Analysieren des Bereitstellungsplaner-Berichts für die VMware-Notfallwiederherstellung in Azure
Der erstellte Microsoft Excel-Bericht enthält die folgenden Tabellen:
On-premises Summary (Lokale Zusammenfassung)
Das Arbeitsblatt „On-premises Summary“ (Lokale Zusammenfassung) enthält eine Übersicht über die VMware-Umgebung für die Profilerstellung.
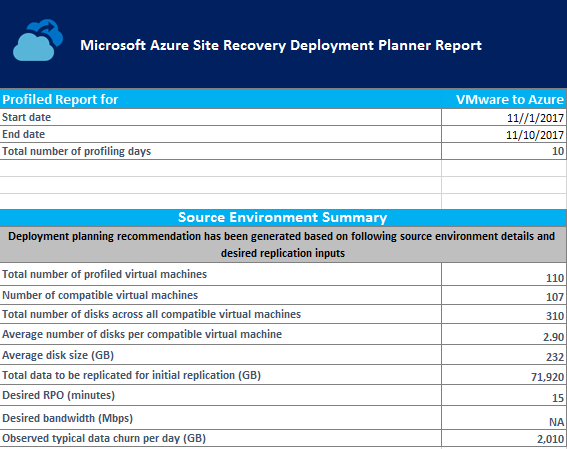
Start date (Startdatum) und End date (Enddatum): Das Start- und das Enddatum der bei der Berichterstellung berücksichtigten Profilerstellungsdaten. Das Startdatum ist standardmäßig das Datum, an dem die Profilerstellung beginnt, und das Enddatum ist das Datum, an dem die Profilerstellung beendet wird. Dies können die Werte von „StartDate“ und „EndDate“ sein, wenn der Bericht mit diesen Parametern erstellt wird.
Total number of profiling days (Gesamtanzahl von Profilerstellungstagen): Die gesamte Anzahl von Tagen der Profilerstellung zwischen dem Start- und dem Enddatum, für die der Bericht erstellt wird.
Number of compatible virtual machines (Anzahl von kompatiblen virtuellen Computern): Die Gesamtanzahl von kompatiblen VMs, für die die erforderliche Netzwerkbandbreite, die erforderliche Anzahl von Speicherkonten, Microsoft Azure-Kerne, Konfigurationsserver und zusätzliche Prozessserver berechnet werden.
Total number of disks across all compatible virtual machines (Gesamtanzahl von Datenträgern über alle kompatiblen virtuellen Computer): Die Zahl für eine der Eingaben, um eine Entscheidung über die Anzahl von Konfigurationsservern und zusätzlichen Prozessservern zu treffen, die in der Bereitstellung verwendet werden sollen.
Average number of disks per compatible virtual machine (Durchschnittliche Anzahl von Datenträgern pro kompatiblem virtuellem Computer): Durchschnittliche Anzahl von Datenträgern, die über alle kompatiblen VMs hinweg berechnet wird.
Average disk size (GB) (Durchschnittliche Datenträgergröße (GB)): Durchschnittliche Datenträgergröße, die über alle kompatiblen VMs hinweg berechnet wird.
Desired RPO (minutes) (Gewünschter RPO-Wert (Minuten)): Der RPO-Standardwert (Recovery Point Objective) oder der Wert, der für den Parameter „DesiredRPO“ zum Zeitpunkt der Berichterstellung übergeben wird, um die erforderliche Bandbreite zu schätzen.
Desired bandwidth (Mbps) (Gewünschte Bandbreite (MBit/s)): Der Wert, den Sie für den Parameter „Bandwidth“ zum Zeitpunkt der Berichterstellung übergeben haben, um den erreichbaren RPO-Wert zu schätzen.
Observed typical data churn per day (GB) (Beobachtete typische Datenänderungsrate pro Tag (GB)): Die durchschnittliche, über alle Tage der Profilerstellung hinweg beobachtete Datenänderungsrate. Diese Anzahl wird als eine der Eingaben genutzt, um eine Entscheidung über die Anzahl von Konfigurationsservern und zusätzlichen Prozessservern zu treffen, die in der Bereitstellung verwendet werden sollen.
Empfehlungen
Das Arbeitsblatt „Recommendations“ (Empfehlungen) des Berichts für „VMware zu Azure“ enthält je nach ausgewähltem gewünschtem RPO die folgenden Details:
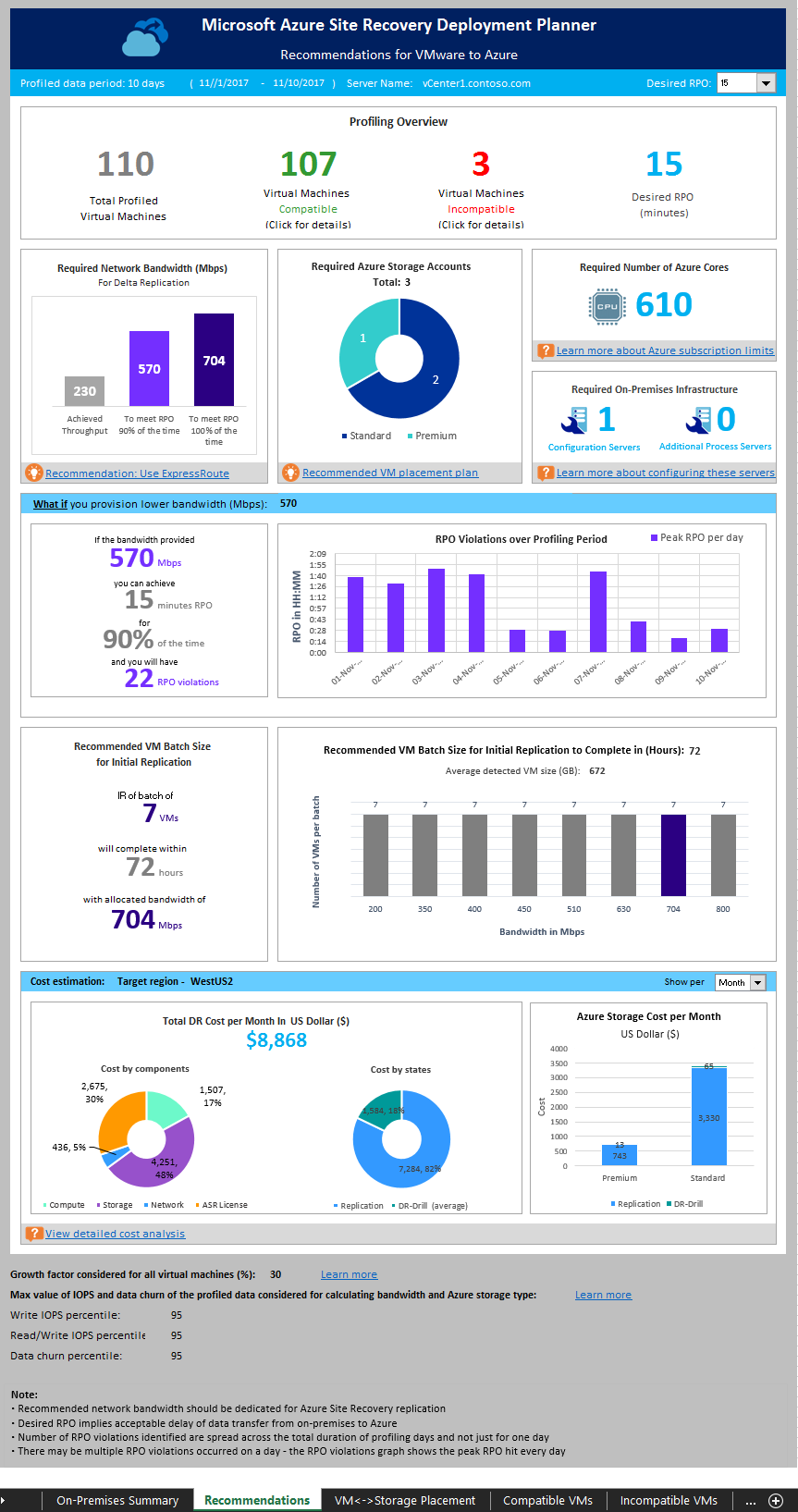
Profilerstellungsdaten

