Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure NetApp Files verfügt über native NFS-Freigaben, die für die Volumes /hana/shared, /hana/data und /hana/log verwendet werden können. Zur Nutzung von ANF-basierten NFS-Freigaben für die Volumes /hana/data und /hana/log wird das v4.1 NFS-Protokoll benötigt. Das NFS-Protokoll v3 wird nicht für die Nutzung der Volumes /hana/data und /hana/log unterstützt, wenn die Freigaben auf ANF basieren.
Wichtig
Die Verwendung des NFS v3-Protokolls, das für Azure NetApp Files implementiert wurde, wird für /hana/data und /hana/lognicht unterstützt. Die Verwendung von NFS 4.1 ist für die Volumes /hana/data und /hana/log aus funktionaler Sicht obligatorisch. Während für das Volume /hana/shared das Protokoll NFS v3 oder NFS v4.1 aus funktionaler Sicht verwendet werden kann.
Wichtige Hinweise
Wenn Sie Azure NetApp Files für die Hochverfügbarkeitsarchitektur von SAP NetWeaver und SAP HANA in Betracht ziehen, beziehen Sie die folgenden wichtigen Überlegungen mit ein:
Informationen zu Grenzwerten für Volumes und Kapazitätspools finden Sie unter Ressourcengrenzwerte für Azure NetApp Files.
Azure NetApp Files-basierte NFS-Freigaben und die VMs, auf denen diese Freigabe eingebunden werden, müssen sich in derselben Azure Virtual Network-Instanz oder in virtuellen Netzwerken mit Peering in derselben Region befinden.
Das ausgewählte virtuelle Netzwerk muss über ein an Azure NetApp Files delegiertes Subnetz verfügen. Für SAP-Workload wird dringend empfohlen, einen /25-Bereich für das Subnetz zu konfigurieren, das an Azure NetApp Files delegiert wurde.
Es ist wichtig, dass die VMs in ausreichender Nähe zum Azure NetApp-Speicher bereitgestellt werden, um eine geringere Latenz zu erreichen, wie sie beispielsweise von SAP HANA für Wiederholungsprotokollschreibvorgänge gefordert wird.
- Azure NetApp Files verfügt mittlerweile über Funktionen zum Bereitstellen von NFS-Volumes in bestimmten Azure-Verfügbarkeitszonen. Eine solche Zonennähe reicht in den meisten Fällen aus, um eine Latenz von weniger als 1 Millisekunde zu erreichen. Die Funktionalität befindet sich in der öffentlichen Vorschau und wird im Artikel Verwalten der Platzierung von Verfügbarkeitszonenvolumes für Azure NetApp Files beschrieben. Diese Funktionalität erfordert keinen interaktiven Prozess mit Microsoft, um die Nähe zwischen Ihrer VM und den von Ihnen zugewiesenen NFS-Volumes zu erreichen.
- Um optimale Nähe zu erreichen, ist die Funktionalität von Anwendungsvolumegruppen verfügbar. Diese Funktionalität sucht nicht nur nach optimaler Nähe, sondern auch nach optimaler Platzierung der NFS-Volumes, sodass HANA-Daten- und Wiederholungsprotokollvolumes von verschiedenen Controllern verarbeitet werden. Der Nachteil besteht darin, dass diese Methode einen interaktiven Prozess mit Microsoft benötigt, um Ihre VMs einzupassen.
Stellen Sie sicher, dass die Latenz zwischen dem Datenbankserver und dem Azure NetApp Files-Volume gemessen wird und unter 1 Millisekunde liegt.
Der Durchsatz eines Azure NetApp-Volumes ist eine Funktion des Volumekontingents und der Dienstebene, wie in Dienstebenen für Azure NetApp Files beschrieben. Stellen Sie bei der Größenanpassung der HANA Azure NetApp-Volumes sicher, dass der sich ergebende Durchsatz die HANA-Systemanforderungen erfüllt. Alternativ können Sie einen manuellen QoS-Kapazitätspool verwenden, in dem Volumenkapazität und -durchsatz unabhängig konfiguriert und skaliert werden können (SAP HANA-spezifische Beispiele finden Sie in diesem Dokument).
Versuchen Sie, Volumes zu „konsolidieren“, um mit einem größeren Volume höhere Leistung zu erzielen, verwenden Sie z. B. ein Volume für „/sapmnt“, „/usr/sap/trans“..., wenn möglich.
