Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel beschreibt die Architektur und Prozesse, die mithilfe des Diensts Azure Site Recovery (klassisch) beim Bereitstellen der Replikation für die Notfallwiederherstellung, bei der Ausführung eines Failovers und beim Wiederherstellen von virtuellen VMware-Computern (VMs) zwischen einem lokalen VMware-Standort und Azure verwendet werden.
Ausführliche Informationen zu dieser modernisierten Architektur finden Sie im Artikel.
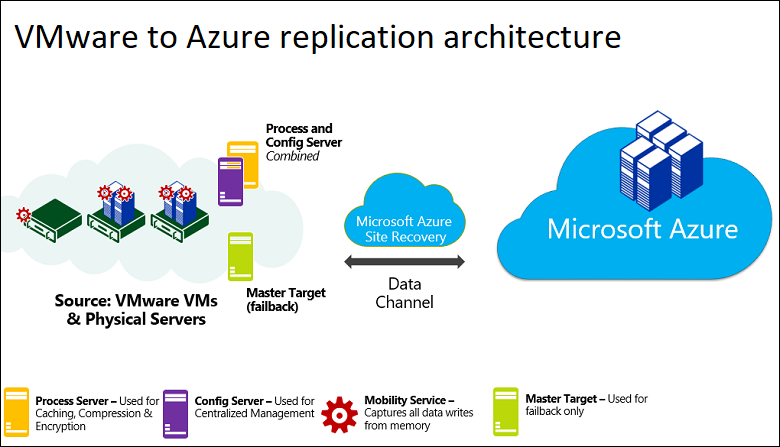
Komponenten der Architektur
Die folgende Tabelle und Grafik enthält eine Übersicht über die Komponenten, die für die Notfallwiederherstellung für VMware-VMs/physische Computer in Azure verwendet werden.
| Komponente | Anforderung | Details |
|---|---|---|
| Azure | Ein Azure-Abonnement, ein Azure Storage-Konto für die Zwischenspeicherung, einen verwalteten Datenträger und ein Azure-Netzwerk. | Replizierte Daten von lokalen VMs werden in Azure Storage gespeichert. Azure-VMs werden mit den replizierten Daten erstellt, wenn Sie ein Failover von lokalen VMs in Azure ausführen. Für die Azure-VMs wird eine Verbindung mit dem virtuellen Azure-Netzwerk hergestellt, wenn diese erstellt werden. |
| Konfigurationsservercomputer | Ein einzelner lokaler Computer. Es wird empfohlen, diesen als eine VMware-VM auszuführen, die aus einer heruntergeladenen OVF-Vorlage bereitgestellt werden kann. Auf dem Computer werden alle lokalen Site Recovery-Komponenten ausgeführt, einschließlich Konfigurationsserver, Prozessserver und Masterzielserver. |
Konfigurationsserver: Koordiniert die Kommunikation zwischen der lokalen Umgebung und Azure und verwaltet die Datenreplikation. Prozessserver Wird standardmäßig auf dem Konfigurationsserver installiert. Er empfängt Replikationsdaten, optimiert sie durch Zwischenspeicherung, Komprimierung und Verschlüsselung und sendet sie an Azure Storage. Der Prozessserver installiert auch Azure Site Recovery Mobility Service auf VMs, die Sie replizieren möchten, und führt auf lokalen Computern eine automatische Ermittlung durch. Bei zunehmender Größe der Bereitstellung können Sie zusätzlich separate Prozessserver hinzufügen, um größere Mengen von Replikationsdatenverkehr zu bewältigen. Masterzielserver: Wird standardmäßig auf dem Konfigurationsserver installiert. Er verarbeitet die Replikationsdaten während des Failbacks von Azure. Bei größeren Bereitstellungen können Sie einen zusätzlichen, separaten Masterzielserver für das Failback hinzufügen. |
| VMware-Server | VMware-Server werden auf lokalen vSphere ESXi-Servern gehostet. Zum Verwalten der Hosts wird ein vCenter-Server empfohlen. | Sie fügen während der Bereitstellung von Site Recovery VMware-Server in den Recovery Services-Tresor hinzu. |
| Replizierte Computer | Mobility Service wird auf jedem virtuellen VMware-Computer installiert, den Sie replizieren. | Es wird empfohlen, dass Sie die automatische Installation vom Prozessserver zulassen. Alternativ können Sie den Dienst manuell installieren oder eine automatisierte Bereitstellungsmethode wie Configuration Manager verwenden. |
Einrichten der ausgehenden Netzwerkkonnektivität
Damit Site Recovery erwartungsgemäß funktioniert, müssen Sie die ausgehende Netzwerkkonnektivität ändern, um Ihrer Umgebung das Replizieren zu ermöglichen.
