Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
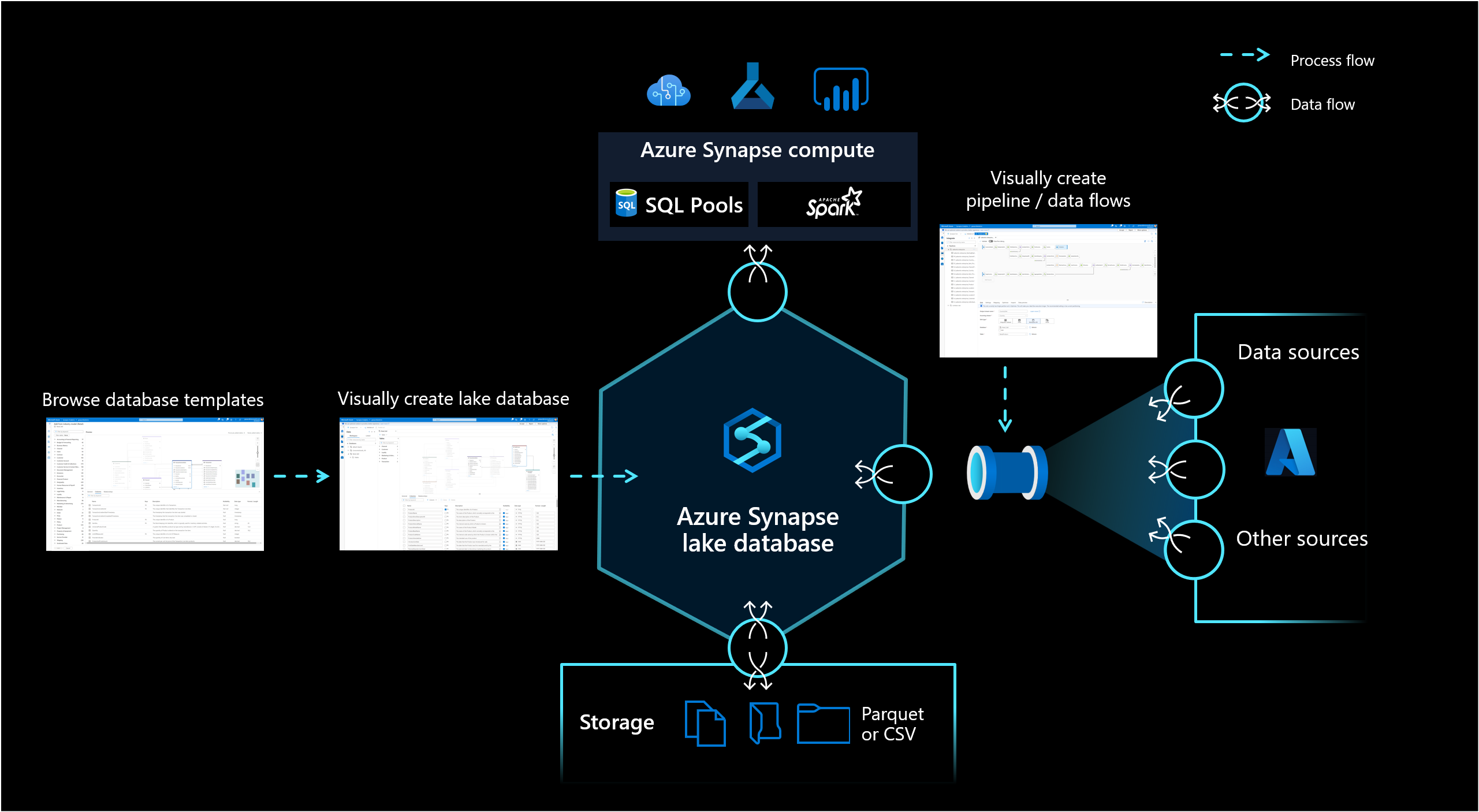
Die Lake-Datenbank in Azure Synapse Analytics ermöglicht es Kunden, Datenbankdesign und Metainformationen zu den gespeicherten Daten zusammenzuführen, gemeinsam mit einer Möglichkeit zur Beschreibung, wie und wo die Daten gespeichert werden sollen. Lake-Datenbanken sind die Antwort auf die Herausforderungen moderner Data Lakes, bei denen es schwierig ist, die Struktur der Daten zu verstehen.