Azure NetApp Files bietet Exportrichtlinien: Sie können die zulässigen Clients und den Zugriffstyp (Lesen und Schreiben, schreibgeschützt usw.) steuern.
Die Benutzer-ID für sidadm und die Gruppen-ID für
sapsysauf den VMs müssen mit der Konfiguration in Azure NetApp Files übereinstimmen.Implementieren von Parametern des Linux-Betriebssystems, die in SAP-Hinweis 3024346 erwähnt werden
Wichtig
Bei SAP HANA-Workloads ist eine niedrige Latenz sehr wichtig. Arbeiten Sie mit Ihrem Microsoft-Vertreter zusammen, um sicherzustellen, dass die virtuellen Computer und die Azure NetApp Files-Volumes in unmittelbarer Nähe zueinander bereitgestellt werden.
Wichtig
Wenn die Benutzer-ID für „sidadm“ und die Gruppen-ID für sapsys auf der VM und in der Azure NetApp-Konfiguration nicht übereinstimmen, werden die Berechtigungen für Dateien auf Azure NetApp-Volumes, die auf der VM eingebunden sind, als nobody angezeigt. Stellen Sie beim Onboarding eines neuen Systems in Azure NetApp Files sicher, dass Sie die richtige Benutzer-ID für „sidadm“ und die Gruppen-ID für sapsys angeben.
NCONNECT-Einbindungsoption
Nconnect ist eine Einbindungsoption für NFS-Volumes, die auf Azure NetApp Files gehostet werden. Sie ermöglicht es dem NFS-Client, mehrere Sitzungen für ein einzelnes NFS-Volume zu öffnen. Wenn Sie Nconnect mit einem Wert verwenden, der größer als 1 ist, nutzt der NFS-Client mehr als eine RPC-Sitzung auf Clientseite (im Gastbetriebssystem), um den Datenverkehr zwischen dem Gastbetriebssystem und den bereitgestellten NFS-Volumes zu verarbeiten. Die Verwendung mehrerer Sitzungen, die Datenverkehr eines NFS-Volumes verarbeiten, aber auch die Verwendung mehrerer RPC-Sitzungen können sich auf Leistungs- und Durchsatzszenarios auswirken, z. B.:
- Einbinden mehrerer auf Azure NetApp Files gehosteter NFS-Volumes mit unterschiedlichen Servicelevels auf einem virtuellen Computer
- Der maximale Schreibdurchsatz für ein Volume und eine einzelne Linux-Sitzung liegt zwischen 1,2 und 1,4 GB/s. Mehrere Sitzungen für ein auf Azure NetApp Files gehostetes NFS-Volume können den Durchsatz erhöhen
Informationen zu Linux-Betriebssystemreleases, die Nconnect als Einbindungsoption unterstützen, sowie einige wichtige Überlegungen zur Konfiguration von Nconnect (insbesondere bei Verwendung verschiedener NFS-Serverendpunkte) finden Sie im DokumentBewährte Methoden für Linux NFS-Einbindungsoptionen für Azure NetApp Files.
Größenanpassung für eine HANA-Datenbank in Azure NetApp Files
Der Durchsatz eines Azure NetApp-Volumes ist eine Funktion der Volumegröße und der Dienstebene, wie in Dienstebenen für Azure NetApp Files beschrieben.
Es ist wichtig, die Leistungsbeziehung und die Größe zu kennen, und zu wissen, dass es physikalische Grenzwerte für einen Speicherendpunkt des Diensts gibt. Jeder Speicherendpunkt wird bei der Volumeerstellung dynamisch in das Azure NetApp Files delegierte Subnetz eingefügt und erhält eine IP-Adresse. Azure NetApp Files-Volumes können – je nach verfügbarer Kapazität und Bereitstellungslogik – einen gemeinsamen Speicherendpunkt nutzen.
Die folgende Tabelle zeigt, dass es sinnvoll sein kann, ein großes „Standard“-Volume zum Speichern von Sicherungen zu erstellen, und dass es nicht sinnvoll ist, ein „Ultra“-Volume zu erstellen, das größer als 12 TB ist, da die maximale physische Bandbreitenkapazität eines einzelnen Volumes überschritten würde.