Hinweis
Für Site Recovery von VMware-/physischen Computern mit klassischer Architektur wird die Verwendung eines Authentifizierungsproxys zum Steuern der Netzwerkkonnektivität nicht unterstützt. Dieser wird unterstützt, wenn die modernisierte Architektur verwendet wird.
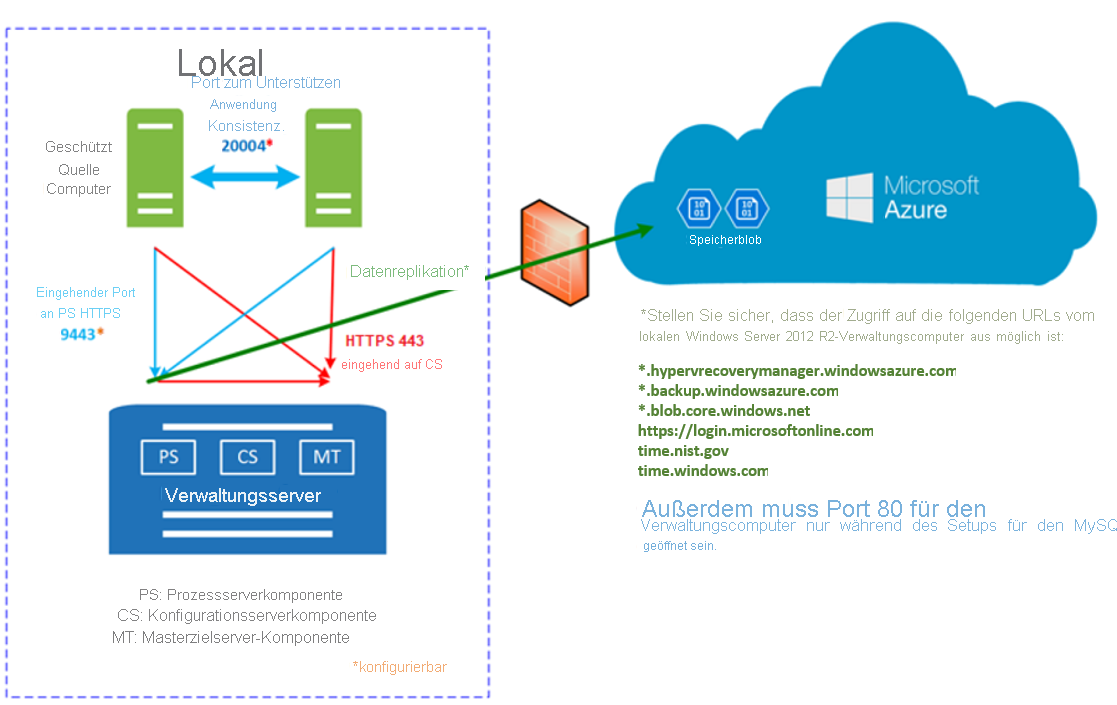
Ausgehende Konnektivität für URLs
Lassen Sie den Zugriff auf die folgenden URLs zu, wenn Sie einen URL-basierten Firewallproxy zum Steuern der ausgehenden Konnektivität verwenden:
| Name | Kommerziell | Behörden | Beschreibung |
|---|---|---|---|
| Storage | *.blob.core.windows.net |
*.blob.core.usgovcloudapi.net |
Ermöglicht das Schreiben von Daten aus der VM in das Cachespeicherkonto in der Quellregion |
| Microsoft Entra ID | login.microsoftonline.com |
login.microsoftonline.us |
Stellt die Autorisierung und Authentifizierung für Site Recovery-Dienst-URLs bereit. |
| Replikation | *.hypervrecoverymanager.windowsazure.com |
*.hypervrecoverymanager.windowsazure.us |
Ermöglicht die Kommunikation der VM mit Site Recovery |
| Service Bus | *.servicebus.windows.net |
*.servicebus.usgovcloudapi.net |
Ermöglicht es der VM, die Site Recovery-Überwachung und -Diagnosedaten zu schreiben |
Eine vollständige Liste der URLs, die für die Kommunikation zwischen der lokalen Azure Site Recovery-Infrastruktur und den Azure-Diensten gefiltert werden müssen, finden Sie im Abschnitt Netzwerkanforderungen im Artikel zu den Voraussetzungen.
