Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure Synapse Analytics Data Explorer (Vorschau) wird am 7. Oktober 2025 eingestellt. Nach diesem Datum werden Arbeitslasten, die im Synapse-Daten-Explorer ausgeführt werden, gelöscht, und die zugehörigen Anwendungsdaten gehen verloren. Es wird dringend empfohlen , zu Eventhouse in Microsoft Fabric zu migrieren.
Das Microsoft Cloud Migration Factory (CMF)-Programm wurde entwickelt, um Kunden bei der Migration zu Fabric zu unterstützen. Das Programm bietet dem Kunden kostenlos praktische Tastaturressourcen. Diese Ressourcen werden für einen Zeitraum von 6-8 Wochen mit einem vordefinierten und vereinbarten Umfang zugewiesen. Kunden nominierungen werden vom Microsoft-Kontoteam oder direkt durch Senden einer Anfrage zur Hilfe an das CMF-Team akzeptiert.
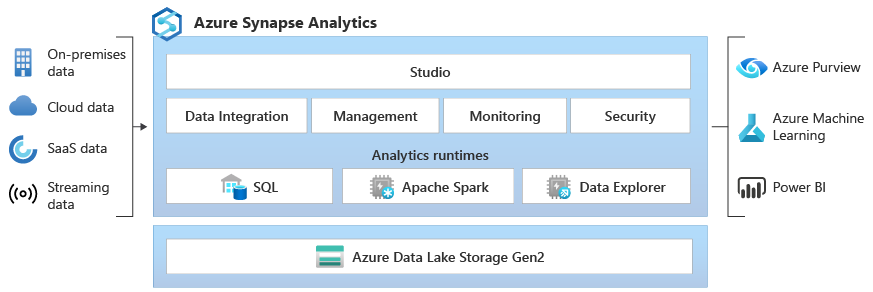
Der Azure Synapse-Daten-Explorer bietet Kunden eine interaktive Abfrageerfahrung, um Einblicke aus Protokoll- und Telemetriedaten zu entsperren. Um vorhandene SQL- und Apache Spark Analytics-Laufzeitmodule zu ergänzen, ist die Daten-Explorer-Analyselaufzeit für effiziente Protokollanalysen mit leistungsstarker Indizierungstechnologie optimiert, um Freitext- und halbstrukturierte Daten, die häufig in Telemetriedaten zu finden sind, automatisch indizieren zu können.
Weitere Informationen finden Sie im folgenden Video:
Was macht Azure Synapse Data Explorer einzigartig?
Einfache Erfassung – Der Daten-Explorer bietet integrierte Integrationen für No-Code/Low-Code, datenaufnahme mit hohem Durchsatz und Zwischenspeichern von Daten aus Echtzeitquellen. Daten können aus Quellen wie Azure Event Hubs, Kafka, Azure Data Lake, Open Source-Agents wie Fluentd/Fluent Bit und einer Vielzahl von Cloud- und lokalen Datenquellen aufgenommen werden.
Keine komplexe Datenmodellierung – Mit dem Daten-Explorer müssen keine komplexen Datenmodelle erstellt werden, und es ist nicht erforderlich, komplexe Skripts zum Transformieren von Daten zu erstellen, bevor sie verbraucht werden.
Keine Indexwartung – Es sind keine Wartungsaufgaben zur Optimierung der Datenabfrageleistung erforderlich, und keine Indexwartung ist notwendig. Mit dem Daten-Explorer sind alle Rohdaten sofort verfügbar, sodass Sie Hochleistungs- und Parallelitätsabfragen für Ihre Streaming- und persistenten Daten ausführen können. Sie können diese Abfragen verwenden, um Nahezu-Echtzeit-Dashboards und -Warnungen zu erstellen und Betriebsanalysedaten mit dem Rest der Datenanalyseplattform zu verbinden.
