Partitionieren von Service Fabric Reliable Services
Dieser Artikel enthält eine Einführung in die grundlegenden Konzepte der Partitionierung von Azure Service Fabric Reliable Services. Die Partitionierung ermöglicht die Datenspeicherung auf lokalen Computern, sodass Daten und Computeressourcen zusammen skaliert werden können.
Tipp
Der vollständige Beispielcode des in diesem Artikel verwendeten Codes ist auf GitHub verfügbar.
Partitionierung
Die Partitionierung ist nicht nur auf Service Fabric beschränkt. Tatsächlich ist sie ein grundlegendes Muster beim Erstellen von skalierbaren Diensten. In einem weiteren Sinne können wir uns die Partitionierung als ein Konzept vorstellen, bei dem der Zustand (Daten) und die Berechnung (Compute) in kleinere zugängliche Einheiten unterteilt werden, um die Skalierbarkeit und Leistung zu verbessern. Eine bekannte Form der Partitionierung ist die Datenpartitionierung, die auch als Sharding bezeichnet wird.
Partitionieren von zustandslosen Service Fabric-Diensten
Bei zustandslosen Diensten können Sie sich eine Partition als eine logische Einheit vorstellen, die mindestens eine Instanz eines Diensts enthält. Abbildung 1 zeigt einen zustandslosen Dienst mit fünf Instanzen, die mit einer Partition auf einen Cluster verteilt sind.
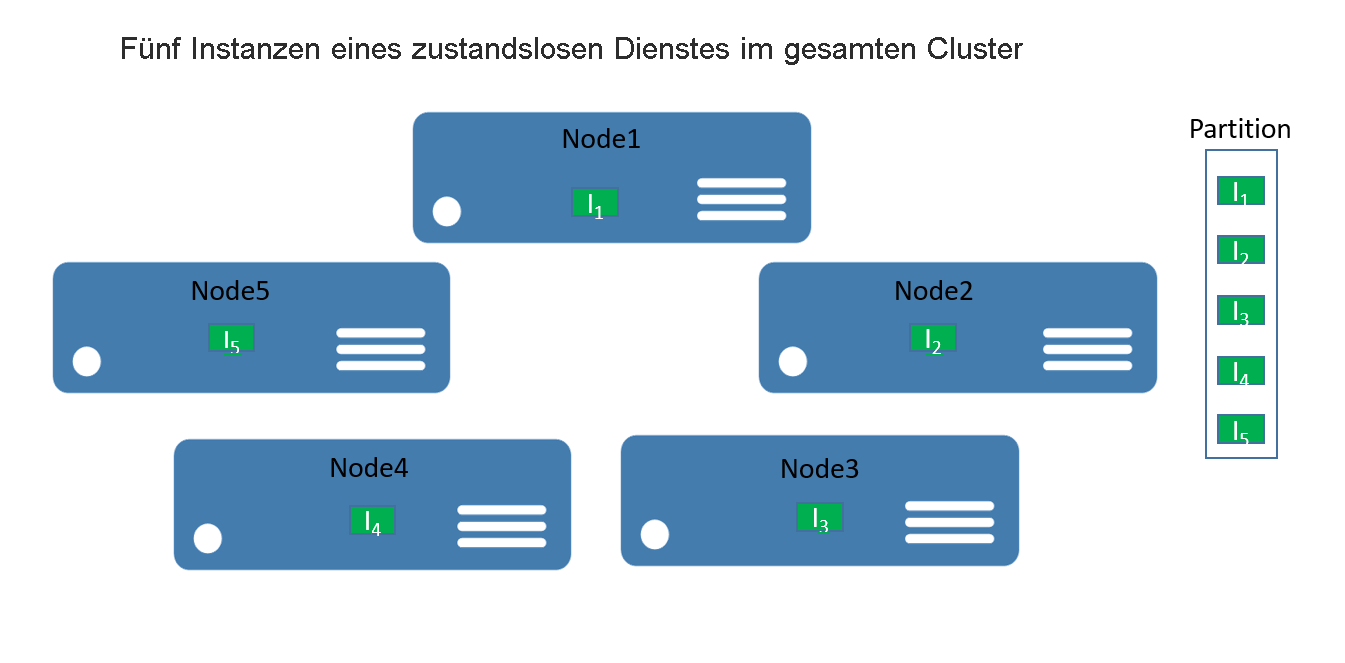
Es gibt im Grunde zwei Arten von Lösungen für zustandslose Dienste. Die erste ist ein Dienst, für den der Zustand extern beibehalten wird, z. B. in einer Datenbank in Azure SQL-Datenbank (etwa eine Website, auf der die Sitzungsinformationen und Daten gespeichert sind). Die zweite umfasst Dienste, die ausschließlich für die Berechnung bestimmt sind (etwa ein Rechner oder Bildminiaturansichten) und keinen beständigen Zustand verwalten.
In beiden Fällen ist das Partitionieren eines zustandslosen Diensts ein sehr seltenes Szenario, und die Skalierbarkeit und Verfügbarkeit werden normalerweise erreicht, indem weitere Instanzen hinzugefügt werden. Sie sollten die Verwendung mehrerer Partitionen für zustandslose Dienstinstanzen nur erwägen, wenn Sie spezielle Routinganforderungen erfüllen müssen.