Replikationsprozess
Wenn Sie die Replikation für einen virtuellen Computer aktivieren, beginnt die erste Replikation in Azure Storage mithilfe der angegebenen Replikationsrichtlinie. Beachten Sie Folgendes:
- Bei VMware-VMs erfolgt die Replikation auf Blockebene und nahezu kontinuierlich mithilfe des Mobility Service-Agents, der auf dem virtuellen Computer ausgeführt wird.
- Es werden alle festgelegten Replikationsrichtlinieneinstellungen angewendet:
- RPO-Schwellenwert: Diese Einstellung hat keine Auswirkungen auf die Replikation. Sie unterstützt bei der Überwachung. Ein Ereignis wird ausgelöst, und optional wird eine E-Mail gesendet, wenn das aktuelle RPO den von Ihnen angegebenen Schwellenwert überschreitet.
- Aufbewahrung des Wiederherstellungspunkts. Diese Einstellung gibt an, wie weit Sie zurückgehen möchten, wenn es zu einer Unterbrechung kommt. Die maximale Aufbewahrungsdauer für verwaltete Datenträger ist 15 Tage.
- App-konsistente Momentaufnahmen: Abhängig von Ihren App-Anforderungen können alle 1 bis 12 Stunden App-konsistente Momentaufnahmen erstellt werden. Bei den Momentaufnahmen handelt es sich um Azure-Blob-Standardmomentaufnahmen. Der auf einem virtuellen Computer ausgeführte Mobility Service-Agent fordert eine VSS-Momentaufnahme in Übereinstimmung mit dieser Einstellung an und markiert diesen Zeitpunkt als anwendungskonsistenten Punkt im Replikationsstrom.
Hinweis
Ein langer Aufbewahrungszeitraum des Wiederherstellungspunkts kann Auswirkungen auf die Speicherkosten haben, da möglicherweise mehr Wiederherstellungspunkte gespeichert werden müssen.
Der Datenverkehr wird über das Internet auf öffentliche Endpunkte von Azure Storage repliziert. Alternativ hierzu können Sie Azure ExpressRoute mit Microsoft-Peering verwenden. Das Replizieren von Datenverkehr über ein virtuelles privates Site-to-Site-Netzwerk (VPN) von einem lokalen Standort nach Azure wird nicht unterstützt.
Der erste Replikationsvorgang stellt sicher, dass die gesamten Daten auf dem Computer zum Zeitpunkt der Replikation an Azure gesendet werden. Die Replikation von Deltaänderungen in Azure beginnt, nachdem die erste Replikation abgeschlossen wurde. Nachverfolgte Änderungen für einen Computer werden an den Prozessserver gesendet.
Die Kommunikation erfolgt folgendermaßen:
- Virtuelle Computer kommunizieren mit dem lokalen Konfigurationsserver über den Port HTTPS 443 für eingehenden Datenverkehr, um die Replikationsverwaltung auszuführen.
- Der Konfigurationsserver orchestriert die Replikation mit Azure über Port HTTPS 443 für ausgehenden Datenverkehr.