Wenn Sie mehr als den maximalen Schreibdurchsatz für Ihr /hana/data-Volume benötigen, als durch eine einzelne Linux-Sitzung bereitgestellt werden kann, können Sie alternativ auch die SAP HANA-Partitionierung für Datenvolumes verwenden. Durch die SAP HANA-Partitionierung für Datenvolumes wird für die E/A-Aktivität während des erneuten Ladens von Daten oder HANA-Sicherungspunkten über mehrere HANA-Datendateien, die sich auf mehreren NFS-Freigaben befinden, ein Striping vorgenommen. Weitere Informationen zum Striping von HANA-Datenvolumen finden Sie in diesen Artikeln:
- HANA-Administratorhandbuch
- Blog zu SAP HANA-Datenvolumepartitionierung
- SAP Note 2400005
- SAP-Hinweis 2700123
| Size | Durchsatz Standard | Durchsatz Premium | Durchsatz Ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1\.280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1\.400 MB/s1 |
| 20 TB | 320 MB/s | 1\.280 MB/s | 1\.400 MB/s1 |
| 40 TB | 640 MB/s | 1\.400 MB/s1 | 1\.400 MB/s1 |
1: Durchsatzlimits für Schreibvorgänge oder für Lesevorgänge in einzelnen Sitzungen (für den Fall, dass die NFS-Bereitstellungsoption „nconnect“ nicht verwendet wird)
Es ist wichtig zu wissen, dass die Daten im Speicher-Back-End auf die gleichen SSDs geschrieben werden. Das Leistungskontingent aus dem Kapazitätspool wurde erstellt, um die Umgebung verwalten zu können. Die Speicher-KPIs sind für alle HANA-Datenbankgrößen gleich. In fast allen Fällen spiegelt diese Annahme nicht die Realität und die Kundenerwartung wider. Die Größe von HANA-Systemen bedeutet nicht notwendigerweise, dass ein kleines System einen niedrigen und ein großes System einen hohen Speicherdurchsatz erfordert. Im Allgemeinen sind jedoch für größere HANA-Datenbankinstanzen höhere Durchsatzanforderungen zu erwarten. Infolge der Dimensionierungsregeln von SAP für die zugrunde liegende Hardware bieten solch größere HANA-Instanzen auch mehr CPU-Ressourcen und eine höhere Parallelität in Aufgaben wie dem Laden von Daten nach einem Neustart einer Instanz. Daher sollten die Volumegrößen den Erwartungen und Anforderungen der Kunden angepasst werden. Sie sollten nicht nur durch reine Kapazitätsanforderungen bestimmt werden.
Beim Entwerfen der Infrastruktur für SAP in Azure müssen Sie einige Mindestanforderungen von SAP an den Speicherdurchsatz (für Produktionssysteme) beachten. Diese Anforderungen führen zu den folgenden Mindestdurchsatzeigenschaften:
| Volumetyp und E/A-Typ | Minimaler KPI-Bedarf von SAP | Premium-Servicelevel | Ultra-Servicelevel |
|---|---|---|---|
| Protokollvolume – Schreiben | 250 MB/s | 4 TB | 2 TB |
| Datenvolume – Schreiben | 250 MB/s | 4 TB | 2 TB |
| Datenvolume – Lesen | 400 MB/s | 6,3 TB | 3,2 TB |
Da alle drei KPIs erforderlich sind, muss das /hana/data-Volume auf die größere Kapazität skaliert werden, um die minimalen Leseanforderungen zu erfüllen. Wenn Sie manuelle QoS-Kapazitätspools verwenden, können Größe und Durchsatz der Volumes unabhängig voneinander definiert werden. Da sowohl die Kapazität als auch der Durchsatz aus demselben Kapazitätspool entnommen werden, müssen die Dienstebene und die Größe des Pools ausreichend groß sein, um die Gesamtleistung zu erbringen (ein Beispiel finden Sie hier).
Bei HANA-Systemen, für die keine hohe Bandbreite erforderlich ist, kann der Durchsatz des Azure NetApp Files-Volumes entweder durch eine kleinere Volumegröße oder bei manuellem QoS durch direktes Anpassen des Durchsatzes verringert werden. Für den Fall, dass ein HANA-System mehr Durchsatz erfordert, kann das Volume angepasst werden, indem die Größe der Kapazität online geändert wird. Für Sicherungsvolumes sind keine KPIs definiert. Der Durchsatz des Sicherungsvolumes ist jedoch für eine gut funktionierende Umgebung entscheidend. Die Leistung von Protokoll- und Datenvolume muss auf die Kundenerwartungen zugeschnitten werden.