Stellen Sie sich beispielsweise einen Fall vor, in dem für Benutzer mit IDs in einem bestimmten Bereich nur eine bestimmte Dienstinstanz verwendet werden sollen. Ein weiteres Beispiel für die mögliche Partitionierung eines zustandslosen Diensts ist, wenn Sie ein Back-End mit echter Partitionierung verwenden, z. B. eine Datenbank in SQL-Datenbank mit Sharding. Sie möchten steuern, welche Dienstinstanz in den Datenbankshard schreiben soll, oder andere Vorbereitungsschritte im zustandslosen Dienst ausführen, für die die gleichen Partitionierungsinformationen wie im Back-End benötigt werden. Diese Arten von Szenarios können auch auf unterschiedliche Arten gelöst werden, und eine Dienstpartitionierung ist nicht unbedingt erforderlich.
Im restlichen Teil dieser Vorgehensweise geht es um zustandsbehaftete Dienste.
Partitionieren von zustandsbehafteten Service Fabric-Diensten
Mit Service Fabric ist es einfach, skalierbare zustandsbehaftete Dienste zu entwickeln, indem ein erstklassiger Weg zum Partitionszustand (Daten) angeboten wird. Vom Konzept her können Sie sich eine Partition eines zustandsbehafteten Diensts als Skalierungseinheit vorstellen, die aufgrund von Replikaten hohe Verfügbarkeit bietet. Die Replikate sind gleichmäßig auf die Knoten in einem Cluster verteilt.
Die Partitionierung im Kontext von zustandsbehafteten Service Fabric-Diensten bezieht sich auf den Prozess der Ermittlung, ob eine bestimmte Dienstpartition für einen Teil des vollständigen Zustands des Diensts zuständig ist. (Wie bereits erwähnt, ist eine Partition ein Satz von Replikaten). Der Vorteil von Service Fabric ist, dass die Partitionen auf unterschiedlichen Knoten angeordnet werden. Dadurch können sie bis zum Ressourcenlimit eines Knotens anwachsen. Wenn die Daten zunehmen müssen, werden die Partitionen vergrößert, und Service Fabric verteilt die Partitionen neu über die Knoten. Dadurch wird die fortgesetzte effiziente Nutzung von Hardwareressourcen sichergestellt.
Beispiel: Sie beginnen mit einem Cluster mit fünf Knoten und einem Dienst, der für zehn Partitionen und einem Ziel von drei Replikaten konfiguriert ist. In diesem Fall verteilt Service Fabric die Replikate gleichmäßig im Cluster, und es werden zwei primäre Replikate pro Knoten verwendet. Wenn Sie den Cluster nun auf zehn Knoten aufskalieren müssen, verteilt Service Fabric die primären Replikate neu auf alle zehn Knoten. Falls Sie wieder auf fünf Knoten herunterskalieren, verteilt Service Fabric alle Replikate neu auf die fünf Knoten.
Abbildung 2 zeigt die Verteilung von zehn Partitionen vor und nach dem Skalieren des Clusters.
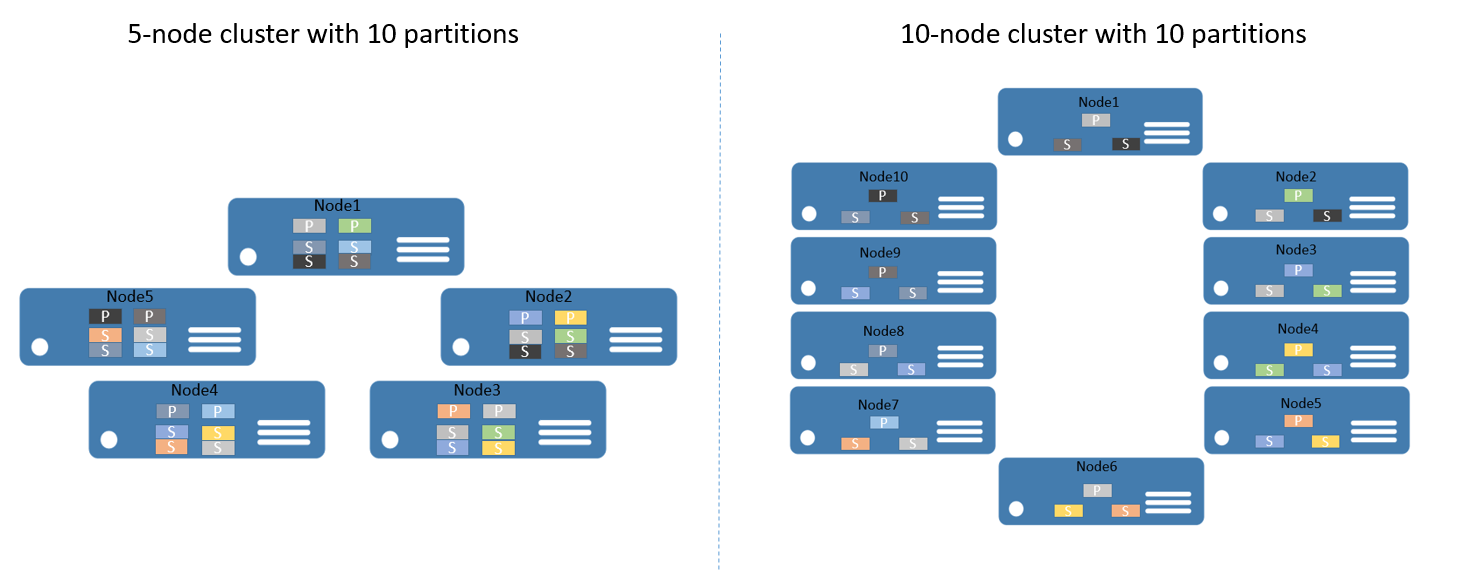
Das horizontale Hochskalieren wird erreicht, da Anforderungen von Clients über die Computer hinweg verteilt werden, die Gesamtleistung der Anwendung verbessert wird und Konflikte beim Zugreifen auf Datenblöcke verringert werden.