- Virtuelle Computer senden Replikationsdaten an den Prozessserver (der auf dem Konfigurationsserver ausgeführt wird) über Port HTTPS 9443 für eingehenden Datenverkehr. Dieser Port kann geändert werden.
- Der Prozessserver empfängt Replikationsdaten, optimiert und verschlüsselt sie und sendet sie über den ausgehenden Port 443 an Azure Storage.
Die Replikationsdatenprotokolle werden zunächst in einem Cachespeicherkonto in Azure gespeichert. Diese Protokolle werden dann verarbeitet, und die Daten werden auf einem (als Azure Site Recovery-Seed-Datenträger bezeichneten) verwalteten Azure-Datenträger gespeichert. Die Wiederherstellungspunkte werden auf diesem Datenträger erstellt.
Neusynchronisierungsprozess
- Manchmal können bei der ersten Replikation oder beim Übertragen von Deltaänderungen Probleme bei der Netzwerkkonnektivität zwischen dem Quellcomputer und dem Prozessserver oder zwischen dem Prozessserver und Azure auftreten. Beide Arten von Problemen können vorübergehend zu Fehlern bei der Datenübertragung an Azure führen.
- Um Probleme bei der Datenintegrität zu vermeiden und die Datenübertragungskosten zu minimieren, markiert Site Recovery einen Computer für die erneute Synchronisierung.
- Ein Computer kann auch in folgenden Situationen für die erneute Synchronisierung markiert werden, um die Konsistenz zwischen dem Quellcomputer und den in Azure gespeicherten Daten aufrechtzuerhalten.
- Wenn das Herunterfahren eines Computers erzwungen wird
- Wenn auf einem Computer Konfigurationsänderungen durchgeführt werden, z. B. eine Änderung der Datenträgergröße (Ändern der Größe des Datenträgers von 2 TB in 4 TB)
- Bei der Neusynchronisierung werden nur Deltadaten an Azure gesendet. Die Datenübertragung zwischen lokalen Systemen und Azure wird durch die Berechnung von Prüfsummen der Daten auf dem Quellcomputer und der in Azure gespeicherten Daten minimiert.
- Standardmäßig ist die Neusynchronisierung so geplant, dass sie automatisch außerhalb der Geschäftszeiten durchgeführt wird. Wenn Sie nicht auf die Standardneusynchronisierung außerhalb der Geschäftszeiten warten möchten, können Sie eine VM manuell neu synchronisieren. Rufen Sie dafür das Azure-Portal auf, und klicken Sie auf VM >Resynchronisieren.
- Wenn die standardmäßige Neusynchronisierung außerhalb der Geschäftszeiten fehlschlägt und ein manueller Eingriff erforderlich ist, wird ein Fehler auf dem jeweiligen Computer im Azure-Portal generiert. Sie können den Fehler beheben und die Neusynchronisierung manuell auslösen.
- Nach Abschluss der Neusynchronisierung wird die Replikation der Deltaänderungen fortgesetzt.
Verwalten von Replikationsrichtlinien
- Sie können die Einstellungen von Replikationsrichtlinien beim Aktivieren der Replikation anpassen.
- Sie können jederzeit eine Replikationsrichtlinie erstellen und diese dann anwenden, wenn Sie die Replikation aktivieren.
Multi-VM-Konsistenz
Wenn Sie virtuelle Computer gemeinsam replizieren möchten und beim Failover über gemeinsame absturz- und App-konsistente Wiederherstellungspunkte verfügen, können Sie sie in einer Replikationsgruppe zusammenfassen. Multi-VM-Konsistenz wirkt sich auf die Leistung einer Workload aus und sollte nur für virtuelle Computer mit Workloads verwendet werden, bei denen Konsistenz auf sämtlichen Computern erforderlich ist.
Momentaufnahmen und Wiederherstellungspunkte
Wiederherstellungspunkte werden aus Momentaufnahmen von VM-Datenträgern zu einem bestimmten Zeitpunkt erstellt. Wenn Sie ein Failover eines virtuellen Computers ausführen, verwenden Sie einen Wiederherstellungspunkt, um die VM am Zielstandort wiederherzustellen.
