Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden die Schritte zum Einrichten von Hochverfügbarkeit in HANA (große Instanzen) unter dem Betriebssystem SUSE mithilfe des Fencinggeräts erläutert.
Hinweis
Dieser Leitfaden ist im Rahmen von erfolgreichen Tests der Konfiguration in der Microsoft HANA-Umgebung (große Instanzen) entstanden. Das Microsoft Service Management-Team für HANA (große Instanzen) unterstützt das Betriebssystem nicht. Wenden Sie sich an SUSE, um Informationen zur Problembehandlung des Betriebssystems oder Erläuterungen zur Betriebssystemebene zu erhalten.
Das Microsoft Service Management-Team richtet das Fencinggerät ein und unterstützt es vollständig. Es kann bei der Behandlung von Problemen mit dem Fencinggerät helfen.
Voraussetzungen
Um Hochverfügbarkeit mithilfe von SUSE-Clustering einzurichten, ist Folgendes erforderlich:
- Bereitstellen von HANA (große Instanzen).
- Installieren und Registrieren des Betriebssystems mit den neuesten Patches.
- Verbinden von HANA-Servern (große Instanzen) mit dem SMT-Server, um Patches und Pakete zu erhalten.
- Einrichten von Network Time Protocol (NTP-Zeitserver).
- Lesen und Verstehen der aktuellen Version der SUSE-Dokumentation zum Einrichten von Hochverfügbarkeit.
Details zur Konfiguration
In diesem Leitfaden wird folgendes Setup verwendet:
- Betriebssystem: SLES 12 SP1 für SAP
- Große HANA-Instanzen: 2 x S192 (vier Sockets, 2TB)
- HANA-Version: HANA 2.0 SP1
- Servernamen: „sapprdhdb95“ (node1) und „sapprdhdb96“ (node2)
- Fencinggerät: iSCSI-basiert
- NTP auf einem der HANA-Knoten (große Instanzen)
Wenn Sie HANA (große Instanzen) mit HANA-Systemreplikation einrichten, können Sie beim Microsoft Service Management-Team die Einrichtung des Fencinggeräts beantragen. Führen Sie dies zum Zeitpunkt der Bereitstellung aus.
Auch wenn Sie Bestandskunde mit bereits bereitgestellter HANA-Instanz (große Instanzen) sind, können Sie das Fencinggerät dennoch einrichten. Geben Sie dem Microsoft Service Management-Team im Service Request-Formular die folgenden Informationen an. Sie können das Service Request-Formular über den Technical Account Manager oder Ihren Microsoft-Kontakt für das Onboarding von HANA (große Instanzen) erhalten.
- Servername und Server-IP-Adresse (z. B. myhanaserver1, 10.35.0.1)
- Standort (z.B. „USA, Osten“)
- Name des Kunden (z. B. Microsoft)
- HANA-Systembezeichner (SID) (z.B. „H11“)
Nachdem das Fencinggerät konfiguriert wurde, erhalten Sie vom Microsoft Service Management-Team den SBD-Namen und die IP-Adresse des iSCSI-Speichers. Anhand dieser Informationen können Sie die Fencingeinrichtung konfigurieren.
Führen Sie die Schritte in den folgenden Abschnitten aus, um Hochverfügbarkeit mit dem Fencinggerät einzurichten.
Identifizieren des SBD-Geräts
Hinweis
Dieser Abschnitt gilt nur für Bestandskunden. Wenn Sie Neukunde sind, nennt Ihnen das Microsoft Service Management-Team den Namen des SBD-Geräts. Überspringen Sie daher diesen Abschnitt.
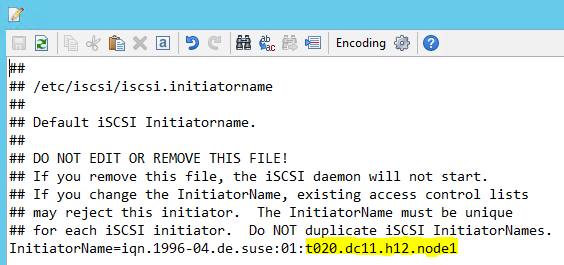
Ändern Sie /etc/iscsi/initiatorname.isci wie folgt:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Diese Zeichenfolge wird vom Microsoft Service Management-Team bereitgestellt. Ändern Sie die Datei auf beiden Knoten. Die Knotennummer ist jedoch auf jedem Knoten unterschiedlich.
Ändern Sie /etc/iscsi/iscsid.conf, indem Sie
node.session.timeo.replacement_timeout=5undnode.startup = automaticfestlegen. Ändern Sie die Datei auf beiden Knoten.Führen Sie den folgenden Ermittlungsbefehl auf beiden Knoten aus.
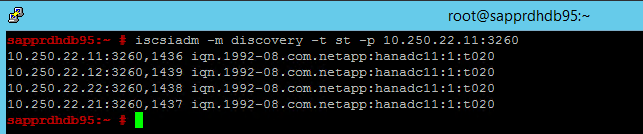
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Die Ergebnisse zeigen vier Sitzungen an.
Führen Sie den folgenden Befehl auf beiden Knoten aus, um sich beim iSCSI-Gerät anzumelden.
iscsiadm -m node -lDie Ergebnisse zeigen vier Sitzungen an.

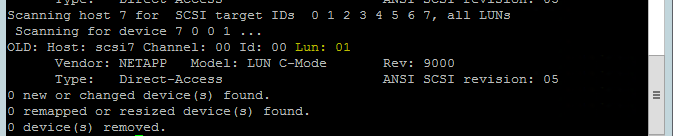
Verwenden Sie den folgenden Befehl, um das Skript rescan-scsi-bus.sh zum erneuten Überprüfen auszuführen. Dieses Skript zeigt die neuen für Sie erstellten Datenträger an. Führen Sie ihn auf beiden Knoten aus.
rescan-scsi-bus.shDie Ergebnisse sollten eine LUN-Nummer größer als 0 anzeigen (z. B. 1, 2usw.).
Führen Sie den folgenden Befehl auf beiden Knoten aus, um den Gerätenamen abzurufen.
fdisk –lWählen Sie in den Ergebnissen das Gerät mit der Größe 178 MiB aus.

Initialisieren des SBD-Geräts
Verwenden Sie den folgenden Befehl, um das SBD-Gerät auf beiden Knoten zu initialisieren.
sbd -d <SBD Device Name> create
Verwenden Sie den folgenden Befehl auf beiden Knoten, um zu überprüfen, was auf das Gerät geschrieben wurde.
sbd -d <SBD Device Name> dump
Konfigurieren des SUSE-Hochverfügbarkeitsclusters
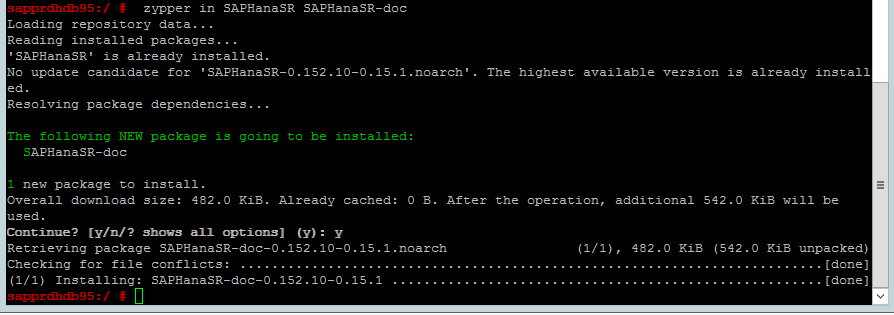
Verwenden Sie den folgenden Befehl, um zu überprüfen, ob die ha_sles- und SAPHanaSR-doc-Muster auf beiden Knoten installiert sind. Wenn sie nicht installiert sein sollten, installieren Sie sie.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Richten Sie den Cluster entweder mit dem
ha-cluster-init-Befehl oder dem yast2-Assistenten ein. In diesem Beispiel wird der yast2-Assistent verwendet. Führen Sie diesen Schritt nur auf dem primären Knoten aus.Navigieren Sie zu yast2>High Availability>Cluster (yast2 > Hochverfügbarkeit > Cluster).
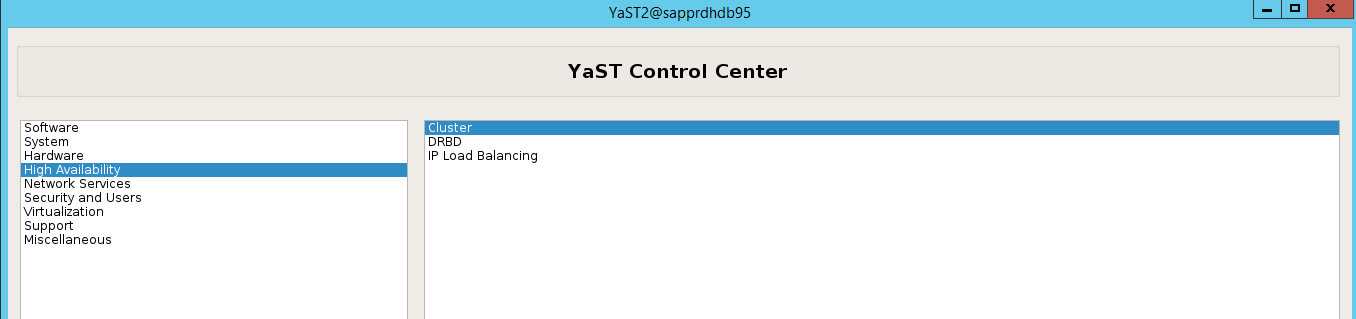
Wählen Sie im Dialogfeld, das zur hawk-Paketinstallation angezeigt wird, Cancel (Abbrechen) aus, weil das Paket „halk2“ bereits installiert ist.
