SAP HANA-Verfügbarkeit in verschiedenen Azure-Regionen
Dieser Artikel beschreibt Szenarien in Zusammenhang mit der Verfügbarkeit von SAP HANA in verschiedenen Azure-Regionen. Aufgrund der Entfernung zwischen den Azure-Regionen müssen für die Einrichtung der Verfügbarkeit von SAP HANA in mehreren Azure-Regionen besondere Überlegungen angestellt werden.
Gründe für die Bereitstellung in mehreren Azure-Regionen
Azure-Regionen sind oft durch große Entfernungen voneinander getrennt. Abhängig von der geopolitischen Region kann die Entfernung zwischen Azure-Regionen Hunderte von Kilometern oder – wie etwa in den USA – sogar mehrere Tausend Kilometer betragen. Aufgrund der Entfernung treten beim Netzwerkdatenverkehr zwischen Ressourcen, die in zwei verschiedenen Azure-Regionen bereitgestellt sind, eine erhebliche Roundtrip-Netzwerklatenz auf. Diese Latenz ist so erheblich, dass ein synchroner Datenaustausch zwischen zwei SAP HANA-Instanzen bei typischen SAP-Workloads unmöglich ist.
Andererseits besteht in vielen Organisationen die Anforderung, dass zwischen dem primären und dem sekundären Rechenzentrum eine bestimmte Mindestentfernung liegt. Eine solche Anforderung an eine bestimmte Entfernung hilft dabei, die Verfügbarkeit sicherzustellen, wenn in einem größeren geografischen Gebiet eine Naturkatastrophe auftritt. Beispiele hier sind die Orkane, die im September und Oktober 2017 in der Karibik und in Florida große Schäden anrichteten. In Ihrer Organisation ist möglicherweise eine Mindestanforderung an Entfernungen vorhanden. Bei den meisten Azure-Kunden erfordert eine solche definierte Mindestentfernung, dass die Verfügbarkeit über mehrere Azure-Regionen hinweg geplant werden muss. Da die Entfernung zwischen zwei Azure-Regionen zu groß ist, um den synchronen HANA-Replikationsmodus zu verwenden, sind Sie durch die Anforderungen an RTO und RPO möglicherweise gezwungen, Verfügbarkeitskonfigurationen in einer Region bereitzustellen und diese dann um weitere Bereitstellungen in einer zweiten Region zu ergänzen.
Ein weiterer Aspekt, der in einem solchen Szenario zu bedenken ist, betrifft das Failover und die Clientumleitung. Es kann angenommen werden, dass ein Failover zwischen SAP HANA-Instanzen in zwei verschiedenen Azure-Regionen immer manuell erfolgen. Da der Replikationsmodus für die SAP HANA-Systemreplikation auf „asynchron“ festgelegt ist, besteht die Möglichkeit, dass Daten, für die in der primären HANA-Instanz ein Commit ausgeführt wurde, in der sekundären HANA-Instanz noch nicht angekommen sind. Aus diesem Grund ist ein automatisches Failover in Konfigurationen mit asynchroner Replikation keine Option. Selbst bei einem manuell gesteuerten Failover – etwa bei einer Failoverübung – müssen Sie sicherstellen, dass alle Daten, für die im primären Standort ein Commit ausgeführt wurde, die sekundäre Instanz erreicht haben, bevor Sie manuell zur anderen Azure-Region wechseln.
Azure Virtual Network verwendet einen anderen IP-Adressbereich. Die IP-Adressen sind in der zweiten Azure-Region bereitgestellt. Sie müssen also entweder die SAP HANA-Clientkonfiguration ändern oder – vorzugsweise – Schritte einrichten, um die Namensauflösung zu ändern. Auf diese Weise werden die Clients an die IP-Adresse des Servers im neuen sekundären Standort umgeleitet. Weitere Informationen finden Sie im SAP-Artikel Client Connection Recovery after Takeover (Wiederherstellung der Clientverbindung nach einer Übernahme).