Planen der Partitionierung
Vor der Implementierung eines Diensts sollten Sie immer die Partitionierungsstrategie bedenken, die für das Aufskalieren erforderlich ist. Es gibt unterschiedliche Ansätze, bei denen aber immer die Frage im Mittelpunkt steht, was mit der Anwendung erreicht werden soll. Im Rahmen dieses Artikels betrachten wir einige der wichtigeren Aspekte.
Ein guter Ansatz besteht darin, sich als ersten Schritt die Struktur des Zustands anzusehen, der partitioniert werden soll.
Wir sehen uns ein einfaches Beispiel an. Wenn Sie einen Dienst für eine bezirksweite Umfrage erstellen, könnten Sie eine Partition für jede Stadt im Bezirk erstellen. Anschließend könnten Sie die Stimmabgaben für jede Person in der Stadt in der Partition speichern, die zu dieser Stadt gehört. Abbildung 3 zeigt eine Gruppe von Personen und den Ort, in dem sie wohnen.
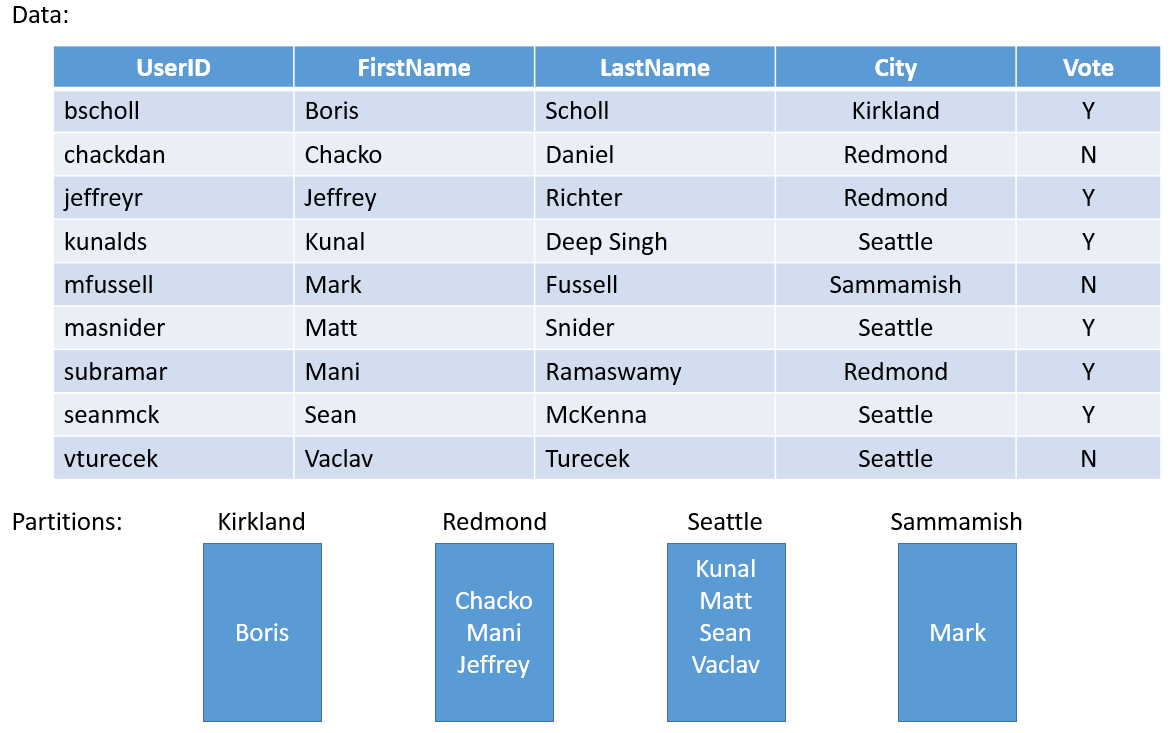
Da die Einwohnerzahl der Orte stark variiert, verfügen Sie über einige Partitionen mit vielen Daten (z. B. Seattle) und andere Partitionen mit sehr wenigen Zuständen (z. B. Kirkland). Welche Auswirkungen hat es, wenn Partitionen mit ungleichen Zustandsmengen verwendet werden?
Wenn Sie sich das Beispiel erneut ansehen, fällt Ihnen auf, dass die Partition mit den Stimmabgaben für Seattle mehr Datenverkehr als die Partition für Kirkland aufweist. Standardmäßig stellt Service Fabric sicher, dass etwa die gleiche Anzahl von primären und sekundären Replikaten auf jedem Knoten vorhanden ist. So könnten Sie am Ende über Knoten mit Replikaten verfügen, die mehr Datenverkehr verarbeiten, und andere, die weniger Datenverkehr verarbeiten. Nach Möglichkeit sollten Sie „Hotspots“ und „Coldspots“ dieser Art in einem Cluster vermeiden.