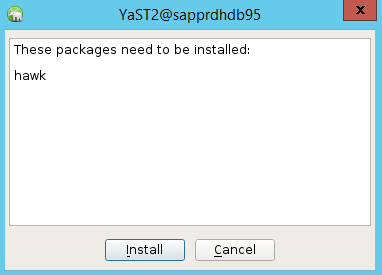
Wählen Sie im Dialogfeld, das zum Fortsetzen angezeigt wird, Continue (Fortsetzen) aus.
Der erwartete Wert entspricht der Anzahl der bereitgestellten Knoten (in diesem Fall 2). Klicken Sie auf Weiter.
Fügen Sie Knotennamen hinzu, und wählen Sie dann Add suggested files (Vorgeschlagene Dateien hinzufügen) aus.
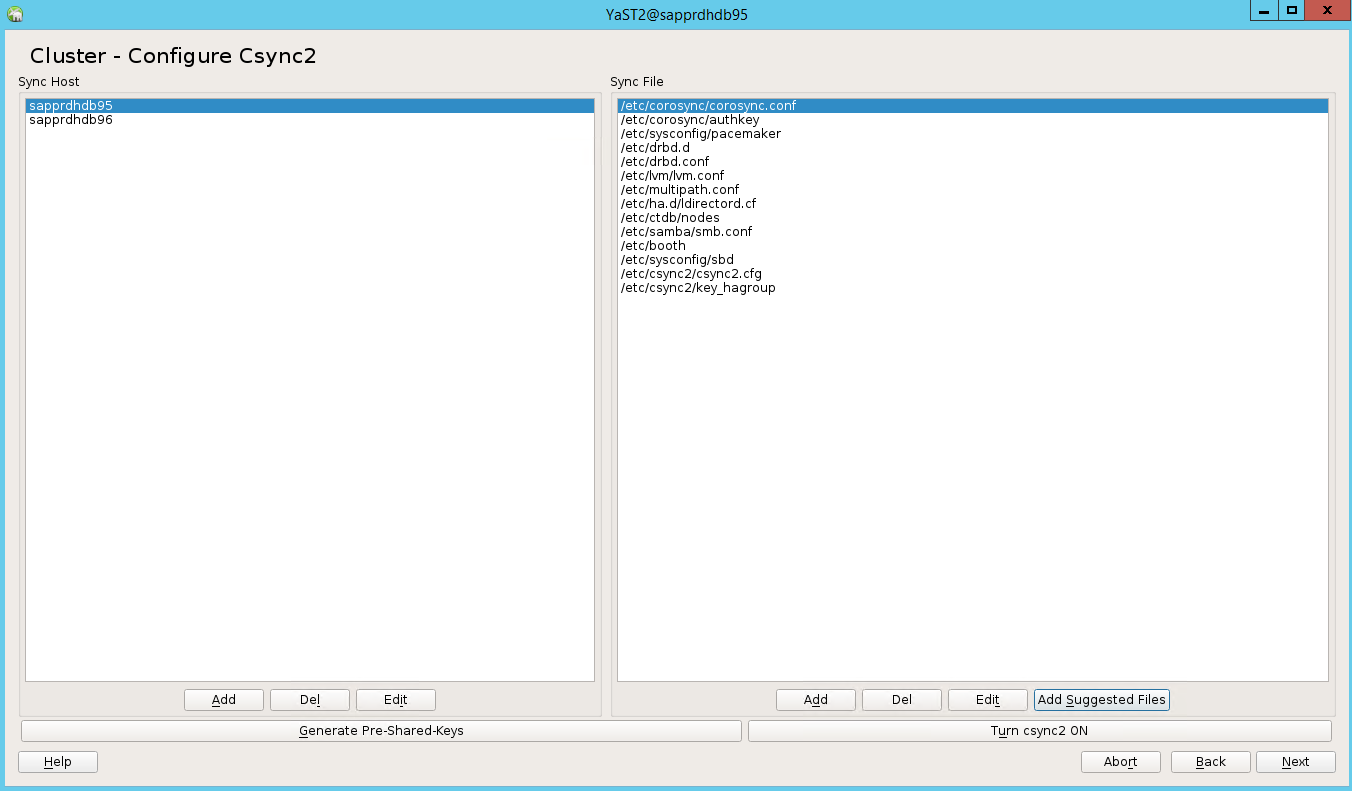
Wählen Sie Turn csync2 ON (csync2 aktivieren) aus.
Wählen Sie Generate Pre-Shared-Keys (Vorinstallierte Schlüssel generieren).
Wählen Sie in der angezeigten Popupmeldung OK aus.
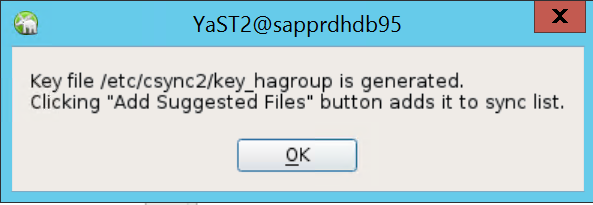
Die Authentifizierung erfolgt über die IP-Adressen und vorinstallierten Schlüssel in Csync2. Die Schlüsseldatei wird mit
csync2 -k /etc/csync2/key_hagroupgeneriert.Kopieren Sie die Datei key_hagroup nach der Erstellung manuell auf alle Mitglieder des Clusters. Achten Sie darauf, die Datei von node1 auf node2 zu kopieren. Wählen Sie Weiteraus.
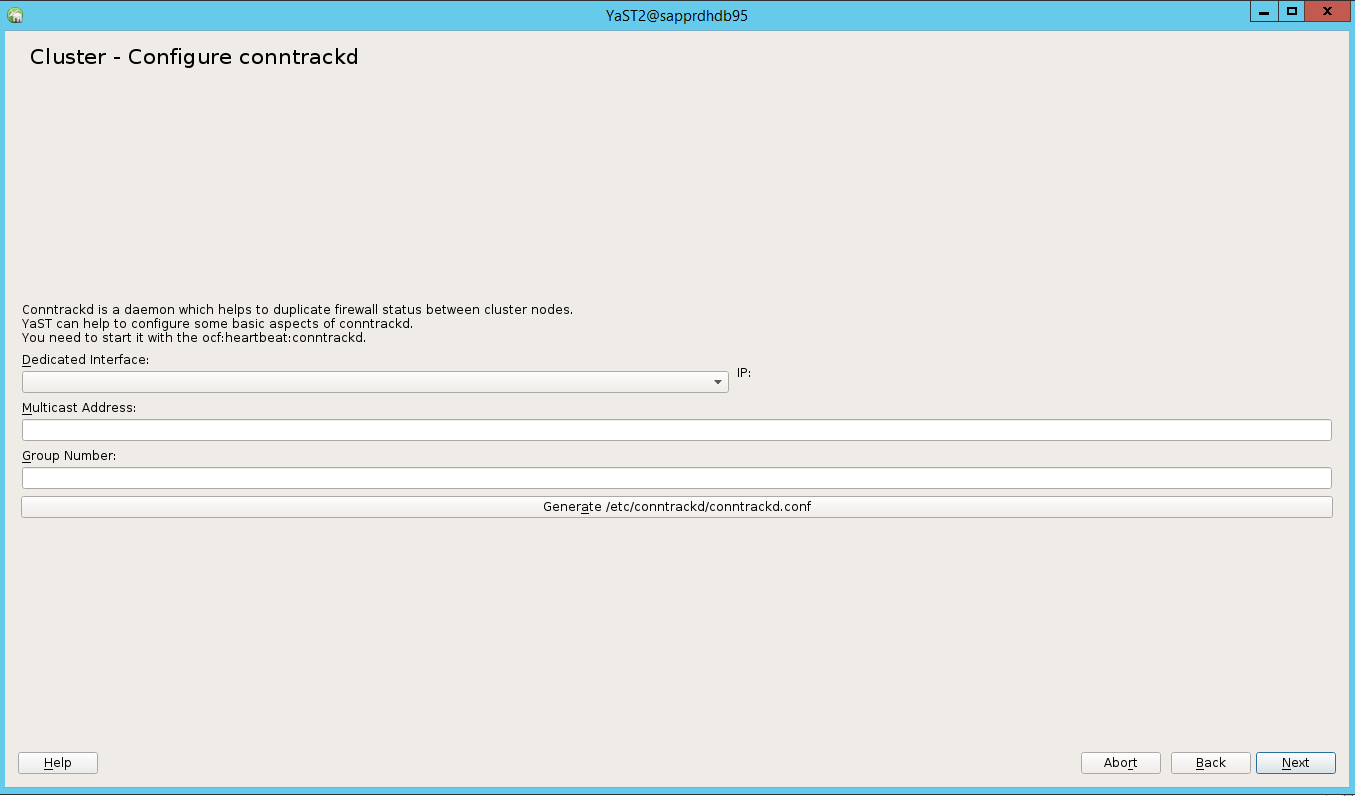
Bei der Standardoption war Booting (Starten) deaktiviert. Ändern Sie sie in die Option in On (Ein), damit der Pacemaker-Dienst beim Start gestartet wird. Sie können die Auswahl gemäß Ihren Konfigurationsanforderungen treffen.