Bei einem Failover soll in der Regel sichergestellt werden, dass der virtuelle Computer ohne Beschädigung oder Verlust von Daten gestartet wird und dass die VM-Daten für das Betriebssystem und die Apps, die auf dem virtuellen Computer ausgeführt werden, konsistent sind. Dies hängt vom Typ der erstellten Momentaufnahmen ab.
Site Recovery verwendet Momentaufnahmen wie folgt:
- Site Recovery verwendet absturzkonsistente Momentaufnahmen von Daten standardmäßig und App-konsistente Momentaufnahmen, wenn Sie für diese eine Häufigkeit angeben.
- Wiederherstellungspunkte werden aus Momentaufnahmen erstellt und gemäß den Aufbewahrungseinstellungen in der Replikationsrichtlinie gespeichert.
Konsistenz
In der folgenden Tabelle werden die verschiedenen Konsistenztypen erläutert.
Absturzkonsistent
| Beschreibung | Details | Empfehlung |
|---|---|---|
| Eine absturzkonsistente Momentaufnahme erfasst Daten, die sich zum Zeitpunkt der Erstellung der Momentaufnahme auf dem Datenträger befunden haben. Sie enthält keine Daten aus dem Arbeitsspeicher. Sie enthält die Entsprechung der Daten auf dem Datenträger, wenn zum Zeitpunkt der Momentaufnahme der virtuelle Computer abgestürzt oder das Verbindungskabel zum Server getrennt worden wäre. Absturzkonsistenz garantiert keine Datenkonsistenz für das Betriebssystem oder die Apps auf der VM. |
Site Recovery erstellt standardmäßig alle fünf Minuten einen absturzkonsistenten Wiederherstellungspunkt. Diese Einstellung kann nicht geändert werden. |
Heutzutage können die meisten Apps gut aus absturzkonsistenten Wiederherstellungspunkten wiederhergestellt werden. Absturzkonsistente Wiederherstellungspunkte reichen in der Regel für die Replikation von Betriebssystemen und Apps wie DHCP-Server und Druckserver aus. |
App-konsistent
| Beschreibung | Details | Empfehlung |
|---|---|---|
| App-konsistente Wiederherstellungspunkte werden aus App-konsistenten Momentaufnahmen erstellt. Eine App-konsistente Momentaufnahme enthält alle Informationen in einer absturzkonsistenten Momentaufnahme sowie darüber hinaus alle Daten im Arbeitsspeicher und alle gerade bearbeiteten Transaktionen. |
App-konsistente Momentaufnahmen verwenden den Volumeschattenkopie-Dienst (Volume Shadow Copy Service, VSS): 1) Azure Site Recovery verwendet die Backup-Methode Copy Only (VSS_BT_COPY), die den Zeitpunkt der Sicherung des Transaktionsprotokolls und die Sequenznummer von Microsoft SQL nicht verändert 2) Wenn ein Snapshot initiiert wird, führt VSS eine Copy-on-Write (COW) Operation auf dem Volume durch. 3) Vor der Ausführung des COW-Vorgangs informiert VSS jede App auf dem Computer darüber, dass die speicherresidenten Daten auf den Datenträger übertragen werden müssen. 4) VSS erlaubt dann der Sicherungs-/Notfallwiederherstellungs-App (in diesem Fall Site Recovery) das Lesen der Momentaufnahmedaten und das Fortsetzen des Vorgangs. |
App-konsistente Momentaufnahmen werden mit der von Ihnen angegebenen Häufigkeit erstellt. Diese Häufigkeit sollte immer kleiner sein als der Wert für die Beibehaltung von Wiederherstellungspunkten. Wenn Sie beispielsweise Wiederherstellungspunkte gemäß der Standardeinstellung von 24 Stunden beibehalten, sollten Sie die Häufigkeit auf weniger als 24 Stunden festlegen. Sie sind komplexer und dauern daher länger als absturzkonsistente Momentaufnahmen. Sie haben auch Auswirkungen auf die Leistung von Apps, die auf einem virtuellen Computer, für den die Replikation aktiviert wurde, ausgeführt werden. |
Failover- und Failbackprozesse
Nachdem die Replikation eingerichtet ist und Sie einen Notfallwiederherstellungsdrill (Testfailover) ausgeführt haben, um zu überprüfen, ob alles wie erwartet funktioniert, können Sie bei Bedarf ein Failover und ein Failback ausführen.