Dazu sollten Sie aus Sicht der Partitionierung zwei Dinge tun:
- Versuchen Sie, den Zustand so zu partitionieren, dass er gleichmäßig auf alle Partitionen verteilt ist.
- Verfolgen Sie die Auslastung für alle Replikate für den Dienst. (Informationen zur Vorgehensweise finden Sie in diesem Artikel unter Metriken und Auslastung). Service Fabric enthält eine Funktion zum Melden der von einem Dienst verbrauchten Auslastungen, z. B. die Arbeitsspeichermenge oder die Anzahl von Datensätzen. Anhand der gemeldeten Metriken erkennt Service Fabric, dass einige Partitionen eine höhere Auslastung als andere Partitionen aufweisen. Es wird eine neue Verteilung für den Cluster durchgeführt, indem Replikate auf besser geeignete Knoten verschoben werden, sodass insgesamt kein Knoten überlastet ist.
Es kann vorkommen, dass Sie nicht wissen, wie viele Daten sich auf einer bestimmten Partition befinden. Also lautet die allgemeine Empfehlung, zweigleisig zu fahren: Verwenden einer Partitionierungsstrategie, bei der die Daten gleichmäßig auf die Partitionen verteilt werden, und Melden der Auslastung. Mit der ersten Methode werden Situationen verhindert, die im Beispiel mit der Umfrage beschrieben sind, und mit der zweiten Methode werden vorübergehende Unterschiede beim Zugriff oder der Auslastung in Abhängigkeit der Zeit ausgeglichen.
Ein weiterer Aspekt der Partitionsplanung ist das Wählen der richtigen Anzahl von Partitionen zu Beginn der Planungsphase. Aus Sicht von Service Fabric spricht nichts dagegen, mit einer höheren Anzahl von Partitionen zu beginnen, als Sie für Ihr Szenario erwarten. Es ist ein guter Ansatz, eine Annahme über die maximale Anzahl von Partitionen zu treffen.
In seltenen Fällen kann es vorkommen, dass Sie mehr Partitionen benötigen, als Sie zu Anfang gewählt haben. Da Sie die Partitionsanzahl später nicht mehr ändern können, müssen Sie andere Partitionsansätze anwenden, z. B. das Erstellen einer neuen Dienstinstanz desselben Diensttyps. Sie müssen zudem eine clientseitige Logik implementieren, mit der die Anforderungen basierend auf clientseitigen Informationen, die von Ihrem Clientcode verwaltet werden müssen, an die richtige Dienstinstanz geleitet werden.
Auch die verfügbaren Computerressourcen müssen bei der Partitionierungsplanung berücksichtigt werden. Da auf den Zustand zugegriffen und der Zustand gespeichert werden muss, sind Sie an Folgendes gebunden:
- Einschränkungen der Netzwerkbandbreite
- Einschränkungen des Systemarbeitsspeichers
- Einschränkungen des Speicherplatzes
Was passiert, wenn es auf einem ausgeführten Cluster zu Ressourceneinschränkungen kommt? Die Antwort lautet, dass Sie den Cluster einfach aufskalieren können, um die neuen Anforderungen abzudecken.
Leitfaden zur Kapazitätsplanung enthält eine Anleitung, wie Sie ermitteln, wie viele Knoten für Ihren Cluster benötigt werden.
Erste Schritte mit der Partitionierung
In diesem Abschnitt wird beschrieben, wie Sie mit der Partitionierung Ihres Diensts beginnen.
Service Fabric bietet drei Partitionsschemas:
- Bereichsbasierte Partitionierung (wird auch als UniformInt64Partition bezeichnet)
- Namensbasierte Partitionierung: Anwendungen, für die dieses Modell verwendet wird, verfügen normalerweise über Daten, für die Buckets genutzt werden können (in einem gebundenen Satz). Einige allgemeine Beispiele für Datenfelder, die als Schlüssel für namensbasierte Partitionen verwendet werden, sind Regionen, Postleitzahlen, Kundengruppen oder andere geschäftliche Grenzen.
- Singleton-Partitionierung: Singleton-Partitionen werden normalerweise verwendet, wenn für den Dienst kein zusätzliches Routing benötigt wird. Für zustandslose Dienste wird dieses Partitionierungsschema beispielsweise standardmäßig verwendet.
Bei namensbasierten und Singleton-Partitionierungsschemas handelt es sich um besondere Formen von bereichsbasierten Partitionen. Standardmäßig wird für Visual Studio-Vorlagen für Service Fabric die bereichsbasierte Partitionierung verwendet, da dies die häufigste und nützlichste Partitionierung ist. Im restlichen Teil dieses Artikels geht es um das bereichsbasierte Partitionierungsschema.
Bereichsbasiertes Partitionierungsschema
Dieses Schema wird verwendet, um einen ganzzahligen Bereich (identifiziert durch einen niedrigen und einen hohen Schlüssel) und eine Anzahl von Partitionen (n) anzugeben. Es werden „n“ Partitionen erstellt, die jeweils für einen nicht überlappenden Unterbereich des gesamten Partitionsschlüsselbereichs zuständig sind. Beispiel: Ein bereichsbasiertes Partitionierungsschema mit einem niedrigen Schlüssel 0, einem hohen Schlüssel 99 und einer Anzahl von 4 erstellt vier Partitionen. Dies ist unten dargestellt.