Profiled data period (Zeitraum der Profilerstellung): Der Zeitraum, in dem die Profilerstellung durchgeführt wurde. Standardmäßig bezieht das Tool alle Profilerstellungsdaten in die Berechnung ein, sofern der Bericht nicht nur für einen bestimmten Zeitraum erstellt wird, indem bei der Berichterstellung die Optionen „StartDate“ und „EndDate“ genutzt werden.
Server Name: Der Name oder die IP-Adresse des VMware vCenter- oder ESXi-Hosts, für dessen VMs der Bericht erstellt wird.
Desired RPO (Gewünschter RPO-Wert): Der RPO-Wert (Recovery Point Objective) für Ihre Bereitstellung. Standardmäßig wird die erforderliche Netzwerkbandbreite für RPO-Werte von 15, 30 und 60 Minuten berechnet. Basierend auf der Auswahl werden die betroffenen Werte auf dem Blatt aktualisiert. Wenn Sie beim Erstellen des Berichts den Parameter DesiredRPOinMin verwendet haben, wird dieser Wert als Ergebnis unter „Desired RPO“ (Gewünschter RPO-Wert) angezeigt.
Übersicht über die Profilerstellung

Total Profiled Virtual Machines (VMs mit Profilerstellung insgesamt): Die Gesamtanzahl der VMs, deren Profilerstellungsdaten verfügbar sind. Wenn „VMListFile“ Namen von VMs enthält, für die keine Profile erstellt wurden, werden diese VMs in der Berichterstellung nicht berücksichtigt und aus der Gesamtzahl von VMs für die Profilerstellung ausgeschlossen.
Compatible Virtual Machines (Kompatible virtuelle Computer): Die Anzahl von VMs, die mit Site Recovery in Azure geschützt werden können. Dies ist die Gesamtzahl von kompatiblen VMs, für die die erforderliche Netzwerkbandbreite, die Anzahl von Speicherkonten, die Anzahl von Azure-Kernen und die Anzahl von Konfigurationsservern und zusätzlichen Prozessservern berechnet werden. Die Details der einzelnen kompatiblen VMs sind im Abschnitt „Kompatible VMs“ enthalten.
Incompatible Virtual Machines (Inkompatible virtuelle Computer): Die Anzahl von VMs, für die Profile erstellt wurden und die mit dem Schutz mit Site Recovery inkompatibel sind. Die Gründe für die Inkompatibilität sind im Abschnitt „Inkompatible VMs“ beschrieben. Wenn „VMListFile“ Namen von VMs enthält, für die keine Profile erstellt wurden, werden diese VMs aus der Anzahl von inkompatiblen VMs ausgeschlossen. Diese VMs werden unten im Abschnitt „Incompatible VMs“ (Inkompatible VMs) unter „Data not found“ (Daten nicht gefunden) aufgeführt.
Desired RPO (Gewünschter RPO-Wert): Ihr gewünschter RPO-Wert (Recovery Point Objective) in Minuten. Der Bericht wird für drei RPO-Werte erstellt: 15 (Standard), 30 und 60 Minuten. Die Bandbreitenempfehlung im Bericht wird basierend auf Ihrer Auswahl in der Dropdownliste „Desired RPO“ (Gewünschter RPO-Wert) oben rechts auf dem Blatt geändert. Wenn Sie den Bericht mit dem Parameter -DesiredRPO und einem benutzerdefinierten Wert erstellt haben, wird dieser benutzerdefinierte Wert in der Dropdownliste „Desired RPO“ (Gewünschter RPO-Wert) als Standardwert angezeigt.
Erforderliche Netzwerkbandbreite (MBit/s)
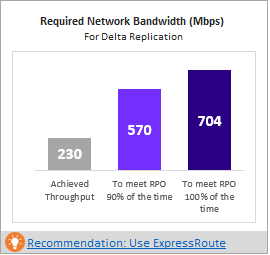
To meet RPO 100 percent of the time (Erreichung des RPO-Werts in 100 % der Fälle): Die empfohlene Bandbreite in MBit/s, die zugeordnet werden sollte, um den gewünschten RPO-Wert in 100 % der Fälle zu erzielen. Diese Menge an Bandbreite muss dediziert für die Deltareplikation im stabilen Zustand für alle kompatiblen VMs bereitgestellt werden, um RPO-Verletzungen zu vermeiden.