Nach Auswählen von Weiter ist die Clusterkonfiguration abgeschlossen.
Einrichten des Softdog-Watchdogs
Fügen Sie /etc/init.d/boot.local auf beiden Knoten die folgende Zeile hinzu.
modprobe softdog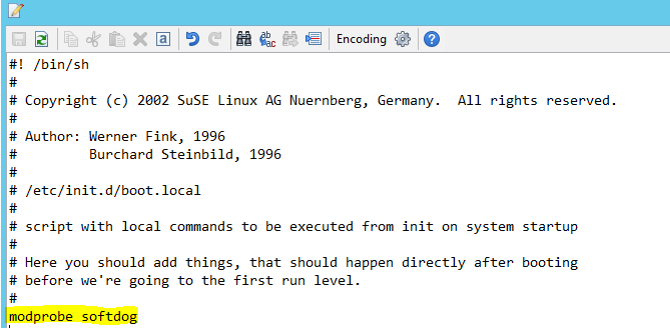
Verwenden Sie den folgenden Befehl, um die Datei /etc/sysconfig/sbd auf beiden Knoten zu aktualisieren.
SBD_DEVICE="<SBD Device Name>"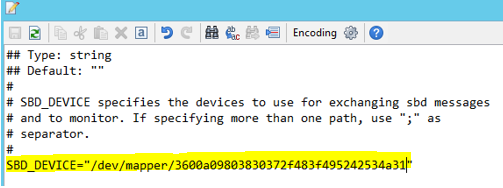
Laden Sie das Kernelmodul auf beiden Knoten, indem Sie den folgenden Befehl ausführen.
modprobe softdog
Verwenden Sie den folgenden Befehl, um sicherzustellen, dass Softdog auf beiden Knoten ausgeführt wird.
lsmod | grep dog
Verwenden Sie den folgenden Befehl, um das SBD-Gerät auf beiden Knoten zu starten.
/usr/share/sbd/sbd.sh start
Verwenden Sie den folgenden Befehl, um den SBD-Daemon auf beiden Knoten zu starten.
sbd -d <SBD Device Name> listDie Ergebnisse zeigen zwei Einträge nach der Konfiguration auf beiden Knoten an.

Senden Sie die folgende Testnachricht an einen der Knoten.
sbd -d <SBD Device Name> message <node2> <message>Verwenden Sie auf dem zweiten Knoten (node2) den folgenden Befehl, um den Nachrichtenstatus zu überprüfen.
sbd -d <SBD Device Name> list
Um die SBD-Konfiguration zu übernehmen, aktualisieren Sie die Datei /etc/sysconfig/sbd wie folgt auf beiden Knoten.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Verwenden Die den folgenden Befehl, um den Pacemaker-Dienst auf dem primären Knoten (node1) zu starten.
systemctl start pacemaker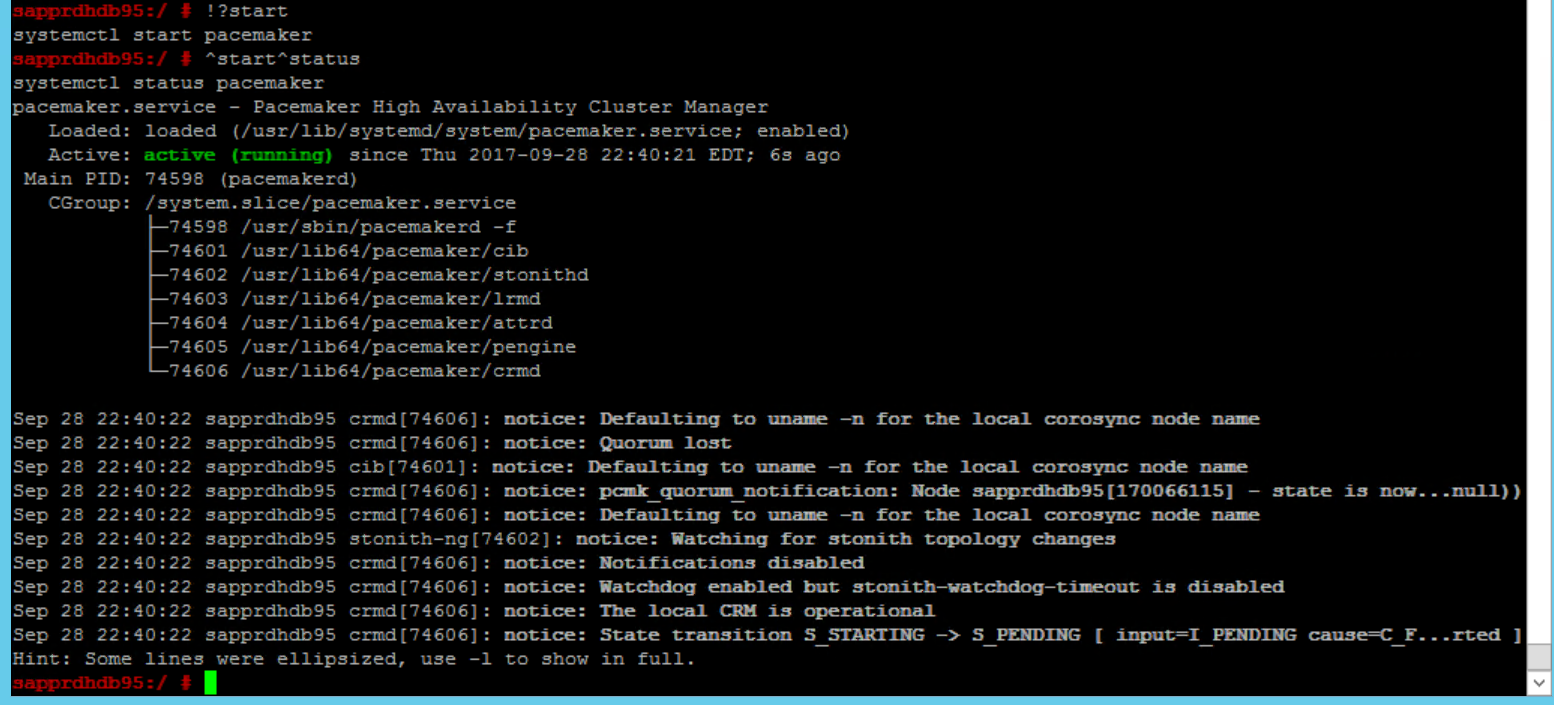
Wenn der Pacemaker-Dienst fehlschlägt, lesen Sie den Abschnitt Szenario 5: Pacemaker-Dienst schlägtfehl weiter unten in diesem Artikel.
Beitreten des Knotens zum Cluster
Führen Sie den folgenden Befehl auf node2 aus, damit dieser Knoten dem Cluster beitritt.
ha-cluster-join
Wenn beim Beitritt zum Cluster ein Fehler auftritt, lesen Sie den Abschnitt Szenario 6: Node2 kann dem Cluster nicht beitreten weiter unten in diesem Artikel.
Überprüfen des Clusters
Verwenden Sie die folgenden Befehle, um den Cluster auf beiden Knoten zu überprüfen und optional zu starten.
systemctl status pacemaker systemctl start pacemaker
Vergewissern Sie sich mithilfe des folgenden Befehls, dass beide Knoten online sind. Sie können ihn auf beiden Knoten des Clusters ausführen.
crm_mon
Sie können sich auch bei hawk anmelden, um den Clusterstatus zu überprüfen:
https://\<node IP>:7630. Der Standardbenutzer lautet hacluster und das Kennwort linux. Wenn erforderlich, können Sie das Kennwort mit dem Befehlpasswdändern.
Konfigurieren von Clustereigenschaften und -ressourcen
In diesem Abschnitt werden die Schritte zum Konfigurieren von Clusterressourcen beschrieben. In diesem Beispiel richten Sie die folgenden Ressourcen ein. Sie können den Rest (bei Bedarf) konfigurieren, indem Sie den SUSE-Leitfaden für Hochverfügbarkeit verwenden.
- Cluster-Bootstrap
- Fencinggerät
- Virtuelle IP-Adresse
Nehmen Sie die Konfiguration nur auf dem primären Knoten vor.
Erstellen Sie die Bootstrapdatei des Clusters, und konfigurieren Sie sie, indem Sie den folgenden Text hinzufügen.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Verwenden Sie den folgenden Befehl, um die Konfiguration dem Cluster hinzuzufügen.
crm configure load update crm-bs.txt
Konfigurieren Sie das Fencinggerät, indem Sie die Ressource hinzufügen, die Datei erstellen und Text wie folgt hinzufügen:
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Verwenden Sie den folgenden Befehl, um die Konfiguration dem Cluster hinzuzufügen.
crm configure load update crm-sbd.txtFügen Sie die virtuelle IP-Adresse für die Ressource hinzu, indem Sie die Datei erstellen und den folgenden Text hinzufügen.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Verwenden Sie den folgenden Befehl, um die Konfiguration dem Cluster hinzuzufügen.