Wichtig
Unabhängig von der Kapazität, die Sie auf einem einzelnen NFS-Volume bereitstellen, wird erwartet, dass der Durchsatz im Bereich von 1,2 bis 1,4 GB/Sek. Bandbreite von einem Consumer in einer einzelnen Sitzung genutzt wird. Dies hat mit der zugrundeliegenden Architektur des Azure NetApp Files-Angebots und den damit verbundenen Einschränkungen der Linux-Sitzungen bezüglich NFS zu tun. Die Leistungs- und Durchsatzzahlen, die im Artikel Ergebnisse des Leistungsbenchmarktests für Azure NetApp Files beschrieben werden, wurden für ein gemeinsam genutztes NFS-Volume mit mehreren Client-VMs und daher mit mehreren Sitzungen durchgeführt. Dieses Szenario unterscheidet sich von dem Szenario, das wir in SAP messen, wo wir den Durchsatz von einer einzelnen VM gegen ein NFS-Volume messen, das auf Azure NetApp Files gehostet wird.
Um die SAP-Mindestanforderungen für den Durchsatz für Daten und Protokolle und die Richtlinien für /hana/shared zu erfüllen, werden folgende Größen empfohlen:
| Volume | Size Storage Premium-Tarif |
Size Storage Ultra-Tarif |
Unterstütztes NFS-Protokoll |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6,3 TiB | 3,2 TiB | v4.1 |
| /hana/shared hochskalieren | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 oder v4.1 |
| /hana/shared aufskalieren | 1 x RAM des Workerknotens pro vier Workerknoten |
1 x RAM des Workerknotens pro vier Workerknoten |
v3 oder v4.1 |
| /hana/logbackup | 3 × RAM | 3 × RAM | v3 oder v4.1 |
| /hana/backup | 2 × RAM | 2 × RAM | v3 oder v4.1 |
Für alle Volumes wird NFS v4.1 dringend empfohlen.
Überprüfen Sie sorgfältig die Überlegungen zur Dimensionierung/hana/shared, entsprechend der Größe des /hana/shared Volumens trägt zur Stabilität des Systems bei.
Die Größen der Sicherungsvolumes sind Schätzungen. Genaue Anforderungen müssen auf der Grundlage von Workload und Vorgangsprozessen definiert werden. Bei Sicherungen können Sie viele Volumes für verschiedene SAP HANA-Instanzen zu einem größeren Volume (oder zwei) konsolidieren, das einen niedrigeren Azure NetApp Files-Servicelevel haben könnte.
Hinweis
Die in diesem Dokument angegebenen Empfehlungen für die Azure NetApp Files-Größenanpassung zielen darauf ab, die Mindestanforderungen zu erfüllen, die SAP an seine Infrastrukturanbieter stellt. In realen Kundenbereitstellungen und Workloadszenarien sind sie möglicherweise nicht ausreichend. Verwenden Sie diese Empfehlungen also als Ausgangspunkt, und nehmen Sie Anpassungen auf Grundlage der Anforderungen der spezifischen Workload vor.
Daher könnten Sie für die Azure NetApp Files-Volumes einen ähnlichen wie den bereits für Disk Storage Ultra angegebenen Durchsatz bereitstellen. Beachten Sie auch die Größen, die für die Volumes verschiedener VM-SKUs bereits in den Tabellen zu Ultra Disks aufgeführt sind.
Tipp
Sie können die Größe der Azure NetApp Files-Volumes dynamisch anpassen, ohne die Bereitstellung der Volumes aufheben (unmount) oder die virtuellen Computer oder SAP HANA beenden zu müssen. Damit kann Ihre Anwendung sowohl den erwarteten als auch unvorhergesehenen Durchsatzanforderungen flexibel gerecht werden.
Die Dokumentation zur Bereitstellung einer SAP HANA-Konfiguration für horizontale Skalierung mit Standbyknoten über Azure NetApp Files-basierte NFS v4.1-Volumes wird in Horizontale SAP HANA-Skalierung mit Standbyknoten auf Azure-VMs mit Azure NetApp Files auf SUSE Linux Enterprise Server veröffentlicht.
Linux-Kerneleinstellungen
Um SAP HANA erfolgreich auf Azure NetApp Files bereitzustellen, müssen die Linux-Kerneleinstellungen gemäß SAP-Hinweis 3024346 implementiert werden.