To meet RPO 90 percent of the time (Erreichung des RPO-Werts in 90 % der Fälle): Wenn Sie aufgrund der Breitbandpreise oder aus einem anderen Grund nicht die Bandbreite festlegen können, die zur Erreichung des gewünschten RPO-Werts in 100 % der Fälle erforderlich ist, können Sie auch eine niedrigere Bandbreiteneinstellung wählen, mit der der gewünschte RPO-Wert in 90 % der Fälle erreicht wird. Zum besseren Verständnis der Auswirkungen, die mit dem Festlegen dieser geringeren Bandbreite verbunden sind, enthält der Bericht eine Was-wäre-wenn-Analyse zu Anzahl und Dauer der zu erwartenden RPO-Verletzungen.
Achieved Throughput (Erzielter Durchsatz): Der Durchsatz von dem Server, auf dem Sie den GetThroughput-Befehl ausgeführt haben, zu der Microsoft Azure-Region, in der sich das Speicherkonto befindet. Mit diesem Durchsatzwert wird die geschätzte Ebene angegeben, die Sie erreichen können, wenn Sie die kompatiblen VMs mit Site Recovery schützen – vorausgesetzt, die Speicher- und Netzwerkmerkmale Ihres Konfigurations- bzw. Prozessservers bleiben in Bezug auf den Server, auf dem Sie das Tool ausgeführt haben, unverändert.
Für die Replikation sollten Sie die empfohlene Bandbreite so festlegen, dass der RPO-Wert in 100 Prozent der Fälle erreicht wird. Nach dem Festlegen der Bandbreite sollten Sie wie folgt vorgehen, falls vom Tool kein Anstieg des erzielten Durchsatzes gemeldet wird:
Überprüfen Sie, ob der Azure Site Recovery-Durchsatz durch die Dienstqualität (Quality of Service, QoS) des Netzwerks eingeschränkt wird.
Überprüfen Sie, ob sich Ihr Azure Site Recovery-Tresor in der nächstgelegenen physisch unterstützten Microsoft Azure-Region befindet, um die Netzwerkwartezeit zu verringern.
Überprüfen Sie Ihre lokalen Speichermerkmale, um zu ermitteln, ob Sie die Hardware (z.B. Wechsel von HDD auf SSD) verbessern können.
Ändern Sie die Azure Site Recovery-Einstellungen auf dem Prozessserver, um die für die Replikation verwendete Menge an Netzwerkbandbreite zu erhöhen.
Wenn Sie das Tool auf einem Konfigurations- oder Prozessserver ausführen, der bereits über geschützte VMs verfügt, ist es ratsam, das Tool mehrmals auszuführen. Der erzielte Durchsatzwert ändert sich je nach dem Datenänderungsvolumen, das zum jeweiligen Zeitpunkt verarbeitet wird.
Für alle Site Recovery-Bereitstellungen für Unternehmen empfehlen wir die Verwendung von ExpressRoute.
Erforderliche Speicherkonten
Im folgenden Diagramm wird die Gesamtzahl von Speicherkonten (Standard und Premium) angegeben, die zum Schützen aller kompatiblen VMs erforderlich sind. Informationen dazu, welches Speicherkonto für eine VM jeweils verwendet werden sollte, finden Sie im Abschnitt „VM/Speicher-Anordnung“. Wenn Sie Version 2.5 des Bereitstellungsplaners verwenden, zeigt diese Empfehlung nur die Anzahl von Standard-Cachespeicherkonten an, die für die Replikation erforderlich sind, da die Daten direkt auf verwaltete Datenträger geschrieben werden.

Erforderliche Anzahl von Azure-Kernen
Dieses Ergebnis gibt die Gesamtzahl von Kernen an, die eingerichtet werden sollten, bevor ein Failover oder Testfailover für alle kompatiblen VMs durchgeführt wird. Falls im Abonnement zu wenig Kerne verfügbar sind, können von Site Recovery bei einem Testfailover oder Failover keine VMs erstellt werden.

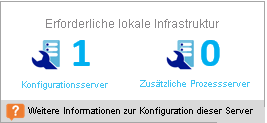
Erforderliche lokale Infrastruktur
Hiermit wird die Gesamtzahl von Konfigurationsservern und zusätzlichen Prozessservern angegeben, die konfiguriert werden müssen, um alle kompatiblen VMs zu schützen. Je nach den unterstützten empfohlene Größen für den Konfigurationsserver werden vom Tool ggf. weitere Server empfohlen. Die Empfehlung basiert auf der täglichen Änderungsrate oder der maximalen Anzahl von geschützten VMs (bei durchschnittlich drei Datenträgern pro VM) – je nachdem, welcher Wert größer ist bzw. auf dem Konfigurationsserver oder zusätzlichen Prozessserver zuerst erreicht wird. Die Details der Gesamtänderungsrate pro Tag und die Gesamtzahl von geschützten Datenträgern finden Sie im Abschnitt „On-premises Summary“ (Lokale Zusammenfassung).
Was-wäre-wenn-Analyse
Bei dieser Analyse wird angegeben, wie viele Regelverletzungen während des Zeitraums der Profilerstellung auftreten können, wenn Sie eine geringere Bandbreite festlegen, um den gewünschten RPO-Wert nur in 90% der Fälle zu erreichen. Jeden Tag können eine oder mehrere RPO-Verletzungen auftreten. Im Graphen wird der RPO-Spitzenwert des Tages angezeigt. Anhand dieser Analyse können Sie entscheiden, ob die Anzahl von RPO-Verletzungen über alle Tage hinweg und die RPO-Spitzenwerte pro Tag für die angegebene geringere Bandbreite akzeptabel sind. Wenn ja, können Sie die geringere Bandbreite für die Replikation zuordnen. Ordnen Sie ansonsten die höhere Bandbreite gemäß dem Vorschlag zu, um den gewünschten RPO-Wert in 100% der Fälle zu erreichen.