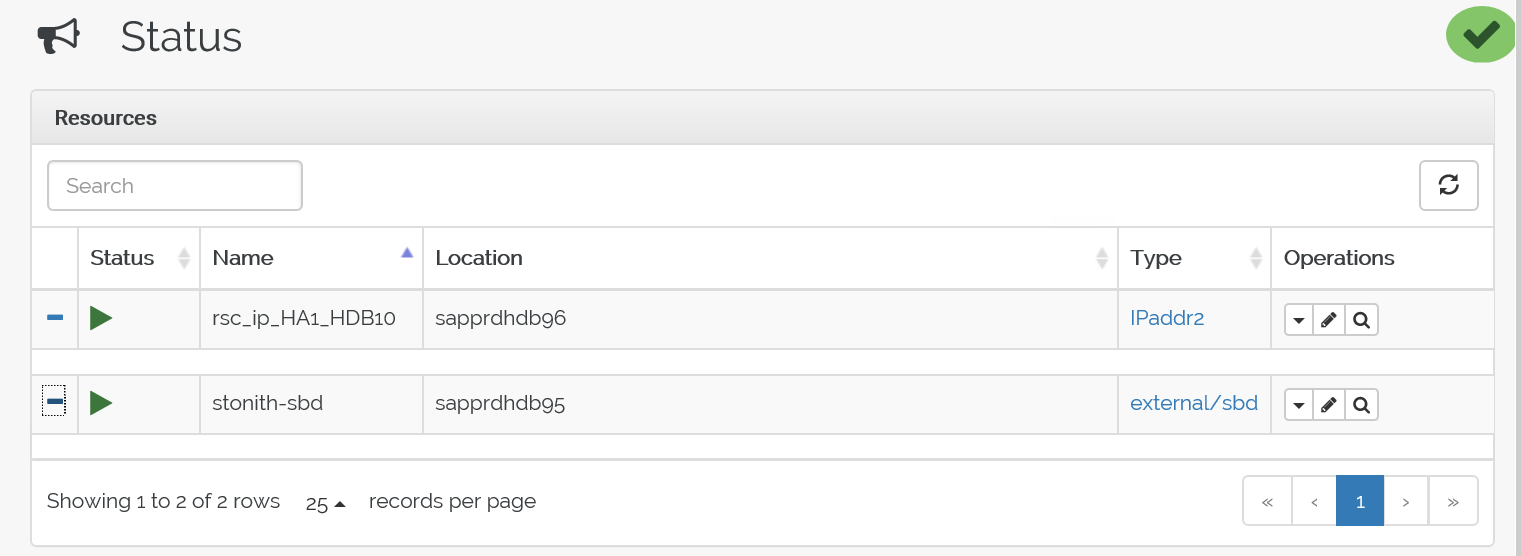
crm configure load update crm-vip.txtVerwenden Sie den
crm_mon-Befehl, um die Ressourcen zu überprüfen.Die Ergebnisse zeigen die beiden Ressourcen.

Darüber hinaus können Sie den Status unter https://<Knoten-IP-Adresse>:7630/cib/live/state prüfen.
Testen des Failoverprozesses
Verwenden Sie zum Testen des Failoverprozesses den folgenden Befehl, um den Pacemaker-Dienst auf node1 zu beenden.
Service pacemaker stopFür die Ressourcen wird ein Failover auf node2 ausgeführt.
Beenden Sie den Pacemaker-Dienst auf node2. Für die Ressourcen wird ein Failover auf node1 ausgeführt.
Dies ist der Status vor dem Failover:
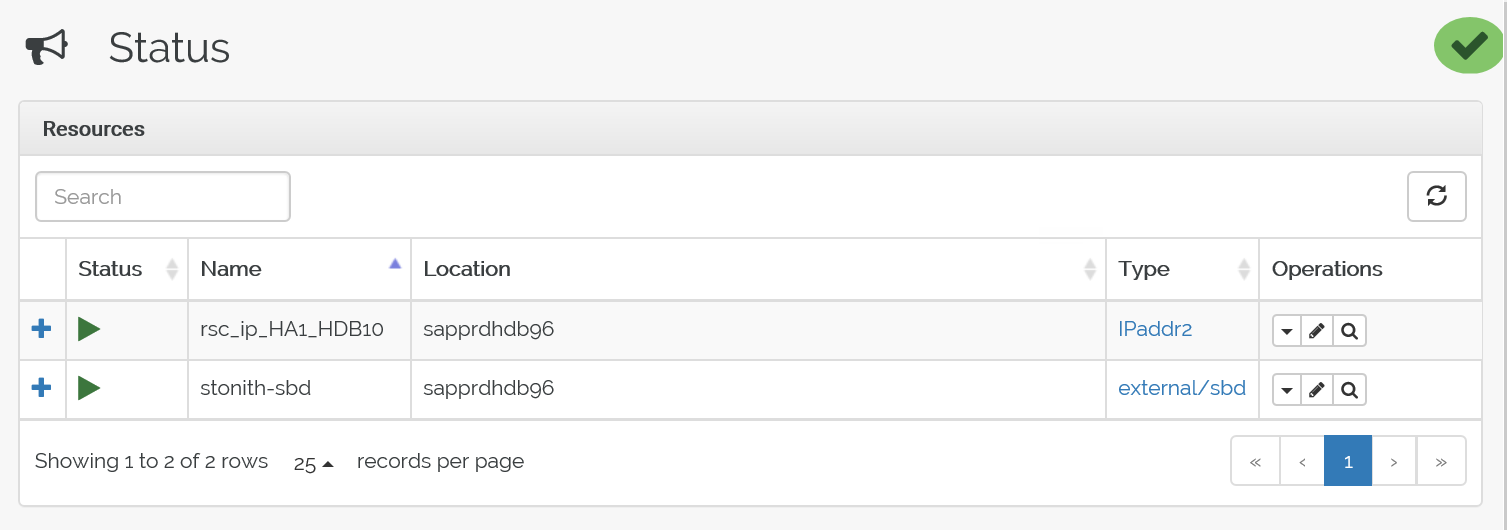
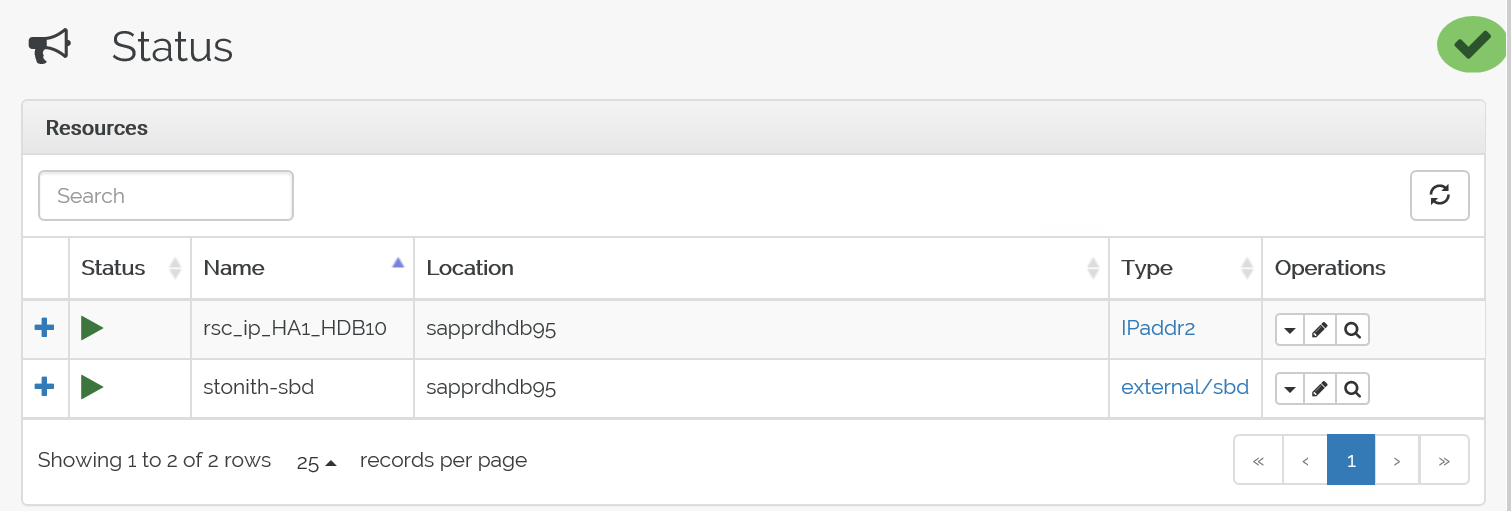
Hier sehen Sie den Status nach dem Failover:

Problembehandlung
In diesem Abschnitt werden Fehlerszenarien beschrieben, die während des Setups auftreten können.
Szenario 1: Der Clusterknoten ist nicht online.
Wenn der Knoten im Cluster-Manager nicht als „online“ angezeigt wird, können Sie Folgendes versuchen, um ihn online zu schalten.
Verwenden Sie den folgenden Befehl zum Starten des iSCSI-Diensts.
service iscsid startVerwenden Sie den folgenden Befehl, um sich bei diesem iSCSI-Knoten anzumelden.
iscsiadm -m node -lDie erwartete Ausgabe sieht wie folgt aus:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Szenario 2: yast2 zeigt keine grafische Ansicht an
In diesem Artikel wurde der grafische yast2-Bildschirm zum Konfigurieren des Hochverfügbarkeitsclusters verwendet. Wenn yast2 nicht wie gezeigt mit dem grafischen Fenster geöffnet und stattdessen ein Qt-Fehler ausgelöst wird, führen Sie die folgenden Schritte aus, um die erforderlichen Pakete zu installieren. Wenn es mit dem grafischen Fenster geöffnet wird, können Sie die Schritte überspringen.
Hier sehen Sie ein Beispiel für den Qt-Fehler:

Dies ist ein Beispiel für die erwartete Ausgabe:
Stellen Sie sicher, dass Sie als „root“-Benutzer angemeldet sind und SMT für den Download bzw. die Installation der Pakete konfiguriert haben.
