung DNS-Einträge (Domain Name System) zwischengespeichert hat, muss der Cache möglicherweise gelöscht werden, um sicherzustellen, dass die Anwendung Datenverkehr an die neue primäre Region sendet.
Konfiguration nach dem Failover: Nach Abschluss eines ungeplanten Failovers verwendet Ihr Speicherkonto in der Zielregion die lokal redundante Speicherebene (LRS). Wenn Sie es erneut replizieren müssen, müssen Sie den georedundanten Speicher (GRS) erneut aktivieren und warten, bis die Daten in die neue sekundäre Region repliziert werden.
Weitere Informationen zum Initiieren eines kundenseitig verwalteten Failovers finden Sie unter Funktionsweise eines kundenseitig verwalteten (ungeplanten) Failovers und Initiieren eines Speicherkontofailovers.
Kundenseitig verwaltetes Failover (geplant): Verwenden Sie ein geplantes Failover, wenn der Speicher in der primären Region betriebsbereit bleibt, aber Sie aus einem anderen Grund ein Failover für die gesamte Lösung in eine sekundäre Region durchführen müssen. Beispielsweise kann ein anderer Azure-Dienst ein Problem haben, und Sie müssen zur Verwendung einer sekundären Region für Ihre gesamte Lösung wechseln. Oder Sie können ein geplantes Failover verwenden, um einen Notfallwiederherstellungs-Test für Compliance- und Prüfzwecke durchzuführen.
Erkennung und Reaktion: Sie sind für die Ausführung eines Failovers verantwortlich. Diese Entscheidung treffen Sie normalerweise, wenn Sie zwischen Regionen ein Failover durchführen müssen, selbst wenn Ihr Speicherkonto in Ordnung ist. Sie können z. B. ein Failover auslösen, wenn es zu einem großen Ausfall eines anderen Anwendungskomponents kommt, von dem Sie sich in der primären Region nicht erholen können.
Benachrichtigung: Microsoft benachrichtigt Sie nicht automatisch, wenn eine Region abfällt. Aber:
Sie können Azure Resource Health verwenden, um den Status einer einzelnen Ressource zu überwachen, und Sie können Ressourcenintegritätswarnungen einrichten, um Sie über Probleme zu informieren.
Sie können Azure Service Health verwenden, um die allgemeine Integrität des Diensts zu verstehen, einschließlich aller Regionsfehler, und Sie können Dienststatuswarnungen einrichten, um Sie über Probleme zu informieren.
Aktive Anforderungen: Während des Failoverprozesses werden sowohl die Endpunkte des primären als auch des sekundären Speicherkontos für Lese- und Schreibvorgänge vorübergehend nicht verfügbar. Möglicherweise werden alle aktiven Anforderungen gelöscht, und Clientanwendungen müssen nach Abschluss des Failovers erneut versuchen.
Erwarteter Datenverlust: Es wird kein Datenverlust erwartet, da der Failovervorgang erst abgeschlossen wird, nachdem alle Daten synchronisiert wurden, was zu einem RPO von Null führt.
Erwartete Ausfallzeiten: Failover wird in der Regel innerhalb von 60 Minuten abgeschlossen, was bedeutet, dass die erwartete RTO je nach Kontogröße und Komplexität 60 Minuten beträgt. Während des Failoverprozesses werden sowohl die Endpunkte des primären als auch des sekundären Speicherkontos für Lese- und Schreibvorgänge vorübergehend nicht verfügbar.
Datenverkehrsumleitung: Nach Abschluss des Failovers aktualisiert Azure automatisch die Endpunkte des Speicherkontos, sodass Anwendungen nicht neu konfiguriert werden müssen. Wenn Ihre Anwendung DNS-Einträge zwischengespeichert hat, muss der Cache möglicherweise gelöscht werden, um sicherzustellen, dass die Anwendung Datenverkehr an die neue primäre Region sendet.