Datenbank-Designer
Der neue Datenbank-Designer in Synapse Studio bietet Ihnen die Möglichkeit, ein Datenmodell für Ihre Lake-Datenbank zu erstellen und ihr zusätzliche Informationen hinzuzufügen. Jede Entität und jedes Attribut kann beschrieben werden, um weitere Informationen über das Modell zu erhalten, das nicht nur Entitäten, sondern auch Beziehungen umfasst. Insbesondere die fehlende Möglichkeit zum Modellieren von Beziehungen stellte eine Herausforderung für die Interaktion mit einem Data Lake dar. Diese Problematik wird nun mit einem integrierten Designer gelöst, der Möglichkeiten bietet, die bislang für Datenbanken, aber nicht für einen Data Lake zur Verfügung standen. Durch die Möglichkeit, dem Modell Beschreibungen und mögliche Beispielwerte hinzuzufügen, können Benutzer bei der späteren Interaktion mit dem Modell Informationen dort abrufen, wo sie sie benötigen, um ein besseres Verständnis der Daten zu erhalten.
Hinweis
Die maximale Größe von Metadaten in einer Lake-Datenbank beträgt 10 GB. Wenn Sie versuchen, ein Modell zu veröffentlichen oder zu aktualisieren, das größer als 10 GB ist, tritt ein Fehler auf. Um dieses Problem zu beheben, verringern Sie die Modellgröße, indem Sie Tabellen und Spalten entfernen. Erwägen Sie, große Modelle in mehrere Lake-Datenbanken aufzuteilen, um diesen Grenzwert zu vermeiden.
Datenspeicher
Lake-Datenbanken verwenden einen Data Lake im Azure Storage-Konto, um die Daten der Datenbank zu speichern. Die Daten können im Parquet-, Delta- oder CSV-Format gespeichert werden, und der Speicher kann mithilfe verschiedener Einstellungen optimiert werden. Jede Lake-Datenbank verwendet einen verknüpften Dienst, um den Speicherort des Stammdatenordners zu definieren. Für jede Entität werden in diesem Datenbankordner im Data Lake standardmäßig separate Ordner erstellt. Per Voreinstellung verwenden alle Tabellen in einer Lake-Datenbank dasselbe Format, aber die Formate und der Speicherort der Daten können bei Bedarf pro Entität geändert werden.
Hinweis
Durch die Veröffentlichung einer Lake-Datenbank werden keine der zugrunde liegenden Strukturen oder Schemata erstellt, die für die Abfrage der Daten in Spark oder SQL benötigt werden. Nach der Veröffentlichung laden Sie die Daten in Ihre Lake-Datenbank, indem Sie Pipelines verwenden, um sie abzufragen.
Derzeit wird die Delta-Formatunterstützung für Lake-Datenbanken in Synapse Studio nicht unterstützt.
Die Synchronisierung von Lake-Datenbankobjekten zwischen Speicher und Synapse ist unidirektional. Führen Sie die Erstellung oder Schemaänderung von Lake-Datenbankobjekten unbedingt mithilfe des Datenbank-Designers in Synapse Studio durch. Wenn Sie solche Änderungen stattdessen über Spark oder direkt im Speicher vornehmen, werden die Definitionen Ihrer Lake-Datenbanken nicht mehr synchronisiert. In diesem Fall werden möglicherweise alte Lake-Datenbankdefinitionen im Datenbank-Designer angezeigt. Sie müssen solche Änderungen im Datenbank-Designer replizieren und veröffentlichen, damit Ihre Lake-Datenbanken wieder synchron sind.
Datenbank-Computeressourcen
Die Lake-Datenbank wird in einem serverlosen Synapse-SQL-Pool und Apache Spark verfügbar gemacht, um Benutzern die Möglichkeit zu bieten, Speicher- von Computeressourcen zu entkoppeln. Die mit der Lake-Datenbank verknüpften Metadaten erleichtern es den verschiedenen Compute-Engines, nicht nur ein integriertes Erlebnis zu bieten, sondern auch zusätzliche Informationen (z. B. Beziehungen) zu nutzen, die ursprünglich im Data Lake nicht unterstützt wurden.
Zugehöriger Inhalt
Erfahren Sie mehr über die Möglichkeiten des Database Designers, indem Sie den Link unten verwenden.