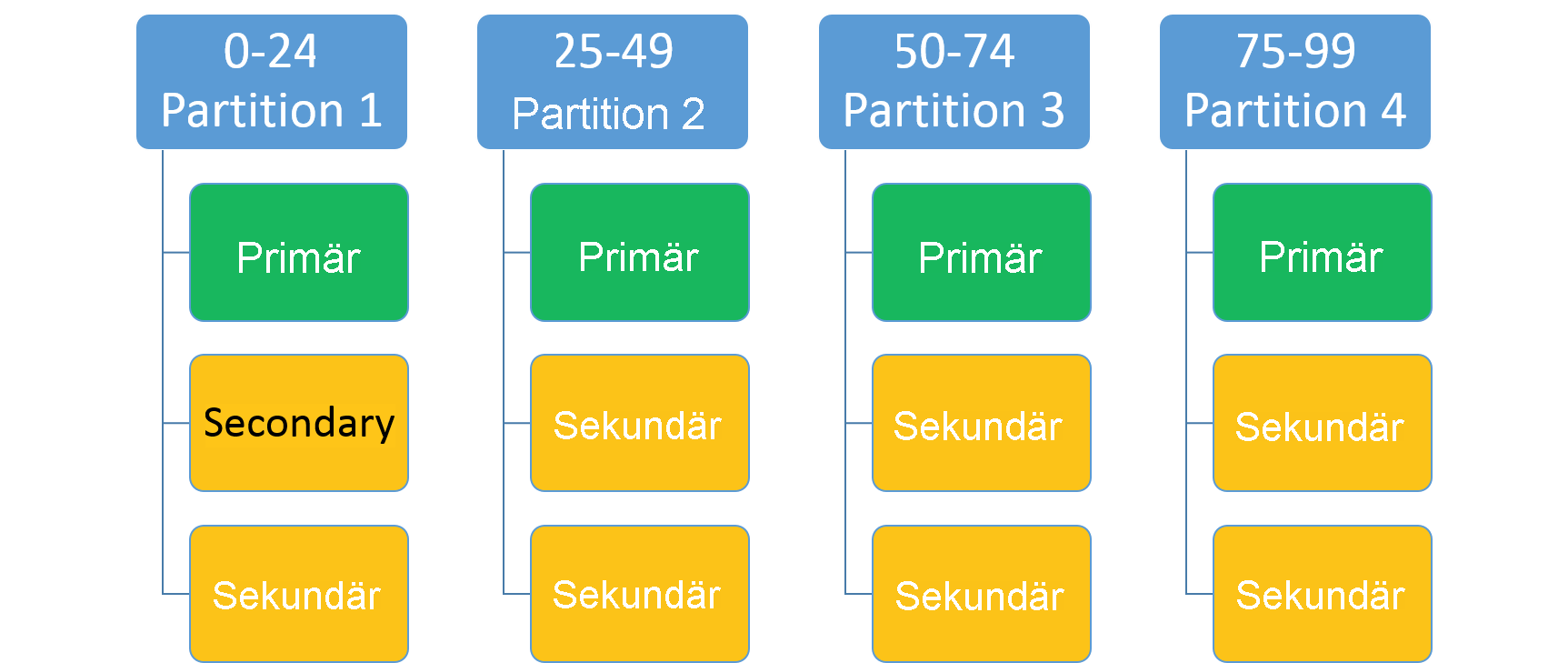
Ein gängiger Ansatz besteht darin, im Dataset einen Hashwert basierend auf einem eindeutigen Schlüssel zu erstellen. Ein Schlüssel kann beispielsweise eine Fahrgestellnummer, eine Mitarbeiter-ID oder eine eindeutige Zeichenfolge sein. Mit diesem eindeutigen Schlüssel generieren Sie dann einen Hashcode (Modulvorgang zum Berechnen des Schlüsselbereichs), den Sie als Ihren Schlüssel verwenden. Sie können den oberen und unteren Grenzwert des zulässigen Schlüsselbereichs angeben.
Auswählen eines Hashalgorithmus
Beim Hashing spielt die Wahl des Hashalgorithmus eine wichtige Rolle. Ausschlaggebend ist, ob ähnliche nah beieinanderliegende Schlüssel gruppiert werden sollen (lokalitätsbasiertes Hashing) oder ob die Aktivität über alle Partitionen weitläufig verteilt werden soll (verteiltes Hashing). Letzteres wird häufiger verwendet.
Die Merkmale eines guten Hashalgorithmus für die Verteilung sind, dass er einfach zu berechnen ist, wenige Konflikte aufweist und die Schlüssel gleichmäßig verteilt. Ein gutes Beispiel für einen effizienten Hashalgorithmus ist der Hashalgorithmus FNV-1 .
Hilfreiche Informationen zur Wahl des Hashcodealgorithmus finden Sie auf der Wikipedia-Seite über Hashfunktionen.
Erstellen eines zustandsbehafteten Diensts mit mehreren Partitionen
Sie erstellen jetzt Ihren ersten zuverlässigen zustandsbehafteten Dienst mit mehreren Partitionen. In diesem Beispiel erstellen Sie eine sehr einfache Anwendung, in der Sie alle Nachnamen, die mit dem gleichen Buchstaben beginnen, in derselben Partition speichern möchten.