Für Systeme mit Hochverfügbarkeit (High Availability, HA) mit Pacemaker und Azure Load Balancer müssen die folgenden Einstellungen in der Datei „/etc/sysctl.d/91-NetApp-HANA.conf“ implementiert werden.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Systeme, die ohne Pacemaker und Azure Load Balancer ausgeführt werden, sollten diese Einstellungen in „/etc/sysctl.d/91-NetApp-HANA.conf“ implementieren.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Bereitstellung mit zonaler Nähe
Um zonale Nähe Ihrer NFS-Volumes und VMs herzustellen, können Sie die Anweisungen befolgen, die unter Verwalten der Platzierung von Verfügbarkeitszonenvolumes für Azure NetApp Files beschrieben werden. Bei dieser Methode befinden sich die VMs und NFS-Volumes in derselben Azure-Verfügbarkeitszone. In den meisten Azure-Regionen sollte diese Art von Nähe ausreichen, um eine Latenz von weniger als 1 Millisekunde für die kleineren Wiederholungsprotokollschreibvorgänge für SAP HANA zu erreichen. Diese Methode erfordert keine interaktive Zusammenarbeit mit Microsoft, um VMs in einem bestimmten Rechenzentrum zu platzieren und einzupassen. Daher sind Sie flexibel beim Ändern von VM-Größen und -Produktfamilien innerhalb aller VM-Typen und -Produktfamilien, die in der Verfügbarkeitszone angeboten werden, in der die Bereitstellung erfolgt ist. So können Sie flexibel auf sich ändernde Bedingungen reagieren oder schneller zu kosteneffizienteren VM-Größen oder -Produktfamilien wechseln. Wir empfehlen diese Methode für Nicht-Produktionssysteme und Produktionssysteme, die mit Wiederholungsprotokoll-Latenzzeiten arbeiten können, die näher an 1 Millisekunde liegen. Die Funktion befindet sich derzeit in der Public Preview.
Bereitstellung über Azure NetApp Files-Anwendungsvolumengruppe für SAP HANA (AVG)
Zum Bereitstellen von Azure NetApp Files-Volumes mit Nähe zu Ihrem virtuellen Computer wurde eine neue Funktion namens „Azure NetApp Files-Anwendungsvolumegruppe für SAP HANA (AVG)“ entwickelt. Es gibt eine Reihe von Artikeln, in denen die Funktion dokumentiert wird. Beginnen Sie am besten mit dem Artikel Grundlegendes zu Azure NetApp Files-Anwendungsvolumegruppen für SAP HANA. In diesem Artikel wird verdeutlicht, dass die Verwendung von AVGs auch die Verwendung von Azure-Näherungsplatzierungsgruppen nach sich zieht. Näherungsplatzierungsgruppen werden von der neuen Funktionalität verwendet, um Verknüpfungen mit den zu erstellenden Volumes einzurichten. Um sicherzustellen, dass die VMs während der Lebensdauer des HANA-Systems nicht von den Azure NetApp Files-Volumes entfernt werden, empfehlen wir die Verwendung einer Kombination aus Avset und PPG für jede der Zonen, in der die Bereitstellung erfolgt. Die Reihenfolge der Bereitstellung sieht wie folgt aus:
