Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In Azure KI-Suche ist der semantische Sortierer ein Feature, das die Suchrelevanz durch die Verwendung der Language Understanding-Modelle von Microsoft verbessert, um Suchergebnisse neu zu bewerten. Der semantische Ranker ist auch in den agentischen Abruf integriert. Dieser Artikel enthält eine allgemeine Einführung in das Verhalten und die Vorteile des semantischen Sortierers.
Der semantische Rangierer ist ein Premium-Feature, das von der Nutzung abgerechnet wird, aber Sie können es kostenlos verwenden, vorbehaltlich der Dienstbeschränkungen für die kostenlose Stufe. Es wird empfohlen, diesen Artikel zu lesen, um Hintergrundinformationen zu erhalten. Falls Sie aber direkt loslegen möchten, können Sie die hier angegebenen Schritte ausführen.
Was ist die semantische Rangfolge?
Semantic Ranker ist eine Sammlung von Funktionen auf der Abfrageseite, die die Qualität eines anfänglichen BM25-bewerteten oder RRF-bewerteten Suchergebnisses für textbasierte Abfragen, den Textanteil von Vektor- und Hybridabfragen verbessert. Die semantische Rangfolge erweitert die Abfrageausführungspipeline auf drei Arten:
Zuerst wird immer eine sekundäre Rangfolge für ein anfängliches Resultset hinzugefügt, das mit BM25 oder RRF (Reciprocal Rank Fusion) bewertet wurde. Diese sekundäre Rangfolge verwendet mehrsprachige, deep learning-Modelle, die von Microsoft Bing angepasst wurden, um die semantisch relevantesten Ergebnisse zu fördern.
Zweitens werden Beschriftungen zurückgegeben und optional Antworten in der Antwort extrahiert, die Sie auf einer Suchseite rendern können, um die Sucherfahrung des Benutzers zu verbessern.
Drittens, wenn Sie die Abfrageumschreibung aktivieren, wird eine anfängliche Abfragezeichenfolge in mehrere semantisch ähnliche Abfragezeichenfolgen erweitert.
Sekundäre Rangfolge und "Antworten" gelten für die Abfrageantwort. Die Abfrageumschreibung ist Teil der Abfrageanforderung.
Hier sind die Funktionen des semantischen Neusortierers.
| Capability | Description |
|---|---|
| L2-Rangfolge | Verwendet den Kontext oder die semantische Bedeutung einer Abfrage, um einen neuen Relevanzbewertung für vorab bewertete Ergebnisse zu berechnen. |
| Semantische Titel und Markierungen | Extrahiert Sätze und Ausdrücke wortgetreu aus Feldern, die den Inhalt am besten zusammenfassen, und hebt wichtige Passagen zum einfachen Überfliegen hervor. Beschriftungen, die ein Ergebnis zusammenfassen, sind nützlich, wenn einzelne Inhaltsfelder für die Suchergebnisseite zu dicht sind. Der markierte Text hebt die relevantesten Begriffe und Ausdrücke hervor, sodass Benutzer schnell ermitteln können, warum eine Entsprechung als relevant eingestuft wurde. |
| Semantische Antworten | Eine optionale und zusätzliche Unterstruktur, die von einer Semantikabfrage zurückgegeben wird. Sie bietet eine direkte Antwort auf eine Abfrage, die wie eine Frage aussieht. Ein Dokument muss Text mit den Merkmalen einer Antwort enthalten. |
| Abfrageumschreibung | Mithilfe von Textabfragen oder dem Textteil einer Vektorabfrage erstellt der semantische Rangierer bis zu 10 Varianten der Abfrage, z. B. Korrigieren von Tippfehlern oder Rechtschreibfehlern oder das Rephrasieren einer Abfrage mithilfe generierter Synonyme. Die umgeschriebene Abfrage wird auf der Suchmaschine ausgeführt. Die Ergebnisse werden mithilfe der BM25- oder RRF-Bewertung bewertet und dann vom semantischen Rangierer rescoret. |
Funktionsweise des semantischen Sortierers
Der semantische Rangierer akzeptiert eine Abfrage und Ergebnisse und sendet sie dann an von Microsoft gehostete Sprachverständnismodelle. Es scannt nach besseren Übereinstimmungen.