Navigieren Sie zu yast>Software>Software Management>Dependencies (Abhängigkeiten), und wählen Sie dann Install recommended packages (Empfohlene Pakete installieren) aus.
Hinweis
Führen Sie die Schritte auf beiden Knoten aus, damit Sie über beide Knoten auf die grafische Ansicht von yast2 zugreifen können.
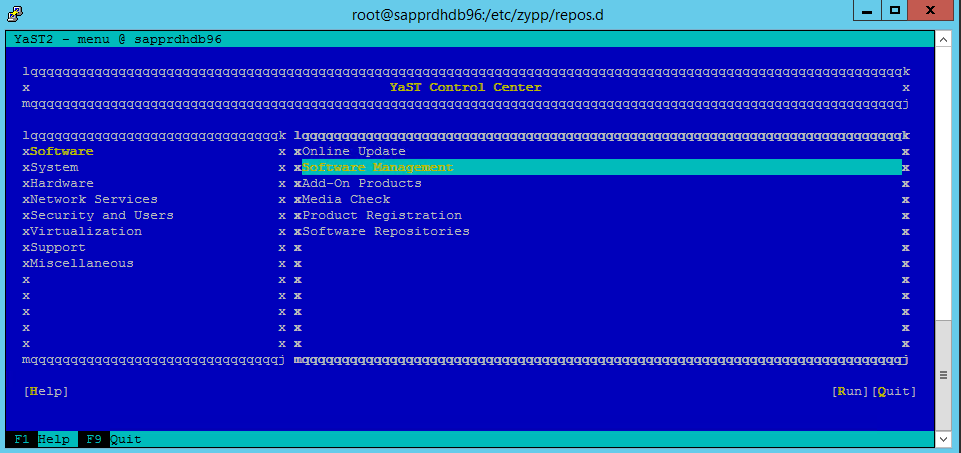
Der folgende Screenshot zeigt den erwarteten Bildschirm an.
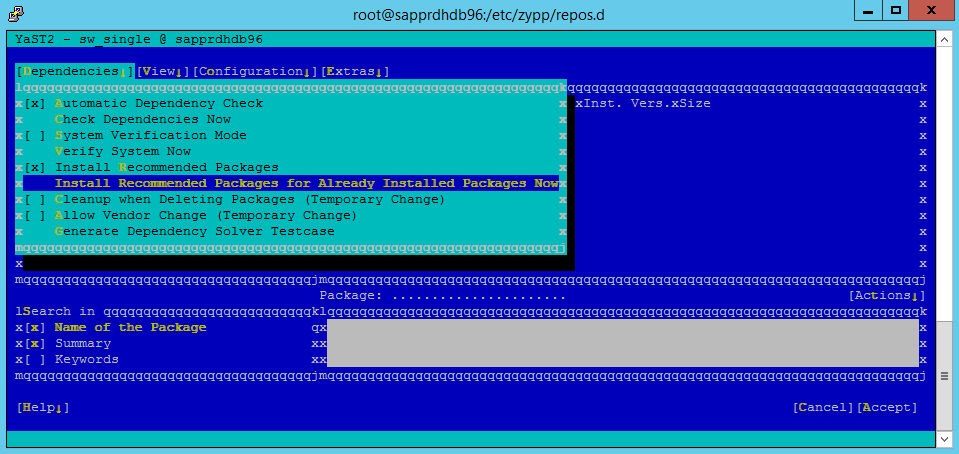
Wählen Sie unter Dependencies (Abhängigkeiten) die Option Install Recommended Packages (Empfohlene Pakete installieren) aus.
Überprüfen Sie die Änderungen, und wählen Sie OK aus.
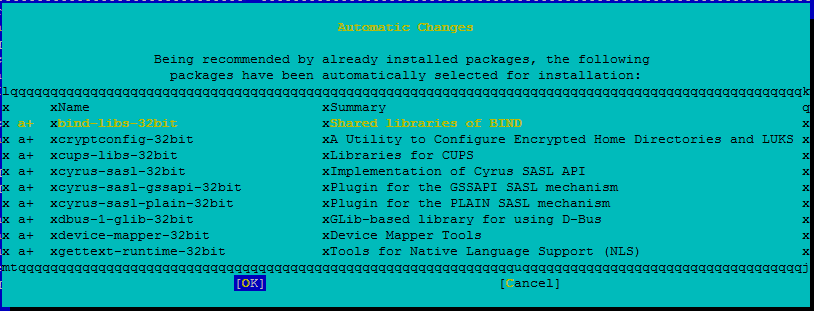
Die Paketinstallation wird fortgesetzt.
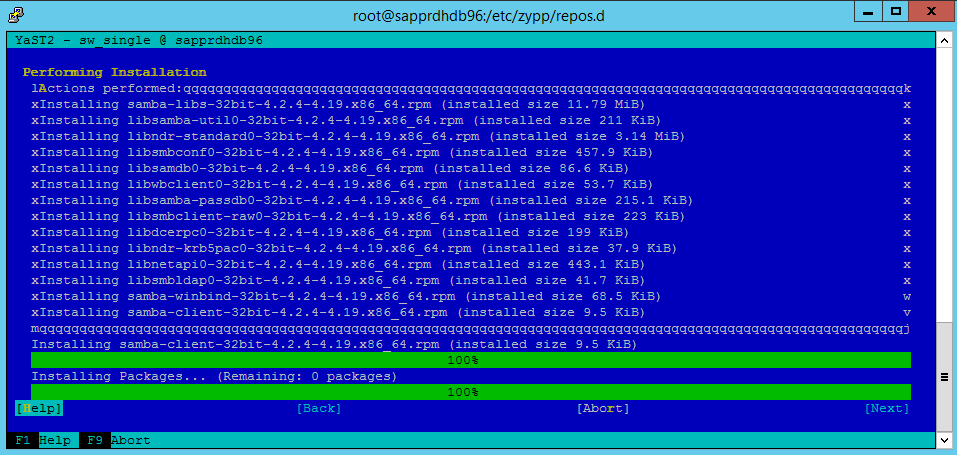
Wählen Sie Weiter aus.
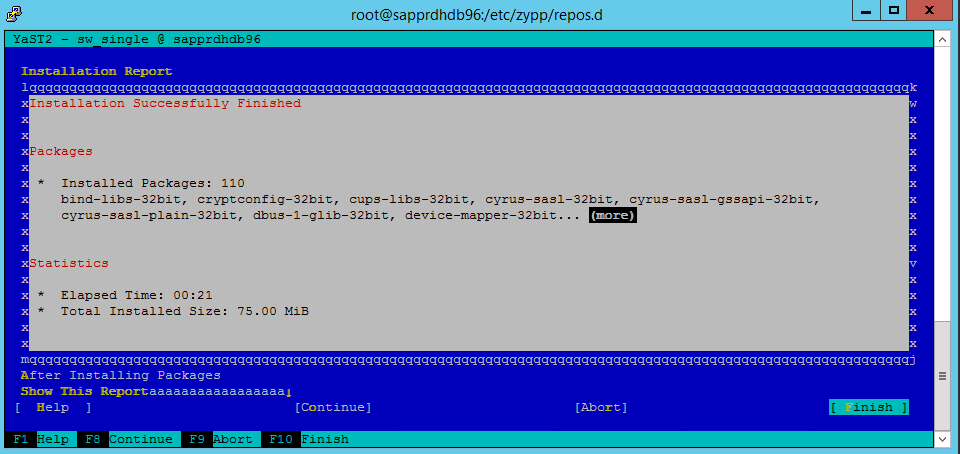
Wenn der Bildschirm Installation Successfully Finished (Installation erfolgreich abgeschlossen) angezeigt wird, wählen Sie Finish (Fertig stellen) aus.
Verwenden Sie die folgenden Befehle, um die Pakete libqt4 und libyui-qt zu installieren.
zypper -n install libqt4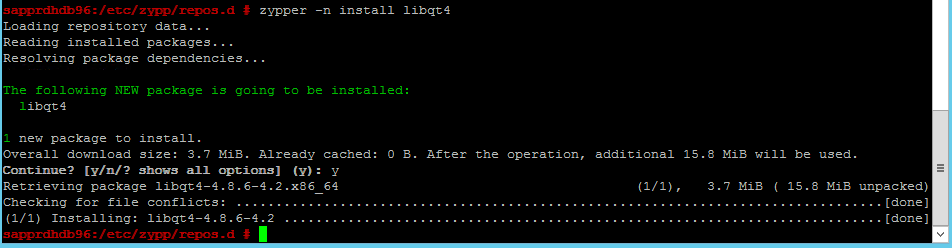
zypper -n install libyui-qt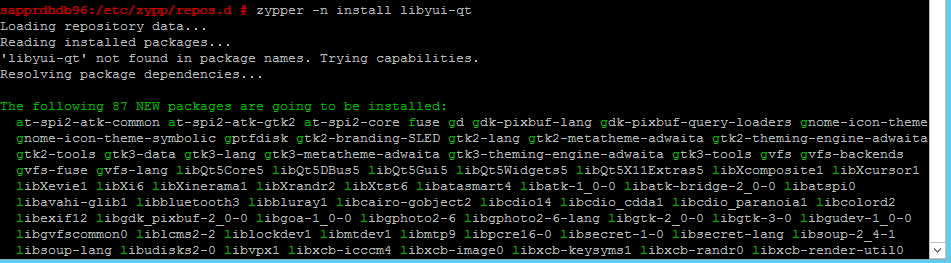

Yast2 kann die grafische Ansicht nun öffnen.