- Sie müssen mithilfe des Formulars eine Anheftung des leeren AvSet an ein Compute-HW anfordern, um sicherzustellen, dass die VMs nicht verschoben werden.
- Zuweisen einer PPG zur Verfügbarkeitsgruppe und Starten eines virtuellen Computers, der dieser Verfügbarkeitsgruppe zugewiesen ist
- Verwenden der Funktion „Azure NetApp Files-Anwendungsvolumegruppe für SAP HANA“ zum Bereitstellen von HANA-Volumes
Die Konfiguration der Näherungsplatzierungsgruppe für die optimale Verwendung von AVGs sieht wie folgt aus:
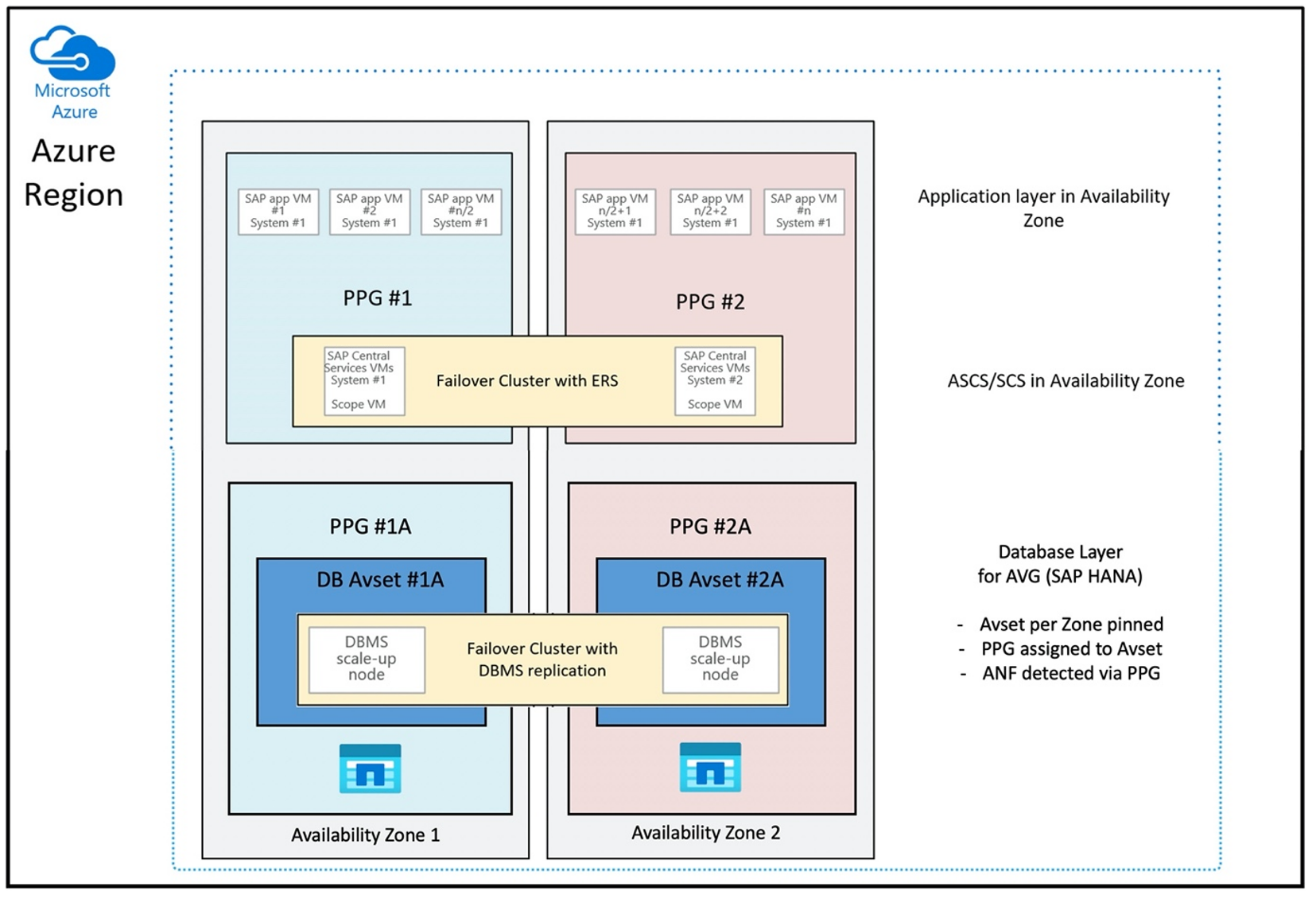
Das Diagramm zeigt, dass Sie eine Azure-Näherungsplatzierungsgruppe für die DBMS-Schicht verwenden. Dadurch kann sie zusammen mit AVGs verwendet werden. Schließen Sie am besten nur die VMs in die Näherungsplatzierungsgruppe ein, auf denen die HANA-Instanzen ausgeführt werden. Die Näherungsplatzierungsgruppe ist auch dann erforderlich, wenn nur eine VM mit einer einzelnen HANA-Instanz verwendet wird, damit die AVG die nächstgelegene Azure NetApp Files-Hardware identifizieren kann. Platzieren Sie außerdem das NFS-Volume in Azure NetApp Files so nah wie möglich an den VMs, die die NFS-Volumes verwenden.
Diese Methode generiert die besten Ergebnisse, da sie sich auf geringe Latenz bezieht. Nicht nur, indem die NFS-Volumes und VMs so nah wie möglich platziert werden. Aber auch Überlegungen zum Platzieren der Daten- und Wiederholungsprotokollvolumes auf verschiedenen Controllern im NetApp-Back-End werden berücksichtigt. Der Nachteil besteht jedoch darin, dass Ihre VM-Bereitstellung in ein Rechenzentrum eingepasst ist. Dadurch verlieren Sie Flexibilität beim Ändern von VM-Typen und -Produktfamilien. Daher sollten Sie diese Methode auf die Systeme beschränken, die eine solch geringe Speicherlatenz benötigen. Für alle anderen Systeme sollten Sie die Bereitstellung mit einer herkömmlichen zonalen Bereitstellung der VM und Azure NetApp Files versuchen. In den meisten Fällen ist dies im Hinblick auf eine geringe Wartezeit ausreichend. Dadurch wird auch eine einfache Wartung und Verwaltung der VM und Azure NetApp Files sichergestellt.