Konfiguration nach dem Failover: Nach Abschluss eines geplanten Failovers wird Ihr Speicherkonto in der Zielregion weiterhin georeplikatiert und verbleibt auf der GRS-Ebene.
Weitere Informationen zum Initiieren eines kundenseitig verwalteten Failovers finden Sie unter Funktionsweise des vom Kunden verwalteten (geplanten) Failovers und Initiieren eines Speicherkontofailovers.
Von Microsoft verwaltetes Failover: Im seltenen Fall einer großen Katastrophe, bei der Microsoft feststellt, dass die primäre Region dauerhaft nicht wiederhergestellt werden kann, kann ein automatisches Failover in die sekundäre Region initiiert werden. Microsoft verarbeitet den gesamten Prozess, und es ist keine Kundenaktion erforderlich. Die Zeitspanne, die vor dem Failover verstrichen ist, hängt vom Schweregrad der Katastrophe und der Zeit ab, die zum Bewerten der Situation erforderlich ist.
Benachrichtigung: Microsoft benachrichtigt Sie nicht automatisch, wenn eine Region abfällt. Aber:
Sie können Azure Resource Health verwenden, um den Status einer einzelnen Ressource zu überwachen, und Sie können Ressourcenintegritätswarnungen einrichten, um Sie über Probleme zu informieren.
Sie können Azure Service Health verwenden, um die allgemeine Integrität des Diensts zu verstehen, einschließlich aller Regionsfehler, und Sie können Dienststatuswarnungen einrichten, um Sie über Probleme zu informieren.
Von Bedeutung
Verwenden Sie vom Kunden verwaltete Failoveroptionen, um Ihre DR-Pläne zu entwickeln, zu testen und zu implementieren. Verlassen Sie sich nicht auf ein von Microsoft verwaltetes Failover, das nur unter extremen Umständen verwendet werden kann. Ein von Microsoft verwaltetes Failover wird wahrscheinlich für eine gesamte Region initiiert. Sie kann nicht für einzelne Speicherkonten, Abonnements oder Kunden initiiert werden. Failover kann zu unterschiedlichen Zeiten für verschiedene Azure-Dienste auftreten. Es wird empfohlen, das kundenseitig verwaltete Failover zu verwenden.
Region-Wiederherstellung
Der Failbackprozess unterscheidet sich erheblich zwischen vom Microsoft verwalteten und kundenseitig verwalteten Failoverszenarien.
Kundenseitig verwaltetes Failover (ungeplant): Nach einem ungeplanten Failover wird das Speicherkonto mit lokal redundanten Speicher (LRS) konfiguriert. Für ein Failback, müssen Sie die georedundante Speicherbeziehung (GRS) neu einrichten und warten, bis die Daten repliziert werden.
Kundenseitig verwaltetes Failover (geplant): Nach einem geplanten Failover bleibt das Speicherkonto georepliziert. Sie können ein weiteres kundenseitig verwaltetes Failover initiieren, um zu der ursprünglichen primären Region zurückzukehren. Es gelten dieselben Failoverüberlegungen.
Von Microsoft verwaltetes Failover: Wenn Microsoft ein Failover initiiert, ist es wahrscheinlich, dass in der primären Region ein erheblicher Notfall aufgetreten ist und die primäre Region möglicherweise nicht wiederhergestellt werden kann. Alle Zeitpläne oder Wiederherstellungspläne hängen vom Umfang der regionalen Notfall- und Wiederherstellungsbemühungen ab. Sie sollten die Azure Service Health-Kommunikation auf Details überwachen.
Test auf Regionsfehler
Sie können regionale Fehler simulieren, um Ihre Notfallwiederherstellungsverfahren zu testen.
Geplante Failovertests: Für georedundante Speicherkonten (GRS)-Konten können Sie geplante Failovervorgänge während der Wartungsfenster ausführen, um den vollständigen Failover- und Failbackprozess zu testen. Ein geplantes Failover erfordert keinen Datenverlust, umfasst aber Ausfallzeiten sowohl während des Failovers als auch während des Failbacks.