In der folgenden Abbildung wird das Konzept erläutert. Nehmen wir den englischen Begriff „capital“. Er hat unterschiedliche Bedeutungen – je nachdem, ob er im Zusammenhang mit Finanzen, Recht, Geographie oder Grammatik verwendet wird. Durch das Sprachverständnis erkennt der semantische Rangierer Kontext und fördert Ergebnisse, die der Abfrageabsicht entsprechen.
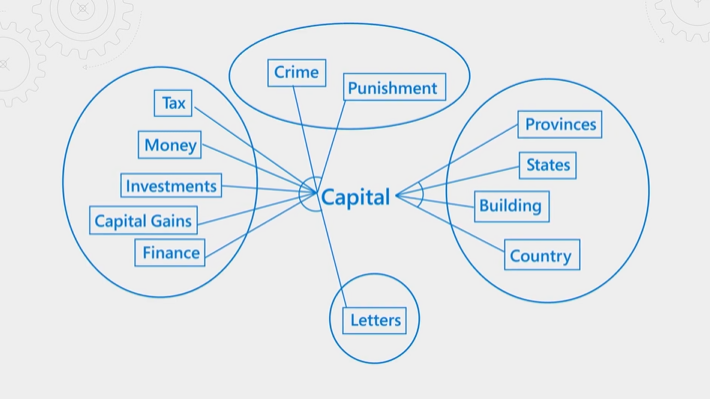
Die semantische Rangfolge verwendet viele Ressourcen und Zeit. Um die Verarbeitung innerhalb der erwarteten Latenz eines Abfragevorgangs abzuschließen, konsolidiert und reduziert das System Eingaben für den semantischen Rangierer. Dieser Ansatz hilft, den Reranking-Schritt so schnell wie möglich abzuschließen.
Die semantische Rangfolge umfasst drei Schritte:
- Sammeln und Zusammenfassen von Eingaben
- Bewertungsergebnisse mithilfe des semantischen Rangierers
- Ausgeben neu bewerteter Ergebnisse, Beschriftungen und Antworten
Wie das System Eingaben erfasst und zusammenfasst
Bei der semantischen Rangfolge übergibt das Abfragesubsystem Suchergebnisse als Eingabe an Zusammenfassungs- und Bewertungsmodelle. Da die Eingabegrößen von Bewertungsmodellen eingeschränkt und die Modelle rechenintensiv sind, müssen Suchergebnisse für eine effiziente Handhabung dimensioniert und strukturiert (zusammengefasst) werden.
Der semantische Rang beginnt mit einem BM25-bewerteten Ergebnis aus einer Textabfrage oder einem RRF-bewerteten Ergebnis aus einem Vektor oder einer Hybridabfrage. Die Reranking-Übung verwendet nur Text. Selbst wenn die Ergebnisse mehr als 50 umfassen, werden nur die besten 50 Ergebnisse für das semantische Ranking herangezogen. In der Regel verwendet semantische Rangfolge informations- und beschreibende Felder.
Für jedes Dokument im Suchergebnis akzeptiert das Zusammenfassungsmodell bis zu 2.000 Token, wobei ein Token etwa zehn Zeichen umfasst. Das Modell fasst Eingaben aus den Feldern "title", "keyword" und "content" zusammen, die in der semantischen Konfiguration aufgeführt sind.
Das System schneidet übermäßig lange Zeichenfolgen ab, um sicherzustellen, dass die Gesamtlänge den Eingabeanforderungen des Zusammenfassungsschritts entspricht. Aus diesem Grund ist es wichtig, Ihrer semantischen Konfiguration Felder in Prioritätsreihenfolge hinzuzufügen. Wenn Sie sehr große Dokumente mit textlastigen Feldern haben, ignoriert das System alles nach dem maximalen Grenzwert.
Bedeutungsfeld Tokengrenzwert "title" 128 Token "keywords 128 Token "content" verbleibende Token Die Zusammenfassungsausgabe ist eine Zusammenfassungszeichenfolge für jedes Dokument, bestehend aus den relevantesten Informationen aus jedem Feld. Das System sendet Zusammenfassungszeichenfolgen für die Bewertung an den Rangierer und an Computerlesemodelle für Beschriftungen und Antworten.