Verfügbarkeit
Updates und Upgrades von ANF-Systemen werden ohne Beeinträchtigung der Kundenumgebung angewendet. Der definierte SLA ist 99,99 %.
Volumes, IP-Adressen und Kapazitätspools
Bei ANF ist es wichtig zu verstehen, wie die zugrunde liegende Infrastruktur erstellt wird. Ein Kapazitätspool ist nur ein Konstrukt, das basierend auf der Dienstebene des Kapazitätspools ein Kapazitäts- und Leistungsbudget und eine Abrechnungseinheit bereitstellt. Ein Kapazitätspool hat keine physische Beziehung zur zugrunde liegenden Infrastruktur. Wenn Sie ein Volume im den Dienst erstellen, wird ein Speicherendpunkt erstellt. Diesem Speicherendpunkt wird eine einzelne IP-Adresse zugewiesen, um Datenzugriff auf das Volume zu ermöglichen. Wenn Sie mehrere Volumes erstellen, werden alle Volumes auf die zugrunde liegende Bare-Metal-Flotte verteilt, die an diesen Speicherendpunkt gebunden ist. Die ANF verfügt über eine Logik, die Kundenworkloads automatisch verteilt, sobald die Volumes oder/und die Kapazität des konfigurierten Speichers eine interne vordefinierte Stufe erreichen. Sie werden solche Fälle bemerken, da automatisch ein neuer Speicherendpunkt mit einer neuen IP-Adresse erstellt wird, um auf die Volumes zuzugreifen. Der ANF-Dienst bietet keine Kundenkontrolle über diese Verteilungslogik.
Protokollvolume und Protokollsicherungsvolume
Das „Protokollvolume“ ( /hana/log) wird zum Schreiben des Onlinewiederholungsprotokolls verwendet. Daher befinden sich in diesem Volume geöffnete Dateien, und es ist nicht sinnvoll, Momentaufnahmen dieses Volumes zu erstellen. Eine Onlinewiederholungsprotokoll-Datei wird im Protokollsicherungsvolume archiviert oder gesichert, sobald sie voll ist oder eine Wiederholungsprotokollsicherung ausgeführt wird. Um eine angemessene Sicherungsleistung zu gewährleisten, erfordert das Protokollsicherungsvolume einen guten Durchsatz. Um die Speicherkosten zu optimieren, kann es sinnvoll sein, das Protokollsicherungsvolume mehrerer HANA-Instanzen zu konsolidieren. Dann würden mehrere HANA-Instanzen das gleiche Volume nutzen und ihre Sicherungen in verschiedene Verzeichnisse schreiben. Mithilfe einer solchen Konsolidierung können Sie einen höheren Durchsatz erzielen, da Sie das Volume etwas vergrößern müssen.
Das gleiche gilt für das Volume, das Sie für das Schreiben vollständiger HANA-Datenbanksicherungen verwenden.
Backup
Neben Streamingsicherungen und dem Azure Backup-Dienst, der SAP HANA-Datenbanken wie im Artikel Sicherungsleitfaden für SAP HANA in Azure Virtual Machines beschrieben sichert, eröffnet Azure NetApp Files die Möglichkeit, speicherbasierte Momentaufnahmensicherungen auszuführen.
SAP HANA unterstützt:
- Unterstützung von speicherbasierter Momentaufnahmesicherung für Einzelcontainersysteme mit SAP HANA 1.0 SPS7 und höher
- Unterstützung von speicherbasierter Momentaufnahmesicherung für MDC-HANA-Umgebungen (Multi Database Container) mit einem einzelnen Mandanten mit SAP HANA 2.0 SPS1 und höher
- Unterstützung von speicherbasierter Momentaufnahmesicherung für MDC-HANA-Umgebungen (Multi Database Container) mit mehreren Mandanten mit SAP HANA 2.0 SPS4 und höher
Das Erstellen speicherbasierter Momentaufnahmensicherungen ist ein einfaches Verfahren in vier Schritten:
- Erstellen einer (internen) HANA-Datenbankmomentaufnahme – eine Aktivität, die von Ihnen oder Tools ausgeführt wird.