Einfache Verfügbarkeit zwischen zwei Azure-Regionen
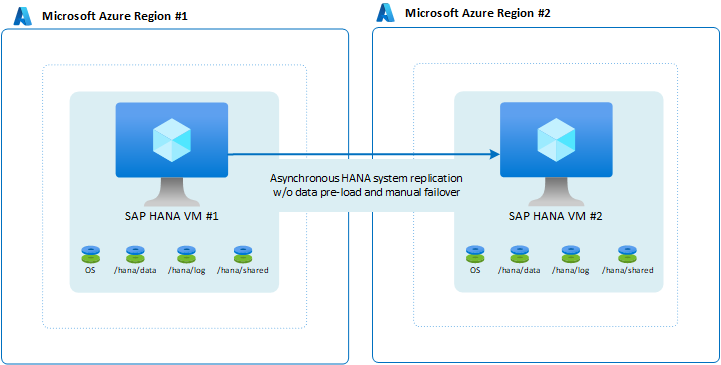
Möglicherweise möchten Sie keine Verfügbarkeitskonfiguration innerhalb einer einzelnen Region einrichten, müssen aber dennoch dafür sorgen, dass die Workloads verarbeitet werden, wenn ein Notfall eintritt. Typische Fälle für solche Szenarios sind Nicht-Produktionssysteme. Hier ist ein Systemausfall für einen halben oder sogar einen ganzen Tag möglicherweise tolerierbar, Sie können aber keinesfalls zulassen, dass das System 48 Stunden oder länger nicht verfügbar ist. Um das Setup kostengünstiger zu gestalten, führen Sie auf dem virtuellen Computer ein weiteres System aus, das weniger wichtig ist. Das andere System fungiert als Ziel. Sie können für den virtuellen Computer in der sekundären Region auch eine kleinere Größe festlegen und entscheiden, dass Daten nicht vorab geladen werden. Da das Failover manuell erfolgt und viele weitere Schritte umfasst, um ein Failover des vollständigen Anwendungsstapels auszuführen, ist die zusätzliche Zeit zum Herunterfahren des virtuellen Computers, zum Ändern der Größe und zum Neustarten des virtuellen Computers akzeptabel.
Wenn in Ihrem Szenario das DR-Ziel mit einem QA-System auf einer VM geteilt wird, müssen Sie die folgenden Aspekte berücksichtigen:
- Mit „delta_datashipping“ und „logreplay“ stehen für ein solches Szenario zwei Betriebsmodi zur Verfügung.
- Für beide Betriebsmodi gelten unterschiedliche Arbeitsspeicheranforderungen ohne das Vorabladen von Daten.
- „Delta_datashipping“ benötigt möglicherweise erheblich weniger Arbeitsspeicher ohne die Option zum Vorabladen als „logreplay“. Weitere Informationen hierzu finden Sie in Kapitel 4.3 des SAP-Dokuments How To Perform System Replication for SAP HANA (Gewusst wie: Durchführen der Systemreplikation für SAP HANA).
- Die Speicheranforderung des Logreplay-Vorgangsmodus ohne Vorladen ist nicht deterministisch und hängt von den geladenen Spaltenspeicherstrukturen ab. In Extremfällen benötigen Sie möglicherweise 50 % des Arbeitsspeichers der primären Instanz. Für den Arbeitsspeicher für den Betriebsmodus „logreplay“ ist es irrelevant, ob Sie die Option zum Vorabladen von Daten ausgewählt haben oder nicht.
Hinweis
In dieser Konfiguration können Sie keine RPO von 0 angeben, da Ihr HANA System im asynchronen Modus repliziert wird. Wenn Sie eine RPO von 0 bereitstellen müssen, ist dies nicht die Konfiguration Ihrer Wahl.
Sie können die Konfiguration geringfügig ändern, indem Sie Daten als vorab ladbar konfigurieren. Angesichts der Tatsache, dass das Failover manuell ausgeführt wird und dass Anwendungsschichten ebenfalls in die zweite Region verlagert werden müssen, ist es jedoch möglicherweise nicht sinnvoll, Daten vorab zu laden.
Kombinieren der Verfügbarkeit innerhalb einer Region und über mehrere Regionen hinweg
Eine Kombination der regionsinternen und regionsübergreifenden Verfügbarkeit kann durch folgende Faktoren motiviert sein:
- Die RPO muss in einer Azure-Region 0 sein.
- In der Organisation ist es nicht gewünscht oder akzeptabel, dass der globale Betrieb durch eine Naturkatastrophe eingeschränkt wird, die eine größere Region betrifft. Dies war der Fall bei den Orkanen, die in den letzten Jahren in der Karibik auftraten.