Bevor Sie Code schreiben, müssen Sie sich überlegen, welche Partitionen und Partitionsschlüssel verwendet werden sollen. Sie benötigen 26 Partitionen (eine für jeden Buchstaben des Alphabets). Aber was ist mit dem niedrigen und dem hohen Schlüssel? Da wir eine Partition pro Buchstabe benötigen, können wir 0 als niedrigen Schlüssel und 25 als hohen Schlüssel verwenden. So hat jeder Buchstabe seinen eigenen Schlüssel.
Hinweis
Dies ist ein vereinfachtes Szenario, da die Verteilung in der Praxis ungleichmäßig wäre. Nachnamen, die mit dem Buchstaben „S“ oder „M“ beginnen, treten häufiger als Nachnamen mit „X“ oder „Y“ auf.
Öffnen Sie Visual Studio>Datei>Neu>Projekt.
Wählen Sie im Dialogfeld Neues Projekt die Service Fabric-Anwendung aus.
Geben Sie dem Projekt den Namen „AlphabetPartitions“.
Wählen Sie im Dialogfeld Dienst erstellen für den Dienst Zustandsbehaftet aus, und geben Sie dem Dienst den Namen „Alphabet.Processing“.
Legen Sie die Anzahl der Partitionen fest. Öffnen Sie im Projekt „AlphabetPartitions“ im Ordner „ApplicationPackageRoot“ die Datei „ApplicationManifest.xml“, und ändern Sie den Parameter „Processing_PartitionCount“ wie unten gezeigt in den Wert 26.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Außerdem müssen Sie, wie unten gezeigt, die Eigenschaften „LowKey“ und „HighKey“ des Elements „StatefulService“ in der Datei „ApplicationManifest.xml“ aktualisieren.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Damit auf den Dienst zugegriffen werden kann, öffnen Sie einen Endpunkt auf einem Port. Fügen Sie hierzu wie folgt das Endpunktelement der Datei „ServiceManifest.xml“ (im Ordner „PackageRoot“) für den Dienst „Alphabet.Processing“ hinzu:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Der Dienst ist jetzt für das Lauschen über einen internen Endpunkt mit 26 Partitionen konfiguriert.
Als Nächstes müssen Sie die
CreateServiceReplicaListeners()-Methode der Processing-Klasse überschreiben.Hinweis
In diesem Beispiel wird davon ausgegangen, dass Sie ein einfaches HttpCommunicationListener-Element verwenden. Weitere Informationen zur Reliable Service-Kommunikation finden Sie unter Das Reliable Service-Kommunikationsmodell.
Ein empfohlenes Muster für die URL, unter der ein Replikat lauscht, ist das folgende Format:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}Es ist also ratsam, Ihren Kommunikationslistener an den richtigen Endpunkten lauschen zu lassen und dieses Muster zu verwenden.Mehrere Replikate dieses Diensts können auf demselben Computer gehostet werden. Diese Adresse muss also für das Replikat also eindeutig sein. Daher werden die Partitions-ID und die Replikat-ID in der URL verwendet. HttpListener kann unter mehreren Adressen auf demselben Port beobachten, solange das URL-Präfix eindeutig ist.
Die zusätzliche GUID ist für einen erweiterten Fall vorhanden, in dem sekundäre Replikate auch auf schreibgeschützte Anforderungen lauschen. In diesem Fall sollten Sie sicherstellen, dass beim Übergang von primären zu sekundären Replikaten eine neue eindeutige Adresse verwendet wird, um Clients zum Auflösen der Adresse zu zwingen. Hier wird „+“ als Adresse verwendet, damit das Replikat auf allen verfügbaren Hosts lauscht (IP, FQDN, localhost usw.). Mit dem folgenden Code wird ein Beispiel veranschaulicht.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Beachten Sie auch, dass sich die veröffentlichte URL leicht vom Überwachungs-URL-Präfix unterscheidet. Die Überwachungs-URL wird für HttpListener vergeben. Die veröffentlichte URL ist die URL, die für den Service Fabric Naming Service veröffentlicht wird. Dieser Dienst wird für die Diensterkennung verwendet. Clients fragen diese Adresse über den Ermittlungsdienst ab. Die Adresse, die Clients erhalten, muss über die tatsächliche IP oder den FQDN des Knotens verfügen, damit eine Verbindung hergestellt werden kann. Sie müssen also wie oben gezeigt „+“ durch die IP oder den FQDN des Knotens ersetzen.
Der letzte Schritt ist das Hinzufügen der Verarbeitungslogik zum Dienst. Dies ist unten dargestellt.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestliest die Werte des Abfragezeichenfolgenparameters, der zum Aufrufen der Partition verwendet wird, und ruftAddUserAsyncauf, um den Nachnamen dem zuverlässigen Wörterbuchdictionaryhinzuzufügen.Wir fügen dem Projekt nun einen zustandslosen Dienst hinzu, um zu verdeutlichen, wie Sie eine bestimmte Partition aufrufen können.
Dieser Dienst dient als einfache Webschnittstelle, die den Nachnamen als Abfragezeichenfolgenparameter akzeptiert, den Partitionsschlüssel bestimmt und diesen zur Verarbeitung an den Alphabet.Processing-Dienst sendet.
Wählen Sie im Dialogfeld Dienst erstellen für den Dienst Zustandslos aus, und vergeben Sie, wie unten gezeigt, den Namen „Alphabet.Web“.
 .