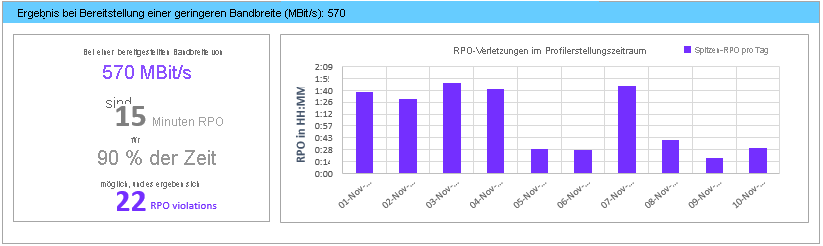
Empfohlene VM-Batchgröße für die erste Replikation
In diesem Abschnitt wird die Anzahl von VMs empfohlen, die parallel geschützt werden können, um die erste Replikation innerhalb von 72 Stunden mit der vorgeschlagenen Bandbreite durchzuführen und den gewünschten RPO-Wert in 100% der Fälle zu erreichen. Dieser Wert ist konfigurierbar. Verwenden Sie den Parameter GoalToCompleteIR, um ihn bei der Berichterstellung zu ändern.
Der hier angegebene Graph zeigt einen Bereich mit Bandbreitenwerten und einer berechneten VM-Batchgrößenanzahl, um die erste Replikation innerhalb von 72 Stunden durchzuführen – basierend auf der ermittelten durchschnittlichen VM-Größe über alle kompatiblen VMs hinweg.
In der öffentlichen Vorschauversion wird im Bericht nicht angegeben, welche VMs in einem Batch enthalten sein sollten. Sie können die im Abschnitt „Kompatible VMs“ angezeigte Datenträgergröße verwenden, um nach den Größen der einzelnen VMs zu suchen und diese für einen Batch auszuwählen, oder Sie können die VMs basierend auf bekannten Workloadmerkmalen auswählen. Die Dauer der ersten Replikation ändert sich proportional basierend auf der tatsächlichen VM-Datenträgergröße, dem genutzten Datenträgerspeicherplatz und dem verfügbaren Netzwerkdurchsatz.
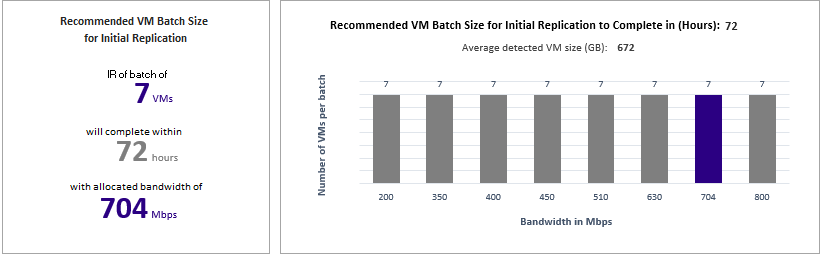
Cost Estimation (Kostenvorkalkulation)
Im Graphen ist die Übersicht über die geschätzten Gesamtkosten der Notfallwiederherstellung (Disaster Recovery, DR) in Azure für Ihre gewählte Zielregion und Währung dargestellt, die Sie für die Berichterstellung angegeben haben.
Die Zusammenfassung erleichtert das Verständnis der Kosten, die für Speicher, Compute, Netzwerk und Lizenz anfallen, wenn Sie Ihre gesamten kompatiblen VMs mit Azure Site Recovery in Azure schützen. Die Kosten werden für kompatible VMs berechnet, nicht für alle VMs, für die eine Profilerstellung durchgeführt wurde.
Sie können die Kosten entweder monatlich oder jährlich anzeigen. Erfahren Sie mehr zu unterstützten Zielregionen und unterstützten Währungen.
Cost by components (Kosten nach Komponenten): Die Gesamtkosten für die Notfallwiederherstellung sind in vier Komponenten unterteilt: Compute-, Speicher-, Netzwerk- und Azure Site Recovery-Lizenzkosten. Die Kosten werden basierend auf der Nutzung berechnet, die während der Replikations- und DR-Drillvorgänge für die Bereiche Compute, Speicher (Premium und Standard), konfigurierte ExpressRoute/VPN-Verbindung zwischen lokalem Standort und Azure sowie Azure Site Recovery-Lizenz anfallen.
Cost by states (Kosten nach Zustand): Die Gesamtkosten für die Notfallwiederherstellung werden basierend auf zwei unterschiedlichen Zuständen kategorisiert: Replikation und DR-Drill.
Replication cost: Die Kosten, die während der Replikation anfallen. Hierin sind die Kosten für Speicher, Netzwerk und Azure Site Recovery-Lizenz enthalten.
DR-Drill cost (Kosten für DR-Drills): Die Kosten, die bei einem Testfailover anfallen. Während des Testfailovers startet Azure Site Recovery virtuelle Computer (VMs). Die Kosten für DR-Drills decken die Compute- und Speicherkosten für die ausgeführten VMs ab.
Azure storage cost per Month/Year (Azure-Speicherkosten pro Monat/Jahr): Hier werden die Speichergesamtkosten angezeigt, die bei der Replikation und bei DR-Drills für Storage Premium und Standardspeicher anfallen. Sie können die ausführliche Kostenanalyse pro VM in der Tabelle Cost Estimation (Kostenvorkalkulation) anzeigen.
Verwendeter Zuwachsfaktor und Perzentilwerte
In diesem Abschnitt werden unten auf dem Blatt der verwendete Perzentilwert für alle Leistungsindikatoren der VMs für die Profilerstellung (Standardeinstellung: 95. Perzentil) und der für alle Berechnungen verwendete Zuwachsfaktor (Standardeinstellung: 30%) angezeigt.

Empfehlungen mit verfügbarer Bandbreite als Eingabe

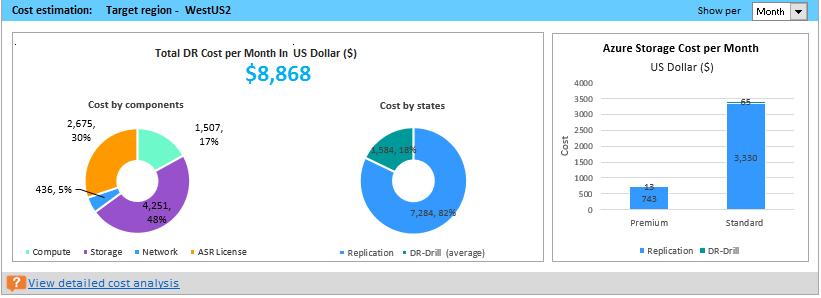
Es kann sein, dass Sie in einer bestimmten Situation wissen, dass Sie keine höhere Bandbreite als x MBit/s für die Site Recovery-Replikation festlegen können. Das Tool ermöglicht Ihnen das Eingeben der verfügbaren Bandbreite (mit Verwendung des Parameters „-Bandwidth“ während der Berichterstellung) und das Ermitteln des erreichbaren RPO-Werts in Minuten. Anhand dieser Angabe zum erreichbaren RPO-Wert können Sie entscheiden, ob Sie zusätzliche Bandbreite einrichten müssen oder ob eine Lösung für die Notfallwiederherstellung mit diesem RPO-Wert für Sie ausreicht.