Sekundäre Endpunkttests: Für Konfigurationen mit georedundantem Speicher mit Lesezugriff (RA-GRS) und für Konfigurationen mit geozonenredundantem Speicher mit Lesezugriff (RA-GZRS) testen Sie regelmäßig Lesevorgänge für den sekundären Endpunkt, um sicherzustellen, dass Ihre Anwendung Daten aus der sekundären Region erfolgreich lesen kann.
Benutzerdefinierte Lösungen mit mehreren Regionen für Resilienz
Die regionsübergreifenden Failoverfunktionen von Azure Storage sind aus den folgenden Gründen möglicherweise nicht geeignet:
Ihr Speicherkonto befindet sich in einer nicht gepaarten Region.
Ihre Geschäftsbetriebsziele sind nicht mit der Wiederherstellungszeit oder dem Datenverlust zufrieden, die die integrierten Failoveroptionen bereitstellen.
Sie müssen ein Failover zu einer Region ausführen, die nicht das Paar Ihrer primären Region ist.
Sie benötigen eine Aktiv-Aktiv-Konfiguration in allen Regionen.
Dieser Abschnitt enthält eine allgemeine Übersicht über einige zu berücksichtigende Ansätze. Eine umfassende Übersicht über Bereitstellungstopologien mit mehreren Regionen für Azure Storage liegt außerhalb des Umfangs dieses Artikels.
Hinweis
Bei erweiterten Anforderungen für mehrere Regionen sollten Sie stattdessen Service Bus verwenden, das Unterstützung für nicht gekoppelte Regionen umfasst.
Sie können Azure Storage über mehrere Regionen hinweg bereitstellen, indem Sie separate Speicherkonten in jeder Region verwenden. Dieser Ansatz bietet Flexibilität bei der Regionsauswahl, der Möglichkeit, nicht gekoppelte Regionen zu verwenden und eine genauere Kontrolle über den Replikationszeitpunkt und die Datenkonsistenz zu erreichen. Wenn Sie mehrere Speicherkonten regionsübergreifend implementieren, müssen Sie die regionsübergreifende Datenreplikation konfigurieren, Lastenausgleichs- und Failoverrichtlinien implementieren und die Datenkonsistenz in allen Regionen sicherstellen.
Bei diesem Ansatz müssen Sie die Nachrichtenverteilung verwalten, die Datensynchronisierung zwischen Warteschlangen in den verschiedenen Speicherkonten behandeln und benutzerdefinierte Failoverlogik implementieren.
Sichern und Wiederherstellen
Queue Storage bietet keine herkömmlichen Sicherungsfunktionen wie die Zeitpunktwiederherstellung (PITR). Dies liegt daran, dass Warteschlangen für die vorübergehende Nachrichtenspeicherung anstatt einer langfristigen Datenpersistenz ausgelegt sind. Nachrichten werden in der Regel verarbeitet und aus Warteschlangen während normaler Anwendungsvorgänge entfernt.
Für Szenarien, die über die integrierten Redundanzoptionen hinausgehen, sollten Sie eine eigene Nachrichtenprotokollierung auf Anwendungsebene oder Persistenz in einen dauerhaften Datenspeicher implementieren, z. B. Blob Storage oder Azure SQL-Datenbank. Mit diesem Ansatz können Sie den Nachrichtenverlauf verwalten, während Sie den Warteschlangenspeicher für den vorgesehenen Zweck der temporären Nachrichtenpufferung und Verarbeitungskoordination verwenden.
Service-Level-Vereinbarung
Der Servicelevelvertrag (SLA) für Azure Storage beschreibt die erwartete Verfügbarkeit des Diensts und die Bedingungen, die erfüllt werden müssen, um diese Verfügbarkeitserwartungen zu erreichen. Die Verfügbarkeits-SLA, für die Sie berechtigt sind, hängt von der Speicherebene und vom verwendeten Replikationstyp ab. Weitere Informationen finden Sie unter SLAs für Onlinedienste.