- Gesetzliche Vorschriften fordern Entfernungen zwischen primären und sekundären Standorten, die eindeutig die Möglichkeiten der Azure-Verfügbarkeitszonen überschreiten.
In diesen Fällen können Sie einrichten, was SAP mit der HANA-Systemreplikationskonfiguration mit mehrfacher Systemreplikation auf SAP HANA aufruft. Die Architektur sieht folgendermaßen aus:
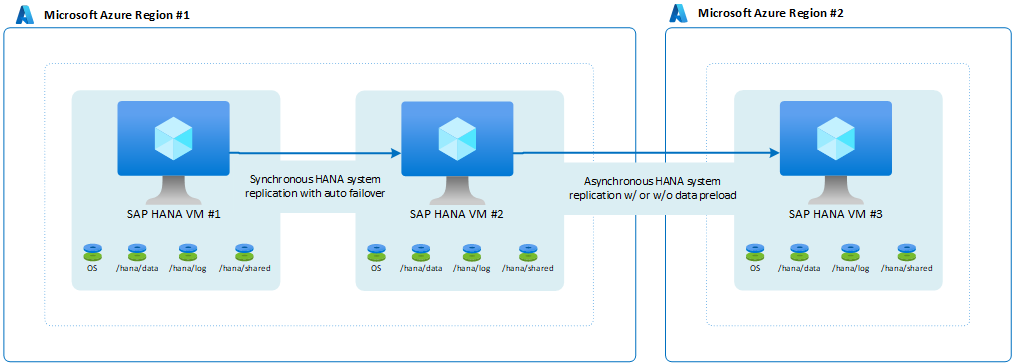
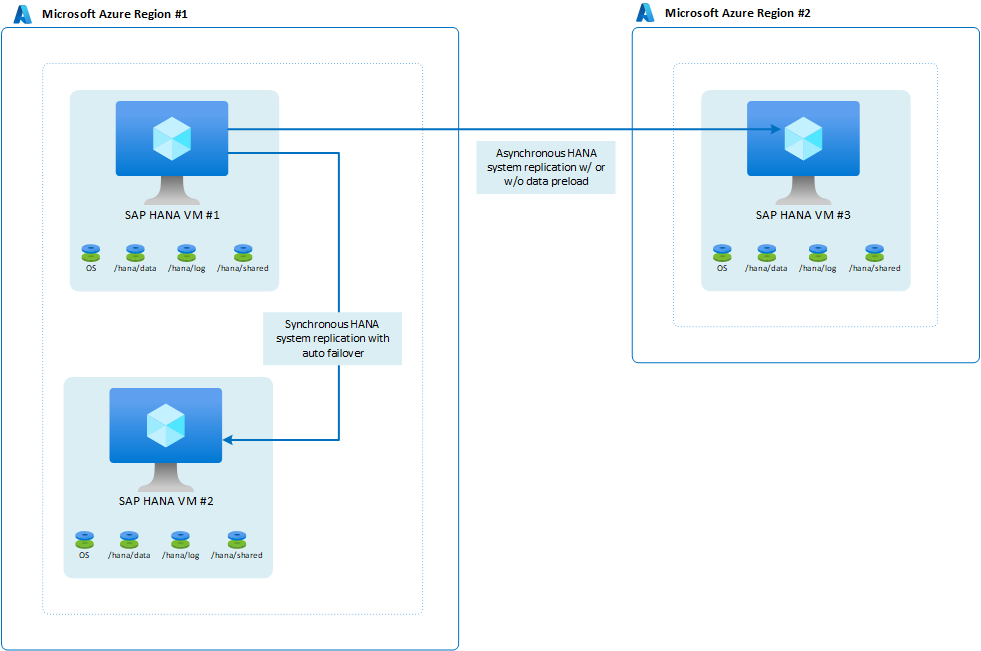
SAP hat mit HANA 2.0 SPS3 die Multi-Target-Systemreplikation eingeführt. Die Multi-Target-Systemreplikation hat einige Vorteile für Updateszenarios. Beispielsweise wird der DR-Standort (Region 2) nicht beeinträchtigt, wenn der sekundäre HA-Standort für Standard Zusenz oder Aktualisierungen deaktiviert ist. Weitere Informationen zur Multi-Target-Systemreplikation von HANA finden Sie im SAP-Hilfeportal. Eine mögliche Architektur mit Multi-Target-Replikation würde folgendermaßen aussehen:
Wenn das Unternehmen Anforderungen an die Hochverfügbarkeit in der zweiten (DR) Azure-Region hat, dann würde die Architektur so aussehen:
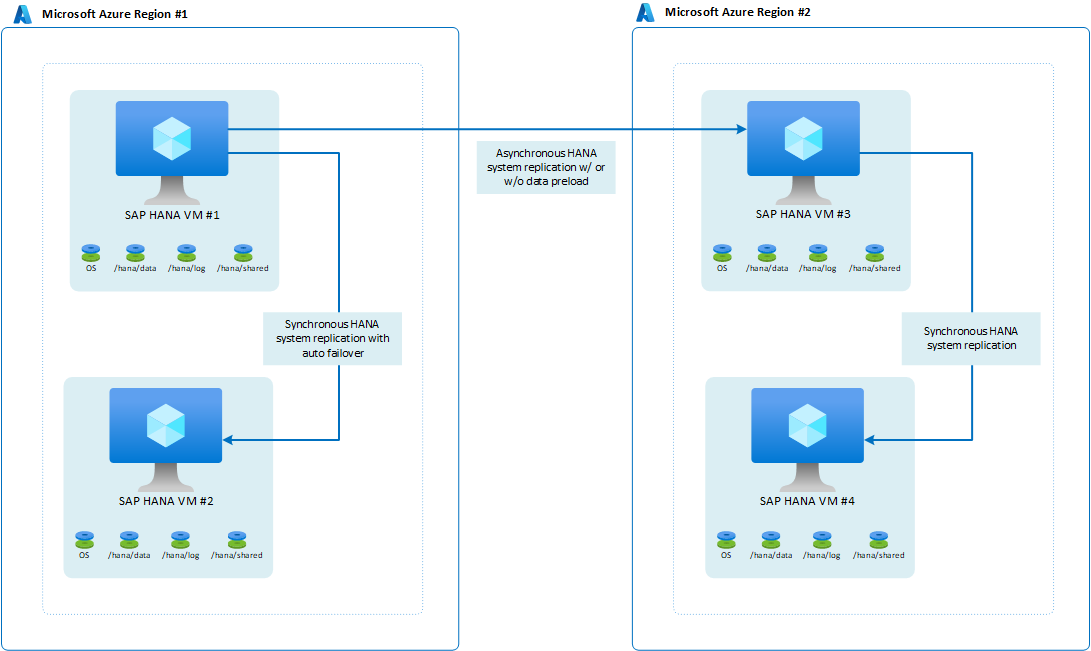
Verwenden von „logreplay“ als Betriebsmodus: Diese Konfiguration stellt in der primären Region einen RPO-Wert von 0 und einen niedrigen RTO-Wert bereit. Die Konfiguration sorgt auch für eine annehmbare RPO, wenn eine Verlagerung