.Aktualisieren Sie die Endpunktinformationen in der Datei „ServiceManifest.xml“ des Alphabet.WebApi-Diensts, um wie unten gezeigt einen Port zu öffnen.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Sie müssen in der Klasse „Web“ eine Sammlung mit „ServiceInstanceListener“-Elementen zurückgeben. Auch hier können Sie wieder einen einfachen HttpCommunicationListener implementieren.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Als Nächstes müssen Sie die Verarbeitungslogik implementieren. Der HttpCommunicationListener ruft
ProcessInputRequestauf, wenn eine Anforderung eingeht. Wir fügen jetzt also den folgenden Code hinzu.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Wir führen Sie schrittweise durch dieses Verfahren. Der Code liest den ersten Buchstaben des Zeichenabfolgeparameters
lastnamein ein char-Objekt ein. Anschließend bestimmt er den Partitionsschlüssel für diesen Buchstaben durch Abziehen des Hexwerts vonAvom Hexwert des Anfangsbuchstabens des Nachnamens.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Bedenken Sie, dass wir für dieses Beispiel 26 Partitionen mit einem Partitionsschlüssel pro Partition verwenden. Als Nächstes rufen wir die Dienstpartition
partitionfür diesen Schlüssel ab, indem wir dieResolveAsync-Methode für dasservicePartitionResolver-Objekt verwenden.servicePartitionResolverist wie folgt definiert:private readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();Für die