Demokratisierung von Datenanalysen – Der Daten-Explorer demokratisiert Self-Service, Big Data Analytics mit der intuitiven Kusto Query Language (KQL), die die Ausdrucksfähigkeit und Leistungsfähigkeit von SQL mit der Einfachheit von Excel bietet. KQL ist hochoptimiert für die Untersuchung von Rohtelemetrie- und Zeitreihendaten, indem die erstklassige Textindizierungstechnologie des Daten-Explorers für effiziente Freitext- und Regex-Suche sowie umfassende Analysefunktionen für die Abfrage von Ablaufverfolgungen sowie Textdaten und von halbstrukturierten JSON-Daten mit Arrays und geschachtelten Strukturen verwendet wird. KQL bietet erweiterte Unterstützung für die Verarbeitung und Analyse mehrerer Zeitreihen mit Python-Ausführungsunterstützung innerhalb der Engine für die Modellbewertung.
Bewährte Technologie im Petabyte-Maßstab – Der Daten-Explorer ist ein verteiltes System mit Computeressourcen und Speicher, das unabhängig skaliert werden kann, wodurch Analysen auf Gigabyte oder Petabyte-Daten ermöglicht werden.
Integriert – Azure Synapse Analytics bietet Interoperabilität zwischen Daten-Explorer-, Apache Spark- und SQL-Engines, mit denen Datentechniker, Data Scientists und Datenanalysten problemlos und sicher auf die gleichen Daten im Datensee zugreifen und zusammenarbeiten können.
Wann soll der Azure Synapse-Daten-Explorer verwendet werden?
Verwenden Sie den Daten-Explorer als Datenplattform zum Erstellen nahezu echtzeitbasierter Protokollanalysen und IoT-Analyselösungen für:
Konsolidieren und korrelieren Sie Ihre Protokolle und Ereignisdaten in lokalen, Cloud- und Drittanbieterdatenquellen.
Beschleunigen Sie Ihre KI Ops-Reise (Mustererkennung, Anomalieerkennung, Prognose und mehr).
Ersetzen Sie infrastrukturbasierte Protokollsuchlösungen, um Kosten zu sparen und die Produktivität zu steigern.
Erstellen Sie IoT-Analyselösungen für Ihre IoT-Daten.
Erstellen Sie Analyse-SaaS-Lösungen, um Ihren internen und externen Kunden Dienste anzubieten.
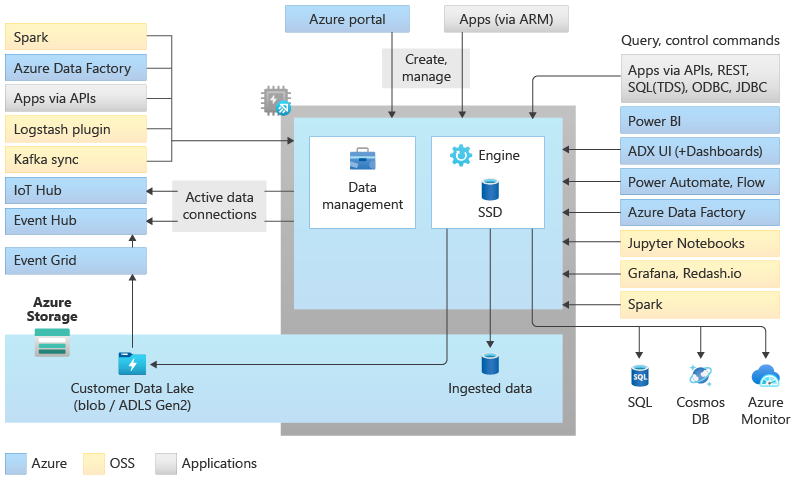
Architektur des Daten-Explorer-Pools
Daten-Explorer-Pools implementieren eine Skalierungsarchitektur, indem die Compute- und Speicherressourcen getrennt werden. Auf diese Weise können Sie jede Ressource unabhängig skalieren und beispielsweise mehrere schreibgeschützte Berechnungen für dieselben Daten ausführen. Daten-Explorer-Pools bestehen aus einer Reihe von Computeressourcen, die das Modul ausführen, das für die automatische Indizierung, Komprimierung, Zwischenspeicherung und Bereitstellung verteilter Abfragen verantwortlich ist. Sie verfügen außerdem über einen zweiten Satz von Computeressourcen, die den Datenverwaltungsdienst ausführen, der für Hintergrundsystemaufträge verantwortlich ist, sowie verwaltete und in die Warteschlange eingereihte Datenaufnahme. Alle Daten werden auf verwalteten Blob-Speicherkonten mithilfe eines komprimierten Spaltenformats gespeichert.