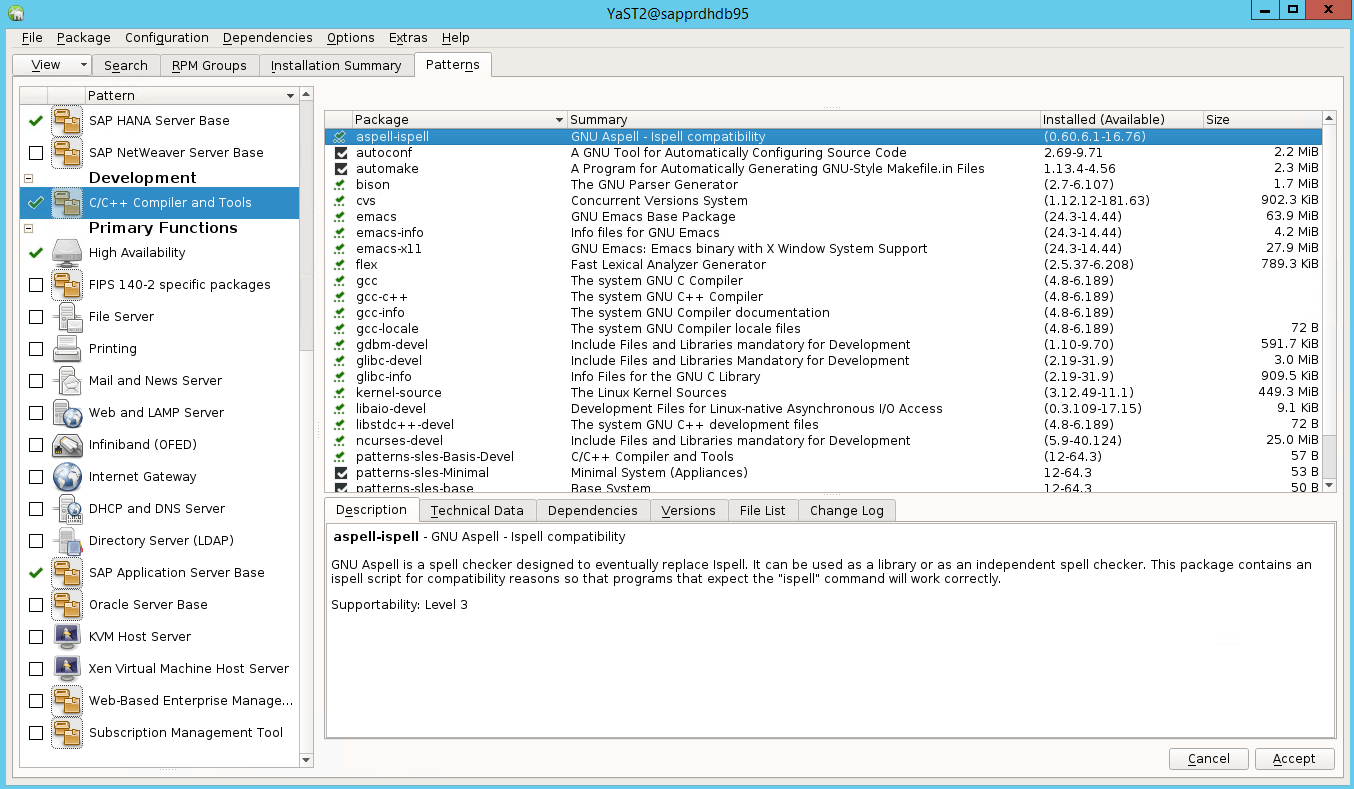
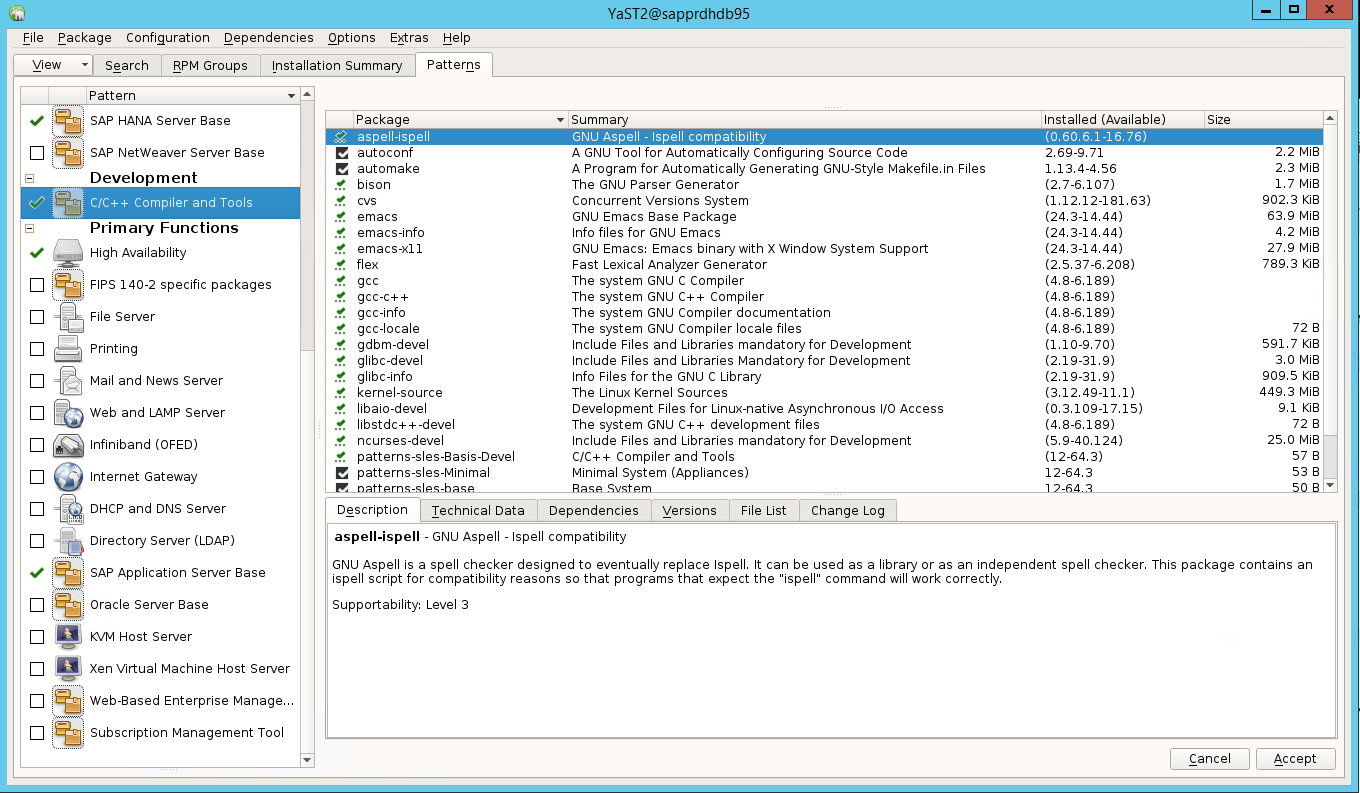
Szenario 3: Yast2 zeigt die Hochverfügbarkeitsoption nicht an
Damit die Hochverfügbarkeitsoption im Control Center von yast2 angezeigt wird, müssen Sie die anderen Pakete installieren.
Navigieren Sie zu Yast2>Software>Software Management. Wählen Sie dann Software>Online Update aus.
Wählen Sie Muster für die folgenden Elemente aus. Wählen Sie dann Accept (Akzeptieren) aus.
- SAP HANA-Serverbasis
- C/C++-Compiler und -Tools
- Hochverfügbarkeit
- SAP-Anwendungsserverbasis
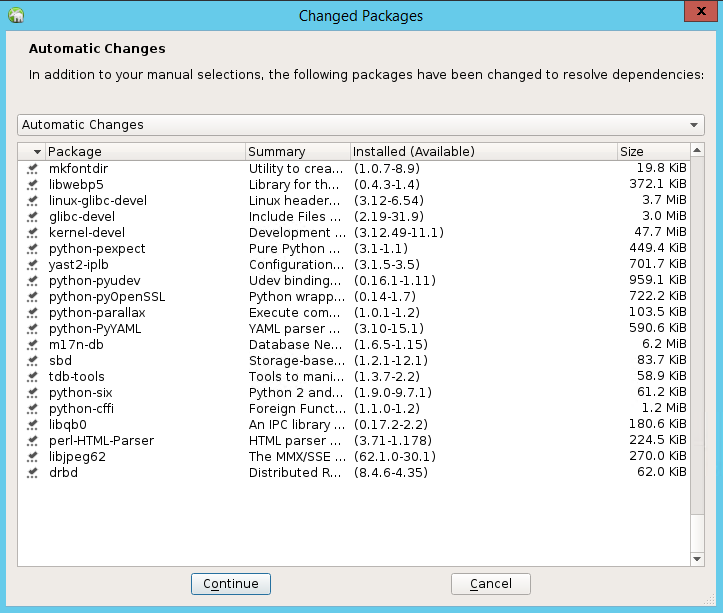
Wählen Sie in der Liste der Pakete, die geändert wurden, um Abhängigkeiten aufzulösen, Weiter aus.