Sie können ein Failover für einen einzelnen Computer ausführen oder Wiederherstellungspläne erstellen, um ein Failover für mehrere virtuelle Computer gleichzeitig auszuführen. Ein Wiederherstellungsplan besitzt gegenüber dem Failover eines einzelnen Computers die folgenden Vorteile:
- Sie können App-Abhängigkeiten modellieren, indem Sie alle virtuellen Computer in der App in einen einzelnen Wiederherstellungsplan einschließen.
- Sie können Skripts und Azure-Runbooks hinzufügen und den Vorgang für manuelle Aktionen anhalten.
Nachdem das erste Failover ausgelöst wird, committen Sie es, um von der Azure-VM auf die Workload zuzugreifen.
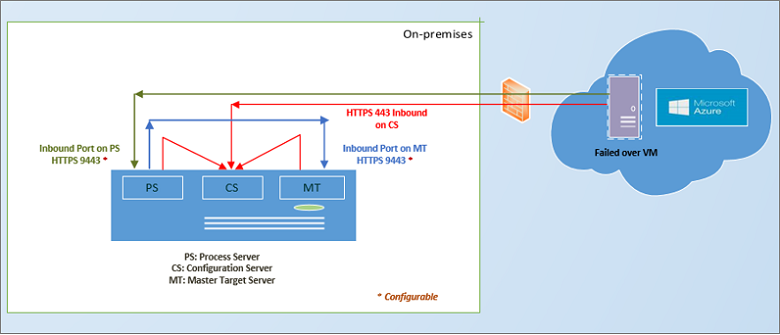
Wenn Ihr primärer lokaler Standort wieder verfügbar ist, können Sie sich auf ein Failback vorbereiten. Damit das Failback ausgeführt werden kann, müssen Sie eine Failbackinfrastruktur festlegen, die Folgendes enthält:
- Temporärer Prozessserver in Azure: Sie legen für ein Failback von Azure eine Azure-VM fest, die als Prozessserver fungiert, um die Replikation von Azure zu verarbeiten. Nach Beendigung des Failbacks können Sie diese VM löschen.
- VPN-Verbindung: Für das Failback benötigen Sie eine VPN-Verbindung (oder ExpressRoute-Verbindung) zwischen dem Azure-Netzwerk und dem lokalen Standort.
- Separater Masterzielserver: Der lokale Masterzielserver, der mit dem Konfigurationsserver in der lokalen VMware-VM installiert wurde, führt standardmäßig das Failback aus. Wenn Sie ein Failback für große Volumen von Datenverkehr ausführen müssen, richten Sie einen separaten lokalen Masterzielserver ein.
- Failbackrichtlinie: Für die Replikation zurück an den lokalen Standort benötigen Sie eine Failbackrichtlinie. Diese Richtlinie wird automatisch erstellt, wenn Sie eine Replikationsrichtlinie aus lokalen VMs in Azure erstellen.
Nachdem die Komponenten vorhanden sind, erfolgt das Failback in drei Phasen:
- Phase 1: Schützen Sie die Azure-VMs erneut, sodass sie die Replikation von Azure zurück zu den lokalen VMware-VMs durchführen.
- Phase 2: Führen Sie ein Failover zum lokalen Standort aus.
- Phase 3: Nachdem für Workloads ein Failback ausgeführt wurde, aktivieren Sie erneut die Replikation für die lokalen VMs.
Nächste Schritte
Absolvieren Sie dieses Tutorial, um eine VMware-zu-Azure-Replikation zu ermöglichen.