Jede generierte Zusammenfassungszeichenfolge, die an den semantischen Bewerter übergeben wird, darf ab November 2024 maximal 2.048 Token lang sein. Zuvor waren es 256 Token.
Wie Ergebnisse bewertet werden
Das System bewertet die Ergebnisse anhand der Bildunterschrift und aller anderen Inhalte aus der Zusammenfassungszeichenfolge, die die Länge von 2.048 Token ausfüllen.
Das System wertet Beschriftungen für die konzeptionelle und semantische Relevanz relativ zur von Ihnen bereitgestellten Abfrage aus.
Das System weist jedem Dokument basierend auf der semantischen Relevanz des Dokuments für die angegebene Abfrage einen @search.rerankerScore zu. Die Bewertungen liegen zwischen 4 und 0 (hoch bis niedrig), wobei eine höhere Bewertung eine größere Relevanz darstellt.
Score Meaning 4.0 Das Dokument ist hochrelevant und beantwortet die Frage vollständig, die Passage enthält jedoch möglicherweise zusätzlichen Text, der nichts mit der Frage zu tun hat. 3.0 Das Dokument ist relevant, aber es fehlen Details, die es vollständig machen würden. 2.0 Das Dokument ist ein bisschen relevant. Es beantwortet die Frage entweder teilweise oder nur einige Aspekte der Frage. 1.0 Das Dokument hängt mit der Frage zusammen und beantwortet einen kleinen Teil davon. 0.0 Das Dokument ist irrelevant. Das System listet Übereinstimmungen nach Wertung in absteigender Reihenfolge auf und schließt sie in die Nutzlast der Abfrageantwort ein. Die Nutzlast umfasst Antworten, nur-Text und markierte Beschriftungen sowie alle Felder, die Sie als abrufbar markiert oder in einer Select-Klausel angegeben haben.
Note
Bei jeder Abfrage können die Verteilungen von @search.rerankerScore aufgrund von Bedingungen auf Infrastrukturebene geringfügige Abweichungen aufweisen. Aktualisierungen des Bewertungsmodells können sich auch auf die Verteilung auswirken. Wenn Sie aus diesen Gründen benutzerdefinierten Code für Mindestschwellenwerte schreiben oder die Schwellenwerteigenschaft für Vektor- und Hybridabfragen festlegen, machen Sie die Grenzwerte nicht zu granular.
Ausgaben des semantischen Sortierers
Anhand der einzelnen Zusammenfassungszeichenfolgen suchen die Modelle für maschinelles Leseverständnis nach den repräsentativsten Passagen.
Die Ergebnisse sind:
Eine semantische Beschriftung für das Dokument. Jede Beschriftung ist in einer reinen Textversion und einer Highlight-Version verfügbar und umfasst häufig weniger als 200 Wörter pro Dokument.
Eine optionale semantischen Antwort, sofern Sie den Parameter
answersangegeben haben, die Abfrage als Frage gestellt wurde und in der langen Zeichenfolge eine Passage gefunden wurde, die eine wahrscheinliche Antwort auf die Frage darstellt.
Bei Beschriftungen und Antworten handelt es sich immer um wortgetreuen Text aus Ihrem Index. In diesem Workflow gibt es kein generatives KI-Modell, das neue Inhalte erstellt oder erstellt.
Semantische Funktionen und Einschränkungen
Was der semantische Rangierer tun kann :
Höherstufen von Übereinstimmungen, die semantisch näher an der Absicht der ursprünglichen Abfrage liegen.
Finden von Zeichenfolgen, die als Beschriftungen und Antworten verwendet werden können. Die Antwort gibt Beschriftungen und Antworten zurück, die Sie auf einer Suchergebnisseite rendern können.
Der semantische Sortierer kann eine Abfrage nicht erneut für den gesamten Korpus ausführen, um semantisch relevante Ergebnisse zu finden. Die semantische Rangfolge bewertet das vorhandene Resultset neu, das aus den 50 besten Ergebnissen besteht, die vom Standardalgorithmus für die Rangfolge ermittelt wurden. Darüber hinaus kann der semantische Sortierer keine neuen Informationen oder Zeichenfolgen erstellen. Die Sprachmodelle extrahieren Beschriftungen und Antworten wortwörtlich aus Ihren Inhalten. Wenn die Ergebnisse also keine antwortähnlichen Texte enthalten, erzeugen sie auch keinen.