ResolveAsync-Methode werden der Dienst-URI, der Partitionsschlüssel und ein Abbruchtoken als Parameter verwendet. Der Dienst-URI für den Verarbeitungsdienst istfabric:/AlphabetPartitions/Processing. Als Nächstes rufen wir den Endpunkt der Partition ab.ResolvedServiceEndpoint ep = partition.GetEndpoint()Als Letztes erstellen wir die Endpunkt-URL sowie die Abfragezeichenfolge und rufen den Verarbeitungsdienst auf.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Nachdem die Verarbeitung abgeschlossen ist, schreiben wir die Ausgabe wieder zurück.
Der letzte Schritt besteht darin, den Dienst zu testen. In Visual Studio werden Anwendungsparameter für die lokale Bereitstellung und die Cloudbereitstellung verwendet. Zum lokalen Testen des Diensts mit 26 Partitionen müssen Sie die Datei
Local.xmlim Ordner „ApplicationParameters“ des Projekts „AlphabetPartitions“ aktualisieren. Dies ist hier dargestellt:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Nach Abschluss der Bereitstellung können Sie den Dienst und alle Partitionen in Service Fabric Explorer überprüfen.
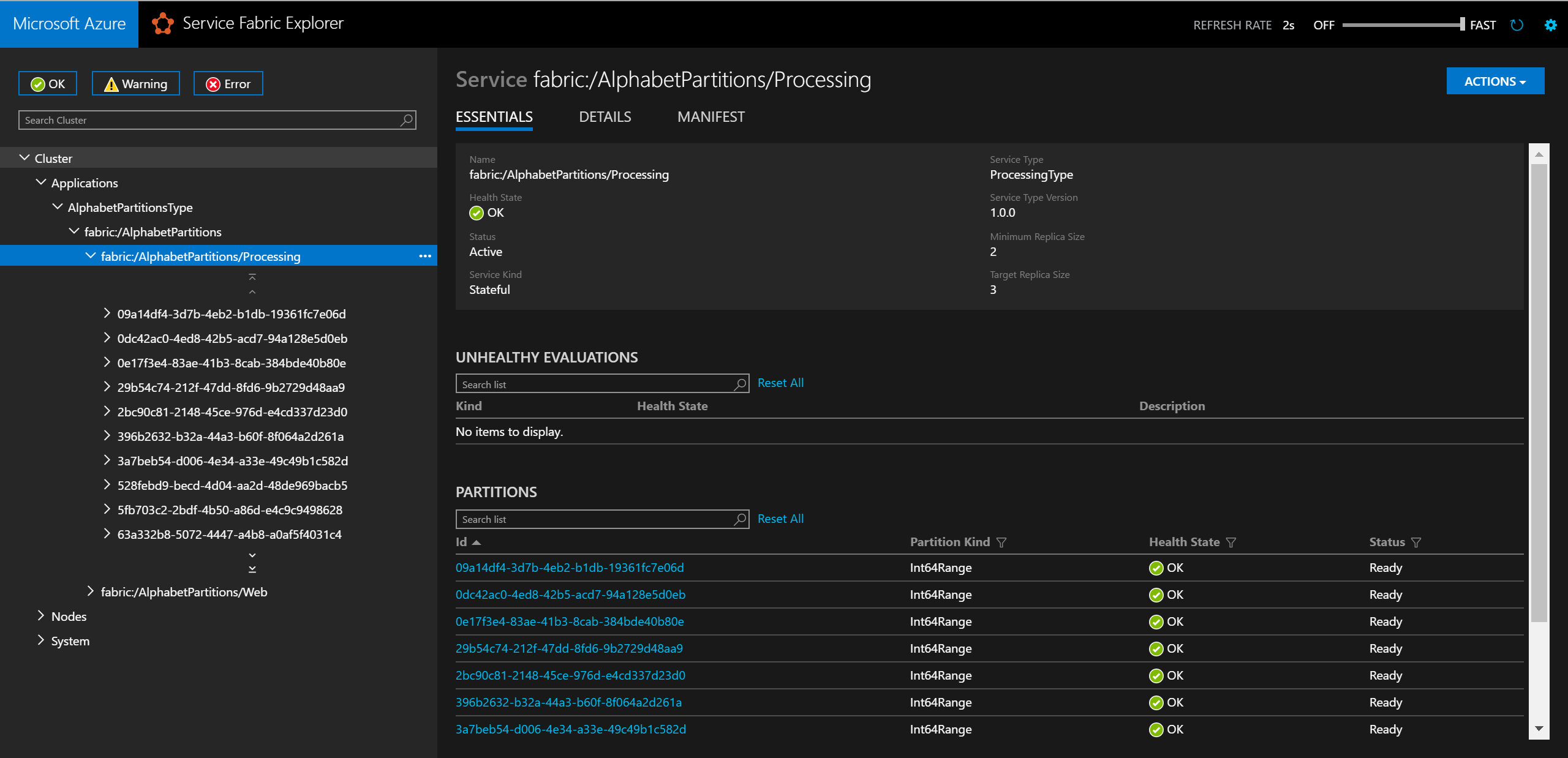
In einem Browser können Sie die Partitionierungslogik testen, indem Sie
http://localhost:8081/?lastname=somenameeingeben. Sie sehen, dass alle Nachnamen mit dem gleichen Anfangsbuchstaben in derselben Partition gespeichert sind.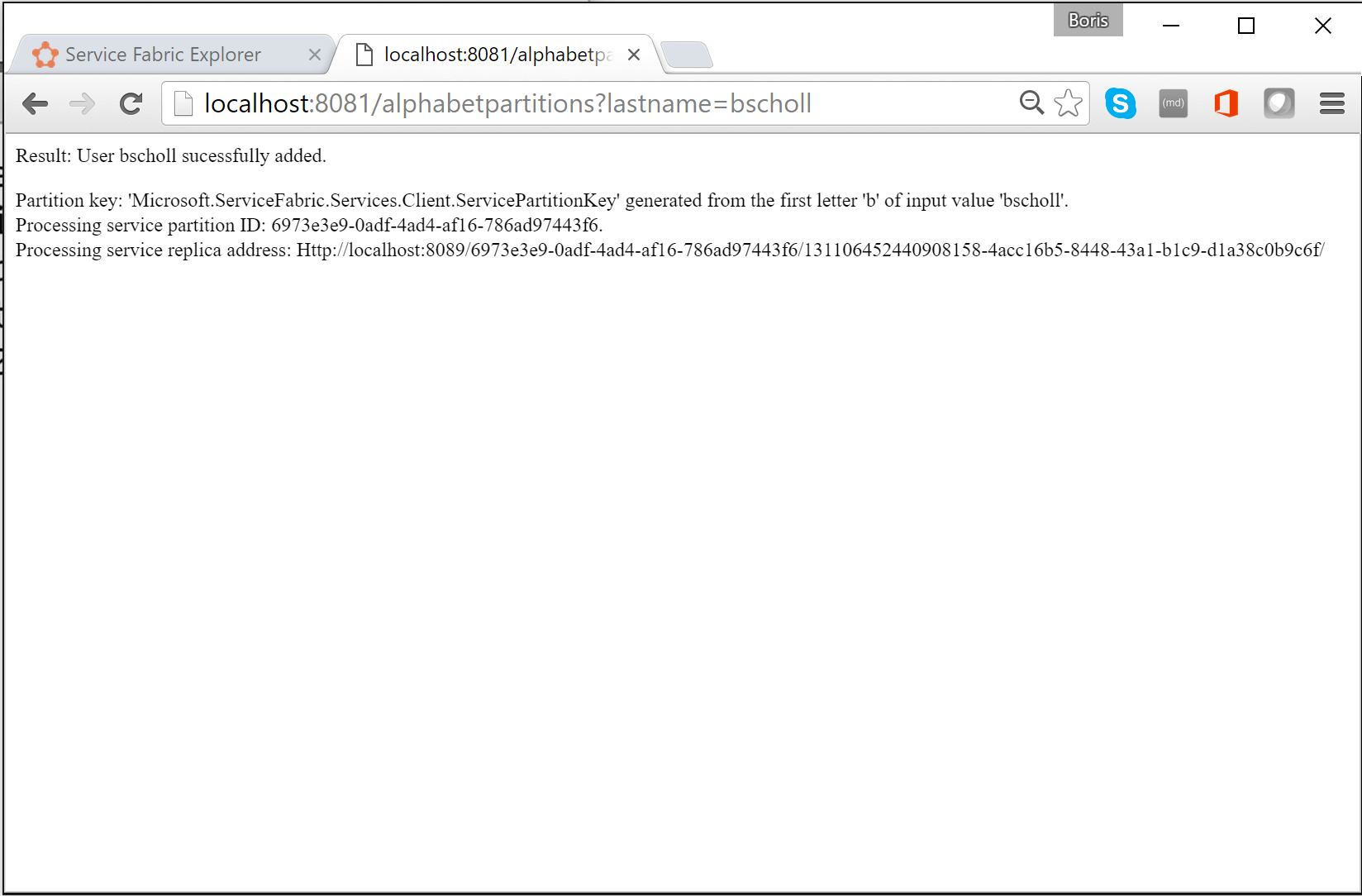
Die vollständige Lösung für den in diesem Artikel verwendeten Code finden Sie hier: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Nächste Schritte
Weitere Informationen zu Service Fabric-Diensten:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für