VM/Speicher-Anordnung
Hinweis
Ab Bereitstellungsplaner v2.5 wird die Speicherplatzierung für Computer empfohlen, die direkt auf verwalteten Datenträgern repliziert werden.
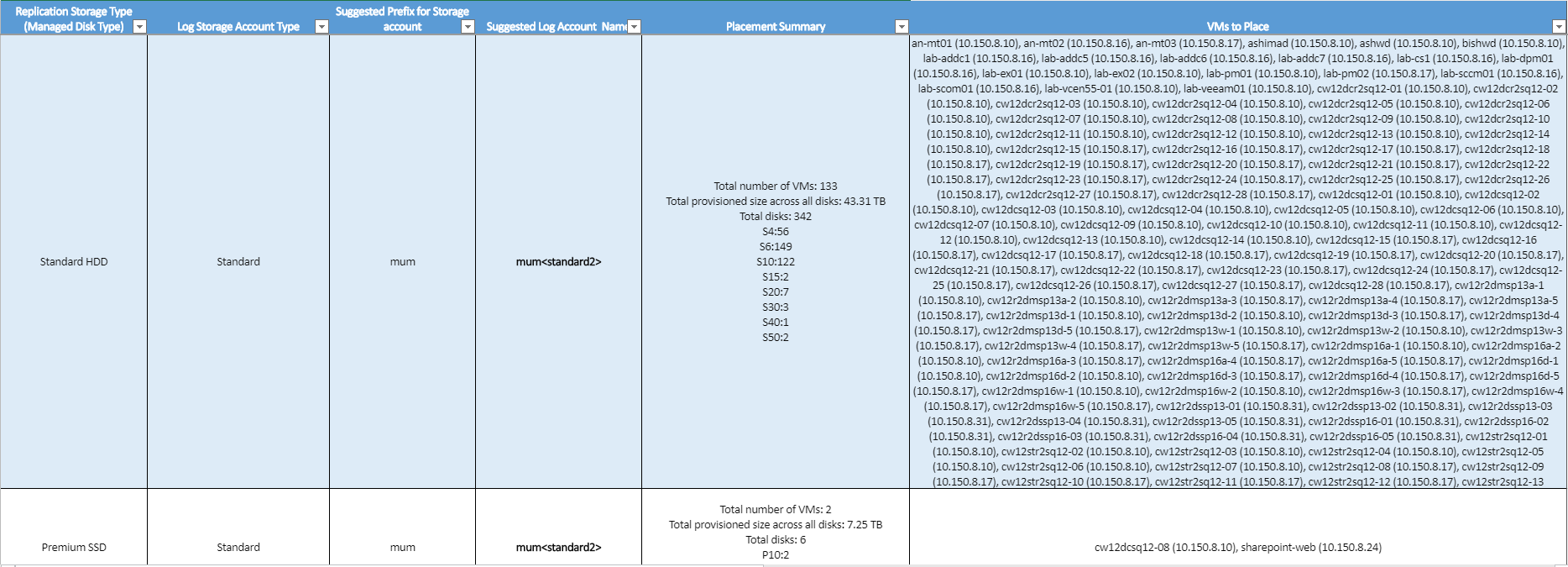
Replication Storage Type (Replikationsspeichertyp): Ein verwalteter Datenträger des Typs „Standard“ oder „Premium“, der zum Replizieren aller VMs verwendet wird, die in der Spalte VMs to Place (Anzuordnende VMs) angegeben sind
Log Storage Account Type (Typ des Protokollspeicherkontos): Alle Replikationsprotokolle werden in einem Speicherkonto vom Typ „Standard“ gespeichert.
Suggested Prefix for Storage Account (Empfohlenes Präfix für das Speicherkonto): Das vorgeschlagene Präfix aus drei Zeichen, das zum Benennen des Cachespeicherkontos verwendet werden kann. Sie können ein eigenes Präfix verwenden, aber der Vorschlag des Tools basiert auf der Partitionsbenennungskonvention für Speicherkonten.
Suggested Log Account Name (Vorgeschlagener Protokollkontoname): Der Speicherkontoname nach Einbindung des vorgeschlagenen Präfix. Ersetzen Sie den Namen innerhalb der spitzen Klammern (< und >) durch Ihre eigene Eingabe.
Placement Summary (Zusammenfassung der Anordnung): Eine Zusammenfassung der zum Schützen der VMs erforderlichen Datenträger nach Speichertyp. Die Spalte enthält die Gesamtanzahl von VMs, die insgesamt auf allen Datenträgern bereitgestellte Größe und die Gesamtanzahl von Datenträgern.
Virtual Machines to Place (Zu platzierende virtuelle Computer): Eine Liste aller VMs, die im jeweiligen Speicherkonto angeordnet werden sollten, um die optimale Leistung und Nutzung zu erzielen.