Die semantische Rangfolge ist zwar nicht in jedem Szenario von Vorteil, bestimmte Inhalte können jedoch erheblich von ihren Funktionen profitieren. Die Sprachmodelle im semantischen Sortierer eignen sich am besten für durchsuchbare Inhalte, die viele Informationen enthalten und in offener Textform strukturiert sind. Für Wissensdatenbanken, Onlinedokumentationen oder Dokumente, die beschreibende Inhalte enthalten, bieten die Funktionen des semantischen Sortierers die meisten Vorteile.
Die zugrunde liegende Technologie stammt von Bing und Microsoft Research und ist als Add-On-Feature in die Infrastruktur von Azure KI Search integriert. Weitere Informationen zu den Forschungs- und KI-Investitionen, die dem semantischen Sortierer zugrunde liegen, finden Sie im Microsoft Research Blog How AI from Bing is powering Azure KI-Suche (Wie Azure KI-Suche durch KI von Bing unterstützt wird).
Im folgenden Video erhalten Sie eine Übersicht zu den Funktionen.
Verwendung von Synonymzuordnungen durch semantischen Rangierer
Wenn Sie die Unterstützung für Synonymzuordnungen aktivieren, die einem Feld in Ihrem Suchindex zugeordnet sind, und dieses Feld in die Semantikbewertungskonfiguration einschließen, wendet der semantische Rangfolger automatisch die konfigurierten Synonyme während des Reranking-Prozesses an.
Verfügbarkeit und Preismodell
Der semantische Rangierer ist in ausgewählten Regionen verfügbar. Verwenden Sie es als eigenständiges Feature und als integrierte Komponente des agentischen Abrufs.
Sie können Ihren semantischen Ranker für Ihren Suchdienst deaktivieren, ihn kostenlos begrenzt verwenden oder mit Abrechnung nach Verbrauch umfangreicher nutzen.
| Plan | Description |
|---|---|
| Kostenlos | Ein Suchdienst für den Free-Tarif stellt 1.000 Anforderungen an den semantischen Sortierer pro Monat und 50 Millionen kostenlose Token für die agentische Begründung pro Monat bereit. Höhere Stufen können auch den kostenlosen Plan verwenden. |
| Norm | Der Standardplan ist pay-as-you-go-Preise, sobald das monatliche kostenlose Kontingent verbraucht wird. Nach den ersten 1.000 Anforderungen für semantische Rangfolger zahlen Sie für jede zusätzliche 1.000 Anforderungen. Nach den ersten 50 Millionen Agentic Reasoning Tokens pro Monat zahlen Sie eine geringe Gebühr für jede weitere Million Agentic Reasoning Tokens. Der Übergang von Free zu Standard ist nahtlos. Sie werden nicht benachrichtigt, wenn der Übergang eintritt. Weitere Informationen zu Gebühren nach Währung finden Sie auf der Azure KI-Suche-Preisseite. |
Auf der Preisseite zu Azure KI Search finden Sie die Abrechnungsrate für verschiedene Währungen und Intervalle.
Gebühren für den semantischen Ranking-Algorithmus fallen an, wenn Suchanfragen queryType=semantic enthalten und die Suchzeichenfolge nicht leer ist (z. B. search=pet friendly hotels in New York). Wenn Ihre Suchzeichenfolge leer ist (search=*), werden Ihnen auch dann keine Gebühren berechnet, wenn „queryType“ auf „semantic“ festgelegt ist.
Erste Schritte mit dem semantischen Sortierer
Konfigurieren Sie den semantischen Rangfolger für den Suchdienst, und wählen Sie einen Preisplan aus. Der kostenlose Plan ist die Standardeinstellung.
Konfigurieren Sie den semantischen Sortierer in einem Suchindex.
Richten Sie Abfragen zum Zurückgeben semantischer Beschriftungen und Hervorhebungen ein.