in die zweite Region erforderlich ist. Die RTO-Zeiten in der zweiten Region richten sich danach, ob Daten vorab geladen werden. Viele Kunden verwenden den virtuellen Computer in der sekundären Region zum Ausführen eines Testsystems. In diesem Fall können die Daten nicht vorab geladen werden.
Wichtig
Die Betriebsmodi zwischen den verschiedenen Ebenen müssen homogen sein. Sie können die Protokollwiedergabe nicht als Betriebsmodus zwischen Ebene 1 und Ebene 2 und delta_datashipping verwenden, um Stufe 3 anzugeben. Sie können jeweils nur einen Betriebsmodus auswählen, der für alle Ebenen einheitlich sein muss. Da „delta_datashipping“ nicht für einen RPO-Wert von 0 geeignet ist, bleibt „logreplay“ der einzige angemessene Betriebsmodus für eine solche Konfiguration mit mehreren Ebenen. Details zu Betriebsmodi und einigen Einschränkungen finden Sie im SAP-Artikel Operation Modes for SAP HANA System Replication (Betriebsmodi für die SAP HANA Systemreplikation).
Nächste Schritte
Eine ausführliche Anleitung zum Einrichten dieser Konfigurationen in Azure finden Sie in folgenden Artikeln:
- Hochverfügbarkeit von SAP HANA auf virtuellen Azure-Computern (VMs)
- Your SAP on Azure – Part 4 – High Availability for SAP HANA using System Replication (SAP in Azure – Teil 4: Hochverfügbarkeit für SAP HANA durch Systemreplikation)