Kompatible VMs
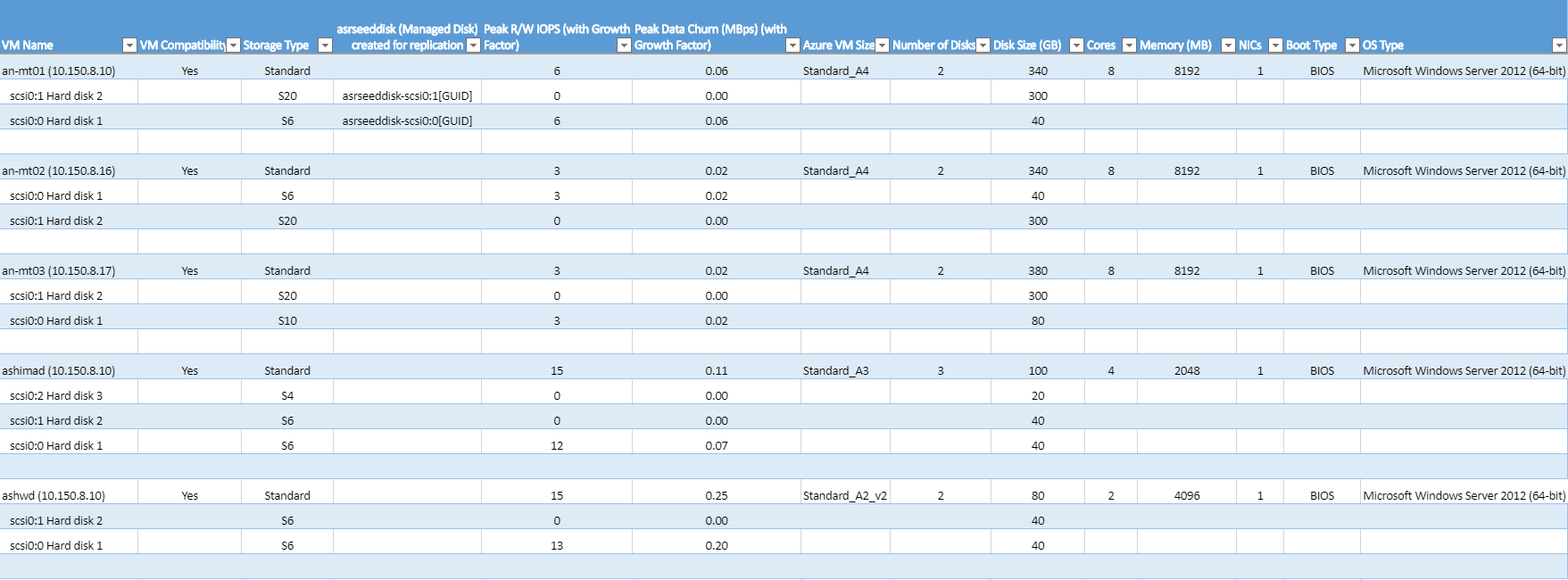
VM Name: Der VM-Name oder die IP-Adresse, der bzw. die beim Erstellen eines Berichts in „VMListFile“ verwendet wird. In dieser Spalte sind auch die Datenträger (VMDKs) angegeben, die an die VMs angefügt sind. Die Namen enthalten den ESXi-Hostnamen, um vCenter-VMs mit doppelten Namen oder IP-Adressen unterscheiden zu können. Der aufgeführte ESXi-Host ist der Host, auf dem die VM angeordnet wurde, als das Tool während der Profilerstellung die Ermittlung durchgeführt hat.
VM Compatibility (VM-Kompatibilität): Mögliche Werte sind Yes und Yes*. Yes* steht für Fälle, in denen die VM für Premium-SSDs geeignet ist. Hier fällt der Datenträger mit hoher Datenänderungsrate bzw. hohem IOPS-Wert, für den das Profil erstellt wird, in die Kategorie P20 oder P30. Aufgrund der Größe des Datenträgers wird er aber auf P10 bzw. P20 heruntergestuft. Das Speicherkonto entscheidet basierend auf der Größe, welchem Storage Premium-Datenträgertyp ein Datenträger zugeordnet wird. Zum Beispiel:
- <Bei bis 128 GB wird die Kategorie P10 verwendet.
- Bei 128 GB bis 256 GB wird die Kategorie P15 verwendet.
- Bei 256 GB bis 512 GB wird die Kategorie P20 verwendet.
- Für den Bereich zwischen 512 GB und 1024 GB (jeweils einschließlich) lautet die Kategorie P30.
- Für den Bereich zwischen 1025 GB und 2048 GB (jeweils einschließlich) lautet die Kategorie P40.
- Für den Bereich zwischen 2049 GB und 4095 GB (jeweils einschließlich) lautet die Kategorie P50.
Wenn beispielsweise eine Festplatte aufgrund ihrer Workload-Merkmale in die Kategorie P20 oder P30 fällt, aber aufgrund ihrer Größe einem niedrigeren Premium-Speicherplattentyp zugeordnet wird, markiert das Tool diese VM als Ja*. Sie erhalten vom Tool außerdem die Empfehlung, dass Sie entweder die Größe des Quelldatenträgers an den empfohlenen Storage Premium-Datenträgertyp anpassen oder den Typ des Zieldatenträgers nach dem Failover ändern sollten.
Storage Type (Speichertyp): Standard oder Premium.
Asrseeddisk (Managed Disk) created for replication (Für die Replikation erstelltes Asrseeddisk-Element (Verwalteter Datenträger)): Der Name des Datenträgers, der beim Aktivieren der Replikation erstellt wird. Er speichert die Daten und die zugehörigen Momentaufnahmen in Azure.
Peak R/W IOPS (with Growth Factor) (Lese/Schreib-IOPS (mit Zuwachsfaktor): Der Lese/Schreib-IOPS-Wert für die Spitzenworkload auf dem Datenträger (Standardeinstellung: 95. Perzentil), einschließlich des Faktors für den zukünftigen Zuwachs (Standardeinstellung: 30%). Beachten Sie, dass der Lese/Schreib-IOPS-Gesamtwert einer VM nicht immer die Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger einer VM ist. Der Grund ist, dass der Lese/Schreib-IOPS-Spitzenwert der VM der Spitzenwert der Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger für jede Minute des Profilerstellungszeitraums ist.
Peak Data Churn (MBps) (with Growth Factor) (Datenänderung (MBit/s) (mit Zuwachsfaktor)): Die Spitzenänderungsrate auf dem Datenträger (Standardeinstellung: 95. Perzentil), einschließlich des Faktors für den zukünftigen Zuwachs (Standardeinstellung: 30%). Beachten Sie Folgendes: Die gesamte VM-Datenänderung ist nicht immer die Summe der Datenänderung der einzelnen VM-Datenträger, da der Spitzenwert der VM-Datenänderung der Spitzenwert der Summe der Datenänderung seiner einzelnen Datenträger für jede Minute des Profilerstellungszeitraums ist.