Daten-Explorer-Pools unterstützen ein umfangreiches Ökosystem zum Aufnehmen von Daten mithilfe von Connectors, SDKs, REST-APIs und anderen verwalteten Funktionen. Es bietet verschiedene Möglichkeiten, Daten für Ad-hoc-Abfragen, Berichte, Dashboards, Warnungen, REST-APIs und SDKs zu nutzen.
Es gibt viele einzigartige Funktionen, mit denen Data Explore das beste Analysemodul für Protokoll- und Zeitreihenanalysen in Azure macht.
In den folgenden Abschnitten werden die wichtigsten Unterscheidungsmerkmale hervorgehoben.
Freitext- und halbstrukturierte Datenindizierung ermöglicht nahezu in Echtzeit hohe Leistung und hohe gleichzeitige Abfragen
Der Daten-Explorer indiziert halbstrukturierte Daten (JSON) und unstrukturierte Daten (Freitext), wodurch die Ausführung von Abfragen für diese Art von Daten gut ausgeführt wird. Standardmäßig wird jedes Feld während der Datenverarbeitung indiziert. Es besteht jedoch die Möglichkeit, eine Low-Level-Codierungsrichtlinie zu verwenden, um den Index für bestimmte Felder zu optimieren oder zu deaktivieren. Der Bereich des Indexes ist ein einzelner Datenshard.
Die Implementierung des Indexes hängt vom Typ des Felds wie folgt ab:
| Feldtyp | Indizierungsimplementierung |
|---|---|
| String | Das Modul erstellt einen invertierten Index für Werte in Zeichenfolgenspalten. Jeder Zeichenfolgenwert wird analysiert und in normalisierte Ausdrücke aufgeteilt, und eine geordnete Liste der logischen Positionen, die Datensatz-Ordnungszahlen enthalten, wird für jeden Ausdruck aufgezeichnet. Die resultierende sortierte Liste von Begriffen und deren zugewiesene Positionen wird als unveränderlicher B-Baum gespeichert. |
|
Numeric (Numerisch) Datum und Uhrzeit TimeSpan |
Das Modul erstellt einen einfachen bereichsbasierten Vorwärtsindex. Der Index zeichnet die Min/Max-Werte für jeden Block auf, für eine Gruppe von Blöcken und für die gesamte Spalte innerhalb der Datenspalte. |
| dynamische | Der Aufnahmeprozess listet alle "atom"-Elemente innerhalb des dynamischen Werts auf, z. B. Eigenschaftsnamen, Werte und Arrayelemente, und leitet sie an den Index-Generator weiter. Dynamische Felder haben den gleichen invertierten Termindex wie Stringfelder. |
Diese effizienten Indizierungsfunktionen ermöglichen Es Data Explore, die Daten in nahezu Echtzeit für Hochleistungs- und Parallelitätsabfragen verfügbar zu machen. Das System optimiert datenshards automatisch, um die Leistung weiter zu steigern.
Kusto-Abfragesprache
KQL verfügt über eine große, wachsende Community mit der schnellen Einführung von Azure Monitor Log Analytics und Application Insights, Microsoft Sentinel, Azure Data Explorer und anderen Microsoft-Angeboten. Die Sprache ist gut mit einer leicht lesbaren Syntax konzipiert und bietet einen reibungslosen Übergang von einfachen einzeiligen zu komplexen Datenverarbeitungsabfragen. Auf diese Weise kann der Daten-Explorer umfassende IntelliSense-Unterstützung und eine umfangreiche Gruppe von Sprachkonstrukten und integrierten Funktionen für Aggregationen, Zeitreihen und Benutzeranalysen bereitstellen, die in SQL nicht zur schnellen Untersuchung von Telemetriedaten verfügbar sind.