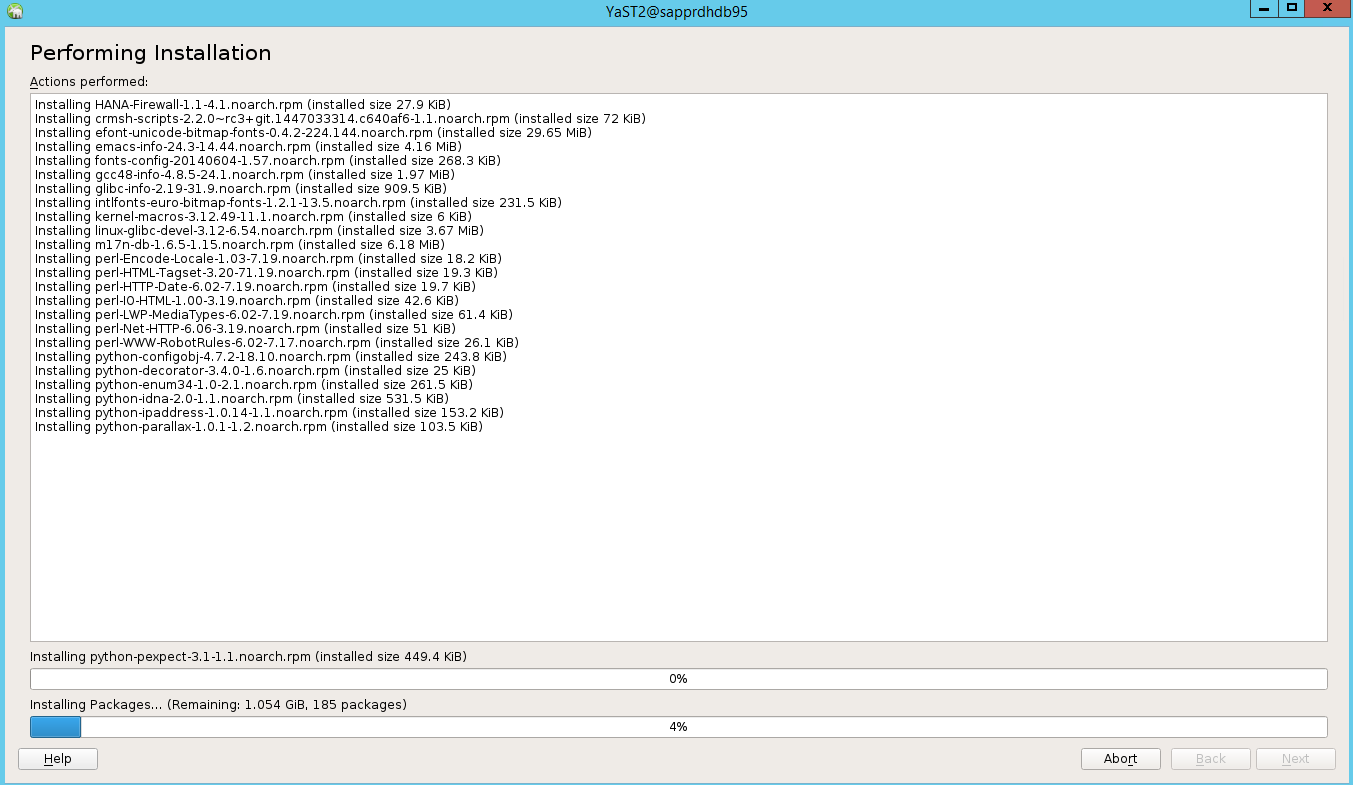
Wählen Sie Next (Weiter) auf der Statusseite Performing Installation (Installation wird ausgeführt) aus.
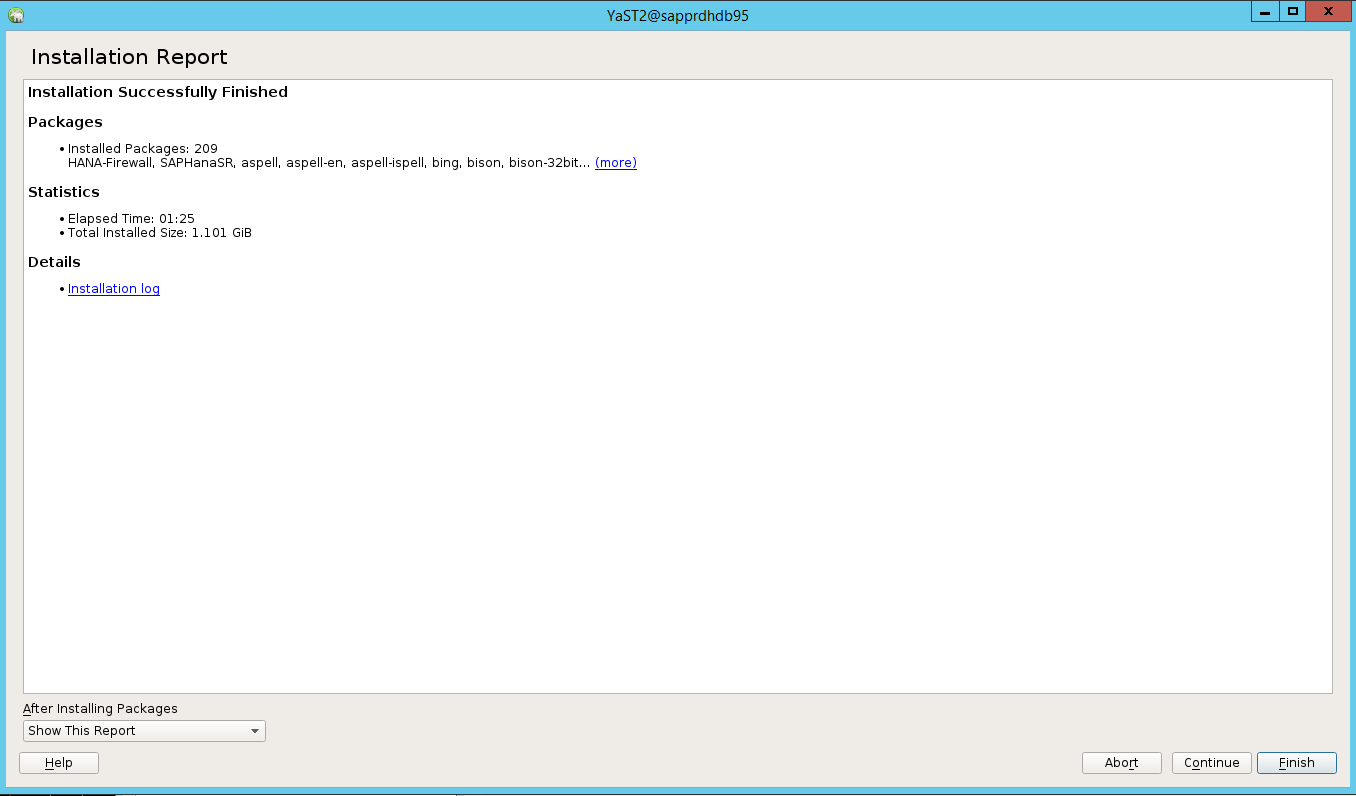
Nach Abschluss der Installation wird ein Installationsbericht angezeigt. Wählen Sie Fertig stellen aus.
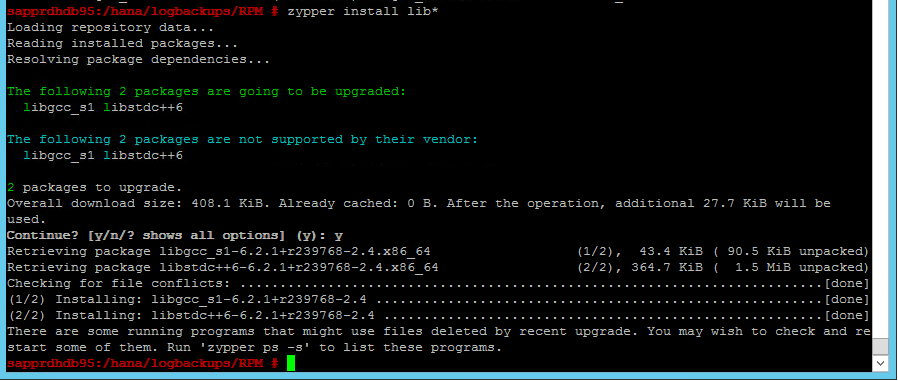
Szenario 4: Bei der HANA-Installation tritt ein GCC-Assemblyfehler auf.
Wenn bei der HANA-Installation ein Fehler auftritt, erhalten Sie möglicherweise die folgende Fehlermeldung.
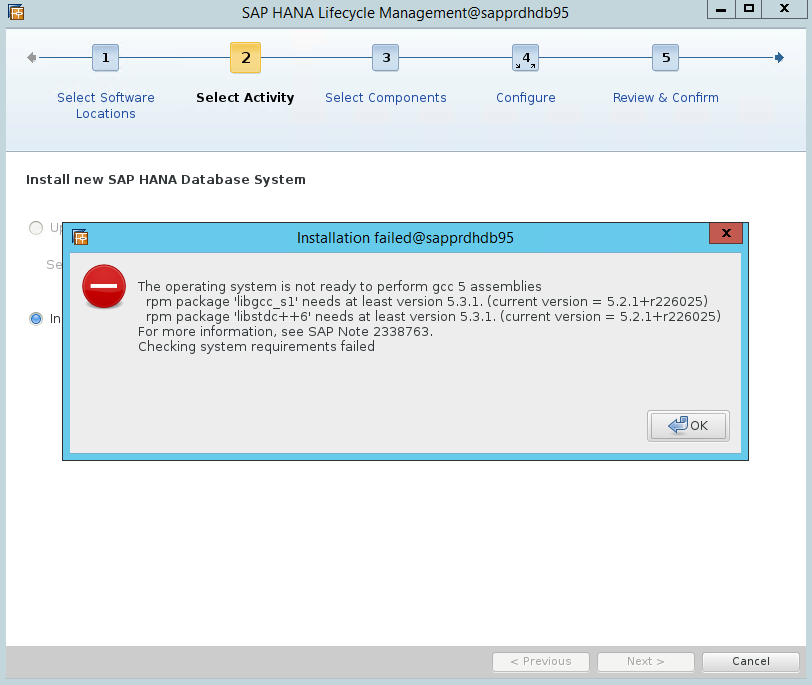
Installieren Sie die Bibliotheken libgcc_sl und libstdc++6 wie im folgenden Screenshot gezeigt, um das Problem zu beheben.