Azure VM Size (Größe des virtuellen Azure-Computers): Die Idealgröße für die Zuordnung von Azure Cloud Services-VMs für diese lokale VM. Die Zuordnung basiert auf dem lokalen Arbeitsspeicher der VM, der Anzahl von Datenträgern/Kernen/NICs und dem Lese/Schreib-IOPS-Wert. Die Empfehlung ist immer die niedrigste Azure-VM-Größe, bei der alle Merkmale der lokalen VM erfüllt werden.
Number of Disks (Anzahl von Datenträgern): Die Gesamtzahl von Datenträgern auf dem virtuellen Computer (Virtual Machine Disks, VMDKs).
Disk size (GB) (Datenträgergröße (GB)): Eingerichtete Gesamtgröße aller Datenträger der VM. Im Tool wird auch die Datenträgergröße für die einzelnen Datenträger der VM angezeigt.
Cores (Kerne): Die Anzahl von CPU-Kernen auf der VM.
Memory (MB) (Arbeitsspeicher (MB)): Der Arbeitsspeicher (RAM) auf der VM.
NICs: Die Anzahl von NICs auf der VM.
Boot Type (Starttyp): Dies ist der Starttyp der VM. Er kann entweder „BIOS“ oder „EFI“ lauten. Derzeit unterstützt Azure Site Recovery Windows Server-EFI-VMs (Windows Server 2012, 2012 R2 und 2016), sofern die Anzahl von Partitionen auf dem Startdatenträger geringer als 4 ist und die Größe des Startsektors 512 Byte beträgt. Zum Schützen von EFI-VMs muss für den Azure Site Recovery Mobility Service die Version 9.13 oder höher verwendet werden. Für EFI-VMs wird nur das Failover unterstützt. Das Failback wird nicht unterstützt.
OS Type: Dies ist der Betriebssystemtyp der VM. Hier kann Windows, Linux oder ein anderer Typ angegeben werden. Dies richtet sich nach der ausgewählten Vorlage für VMware vSphere während der Erstellung der VM.
Inkompatible VMs
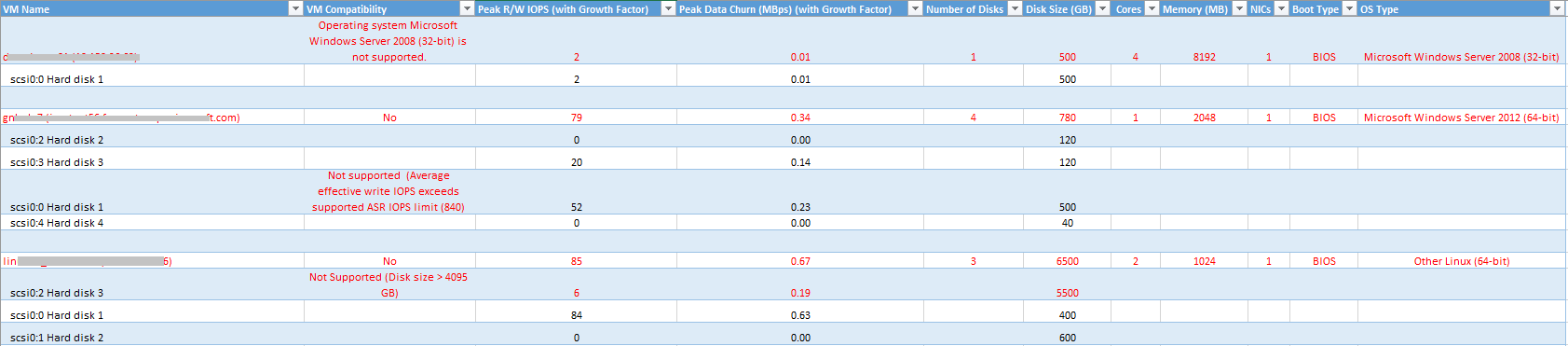
VM Name (VM-Name): Der VM-Name oder die IP-Adresse, der bzw. die in „VMListFile“ verwendet wird, wenn ein Bericht erstellt wird. In dieser Spalte sind auch die Datenträger (VMDKs) angegeben, die an die VMs angefügt sind. Die Namen enthalten den ESXi-Hostnamen, um vCenter-VMs mit doppelten Namen oder IP-Adressen unterscheiden zu können. Der aufgeführte ESXi-Host ist der Host, auf dem die VM angeordnet wurde, als das Tool während der Profilerstellung die Ermittlung durchgeführt hat.
VM Compatibility (VM-Kompatibilität): Gibt an, warum die jeweilige VM für die Verwendung mit Site Recovery nicht kompatibel ist. Die Gründe werden für jeden inkompatiblen Datenträger der VM beschrieben. Basierend auf den veröffentlichten Speichergrenzwerten können dies folgende Gründe sein:
Falsche Datenträgergröße oder falsche Größe des Betriebssystem-Datenträgers. Überprüfen Sie die Supportlimits.
Die VM-Gesamtgröße (Replikation + TFO) übersteigt den Grenzwert für die Unterstützung von Speicherkonten (35 TB). Diese Inkompatibilität tritt normalerweise auf, wenn ein einzelner Datenträger der VM über ein Leistungsmerkmal verfügt, das den unterstützten Azure- oder Site Recovery-Grenzwert für Standardspeicher überschreitet. Hierdurch fällt die VM in die Storage Premium-Zone. Die maximal unterstützte Größe für ein Storage Premium-Konto beträgt aber 35 TB, und eine einzelne geschützte VM kann nicht über mehrere Speicherkonten hinweg geschützt werden. Beachten Sie außerdem Folgendes: Wenn ein Testfailover auf einer geschützten VM durchgeführt wird, erfolgt dies unter demselben Speicherkonto, unter dem die Replikation durchgeführt wird. Richten Sie in diesem Fall die doppelte Größe des Datenträgers ein, damit die Replikation weiter durchgeführt werden kann und gleichzeitig das Testfailover erfolgreich ist.
Der IOPS-Quellwert übersteigt den unterstützten IOPS-Speichergrenzwert von 7.500 pro Datenträger.
Der IOPS-Quellwert übersteigt den unterstützten IOPS-Speichergrenzwert von 80.000 pro VM.
Die durchschnittliche Datenänderungsrate übersteigt den unterstützten Grenzwert für die Site Recovery-Datenänderungsrate von 20 MB/s für die durchschnittliche E/A-Größe für den Datenträger.