- SAP HANA schreibt Daten in die Datendateien, um einen konsistenten Zustand im Speicher zu schaffen – HANA führt diesen Schritt aus, wenn eine HANA-Momentaufnahme erstellt wird.
- Erstellen einer Momentaufnahme auf dem /hana/data-Volume im Speicher – ein Schritt, der von Ihnen oder Tools ausgeführt wird. Es ist nicht erforderlich, eine Momentaufnahme auf dem Volume /hana/log auszuführen.
- Löschen der (internen) HANA-Datenbankmomentaufnahme und Fortsetzen des normalen Betriebs – ein Schritt, der von Ihnen oder Tools ausgeführt wird.
Warnung
Wenn der letzte Schritt fehlt oder nicht durchgeführt werden kann, wirkt sich dies schwerwiegend auf den Arbeitsspeicherbedarf von SAP HANA aus und kann zu einem Anhalten von SAP HANA führen.
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Der Vorgang der Momentaufnahmensicherung kann auf unterschiedliche Weise mithilfe verschiedener Tools verwaltet werden.
Achtung
Eine Momentaufnahme an sich ist keine geschützte Sicherung, da sie sich im gleichen physischen Speicher befindet wie das Volume, von dem Sie gerade diese Momentaufnahme erstellt haben. Es ist unbedingt erforderlich, mindestens eine Momentaufnahme pro Tag an einem anderen Speicherort zu sichern. Dies kann in derselben Umgebung, in einer Azure-Remoteregion oder in Azure Blob Storage durchgeführt werden.
Verfügbare Lösungen für die auf Speichermomentaufnahmen basierende anwendungskonsistente Sicherung:
- Das Microsoft-Tool für konsistente Momentaufnahmen in Azure-Anwendungen ist ein Befehlszeilentool, das den Schutz von Daten für Datenbanken von Drittanbietern ermöglicht. Es übernimmt die gesamte Orchestrierung, die erforderlich ist, um die Datenbanken in einen anwendungskonsistenten Zustand zu versetzen, bevor eine Speichermomentaufnahme erstellt wird. Nachdem die Speichermomentaufnahme erstellt wurde, versetzt das Tool die Datenbanken zurück in einen betriebsbereiten Zustand. AzAcSnap unterstützt momentaufnahmenbasierte Sicherungen für HANA (große Instanzen) sowie Azure NetApp Files. Um weitere Informationen zu erhalten, lesen Sie den Artikel Worum handelt es sich beim Tool für konsistente Momentaufnahmen in Azure-Anwendungen?
- Für Benutzer von Commvault-Sicherungsprodukten ist Commvault IntelliSnap V.11.21 und höher eine weitere Option. Diese oder höhere Versionen von Commvault bieten Unterstützung von Momentaufnahmen für Azure NetApp Files. Im Artikel Commvault IntelliSnap 11.21 finden Sie weitere Informationen.
Sichern der Momentaufnahme mit Azure Blob Storage
Die Sicherung in Azure Blob Storage ist eine kostengünstige und schnelle Methode zum Speichern von Momentaufnahmensicherungen auf ANF basierenden HANA-Datenbankspeichers. Zum Speichern der Momentaufnahmen in Azure Blob Storage wird das Tool AzCopy bevorzugt. Laden Sie die neueste Version dieses Tools herunter, und installieren Sie sie z. B. im Verzeichnis „bin“, wo das Python-Skript von GitHub installiert ist. Laden Sie das aktuellste AzCopy-Tool herunter:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
Das fortschrittlichste Feature ist die Option SYNC. Wenn Sie die Option SYNC verwenden, werden Quell- und Zielverzeichnis von azcopy synchronisiert. Die Verwendung des Parameters --delete-destination ist wichtig. Ohne diesen Parameter werden Dateien am Zielstandort von AzCopy nicht gelöscht, und die Speicherplatzauslastung auf der Zielseite würde zunehmen. Erstellen Sie einen Blockblobcontainer in Ihrem Azure-Speicherkonto. Erstellen Sie dann den SAS-Schlüssel für den Blobcontainer, und synchronisieren Sie den Momentaufnahmenordner mit dem Azure Blob-Container.
Dies ist z. B. sinnvoll, wenn eine tägliche Momentaufnahme mit dem Azure-Blobcontainer synchronisiert werden soll, um die Daten zu schützen. Wenn nur eine Momentaufnahme beibehalten werden soll, kann der folgende Befehl verwendet werden.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Nächste Schritte
Lesen Sie diesen Artikel: