Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Ihr Agent überlegt bei Problemen, statt einfach Skripten zu folgen. Es sammelt Nachweise, wählt die richtigen Tools aus, klassifiziert Aktionen nach Risiko und erklärt sein Denken, alles sichtbar in der Chatoberfläche.
Die Begründungsschleife
Jede nachricht, die Sie senden, durchläuft dieselbe Schleife.

- Verstehen: Analysieren Sie Ihre Anfrage, und identifizieren Sie, welche Daten benötigt werden.
- Sammelkontext: Abfragen von Datenquellen parallel, einschließlich Protokollen, Metriken, Ressourcenstatus, Bereitstellungsverlauf und Arbeitsspeicher.
- Grund: Analysieren Sie gesammelte Daten, identifizieren Sie Muster und ziehen Sie Schlussfolgerungen.
- Handeln oder antworten: Führen Sie sichere Aktionen aus, fordern Sie eine Genehmigung für riskante Aktionen an, oder präsentieren Sie Ergebnisse.
Wenn das Problem mehr Arbeit erfordert, iteriert die Schleife bis zu 10 Mal pro Iteration. Danach fragt Ihr Agent, ob der Vorgang fortgesetzt werden soll.
Adaptives Denken
Bei komplexen Problemen zeigt Ihr Agent seinen Begründungsprozess im Chat an. Ein einklappbarer "Denken"-Abschnitt erscheint mit beschreibenden Titeln für jeden Schritt (z. B. "Erforschen von Azure-Gesundheitsproblemen" oder "Analysieren aktiver Warnungen") und der verstrichenen Zeit.
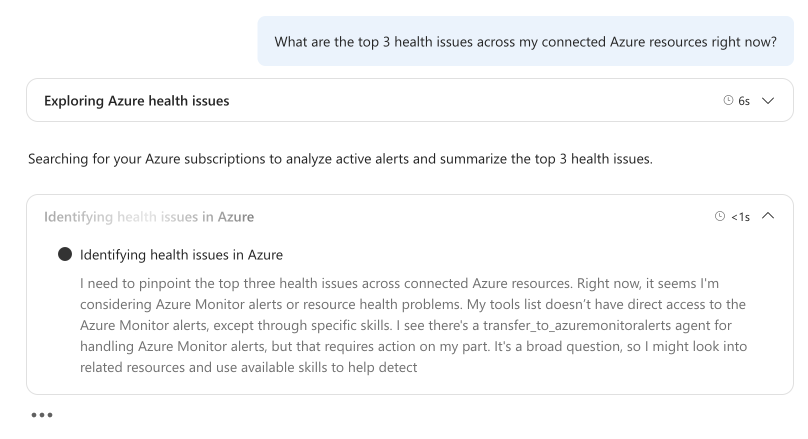
Ihr Agent passt die Begründungstiefe automatisch an. Eine Statusüberprüfung erhält eine schnelle Antwort. Ein Mehrschritt-Ausfall wird mit einer mehrstufigen Analyse und Beweiskorrelation behandelt.
Gedächtnis und Wissen bei der Begründung
Ihr Agent beginnt nicht von Grund auf neu. Es durchsucht den Speicher am Anfang jeder Unterhaltung. Dieser Speicher beeinflusst, wie es denkt.
| Was es daraus zieht | Wie es das Denken verbessert |
|---|---|
| Sitzungseinblicke | Lernen aus allen vergangenen Gesprächen, einschließlich Vorfallsuntersuchungen, Fehlerbehebungsgesprächen und geplanten Aufgabenergebnissen. |
| Ähnliche Symptommuster | Erkennt wiederkehrende Muster und springt schneller zu wahrscheinlichen Ursachen. |
| Ihre hochgeladenen Runbooks und Dokumentationen | Folgt den Verfahren Ihres Teams anstelle von generischen Ratschlägen |
| Benutzereinstellungen | Merkt sich Ihren Umgebungskontext und Ihre Antwortpräferenzen. |
Je mehr Wissen Sie bereitstellen, z. B. Runbooks, Architekturdokumente und Teamprozeduren, desto relevanter wird die Begründung Ihres Agenten. Weitere Informationen finden Sie unter "Speicher und Wissen".
Toolauswahl
Ihr Agent wählt tools strategisch basierend auf dem Problem aus.
- Beginnt mit allen Tools, die für den aktuellen Subagent registriert sind.
- Filtert nach Plattform, und wählt nur Vorfalltools für die verbundene Vorfallplattform aus.
- Filtert nach veröffentlichter Liste, und wählen Sie nur Tools aus, die Sie zur Verfügung stellen.
- Passt sich an, wenn während der Unterhaltung neue Informationen entstehen.
Jeder Subagent verfügt über einen eigenen Toolsatz. Wenn Ihr Agent an einen anderen Subagent delegiert wird, werden die verfügbaren Tools automatisch geändert.
Weitere Informationen zu den verfügbaren Tools finden Sie unter Tools.
Aktionsklassifizierung
Ihr Agent klassifiziert jede Aktion, bevor sie ausgeführt wird.
| Klassifizierung | Verhalten | Beispiele |
|---|---|---|
| Sicher | Wird sofort ausgeführt | Abfrageprotokolle, Überprüfen des Ressourcenstatus, Listenbereitstellungen |
| Vorsichtig | Führt eine Aktion mit einer kurzen Erläuterung durch | Senden von E-Mails, Posten von Teams-Nachrichten |
| Zerstörend | Erfordert Ihre Bestätigung | Starten Sie eine App neu, skalieren Sie Ressourcen, ändern Sie Konfigurationen. |
Wie Ihr Agent jeden Typ verarbeitet, hängt vom Ausführungsmodus ab.
| Ausführungsmodus | Sicher | Vorsichtig | Zerstörend |
|---|---|---|---|
| ReadOnly | Ausführen | Schreibgeschützt | Blocked |
| Bewertung | Ausführen | Ausführen | Bittet um Genehmigung |
| Autonome | Ausführen | Ausführen | Ausführen |
Konversationsmanagement
Zwei Mechanismen halten lange Unterhaltungen produktiv.
| Mechanismus | Was es tut |
|---|---|
| Verdichtung | Wenn Unterhaltungen sehr lang sind, fasst Ihr Agent früheren Kontext zusammen und bewahrt wichtige Ergebnisse auf. Sie können diese Aktion manuell mithilfe des /compact Befehls auslösen. |
| Automatische Wiederholversuche | Wenn eine Dienstunterbrechung während der Antwort auftritt, versucht Ihr Agent es erneut im Hintergrund. |
| Fehlerbehandlung | Wenn ein Modell auf ein temporäres Problem stößt, zeigt Ihr Agent anstelle eines allgemeinen internen Fehlers eine benutzerfreundliche Meldung an ("Modell tritt vorübergehend Probleme auf"). |
Stornierung
Wenn Sie "Beenden" auswählen, hält Ihr Agent sofort alle Vorgänge an und fügt eine interne Markierung hinzu, die verhindert, dass die abgebrochene Aufgabe wiederholt wird. Die nächste Nachricht wird neu gestartet, es sei denn, Sie ändern die abgebrochene Anforderung explizit.
Boundaries
In der folgenden Tabelle wird zusammengefasst, was die Agent-Begründung tut und was nicht.
| Was macht die Begründung? | Was dies nicht tut |
|---|---|
| Sammelt Nachweise aus mehreren Quellen parallel | Garantie für das Auffinden einer Ursache (Nachweise sind möglicherweise unzureichend) |
| Klassifiziert Aktionen und respektiert den Ausführungsmodus. | Automatische Korrektur ohne Bestätigung im Überprüfungsmodus |
| Erläutert das Denken schritt für Schritt | Gemeinsame Untersuchungsmethode über separate Agents hinweg |
| Passt die Denktiefe an die Problemkomplexität an. | Ersetzen des menschlichen Urteils für kritische Entscheidungen |
Nächster Schritt
Verwandte Inhalte
- Ursachenanalyse: Umfassende Untersuchung mit Hypothesenbäumen
- Ausführungsmodi: ReadOnly, Review und Autonomes Verhalten
- Speicher und Wissen: Wie Ihr Agent sich kontextübergreifend in Unterhaltungen erinnert
- Tools: Integrierte und benutzerdefinierte Toolfunktionen
- Fähigkeiten: Domänenspezifische Untersuchungsverfahren