Szenario 5: Beim Pacemaker-Dienst tritt ein Fehler auf.
Die folgenden Informationen werden angezeigt, wenn der Pacemaker-Dienst nicht gestartet werden kann.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
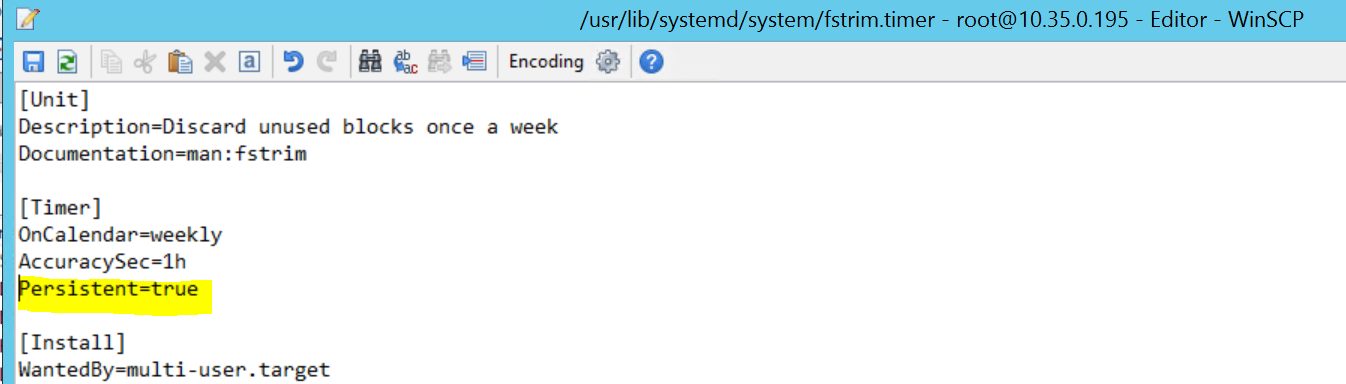
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Um dieses Problem zu beheben, löschen Sie die folgende Zeile aus der Datei /usr/lib/systemd/system/fstrim.timer:
Persistent=true
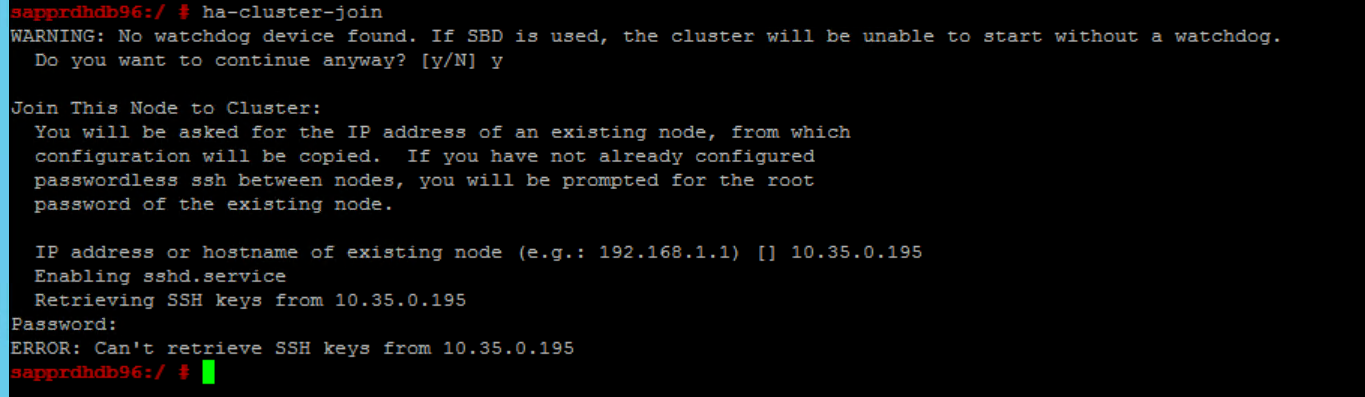
Szenario 6: Node2 kann dem Cluster nicht beitreten
Der folgende Fehler wird angezeigt, wenn beim Beitritt von node2 zum vorhandenen Cluster über den Befehl ha-cluster-join ein Problem auftritt.
ERROR: Can’t retrieve SSH keys from <Primary Node>
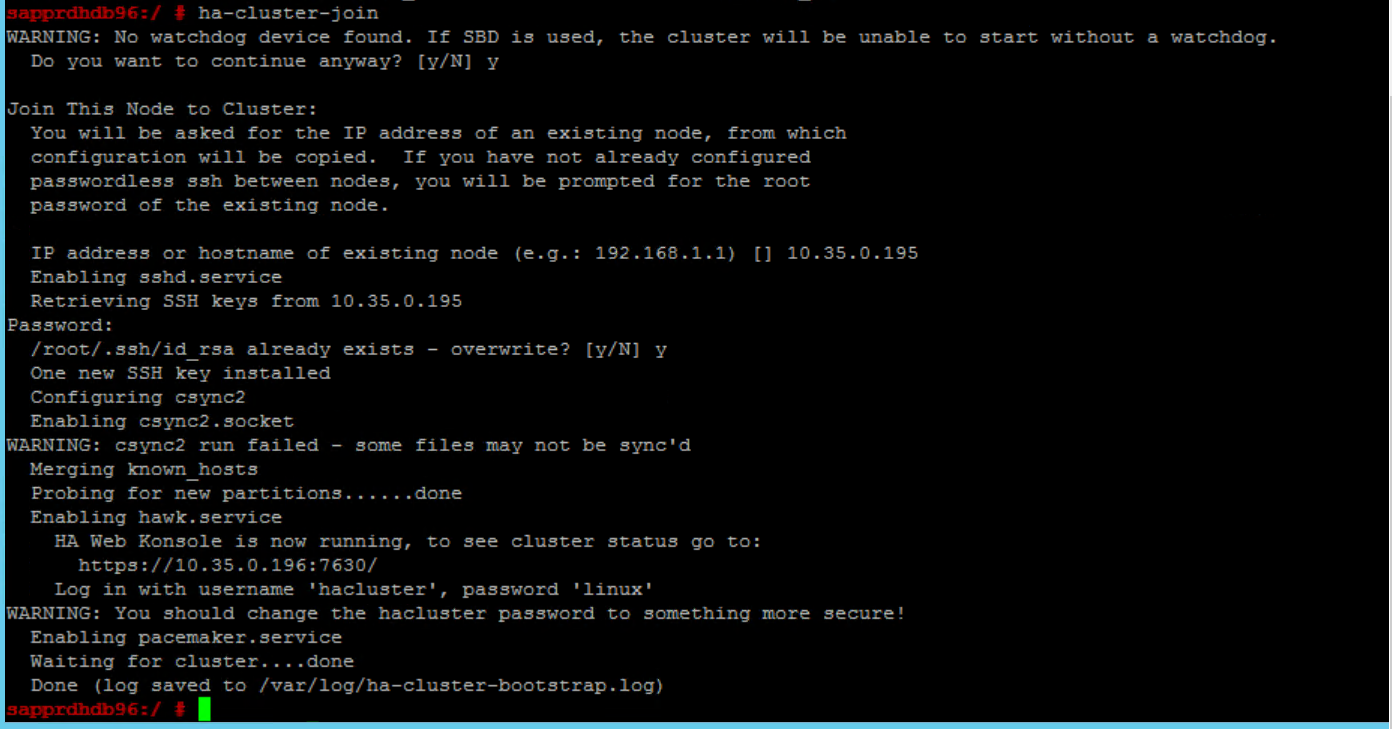
Problemlösung:
Führen Sie die folgenden Befehle auf beiden Knoten aus.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Bestätigen Sie, dass node2 dem Cluster hinzugefügt wurde.
Nächste Schritte
Weitere Informationen zur Hochverfügbarkeitskonfiguration unter SUSE finden Sie in folgenden Artikeln:
- SAP HANA SR Performance Optimized Scenario (Leistungsoptimiertes SAP HANA-SR-Szenario) (SUSE-Website)
- Fencing und Fencinggeräte (SUSE-Website)
- Be Prepared for Using Pacemaker Cluster for SAP HANA – Part 1: Basics (Vorbereiten auf die Verwendung des Pacemaker-Clusters für SAP HANA – Teil 1: Grundlagen) (SAP-Blog)
- Be Prepared for Using Pacemaker Cluster for SAP HANA – Part 2: Failure of Both Nodes (Vorbereiten auf die Verwendung des Pacemaker-Clusters für SAP HANA – Teil 2: Fehler beider Knoten) (SAP-Blog)
- Betriebssystemsicherung und -wiederherstellung