Die Spitzenänderungsrate für alle Datenträger auf der VM übersteigt den maximal unterstützten Grenzwert für die Site Recovery-Spitzenänderungsrate von 54 MB/s pro VM.
Der durchschnittliche effektive Schreib-IOPS-Wert übersteigt den unterstützten Site Recovery-IOPS-Grenzwert von 840 für den Datenträger.
Der berechnete Momentaufnahmespeicher übersteigt den unterstützten Grenzwert für Momentaufnahmespeicher von 10 TB.
Die gesamte Datenänderungsrate pro Tag übersteigt das unterstützte Limit für die Datenänderung pro Tag von 2 TB durch einen Prozessserver.
Peak R/W IOPS (with Growth Factor) (Lese/Schreib-IOPS-Spitzenwert (mit Zuwachsfaktor)): Der IOPS-Wert für die Spitzenworkload auf dem Datenträger (Standardeinstellung: 95. Perzentil), einschließlich des Faktors für den zukünftigen Zuwachs (Standardeinstellung: 30%). Beachten Sie, dass der Lese/Schreib-IOPS-Gesamtwert der VM nicht immer die Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger einer VM ist. Der Grund ist, dass der Lese/Schreib-IOPS-Spitzenwert der VM der Spitzenwert der Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger für jede Minute des Profilerstellungszeitraums ist.
Peak Data Churn in Mbps (with Growth Factor) (Spitzendatenänderung (MBit/s) (mit Zuwachsfaktor)): Die Spitzenänderungsrate auf dem Datenträger (Standardeinstellung: 95. Perzentil), einschließlich des Faktors für den zukünftigen Zuwachs (Standardeinstellung: 30%). Beachten Sie Folgendes: Die gesamte VM-Datenänderung ist nicht immer die Summe der Datenänderung der einzelnen VM-Datenträger, da der Spitzenwert der VM-Datenänderung der Spitzenwert der Summe der Datenänderung seiner einzelnen Datenträger für jede Minute des Profilerstellungszeitraums ist.
Number of Disks (Anzahl von Datenträgern): Die Gesamtzahl von VMDKs auf der VM.
Disk size (GB) (Datenträgergröße (GB)): Eingerichtete Gesamtgröße aller Datenträger der VM. Im Tool wird auch die Datenträgergröße für die einzelnen Datenträger der VM angezeigt.
Cores (Kerne): Die Anzahl von CPU-Kernen auf der VM.
Memory (MB) (Arbeitsspeicher (MB)): Die Größe des Arbeitsspeichers (RAM) auf der VM.
NICs: Die Anzahl von NICs auf der VM.
Boot Type (Starttyp): Dies ist der Starttyp der VM. Er kann entweder „BIOS“ oder „EFI“ lauten. Derzeit unterstützt Azure Site Recovery Windows Server-EFI-VMs (Windows Server 2012, 2012 R2 und 2016), sofern die Anzahl von Partitionen auf dem Startdatenträger geringer als 4 ist und die Größe des Startsektors 512 Byte beträgt. Zum Schützen von EFI-VMs muss für den Azure Site Recovery Mobility Service die Version 9.13 oder höher verwendet werden. Für EFI-VMs wird nur das Failover unterstützt. Das Failback wird nicht unterstützt.
OS Type: Dies ist der Betriebssystemtyp der VM. Hier kann Windows, Linux oder ein anderer Typ angegeben werden. Dies richtet sich nach der ausgewählten Vorlage für VMware vSphere während der Erstellung der VM.
Azure Site Recovery-Grenzwerte
Die folgende Tabelle enthält die Azure Site Recovery-Grenzwerte. Diese Grenzwerte basieren auf unseren Tests, können aber nicht alle möglichen E/A-Kombinationen für Anwendungen abdecken. Die tatsächlichen Ergebnisse können je nach Ihrer E/A-Mischung für die Anwendungen variieren. Auch nach der Planung der Bereitstellung ist es zum Erzielen der bestmöglichen Ergebnisse stets zu empfehlen, umfangreiche Anwendungstests per Testfailover durchzuführen, um sich ein eindeutiges Bild der Anwendungsleistung zu verschaffen.
| Replikationsspeicherziel | Durchschnittliche E/A-Größe des Quelldatenträgers | Durchschnittliche Datenänderungsrate des Quelldatenträgers | Gesamte Datenänderungsrate des Quelldatenträgers pro Tag |
|---|---|---|---|
| Standardspeicher | 8 KB | 2 MB/s | 168 GB pro Datenträger |
| Premium-Datenträger – P10 oder P15 | 8 KB | 2 MB/s | 168 GB pro Datenträger |
| Premium-Datenträger – P10 oder P15 | 16 KB | 4 MB/s | 336 GB pro Datenträger |
| Premium-Datenträger – P10 oder P15 | 32 KB oder höher | 8 MB/s | 672 GB pro Datenträger |
| Premium-Datenträger – P20, P30, P40 oder P50 | 8 KB | 5 MB/s | 421 GB pro Datenträger |
| Premium-Datenträger – P20, P30, P40 oder P50 | 16 KB oder höher | 20 MB/s | 1\.684 GB pro Datenträger |
| Quell-Datenänderungsrate | Maximales Limit |
|---|---|
| Spitzenänderungsrate für alle Datenträger auf einer VM | 54 MB/s |
| Maximale Datenänderung pro Tag, die von einem Prozessserver unterstützt wird | 2 TB |
Dies sind Durchschnittswerte, bei denen eine E/A-Überlappung von 30% angenommen wird. Site Recovery kann einen höheren Durchsatz basierend auf dem Überlappungsverhältnis, höheren Schreibgrößen und dem tatsächlichen Workload-E/A-Verhalten verarbeiten. Für die obigen Zahlen wurde ein typischer Backlog von ca. fünf Minuten vorausgesetzt. Dies bedeutet, dass die Daten nach dem Hochladen verarbeitet werden und innerhalb von fünf Minuten ein Wiederherstellungspunkt erstellt wird.
Cost Estimation (Kostenvorkalkulation)
Erfahren Sie mehr über die Kostenvorkalkulation.
Nächste Schritte
Erfahren Sie mehr über die Kostenvorkalkulation.